Введение в технологию CUDA
Автор:Владимир Фролов
Источник: Электронный журнал "Компьютерная графика и мультимедиа" http://cgm.computergraphics.ru/issues/issue16/cuda
ОГЛАВЛЕНИЕ
1. Введение
2. Принципиальная разница между CPU и GPU
3. Ядро CUDA
4. Рекомендации по оптимизации
5. CPU/GPU переносимая математическая библиотека
6. Литература
1. Введение
Развитие вычислительных технологий последние десятки лет шло быстрыми темпами. Настолько быстрыми, что уже сейчас разработчики процессоров практически подошли к так называемому "кремниевому тупику". Безудержный рост тактовой частоты стал невозможен в силу целого ряда серьезных технологических причин.
Отчасти поэтому все производители современных вычислительных систем идут в сторону увеличения числа процессоров и ядер, а не увеличивают частоту одного процессора. Количество ядер центрального процессора (CPU) в передовых системах сейчас уже равняется 8.
Другая причина - относительно невысокая скорость работы оперативной памяти. Как бы быстро не работал процессор, узкими местами, как показывает практика, являются вовсе не арифметические операции, а именно неудачные обращения к памяти - кэш-промахи.
Однако если посмотреть в сторону графических процессоров GPU (Graphics Processing Unit), то там по пути параллелизма пошли гораздо раньше. В сегодняшних видеокартах, например в GF8800GTX, число процессоров может достигать 128. Производительность подобных систем при умелом их программировании может быть весьма значительной (рис. 1).

Рис. 1. Количество операций с плавающей точкой для CPU и GPU
Когда первые видеокарты только появились в продаже, они представляли собой достаточно простые (по сравнению с центральным процессором) узкоспециализированные устройства, предназначенные для того чтобы снять с процессора нагрузку по визуализации двухмерных данных. С развитием игровой индустрии и появлением таких трехмерных игр как Doom (рис. 2) и Wolfenstein 3D (рис. 3) возникла необходимость в 3D визуализации.
Рис. 2. Игра Doom

Рис. 3. Игра Wolfenstein 3D
Со времени создания компанией 3Dfx первых видеокарт Voodoo (1996 год) и вплоть до 2001 года в GPU был реализован только фиксированный набор операций над входными данными.
У программистов не было никакого выбора в алгоритме визуализации, и для повышения гибкости появились шейдеры - небольшие программы, выполняющиеся видеокартой для каждой вершины либо для каждого пиксела. В их задачи входили преобразования над вершинами и затенение - расчет освещения в точке, например по модели Фонга.
Хотя в настоящий момент шейдеры получили очень сильное развитие, следует понимать, что они были разработаны для узкоспециализированных задач трехмерных преобразований и растеризации.
В то время как GPU развиваются в сторону универсальных многопроцессорных систем, языки шейдеров остаются узкоспециализированными. Их можно сравнить с языком FORTRAN в том смысле, что они, как и FORTRAN, были первыми, но предназначенными для решения лишь одного типа задач. Шейдеры малопригодны для решения каких-либо других задач, кроме трехмерных преобразований и растеризации, как и FORTRAN не удобен для решения задач, не связанных с численными расчетами.
Сегодня появилась тенденция нетрадиционного использования видеокарт для решения задач в областях квантовой механики, искусственного интеллекта, физических расчетов, криптографии, физически корректной визуализации, реконструкции по фотографиям, распознавания и т.п. Эти задачи неудобно решать в рамках графических API (DirectX, OpenGL), так как эти API создавались совсем для других применений.
Развитие программирования общего назначения на GPU (General Programming on GPU, GPGPU) логически привело к возникновению технологий, нацеленных на более широкий круг задач, чем растеризация. В результате компанией Nvidia была создана технология Compute Unified Device Architecture (или сокращенно CUDA), а конкурирующей компанией ATI - технология STREAM.
Следует заметить, что на момент написания этой статьи, технология STREAM сильно отставала в развитии от CUDA, и поэтому здесь она рассматриваться не будет. Мы сосредоточимся на CUDA - технологии GPGPU, позволяющей писать программы на подмножестве языка C++.
2. Принципиальная разница между CPU и GPU
Рассмотрим вкратце некоторые существенные отличия между областями и особенностями применений центрального процессора и видеокарты.
