УДК 004.622
А.О. Петце
Донецкий Национальный Технический Университет, Факультет Компьютерных Наук и Технологий, Кафедра Автоматизированных Систем Управления
Предварительная обработка данных и отбор факторов в задачах нейросетевой классификации и прогнозирования
Аннотация
Петце А.О. Предварительная обработка данных и отбор факторов в задачах нейросетевой классификации и прогнозирования
Ключевые слова: данные, обработка, отбор факторов, нейронные сети, классификация, прогноз.
Постановка проблемы
Предварительная обработка данных является важнейшим этапом, от качества выполнения которого, зависит возможность получения качественных результатов всего процесса анализа данных.
Если возникает необходимость использовать нейросетевые методы для решения конкретных задач, то первое с чем приходится сталкиваться – это подготовка данных. Как правило, при описании различных нейроархитектур, по умолчанию предполагают что данные для обучения уже имеются и представлены в виде, доступном для нейросети. На практике же именно этап предобработки может стать наиболее трудоемким элементом нейросетевого анализа. По некоторым оценкам этап предварительной обработки данных может занять до 80% всего времени, отведенного на проект. Успех обучения нейросети также может решающим образом зависеть от того, в каком виде представлена информация для ее обучения.
Собственно, предварительная обработка данных позволяет как повысить качество интеллектуального анализа данных, так и повысить качество самих данных.
Один из прогнозов необходимости увеличения качества данных, сделанный Даффи Брансоном [4] (Duffie Brunson) звучит следующим образом:
«Прогноз. Многие компании стали обращать больше внимания на качество данных, поскольку низкое качество данных стоит денег в том смысле, что ведет к снижению производительности, принятию неправильных бизнес-решений и невозможности получить желаемый результат, а также затрудняет выполнение требований законодательства. Поэтому компании действительно намерены предпринимать конкретные действия для решения проблем качества данных.
Реальность. Данная тенденция сохраняется, особенно в индустрии финансовых услуг. В первую очередь это относится к фирмам, старающимся выполнять соглашение Basel II. Некачественные данные не могут использоваться в системах оценки рисков, которые применяются для установки цен на кредиты и вычисления потребностей организации в капитале. Интересно отметить, что существенно изменились взгляды на способы решения проблемы качества данных. Вначале менеджеры обращали основное внимание на инструменты оценки качества, считая, что "собственник" данных должен решать проблему на уровне источника, например, очищая данные и переобучая сотрудников. Но сейчас их взгляды существенно изменились. Понятие качества данных гораздо шире, чем просто их аккуратное введение в систему на первом этапе. Сегодня уже многие понимают, что качество данных должно обеспечиваться процессами извлечения, преобразования и загрузки (extraction, transformation, loading - ETL), а также получения данных из источников, которые подготавливают данные для анализа».
Цель статьи
Целью статьи является создание компьютеризированной системы, позволяющей проводить предварительную обработку данных и отбирать наиболее значимые факторы, для решения задач нейросетевой классификации и прогнозирования.
Максимизация энтропии
![]() Информативность
каждого поля/параметра данных, в условиях решаемой задачи, должна быть
максимальной. Следовательно, можно утверждать о необходимости максимизации
энтропии, для увеличения вероятности правильного прогнозирования и классификации.
Информативность
каждого поля/параметра данных, в условиях решаемой задачи, должна быть
максимальной. Следовательно, можно утверждать о необходимости максимизации
энтропии, для увеличения вероятности правильного прогнозирования и классификации.
, где
![]() - состояние некоторого поля/параметра
данных,
- состояние некоторого поля/параметра
данных,
![]() - вероятность этого состояния,
- вероятность этого состояния,
![]() - количество таких состояний.
- количество таких состояний.
Такая предобработка данных предназначена для кодирования входов-выходов в нейронных сетях, так как они воспринимают только числовую информацию.
Нормировка данных
Очевидно, что результаты нейросетевого моделирования не должны зависеть от единиц измерения величин. Значит, можно утверждать, что для повышения качества и скорости обучения нейронной сети, есть необходимость приведения данных к единому масштабу путем нормировки данных.
