| noun | Wine |
| [a/an] noun | a wine |
| noun(s) | Wines |
| cardinal noun(s) | three grapes |
| the/this noun | the wine |
| the noun of [the] noun | the sender of the message |
| pronouns | it has … |
| all [the] noun(s) | all [the] wines |
| each/every noun | each message |
| reference and reference | a color and a body |
The reference sublanguage is what makes the language we propose different in relation to the language mentioned in Pulman’s works [20]. There, he emphasizes that the sentences he calls notation in macro style (which are similar to the ones proposed in the metalanguage sublanguage) do not have flexibility. He uses examples such as: A subtype is_a type, where the elements between ... can only be objects. The metalanguage proposed here is formed by similar sentences, but we allow for users to work with complex objects in a natural way, including the use of ellipses and anaphors, which gives us a profit in the usability of the language. Thus, our language will be closer to the one users is accustomed to use to express themselves. For example, if an expert introduced the element book in a previous sentence as in A book is a publication, s/he will be able to reference it in other future sentences, by using the pronoun “it”, as for example, It has chapters and sections.
The metalanguage sublanguage we propose makes extensive use of the reference sublanguage and is used to define the domain’s ontology itself. Each sentence allowed in the metalanguage has a purpose in the definition of the domain’s ontology. Below we present the types of metalanguage sentences and we also show the purpose of two sentences, and one example of the usage and the syntax of the metalanguage.
Sentences of the metalanguage sublanguage for the definition of classes:
1a) Ref1 ‘is a kind of’ Ref2* ‘.’
2b) Ref1 ‘is a’ Ref2* ‘.’
2a) Ref1 ‘is a kind of’ Ref2* ‘that has’ Ref3 ‘.’
2b) Ref1 ‘is a’ Ref2* ‘that has’ Ref3 ‘.’
3) Ref1 (‘is part of’ | ‘are parts of’) Ref2* ‘.’
4) Ref1 (‘has’|‘have’) ‘at least one’ Ref2 ‘that must be’ Ref3* ‘.’
5a) Ref1 Ref2 ‘must be’ Ref3* ‘.’
5b) Ref2 ‘of’ Ref1 ‘are’ Ref3* ‘.’
6) Ref1 ‘of’ Ref2 ‘must be’ Ref3 ‘.’
7) Ref1 ‘must have exactly’ Ref2 ‘.’
8) Ref1 ‘must have at least’ Ref2 ‘.’
9) Ref1 ‘must have at most’ Ref2 ‘.’
10) Ref1 ‘can only be’ Ref2 ‘.’
11) Ref1 ‘is also known as’ Ref2*+ ‘.’
Sentence for the definition of properties and values to the properties: therefore
12) Ref1* (‘has’ | ‘have’) Ref2 ‘.’
13) Ref1&(‘is’ | ‘are’) Ref2# ‘.’
14) Ref1& ‘has possible values’ Ref2 ‘.’
15) Ref1* ‘has’ Ref2 ‘, with possible’ (‘value’ | ‘values’) Ref3 ‘.’
16) Ref1* ‘has’ Ref2 ‘, which is’ Ref3# ‘.’
17) Ref1 ‘has default value’ Ref2 ‘.’
18) Ref1+ ‘of’ Ref2 ‘is’ Ref3 ‘.’
Examples of the Usage of the Sentences
1) Sentences of type 4: Ref1 (‘has’|‘have’) ‘at least one’ Ref2 ‘that must be’ Ref3* ‘.’
Purpose: to define a class by means of a value restriction for a property. The restriction determines that all elements of a class (Ref1) that have at least one element of another class (Ref3) as a value for a property (Ref2) belong to this class. Thus, this restriction requires that at least one value for the property (Ref2) belong to a given class (Ref3) so that it belongs to the class that is being defined (Ref1). Other values can exist for the property that are not elements of the given class (Ref3).
• A wine has at least one maker that must be a winery;
• All wines have at least one maker that must be a winery.
2) Sentences of type 13: Ref1&(‘is’ | ‘are’) Ref2# ‘.’
