Тестування баз даних корпоративних інформаційних систем
Автор: Левченко О.Ю.
Источник: электронный архив Донецкого национального технического университета
Автор: Левченко О.Ю.
Источник: электронный архив Донецкого национального технического университета
У статті показано, що для підвищення продуктивності КІС методом налаштування параметрів конфігурації СУБД необхідно виконувати навантажне тестування. Представлено імітаційний підхід до побудови моделі тестування БД. Розписана методика побудови тесту та тестування БД із застосуванням імітаційної моделі. Для перевірки достовірності отриманих результатів тестування запропоновано використовувати довірчий інтервал та довірчу ймовірність.
З метою підвищити продуктивність корпоративних інформаційних систем (КІС) методом налаштування параметрів конфігурації систем керування базами даних (СКБД), що обслуговують ці КІС, необхідно досліджувати вплив різних конфігурацій параметрів на продуктивність БД досліджуваної КІС [1]. Навантажне тестування СКБД дозволяє фіксувати показники продуктивності із заданим робочим навантаженням в різних діапазонах зміни конфігураційних параметрів СКБД. Аналіз результатів тестування дозволить підібрати такі значення параметрів конфігурації СКБД, що забезпечать підвищення продуктивності БД КІС в заданих реальних умовах функціонування системи.
Одним з методів побудови моделі тестування БД КІС є імітаційне моделювання [2]. Модель описує реальну БД, включаючи структуру таблиць, дані, запити користувачів з урахуванням послідовності і частоти їх виникнення.
Методика тестування СКБД включає 3 етапи:
Етап формування моделі включає збір інформації про стан БД на момент часу P0 (структура таблиць, зв'язки між ними і наповнення таблиць). При цьому, з метою скорочення ресурсів в процесі тестування, таблиці з однаковою структурою об'єднуються під новими іменами. Потім виконується збір інформації щодо здійснених запитів Q = {q1, q2,..,qn} у досліджуваний період часу. Синтаксичний розбір (парсинг) журналу транзакцій дозволяє сформувати шаблони запитів та класифікувати їх, що дозволить абстрагуватися від смислового значення імен таблиць та поєднати запити з однаковою структурою реляційних операцій. Класифікація включає віднесення шаблонів запитів з безлічі Q до одного з класів, що описуються еталонами шаблонів. На основі зібраної інформації про структуру таблиць і їх наповнення створюється ІМТ БД.
На етапі моделювання досліджується вплив різних значень параметрів конфігурації СКБД з множини:
де pi, i=1, n – найменування параметру конфігурації, vi – поточне значення параметру pi. За початковим набором параметрів конфігурації P0 фіксуються характеристики загальної продуктивності БД: для усієї множини запитів Q – показник Hp0, для окремих запитів – Hp0qi. Потім виконується їх порівняння з новими характеристиками Hpi та Hpiqi, що було отримано у ході моделювання із набором параметрів pi. Моделювання виконується доки Hpiqi > Hpi-1qi-1. Щоб виключити ситуацію, коли ефект від застосування найкращого набору параметрів Hpopt (отриманого в ході ітерацій моделювання) може статися меншим, ніж при заміні значення окремого параметру, виконується порівняння показників продуктивності: сумарного Hpopt та за окремими параметрами Hpi. Отримані таким чином погоджені значення параметрів конфігурації зберігаються у базі знань у вигляді рекомендацій щодо зміни значень параметрів для КІС заданого класу. Алгоритм тестування наведено на рис. 1.

Характеристики, що отримано в процесі тестування, необхідно оцінювати з погляду достовірності. Важливим також є питання щодо кількості експериментів, що виконуються: їх недостатня кількість призводить до зниження достовірності отриманих характеристик, тоді як збільшення кількості експериментів вимагає більшої кількості ресурсів, що призводить до зниження продуктивності. Для оцінки точності й надійності отриманої характеристики пропонується використовувати інструментарій математичної статистики: довірчий інтервал та довірчу вірогідність. У такому разі достовірною вважається така характеристика, яка потрапляє в інтервал lB , заздалегідь розрахований виходячи з довірчої вірогідності B, що задається дослідником:
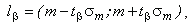
де m – математичне очікування, o – середньоквадратичне відхилення оцінки m; tB – (t- критерій) статистичний показник, визначається значенням довірчої вірогідності B та числом ступенів свободи за таблицями розподілів Стьюдента.
Запропонована методика дозволяє проаналізувати міру впливу кожного окремого параметру конфігурації БД на загальну продуктивність КІС. Аналіз впливу на продуктивність окремих груп запитів (шаблонів) дозволить додатково зробити висновок про необхідність подальшого їх використання в імітаційній моделі БД
Для оцінки достовірності отриманих характеристик пропонується розраховувати довірчий інтервал по заданій довірчій вірогідності.
Для реалізації запропонованої методики розроблено комплекс програмних засобів, що реалізовує алгоритми тестування параметрів налаштування СКБД, побудовані із застосуванням наведеної методики тестування. Розроблений модуль тестування дозволяє змінювати значення вибраних параметрів конфігурації у заданому діапазоні із заданим кроком та виконувати тестування для обраного робочого навантаження (кількість клієнтів, що симулюються, коефіцієнт масштабування, кількість транзакцій та ін.). В ході експерименту з використанням цього комплексу було протестоване 14 параметрів налаштування СКБД PostgreSQL. Було отримано рекомендації щодо налаштування параметрів конфігурації СКБД, що обслуговує КІС деканату студентів.
[1] Блажко А.А. Модели для автоматизированной оптимизации производительности СУБД / А.А. Блажко, А.Ю. Левченко, А.С. Пригожев // Радіоелектронні і комп’ютерні системи. – ХАІ, Харків, 2010. – No7(48). – С. 24-29.
[2] Зиноватная С.Л., Задачи имитационного моделирования реляционных баз данных/ С.Л.
Зиноватная, А.Б. Кунгурцев, А.А. Мунзер // Труди XI международної науково-практичної
конференції «Сучасні інформаційні та електронні технології» (СИЭТ-2010). – Одеса, 2010.
– Том1. – С. 118.