2.1. Возможности
CPU изначально приспособлен для решения задач общего плана и работает с произвольно адресуемой памятью. Программы на CPU могут обращаться напрямую к любым ячейкам линейной и однородной памяти.
Для GPU это не так. Как вы узнаете, прочитав эту статью, в CUDA имеется целых 5 видов памяти. Читать можно из любой ячейки, доступной физически, но вот записывать – не во все ячейки. Причина заключается в том, что GPU в любом случае представляет собой специфическое устройство, предназначенное для конкретных целей. Это ограничение введено ради увеличения скорости работы определенных алгоритмов и снижения стоимости оборудования.
2.2. Быстродействие памяти
Извечная проблема большинства вычислительных систем заключена в том, что память работает медленнее процессора. Производители CPU решают ее путем введения кэшей. Наиболее часто используемые участки памяти помещается в сверхоперативную или кэш-память, работающую на частоте процессора. Это позволяет сэкономить время при обращении к наиболее часто используемым данным и загрузить процессор собственно вычислениями.
Заметим, что кэши для программиста фактически прозрачны. Как при чтении, так и при записи данные не попадают сразу в оперативную память, а проходят через кэши. Это позволяет, в частности, быстро считывать некоторое значение сразу же после записи [1].
На GPU (здесь подразумевается видеокарты GeForce восьмой серии) кэши тоже есть, и они тоже важны, но этот механизм не такой мощный, как на CPU. Во-первых, кэшируется не все типы памяти, а во-вторых - кэши работают только на чтение.
На GPU медленные обращения к памяти скрывают, используя параллельные вычисления. Пока одни задачи ждут данных, работают другие, готовые к вычислениям. Это один из основных принципов CUDA, позволяющих сильно поднять производительность системы в целом [2].
3. Ядро CUDA
3.1. Потоковая модель
Вычислительная архитектура CUDA основана на понятии мультипроцессора и концепции одна команда на множество данных (Single Instruction Multiple Data, SIMD).
Концепция SIMD подразумевает, что одна инструкция позволяет одновременно обработать множество данных. Например, команда addps в процессоре Pentium 3 и в более новых моделях Pentium позволяет складывать одновременно 4 числа с плавающей точкой одинарной точности.
Мультипроцессор - это многоядерный SIMD процессор, позволяющий в каждый определенный момент времени выполнять на всех ядрах только одну инструкцию. Каждое ядро мультипроцессора скалярное, т.е. оно не поддерживает векторные операции в чистом виде.
Перед тем как продолжить, введем пару определений. Отметим, что под устройством и хостом в данной статье будет пониматься совсем не то, к чему привыкло большинство программистов. Мы будем пользоваться такими терминами для того чтобы избежать расхождений с документацией CUDA.
Под устройством (device) в нашей статье мы будем понимать видеоадаптер, поддерживающий драйвер CUDA, или другое специализированное устройство, предназначенное для исполнения программ, использующих CUDA (такое, например, как NVIDIA Tesla). В этой статье мы рассмотрим GPU только как логическое устройство, избегая конкретных деталей реализации.
Хостом (host) мы будем называть программу в обычной оперативной памяти компьютера, использующую CPU и выполняющую управляющие функции по работе с устройством.
Фактически, та часть вашей программы, которая работает на CPU - это хост, а ваша видеокарта - устройство.
Логически устройство можно представить как набор мультипроцессоров (рис. 4) плюс драйвер CUDA.

Рис. 4. Устройство
Предположим, что мы хотим запустить на нашем устройстве некую процедуру в N потоках (то есть хотим распараллелить ее работу). В соответствии с документацией CUDA, назовем эту процедуру ядром.
Особенностью архитектуры CUDA является блочно-сеточная организация, необычная для многопоточных приложений (рис. 5). При этом драйвер CUDA самостоятельно распределяет ресурсы устройства между потоками.