Purpose: sentences of this type can be used for two purposes: a) to define a type (Ref2) to a property (Ref1) that has already been defined; and b) to define an instance (Ref1) of a class.
a) The maker is a winery.
b) W1 is a wine.
— The differentiation between the two intentions will be done by using the structure of the reference Ref1. In type a sentences the defining article “the” will be used as a anaphoric determiner [21], that is, with the purpose of making reference to an entity of the discourse that has already been defined in the ontology. Thus, every time Ref1 is a defined reference, we are defining a type for a property that already exists in the ontology; otherwise, we will be introducing a new instance of a class in the ontology. Sentences of the type a are normally used after a definition of a property, using the sentences of type 2, 4, 5, 6, 7, 8, 9 or 12.
3. The Automatic Mapping of the Proposed Language to the OWL
The mapping of the CNL proposed here for a KRT begins by the implementation of a parser for this language. One of the main points in this task is the process of anaphor resolution. To solve the anaphors correctly, we have to consider the set of sentences that composes our codified description as a discourse in which one sentence can reference entities that have been introduced in previous sentences. We adopt as an intermediate discourse representation schema the Discourse Representation Theory (DRT) [13], a different representation for the first order logic that deal with discourses and offers methods for anaphors and presuppositions resolution in a sufficiently attractive way. For the parser implementation, we used a parser (in Prolog language) for a wide subset of the English grammar developed by Blackburn e Bos [3]. That parser maps NL to Discourse Representation Structures (DRSs), solve the anaphors and ellipsis and deals with presuppositions naturally.
We decide to use the OWL as the formal language for ontology building mainly because it has become a standard in Semantic Web. Moreover, there are good reasoners available to it like RACER and PELLET . The OWL language [16] has ways to represent semantics about a domain and also to make this representation available to be processed by means of software applications. OWL entails three sublanguages which combine a balance between expressiveness and efficient reasoning — OWL Full, OWL DL and OWL Lite. In our research, we chose OWL DL as the KRT to which the language we propose is mapped.
Mapping the sentences first to DRSs results in a good advantage because from there we can map them for different KRTs, only mapping a formal language (the DRS) to another formal language (a KRT). This is simpler than working with CNL. Thus, after the text in CNL is processed by the parser, the resulting DRSs are processed by an algorithm that maps them to OWL. Although we choose OWL-DL, from the three sublanguages of OWL, our proposed language does not deal with: some characteristics of RDF Schema (rdfs:subPropertyOf, rdfs:domain, DifferentFrom, AllDifferent); some characteristics of properties (InverseOf, TransitiveProperty, SymmetricProperty, FunctionalProperty, InverseFunctionalProperty); some axioms of class (disjointWith), and some boolean combinations for the description class (unionOf, complementOf, intersectionOf). This happens because we are trying to find simple and natural sentences that can represent these OWL constructors in CNL. Other researches with similar aims have had the same problems [24]. However, some constructors like boolean combinations should be deal with in the next version of the proposed CNL.
Now, we present, as examples, the mapping of two metalanguage sentences to the resulting OWL code. We chose to use example sentences instead of generic sentences to facilitate the understanding. The underlined elements are elements that are being introduced in the ontology and, therefore, do not belong to the lexicon yet.
Example 1: Sentences of type 4 used for the definition of a class by means of a property restriction.
• A wine has at least one makerthat must be a winery
Resulting OWL mapping:

Example 2: Sentences of type 13 used for the definition of a type to a property.
a) The maker is a winery.
Resulting OWL mapping:

b) W1 is a wine.
Resulting OWL mapping:

<
4. The Ontology Editing Environment
As we mentioned before, we believe domain experts will have less difficulties to express their knowledge by means of a controlled natural language than if they have to do it using a KRT. In order to assist the interaction between experts and the knowledge base even further, we propose the use of a process-driven editor, which suggests a sequence of actions to the building of ontologies and, at the same time, filters the sentences, from the metalanguage sublanguage, that are valid in the current situation and the sentence elements which must be used in each step of the process. This editor is an adaptation of Godoi [8] and Oliveira’s [17] work.
The editor we propose is formed by an editing area — in which the text which represents the ontology is written; an area which represents the ontology building process (that is implemented as a hierarchical state machine) and indicates the phase of the process the user is in; and an explanation area which can, for example, show users the meaning of the sentence which is being written for the ontology. Fig. 1 shows the editor’s interface.