![]() Приведение данных
к единичному масштабу обеспечивается нормировкой каждой переменной на диапазон
разброса ее значений. В простейшем варианте это - линейное преобразование:
Приведение данных
к единичному масштабу обеспечивается нормировкой каждой переменной на диапазон
разброса ее значений. В простейшем варианте это - линейное преобразование:
, где
![]() - выбранное состояние поля/параметра
данных,
- выбранное состояние поля/параметра
данных,
![]() - максимальное состояние поля/параметра
данных,
- максимальное состояние поля/параметра
данных,
![]() - минимальное состояние поля/параметра
данных.
- минимальное состояние поля/параметра
данных.
Понижение размерности входов
Существует два типа алгоритмов:
- отбор наиболее информативных признаков и использование их в процессе обучения нейронной сети (в этом случае наиболее правильным будет использование генетического алгоритма отбирающего наиболее информативные признаки, однако возможен вариант с оценкой, по векторов признаков, стохастического расстояния между распределениями вероятностей);
- кодирование исходных данных меньшим числом переменных, но при этом содержащих по возможности всю информацию, заложенную в исходных данных (анализ главных компонент с использованием нейронной сети).
Был выбран метод анализа главных компонент, с использованием нейронной сети, в общем виде выглядящей так:
![]()
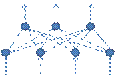
![]()
, где
![]() - выход с i-того нейрона
внутреннего слоя,
- выход с i-того нейрона
внутреннего слоя,
![]() - веса сети между входным и выходным
слоями,
- веса сети между входным и выходным
слоями,
![]() - компонента входного вектора.
- компонента входного вектора.
Алгоритм построения классификатора на основе нейронных сетей
1. Работа с данными
· Составить базу данных из примеров, характерных для данной задачи
· Разбить всю совокупность данных на два множества: обучающее и тестовое (возможно разбиение на 3 множества: обучающее, тестовое и подтверждающее).
2. Предварительная обработка
· Выбрать систему признаков, характерных для данной задачи, и преобразовать данные соответствующим образом для подачи на вход сети (нормировка, стандартизация и т.д.). В результате желательно получить линейно отделяемое пространство множества образцов.
· Выбрать систему кодирования выходных значений (классическое кодирование, 2 на 2 кодирование и т.д.)
3. Конструирование, обучение и оценка качества сети
· Выбрать топологию сети: количество слоев, число нейронов в слоях и т.д.
· Выбрать функцию активации нейронов (например "сигмоида")
· Выбрать алгоритм обучения сети
· Оценить качество работы сети на основе подтверждающего множества или другому критерию, оптимизировать архитектуру (уменьшение весов, прореживание пространства признаков)
· Остановится на варианте сети, который обеспечивает наилучшую способность к обобщению и оценить качество работы по тестовому множеству
4. Использование и диагностика
· Выяснить степень влияния различных факторов на принимаемое решение (эвристический подход).
· Убедится, что сеть дает требуемую точность классификации (число неправильно распознанных примеров мало)
· При необходимости вернутся на этап 2, изменив способ представления образцов или изменив базу данных.
· Практически использовать сеть для решения задачи.
Выводы
Для выполнения задач предварительной обработки данных, позволяющих быстрее и качественнее решать задачи классификации и прогнозирования были выбраны следующие методы обработки данных: максимизация энтропии, индивидуальная нормировка данных, понижение размерности входов обучаемой сети путем метода анализа главных компонент. Выбран алгоритм построения классификатора на основе используемой нейронной сети.
Список литературы
1. А.А. Ежов, С.А. Шумский Нейрокомпьютинг и его применение в экономике и бизнесе. – М, 1998. – С. 126-145.
2. Чубукова И.А. Data Mining: учебное пособие. — М.: Интернет-университет информационных технологий: БИНОМ: Лаборатория знаний, 2006. – С. 208-221.
4. Десять основных тенденций 2005 года в области Business Intelligence и Хранилищ данных - http://citforum.ru/gazeta/3/
5. Великие раскопки и великие вызовы - http://www.kdnuggets.com/gpspubs/piatetsky-interview-computerra.pdf
Барсегян А.А., Куприянов М.С., Степаненко В.В., Холод И.И. - Технологии анализа данных. Data Mining, Visual Mining, Text Mining, OLAP (2-е издание)