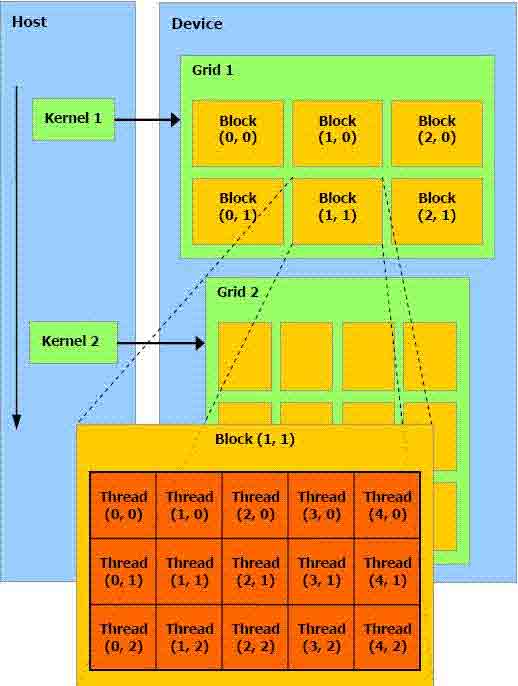
Рис. 5. Организация потоков
На рис. 5. ядро обозначено как Kernel. Все потоки, выполняющие это ядро, объединяются в блоки (Block), а блоки, в свою очередь, объединяются в сетку (Grid).
Как видно на рис 5, для идентификации потоков используются двухмерные индексы. Разработчики CUDA предоставили возможность работать с трехмерными, двухмерными или простыми (одномерными) индексами, в зависимости от того, как удобнее программисту. В общем случае индексы представляют собой трехмерные векторы. Для каждого потока будут известны: индекс потока внутри блока threadIdx и индекс блока внутри сетки blockIdx. При запуске все потоки будут отличаться только этими индексами. Фактически, именно через эти индексы программист осуществляет управление, определяя, какая именно часть его данных обрабатывается в каждом потоке.
Ответ на вопрос, почему разработчики выбрали именно такую организацию, нетривиален. Одна из причин состоит в том, что один блок гарантировано исполняется на одном мультипроцессоре устройства, но один мультипроцессор может выполнять несколько различных блоков. Остальные причины прояснятся дальше по ходу статьи.
Блок задач (потоков) выполняется на мультипроцессоре частями, или пулами, называемыми warp. Размер warp на текущий момент в видеокартах с поддержкой CUDA равен 32 потокам. Задачи внутри пула warp исполняются в SIMD стиле, т.е. во всех потоках внутри warp одновременно может выполняться только одна инструкция [2].
Здесь следует сделать одну оговорку. В архитектурах, современных на момент написания этой статьи, количество процессоров внутри одного мультипроцессора равно 8, а не 32. Из этого следует, что не весь warp исполняется одновременно, он разбивается на 4 части, которые выполняются последовательно (т.к. процессоры скалярные).
Но, во-первых, разработчики CUDA не регламентируют жестко размер warp. В своих работах они упоминают параметр warp size, а не число 32. Во-вторых, с логической точки зрения именно warp является тем минимальным объединением потоков, про который можно говорить, что все потоки внутри него выполняются одновременно — и при этом никаких допущений относительно остальной системы сделано не будет [3].
3.1.1. Ветвления
Сразу же возникает вопрос: если в один и тот же момент времени все потоки внутри warp исполняют одну и ту же инструкцию, то как быть с ветвлениями? Ведь если в коде программы встречается ветвление, то инструкции будут уже разные. Здесь применяется стандартное для SIMD программирования решение (рис 6).

Рис. 6. Организация ветвления в SIMD
Пусть имеется следующий код:
A; if(cond) B; else C; D;
В случае SISD (Single Instruction Single Data) мы выполняем оператор A, проверяем условие, затем выполняем операторы B и D (если условие истинно).
Пусть теперь у нас есть 10 потоков, исполняющихся в стиле SIMD. Во всех 10 потоках мы выполняем оператор A, затем проверяем условие cond и оказывается, что в 9 из 10 потоках оно истинно, а в одном потоке - ложно.
Понятно, что мы не можем запустить 9 потоков для выполнения оператора B, а один оставшийся - для выполнения оператора C, потому что одновременно во всех потоках может исполняться только одна инструкция. В этом случае нужно поступить так: сначала "убиваем" отколовшийся поток так, чтобы он не портил ничьи данные, и выполняем 9 оставшихся потоков. Затем "убиваем" 9 потоков, выполнивших оператор B, и проходим один поток с оператором C. После этого потоки опять объединяются и выполняют оператор D все одновременно [4].