In the text area, users can use the right button of the mouse and may choose from a list of templates, which represent the sentences which are currently possible to be used to edit the ontology. The main advantage of using templates is that users do not need to learn all the details of the specification language.
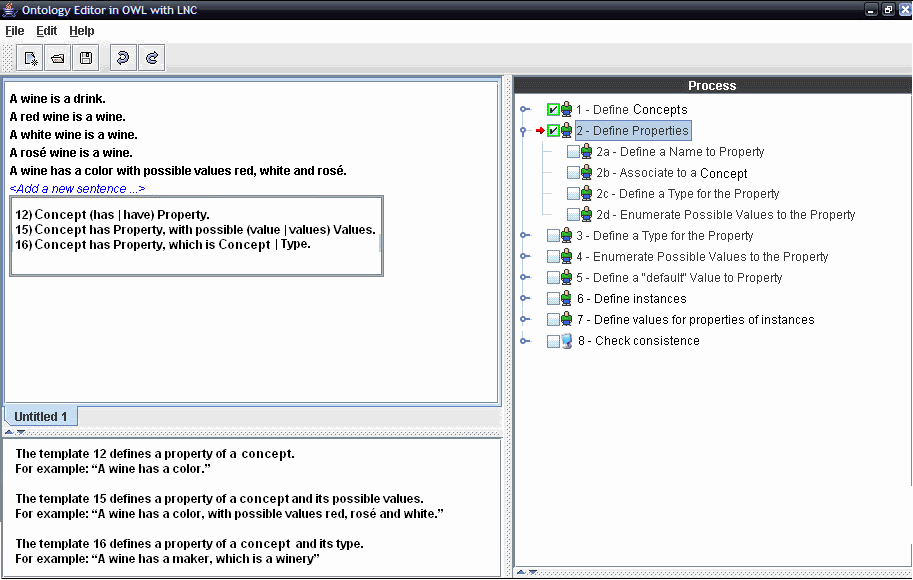
The editor makes the templates of permitted sentences in the language available and the users choose the one they want. From this point onwards, the references of this sentence can be filled in so that it is actually processed by the parser. At this stage, the editor has an intense interaction with the knowledge base, because according to the sentence which is chosen by the user, the base needs to be consulted and the elements which can be used by the user to fulfill the references must be made available by means of pop-up menus. This approach prevents users from making common mistakes as, for example, using the name of a non-existent class, or using the name of a class instead of a property. Besides that, we can pre-process the DRSs which correspond to each of the templates, lowering the processing which is necessary to map the sentences to OWL. Thus, the DRSs would only be used to solve anaphors and presuppositions.
The templates which are available in this editor correspond to the sentences which are part of the proposed metalanguage sublanguage. However, instead of using the elements “Ref”, as a name for the references, we use the ontology elements which are expected in each of them (e.g. concept, property, types, values, etc.), so that users can understand them more easily.
5. Results and Conclusions
The ontology editors we know of are mostly aimed at being used by knowledge engineers, or experts with some experience in the ontology building area. As shown by Perez [18], they usually use the KRT in which the ontology will be codified, besides graphic resources which are made available by the editor as a means of Fig. 1. Ontology editor interface. communication between the tool and its user. This type of communication is not efficient for our purposes, as our idea is to allow domain experts to use the tool in order to place their knowledge in the system directly and they frequently have no knowledge of a KRT.
Other researches have the same or a similar aim as ours. The Attempto project [7] presents an approach which is similar to ours. It also makes use of a CNL, called ACE, as an interface to knowledge representation. It is an incremental project that was originally defined to create software requirement specifications and has evolved to be applied to represent general knowledge as well. The Schwitter’s [22] approach, which is derived from the Attempto project, also makes use of a CNL as an interface between the user and the KRT. In this approach, users begin by entering the text and the editor suggests the syntactic structures which should come next, keeping the controlled aspect of the language. If a sentence is not part of the lexicon, users have the option of extending it, by means of a lexical editor. Ambiguous sentences will be reported to users so that they can decide on the meaning of each of them. Users can also add a word or modify the content of the lexicon using a specific interface which requires minimal linguistic knowledge.
