УДК 04.9
Донецкий национальный технический университет
ИСПОЛЬЗОВАНИЕ ПАРАЛЛЕЛЬНЫХ АРХИТЕКТУР ПРИ
ПРОГНОЗИРОВАНИИ МОДЕЛИРОВАНИЯ ПОВЕДЕНИЯ
ДВИЖУЩЕГОСЯ ОБЪЕКТА
Аннотация
Супонин О.О., Кривошеев С.В.Использование параллельных архитектур при прогнозировании моделирования поведения движущегося объекта. В данной статье рассматривается актуальность использования параллельной архитектуры при расчетах и прогнозировании поведения движущегося объекта, а так же, непосредственно, краткий обзор параллельной архитектуры.
Ключевые слова: моделирование, CUDA, MPI, MIMD, движущиеся объекты.
Введение. На сегодняшний день актуальной является тема прогнозирования поведения движущихся объектов. Технический прогресс сделал большой шаг вперед и сегодня создается огромное множество проектов, таких как космические корабли, морские суда, авиалайнеры, поезда, ракеты, автомобили и другие движущиеся объекты, которые необходимо отслеживать в пространстве и выполнять всевозможные операции контроля и управления. Поэтому для всех этих объектов необходимо уметь рассчитывать и прогнозировать траекторию и характеристику движения.
Актуальность прогнозирования поведения движущегося объекта. Актуальность прогнозирования и поведения моделей движущегося объекта заключается в том, что необходимо заранее знать и уметь рассчитывать и просчитывать поведение объекта в зависимости от внешних факторов и установок пользователя. Это позволяет решить проблемы временного ограничения, когда необходимо за доли секунд рассчитать и определить положение объекта.
Общие параллельные архитектуры и реализации. Однако, имея обычную вычислительную систему, расчет координат, векторов движения является довольно проблематичным в связи с большим объемом данных и немалым количеством вычислительных преобразований с матрицами. На помощь в этих расчетах приходят супер компьютеры. Супер компьютеры представляют собой большое число высокопроизводительных серверных компьютеров, связанных высокоскоростной магистралью. Для достижения максимальной производительности выполняется распараллеливание вычислительных задач на отдельные процессоры, потоки. Существуют различные архитектуры супер компьютеров, такие как MIMD (Multiple Instruction stream, Multiple Data stream - Множественный поток Команд, Множественный поток Данных ), CUDA(Compute Unified Device Architecture), а так же параллельные реализации через различные интерфейсы (MPI – message passing interface – интерфейс передачи сообщений). [1]
MIMD. MIMD – архитектура компьютера, которая используется для
достижения параллельных вычислений. Вычислитель имеет несколько
процессоров, которые функционируют асинхронно и независимо. Различные
процессоры в любой момент могут выполнять различные команды над
различными частями данных.
MIMD архитектуры далее классифицируются в зависимости от
физической организации памяти, то есть имеет ли процессор свою
собственную локальную память и обращается к другим блокам памяти, используя коммутирующую сеть, или коммутирующая сеть подсоединяет все процессоры к общедоступной памяти. Исходя из организации памяти,
различают следующие типы параллельных архитектур:
Компьютеры с распределенной памятью (Distributed memory)
Процессор может обращаться к локальной памяти, может посылать и получать
сообщения, передаваемые по сети, соединяющей процессоры. Сообщения
используются для осуществления связи между процессорами или, что
эквивалентно, для чтения и записи удаленных блоков памяти. В
идеализированной сети стоимость посылки сообщения между двумя узлами
сети не зависит как от расположения обоих узлов, так и от трафика сети, но зависит от длины сообщения [2]
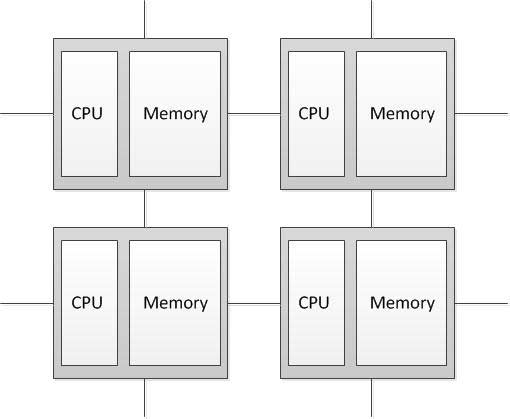
Рисунок 1 – Структура компьютера с распределенной памятью
MPI. MPI - программный интерфейс для передачи информации, который позволяет обмениваться сообщениями между процессами, выполняющими одну задачу.
MPI является наиболее распространённым стандартом интерфейса обмена данными в параллельном программировании, существуют его реализации для большого числа компьютерных платформ. Используется при разработке программ для кластеров и супер компьютеров. Основным средством коммуникации между процессами в MPI является передача сообщений друг другу.
В первую очередь MPI ориентирован на системы с распределенной памятью, то есть когда затраты на передачу данных велики.
Базовым механизмом связи между MPI процессами является передача и
приём сообщений. Сообщение несёт в себе передаваемые данные и
информацию, позволяющую принимающей стороне осуществлять их
выборочный приём:
1. отправитель - ранг (номер в группе) отправителя сообщения;
2. получатель - ранг получателя;
3. признак - может использоваться для разделения различных видов
сообщений;
4. коммуникатор - код группы процессов.
Операции приёма и передачи могут быть блокирующимися и не блокирующимися. Для не блокирующихся операций определены функции проверки готовности и ожидания выполнения операции.
CUDA. CUDA - программно-аппаратная архитектура параллельных вычислений, которая позволяет существенно увеличить вычислительную производительность благодаря использованию графических процессоров фирмы NVIDIA.
В архитектуре CUDA используется модель памяти грид, кластерное моделирование потоков и SIMD-инструкции. Применима не только для
высокопроизводительных графических вычислений, но и для различных
научных вычислений с использованием видеокарт nVidia. Ученые и
исследователи широко используют CUDA в различных областях, включая
астрофизику,вычислительную биологию и химию, моделирование динамики
жидкостей, электромагнитных взаимодействий, компьютерную томографию,
сейсмический анализ и многое другое. В CUDA имеется возможность
подключения к приложениям, использующим OpenGL и Direct3D. CUDA -
кросс платформенное программное обеспечение для таких операционныхсистем как Linux, Mac OS X и Windows.
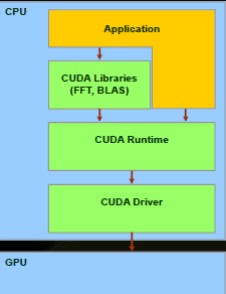
Рисунок 2 - Общая структура устройства CUDA [3]
Актуальность использования супер компьютеров, а соответственно и параллельной архитектуры, при прогнозировании поведения движущегося объекта заключается в необходимости в кротчайшие сроки производить расчеты движения объекта, его траектории пути и поведения объекта в зависимости от внешних факторов, таких как ветер, скорость течения воды или человеческих, а именно ускорение, торможение движущегося объекта. При разработке модели поведения движущегося объекта крайне важна скорость вычисления, поэтому и необходимо повышать эффективность этих вычислений. Это является основной и актуальной задачей.
Список литературы
1. Parallel Computer Architecture: A Hardware/Software Approach (The Morgan Kaufmann Series in Computer Architecture and Design), Callifornia, 1999, 1025c
2. MIMD – архитектура. Электронный ресурс. Режим доступа:
http://www.ccas.ru/paral/mimd/mimd.html
3. CUDA. Электронный ресурс. Режим доступа:
http://www.nvidia.ru/object/what_is_cuda_new_ru.html