Получается печальный результат: мало того что ресурсы процессоров расходуются на пустое перемалывание битов в отколовшихся потоках, так еще, что гораздо хуже, мы будем вынуждены в итоге выполнить ОБЕ ветки.
Однако не все так плохо, как может показаться на первый взгляд. К очень большому плюсу технологии можно отнести то, что эти фокусы выполняются динамически драйвером CUDA и для программиста они совершенно прозрачны. В то же время, имея дело с SSE командами современных CPU (именно в случае попытки выполнения 4 копий алгоритма одновременно), программист сам должен заботиться о деталях: объединять данные по четверкам, не забывать о выравнивании, и вообще писать на низком уровне, фактически как на ассемблере [5].
Из всего вышесказанного следует один очень важный вывод. Ветвления не являются причиной падения производительности сами по себе. Вредны только те ветвления, на которых потоки расходятся внутри одного пула потоков warp. При этом если потоки разошлись внутри одного блока, но в разных пулах warp, или внутри разных блоков, это не оказывает ровным счетом никакого эффекта.
3.1.2. Взаимодействие между потоками
На момент написания этой статьи любое взаимодействие между потоками (синхронизация и обмен данными) было возможно только внутри блока. То есть между потоками разных блоков нельзя организовать взаимодействие, пользуясь лишь документированными возможностями.
Что касается недокументированных возможностей, ими пользоваться крайне не рекомендуется. Причина этого в том, что они опираются на конкретные аппаратные особенности той или иной системы.
Синхронизация всех задач внутри блока осуществляется вызовом функции __synchtreads. Обмен данными возможен через разделяемую память, так как она общая для всех задач внутри блока [2].
3.2. Память
В CUDA выделяют пять видов памяти (рис. 7). Это регистры, локальная, глобальная, разделяемая, константная и текстурная память. Такое обилие обусловлено спецификой видеокарты и первичным ее предназначением, а также стремлением разработчиков сделать систему как можно дешевле, жертвуя в различных случаях либо универсальностью, либо скоростью.

Рис. 7. Виды памяти в CUDA
3.2.1. Регистры
По возможности компилятор старается размещать все локальные переменные функций в регистрах. Доступ к таким переменным осуществляется с максимальной скоростью. В текущей архитектуре на один мультипроцессор доступно 8192 32-разрядных регистра. Для того чтобы определить, сколько доступно регистров одному потоку, надо разделить это число (8192) на размер блока (количество потоков в нем).
При обычном разделении в 64 потока на блок получается всего 128 регистров (существуют некие объективные критерии, но 64 подходит в среднем для многих задач).
Если учесть, что на одном мультипроцессоре может исполняться несколько блоков, то для большей эффективности надо стараться занимать меньше 64 или даже меньше 32 регистров. Тогда теоретически может быть запущено 4 блока на одном мультипроцессоре. Однако здесь еще следует учитывать объем разделяемой памяти, занимаемой потоками, так как если один блок занимает всю разделяемую память, два таких блока не могут выполняться на мультипроцессоре одновременно [2].
3.2.2. Локальная память
В случаях, когда локальные данные процедур занимают слишком большой размер, или компилятор не может вычислить для них некоторый постоянный шаг при обращении, он может поместить их в локальную память. Этому может способствовать, например, приведение указателей для типов разных размеров.
Физически локальная память является аналогом глобальной памяти, и работает с той же скоростью. На момент написания статьи не было никаких механизмов, позволяющих явно запретить компилятору использование локальной памяти для конкретных переменных. Так как проконтролировать локальную память довольно трудно, лучше не использовать ее вовсе (смотрите главу 4 "Рекомендации по оптимизации").
3.2.3. Глобальная память
В документации CUDA в качестве одного из основных достижений технологии приводится возможность произвольной адресации глобальной памяти. То есть можно читать из любой ячейки памяти, и писать можно тоже в произвольную ячейку (на GPU это обычно не так).
Однако за универсальность в данном случае приходится расплачиваться скоростью. Глобальная память не кэшируется. Она работает очень медленно, количество обращений к глобальной памяти следует в любом случае минимизировать. Глобальная память необходима в основном для сохранения результатов работы программы перед отправкой их на хост (в обычную память DRAM). Причина этого в том, что глобальная память - единственный вид памяти, куда можно что-то записывать.