Although the CNL proposed in this paper presents limitations if compared with Attempto [7], we may easily broaden its expressiveness in future works. Comparing to Schitter’s [22] work, which builds sentences in a similar way to ours, we may say that the expressiveness of the CNL which he proposed is similar to ours. Although he covers some OWL-DL elements which we do not, for example, sentences which allow for the representation of the characteristics of a property (e.g., a property being transitive, inverse or symmetrical), he does not cover other elements which we do as, for example, the representations of the existential quantificator (some ValuesFrom), of the equivalence of instances, of the enumeration of members of a class, and of the cardinality restrictions. What’s more, some sentences which are proposed by Schwitter are not very natural for a lay user as, for example, the sentence ‘ObjectProperty’ has the range ‘class’ which can be instantiated to A maker has the range winery. In our language, the same purpose would be achieved by means of the sentence The maker is a winery. As the property maker should have been defined before the definition of its value range, we know that maker is a property and winery is its range of possible values.
As for the lexical extension issue, the editor we propose presents advantages in relation to the proposals we have discussed above, because it allows for the automatic inclusion of nouns, since the declaration of a new entity in the ontology is automatically translated in the inclusion of a new noun in the lexicon. The inclusion of elements of other parts of speech such as verbs, adjectives, etc., has not been considered yet, but these elements can be treated in a similar way.
The process-driven ontology editor we propose partially limits the users’ expression when it comes to specifying the knowledge base, making them follow a partial sequence in order to define the elements of the ontology. This approach of making users utilize an element which is in the pop-up menus has the following benefits: 1) preventing experts from making mistakes which are very common such as to refer to an element which does not yet exist in the ontology; 2) helping users to remember the elements which have already been defined in the ontology, thus reducing the cognitive burden on users and 3) preventing experts from making reference to a class instead of a property, which would imply in a mistake in the language mapping phase. Another interesting fact is that the use of templates allows for, as a secondary effect, the pre-processing of the sentences (i.e., their pre-parsing), making the use of an explicit parser almost unnecessary.
There are other forms to implement the ontology building process which reduce the demands of ordering and give users more freedom of speech as, for example, using late evaluation. However, the ideal balance between the potential of the user’s freedom of speech, the cost of implementing the parser and the cognitive burden on users can only be identified after a detailed assessment of the editor’s usability, enlightening which approach is best.
The proposal of an ontology building process which is associated to a specification language represents a step forward when compared to the Attempto project and to Schwitter’s work, as they do not consider a process like this to guide experts in this task. Another ontology editor, called DOE (Differential Ontology Editor) [5], which is aimed at knowledge engineers, suggests some steps which should be followed in the ontology specification process. This editor requires that users define a complete taxonomy for the elements in the ontology so that they can later define the implied restrictions. In this sense, our process is more flexible. If users find it necessary to define a subclass, and soon after, want to define its properties, possible value range and its restrictions as well, they can do it.
Thus, our proposal was to make it possible for domain experts to build a knowledge base. This proposal entailed the definition of a controlled natural language, its mapping to a KRT and the proposal of a process-driven editor. To make sure that the CNL we presented here is easily used and learnt by experts, we need to carry out usability tests regarding both the language and the editor-language set, which is a future goal of this research. Moreover, in the future, we intend to make a comparison between our proposal and the main current ontology editors like Protege , SWOOP , etc., to make it possible to combine textual and graphical representations. Also, if we consider the possibility of expressing procedural knowledge, we need to broaden the set of templates which are available to the users and define a mapping to a rule language, like SWRL. The same type of language may be used in the specification of business rules in the web semantic, making this type of task accessible to lay users.
References:
1. ALMEIDA, M. B. Linguagens utilizadas na construcao de ontologias. Available in: http://www.eci.ufmg.br/mba/p1_2_2.html. On: 25 abr. 2005
2. ALTWARG, R. (2000). Controlled languages: an introduction. Macquarie University, Graduate Program in Speech and Language Processing.
Macquarie, Available in: http://www.shlrc.mq.edu.au/masters/students/raltwarg/clwhatisa.htm. On: 22 jun. 2004.