Переменные, объявленные с квалификатором __global__, размещаются в глобальной памяти. Глобальную память также можно выделить динамически, вызвав функцию cudaMalloc(void* mem, int size) на хосте. Из устройства эту функцию вызывать нельзя. Отсюда следует, что распределением памяти должна заниматься программа-хост, работающая на CPU. Данные с хоста можно отправлять в устройство вызовом функции cudaMemcpy:
cudaMemcpy(void* gpu_mem, void* cpu_mem, int size, cudaMemcpyHostToDevice);
Точно таким же образом можно проделать и обратную процедуру:
cudaMemcpy(void* cpu_mem, void* gpu_mem, int size, cudaMemcpyDeviceToHost);
Этот вызов тоже осуществляется с хоста.
3.2.4. Разделяемая память
Разделяемая память - это некэшируемая, но быстрая память. Ее и рекомендуется использовать как управляемый кэш. На один мультипроцессор доступно всего 16KB разделяемой памяти. Разделив это число на количество задач в блоке, получим максимальное количество разделяемой памяти, доступной на один поток (если планируется использовать ее независимо во всех потоках).
Отличительной чертой разделяемой памяти является то, что она адресуется одинаково для всех задач внутри блока (рис. 7). Отсюда следует, что ее можно использовать для обмена данными между потоками только одного блока.
Гарантируется, что во время исполнения блока на мультипроцессоре содержимое разделяемой памяти будет сохраняться. Однако после того как на мультипроцессоре сменился блок, не гарантируется, что содержимое старого блока сохранилось. Поэтому не стоит пытаться синхронизировать задачи между блоками, оставляя в разделяемой памяти какие-либо данные и надеясь на их сохранность.
Переменные, объявленные с квалификатором __shared__, размещаются в разделяемой памяти:
__shared__ float mem_shared[N_THREADS];
Следует еще раз подчеркнуть, что разделяемая память для блока одна. Поэтому если нужно использовать ее просто как управляемый кэш, следует обращаться к разным элементам массива, например, так:
float x = mem_shared[threadIdx.x];
Где threadIdx.x — индекс x потока внутри блока.
3.2.5. Константная память
Константная память кэшируется, как это видно на рис. 4. Кэш существует в единственном экземпляре для одного мультипроцессора, а значит, общий для всех задач внутри блока. На хосте в константную память можно что-то записать, вызвав функцию cudaMemcpyToSymbol. Из устройства константная память доступна только для чтения.
Константная память очень удобна в использовании. Можно размещать в ней данные любого типа и читать их при помощи простого присваивания.
#define N 100 __constant__ int gpu_buffer[N]; void host_function() { int cpu_buffer[N]; ... cudaMemcpyToSymbol(gpu_buffer, cpu_buffer, sizeof(int)*N); } ... // __global__ означает, что device_kernel - ядро, которое может быть запущено на GPU __global__ void device_kernel() { int a = gpu_buffer[0]; int b = gpu_buffer[1] + gpu_buffer[2]; //gpu_buffer[3] = a; ОШИБКА! константная память доступна только для чтения }
Так как для константной памяти используется кэш, доступ к ней в общем случае довольно быстрый. Единственный, но очень большой недостаток константной памяти заключается в том, что ее размер составляет всего 64 Kбайт (на все устройство). Из этого следует, что в контекстной памяти имеет смысл хранить лишь небольшое количество часто используемых данных.
3.2.6. Текстурная память
Текстурная память кэшируется (рис. 4). Для каждого мультипроцессора имеется только один кэш, а значит, этот кэш общий для всех задач внутри блока.
Название текстурной памяти (и, к сожалению, функциональность) унаследовано от понятий «текстура» и «текстурирование». Текстурирование - это процесс наложения текстуры (просто картинки) на полигон в процессе растеризации. Текстурная память оптимизирована под выборку 2D данных и имеет следующие возможности:
- быстрая выборка значений фиксированного размера (байт, слово, двойное или учетверенное слово) из одномерного или двухмерного массива
- нормализованная адресация числами типа float в интервале [0,1].
- аппаратная линейная или билинейная (в случае 2D) интерполяция соседних значений в случае нормализованной адресации
- аппаратная обработка выхода за границу массива с использованием двух режимов: clamp и wrap (не путать с пулами потоков warp!)
Текстурная память физически не отделена от глобальной памяти. Выделив функцией cudaMalloc некий участок глобальной памяти, можно затем указать с помощью функции cudaBindTexture, что данный участок теперь будет рассматриваться как текстурная память.
Это хорошая новость, так как она означает, что размер текстурной памяти ограничивается только максимальным размером памяти, которую может выделить устройство (а это обычно сотни мегабайт).
Но есть и плохая новость. Из текстурной памяти можно читать данные только встроенных в nvcc типов, имеющих размер 1, 2, 4, 8 или 16 байт, и только с помощью специальных функций - tex1D, tex2D или tex1Dfetch, tex2Dfetch. Иначе говоря, нельзя сделать указатель на текстурную память и разыменовать его произвольным образом (например, прочитав какую-либо структуру размером в 26 байт).
В случае с константной памятью так делать было можно, и поэтому обращения к константной памяти в коде выглядят вполне приемлемо и никак не выделяются. Для того чтобы воспользоваться объектом или структурой в текстурной памяти, его придется сначала оттуда выбрать (с помощью функции tex1Dfetch, например) в регистровую или разделяемую память, и уж затем только использовать.
Теперь подробнее про возможности. Нормализованная адресация - это адресация числом с плавающей точкой от 0 до 1.
При нормализованной адресации на финальной стадии производится дискретизация float индекса. В этой ситуации можно либо выбрать ближайший элемент, либо провести интерполяцию между соседними элементами.
Интерполяцию можно использовать только в том случае, если текстура выбирается значениями float. При этом допускаются векторизованные типы и типы, отличные от типов с плавающей точкой.
Например, можно создать текстуру с элементами uchar4, находящимися в интервале [0,255]. Затем можно их выбирать, используя нормализованную адресацию. Результатом будет значение типа float4, отображенное в интервал [0,1). Здесь используется стандартное математическое обозначение для интервала, где 0 включается, а 1 - нет.
Обработку выхода за границы массива можно сделать в двух режимах wrap и clamp. При использовании режима clamp происходит «схлопывание» значения до ближайшей границы. В режиме wrap координаты заворачиваются таким образом, что если координата x выходит за границу массива на N, то будет взят N-ый элемент массива. Т.е. фактически всегда берется остаток от деления на размер массива. Следует отметить, что это свойство текстурной памяти весьма полезно для реализации хэш-таблиц.
#define N 1024 // намеренно выбран тип uint4, встроенный в nvcc, так как он имеет максимально // возможный размер для текстурной выборки. Это позволяет сократить количество выборок uint4* gpu_memory; texture<uint4, 1, cudaReadModeElementType> texture; void host_function() { uint cpu_buffer[N]; ... cudaMalloc((void**) &gpu_memory, N*sizeof(uint4)); // выделим память в GPU // настройка параемтров текстуры texture texture.addressMode[0] = cudaAddressModeWrap; // режим Wrap texture.addressMode[1] = cudaAddressModeWrap; texture.filterMode = cudaFilterModePoint; // ближайшее значение texture.normalized = false; // не использовать нормализованную адресацию cudaBindTexture(0, texture, gpu_memory,N) // отныне эта память будет считаться текстурной cudaMemcpy(gpu_memory,cpu_buffer,N*sizeof(uint4),cudaMemcpyHostToDevice); // копируем данные на GPU } ... // __global__ означает, что device_kernel - ядро, которое нужно распараллелить __global__ void device_kernel() { uint4 a = tex1Dfetch(texture,0); // можно выбирать данные только таким способом ! uint4 b = tex1Dfetch(texture,1); int c = a.x * b.y; ... }
3.3. Простой пример
В качестве простого примера предлагается рассмотреть программу cppIntegration из CUDA SDK. Она демонстрирует приемы работы с CUDA, а также использование nvcc (специальный компилятор подмножества С++ от Nvidia) в сочетании с MS Visual Studio, что сильно упрощает разработку программ на CUDA.
4. Рекомендации по оптимизации
4.1. Правильно проводите разбиение вашей задачи
Не все задачи подходят для SIMD архитектур. Если ваша задача для этого не пригодна, возможно, не стоит использовать GPU. Но если вы твердо решили использовать GPU, нужно стараться разбить алгоритм на такие части, чтобы они могли эффективно выполняться в стиле SIMD. Если нужно - измените алгоритм для решения вашей задачи, придумайте новый - тот, который хорошо бы ложился на SIMD. Как пример подходящей области использования GPU можно привести реализацию пирамидального сложения элементов массива [6].
4.2. Выбор типа памяти
Помещайте свои данные в текстурную или константную память, если все задачи одного блока обращаются к одному и тому же участку памяти или к близко расположенным участкам. Двухмерные данные могут быть эффективно обработаны при помощи функций text2Dfetch и text2D. Текстурная память специально оптимизирована под двухмерную выборку.
Используйте глобальную память в сочетании с разделяемой памятью, если все задачи обращаются бессистемно к разным, далеко расположенным друг от друга участкам памяти (с сильно различными адресами или координатами, если это 2D/3D данные). Скопируйте данные из глобальной памяти в разделяемую, обработайте их там, а затем скопируйте результаты из разделяемой памяти обратно в глобальную.
4.3. Разделяемая память вместо локальной
Если компилятор Nvidia по какой-то причине расположил данные в локальной памяти (обычно это заметно по очень сильному падению производительности в местах, где ничего ресурсоемкого нет), выясните, какие именно данные попали в локальную память, и поместите их в разделяемую память (shared memory).
Зачастую компилятор располагает переменную в локальной памяти, если она используется не часто. Например, это некий аккумулятор, где вы накапливаете значение, рассчитывая что-то в цикле. Если цикл большой по объему кода (но не по времени выполнения!), то компилятор может поместить ваш аккумулятор в локальную память, т.к. он используется относительно редко, а регистров мало. Потеря производительности в этом случае может быть заметной.
Если же вы действительно редко используете переменную - лучше явным образом поместить ее в глобальную память.
Хотя автоматическое размещение компилятором таких переменных в локальной памяти может показаться удобным, на самом деле это не так. Непросто будет найти узкое место при последующих модификациях программы, если переменная начнет использоваться чаще. Компилятор может перенести такую переменную в регистровую память, а может и не перенести. Если же модификатор __global__ будет указан явно, программист скорее обратит на это внимание.
4.4. Разворачивание циклов
Разворачивание циклов представляет собой стандартный прием повышения производительности во многих системах. Суть его в том, чтобы на каждой итерации выполнять больше действий, уменьшив таким способом общее число итераций, а значит и количество условных переходов, которые должен будет выполнить процессор [1].
Вот как можно развернуть цикл нахождения суммы массива (например, целочисленного):
int a[N];
int summ;
for(int i=0; i<N/4; i++)
{
summ += a[i+0];
summ += a[i+1];
summ += a[i+2];
summ += a[i+3];
}
Разумеется, циклы можно развернуть и вручную (как показано выше), но это малопроизводительный труд. Гораздо лучше использовать шаблоны С++ в сочетание со встраиваемыми функциями.
template <int n,class T> class ArraySumm { __device__ static T exec(const T* arr) { return arr[0] + ArraySumm<n-1,T>(arr+1); } } template <class T> class ArraySumm<0,T> { __device__ static T exec(const T* arr) { return 0; } } for(int i=0;i<N/4;i++) { summ+= ArraySumm<4,int>::exec(a); }
Следует отметить одну интересную особенность компилятора nvcc. Компилятор всегда будет встраивать функции типа __device__ по умолчанию (чтобы это отменить, существует специальная директива __noinline__) [2].
Следовательно, можно быть уверенным в том, что пример, подобный приведенному выше, развернется в простую последовательность операторов, и ни в чем не будет уступать по эффективности коду, написанному вручную. Однако в общем случае (если не используется компилятор nvcc) в этом уверенным быть нельзя, так как inline - это всего-лишь рекомендация компилятору, которую он может проигнорировать. Поэтому не гарантируется, что ваши функции будут встраиваться.
4.5. Выравнивание данных и выборка по 16 байт
Выравнивайте структуры данных по 16-байтовой границе. В этом случае компилятор сможет использовать для них специальные инструкции, выполняющие загрузку данных сразу по 16 байт.
Если структура занимает 8 байт или меньше, можно выравнивать ее по 8 байт. Но в этом случае можно выбрать сразу две переменные за один раз, объединив две 8-байтовые переменные в структуру с помощью union или приведения указателей. Приведением следует пользоваться осторожно, так как компилятор может поместить данные в локальную память, а не в регистры.
4.6. Конфликты банков разделяемой памяти
Разделяемая память организована в виде 16 (всего-то!) банков памяти с шагом в 4 байта. Во время выполнения пула потоков warp на мультипроцессоре, он делится на две половинки (если warp-size = 32) по 16 потоков, которые осуществляют доступ к разделяемой памяти по очереди.
Задачи в разных половинах warp не конфликтуют по разделяемой памяти. Из-за того что задачи одной половинки пула warp будут обращаться к одинаковым банкам памяти, возникнут коллизии и, как следствие, падение производительности. Задачи в пределах одной половинки warp могут обращаться к различным участкам разделяемой памяти с определенным шагом.
Оптимальные шаги — 4, 12, 28, ..., 2n-4 байт (рис. 8).
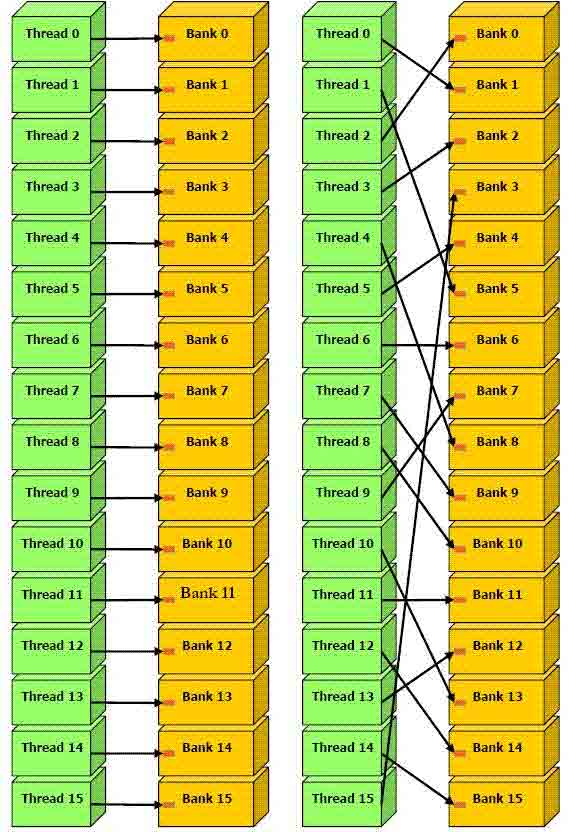
Рис. 8. Оптимальные шаги

Рис. 9. Не оптимальные шаги
4.7. Минимизация перемещений данных Host-Device
Старайтесь как можно реже передавать промежуточные результаты на host для обработки с помощью CPU. Реализуйте если не весь алгоритм, то, по крайней мере, его основную часть на GPU, оставляя CPU лишь управляющие задачи.
5. CPU/GPU переносимая математическая библиотека
Автором этой статьи написана переносимая библиотека MGML_MATH для работы с простыми пространственными объектами, код которой работоспособен как на устройстве, так и на хосте.
Библиотека MGML_MATH может быть использована как каркас для написания CPU/GPU переносимых (или гибридных) систем расчета физических, графических или других пространственных задач. Основное ее достоинство в том, что один и тот же код может использоваться как на CPU, так и на GPU, и при этом во главу требований, предъявляемых к библиотеке, ставится скорость.
На сайте http://www.ray-tracing.ru вы можете найти подробную информацию о библиотеке MGML_MATH и примеры ее использования.
6. Литература
1. Крис Касперски. Техника оптимизации программ. Эффективное использование памяти. - Спб.: БХВ-Петербург, 2003.
3. CUDA Programming Guide 1.1. page 14-15
4. CUDA Programming Guide 1.1. page 48
5. Alex Klimovitski. Using SSE and SSE2: Misconceptions and Reality
6. О пирамидальном сложении на параллельной архитектуре