3. BLACKBURN, P.; BOS, J. (1999) Representation and inference for natural language: a first course in computational semantics. Universitat des Saarlandes. V.2 – Working with discourse representation structure. Available in: http://www.cogsci.ed.ac.uk/~jbos/comsem/book2.html. On: 21 jul. 2004.
4. DA SILVA, S. R. P. (2001) Um modelo semiotico para programacao por usuarios finais. Tese (Doutorado) - Departamento de Informatica, PUC-Rio Janeiro, Rio de Janeiro.
5. DOE. Differential ontology editor. Available in: http://opales.ina.fr/public/. On: 21 jun. 2005
6. ECO, U. (1976) Theory of semiotics. Bloomington: Indiana: University Press
7. FUCHS, N. E.; SCHWERTEL, U.; SCHWITTER, R. (1999) Attempto Controlled English – not just another logic specification language. In: LNCS 1559. Springer pages 1–20.
8. GODOI, M. S. (2004) Implementacao de Uma Interface para o Ambiente de Extensoes para Aplicacoes Extensiveis. Relatorio Tecnico. Maringa: DIN, UEM Brasil. 22 p.
9. GRUBER, TOM. (1996) What is an ontology? Available in: http://www.ksl.stanford.edu/kst/what-isan-ontology.html. On: 15 set. 2004.
10. GUARINO, N. (1995) Formal ontology, conceptual analysis and knowledge representation. International Journal of human and Computer Studies, v. 43 n. 5/6.
11. HALL, A. (1990) Seven myths of formal methods. IEEE Software, v. 48, n. 1, pgs 67–79.
12. HOEFLER, S. (2004) The syntax of Attempto Controlled English: an abstract grammar for ACE 4.0. Technical report. Zurich: Department of informatics, University of Zurich, Switzerland.
13. KAMP, H. (1981) A theory of truth and semantic representation. In: GROENENDIJK, J. et al. (Ed.). Formal methods in the study of languages Foris, Amsterdam: Mathematisch Centrum.
14. KNUMBLAUCH, H. (2004) Editing OWL ontologies with Protege. Stanford University. Available in: http://protege.stanford.edu/plugins/owl/publications/2004-07-06-OWLTutorial.ppt On: 24 fev. 2005.
15. LYONS, J. (1981) Language and Linguistics: an introduction. Cambridge, UK: Cambridge University Press.
16. MCGUINESS, D. L.; HARMELEN, F. (2003) OWL web ontology language - overview. Available in:http:www.w3.org/TR/2003/PR-owl-features-20031215, On: 10 jan. 2004
17. OLIVEIRA, E. M. (2004) Integracao e Implementacao de um Ambiente de Extensao para Aplicacoes Extensiveis. 51 f. Monografia de Graduacao – DIN, UEM, Maringa, jan. 2004.
18. PEREZ, A. G. et al. (2002) A survey on ontology tools. OntoWeb. Available in: http://ontoweb.aifb.uni-karlsruhe.de/About/Deliverables/D13_v1-0.zip. On: 23 jun. 2005.
19. PEIRCE, C.S. Collected papers. Cambridge: Ma. Harvard University Press. (Excerpted in BUCHLER, J., ed., Philosophical Writings of Peirce. New York: Dover, 1955).
20. PULMAN, S.G. (1996) Controlled Language and Knowledge Representation. In: Proceedings of International Workshop on Controlled Language Applications, 1., Belgium. Belgium: Katholieke Universiteit Leuven. pages 233-242.
21. QUIRK, R. (1972) et al. A grammar of contemporary English. 1st ed. Essex, UK: Longman Group. ISBN 0 582 52444 X.
22. SCHWITTER R. (2005) Controlled natural language as interface language to the semantic web. Sydney, Australia: Centre for Language Technology Macquarie Universit.
23. SCHWITTER, R. (2004) Representing knowledge in controlled natural language: a case study. In: NEGOITA, M. G.; HOWLETT, R. J.; JAIN, L. C. (Ed.). Knowledge-based intelligent information and engineering systems. In: Proceedings of international conference, KES, 8. Wellington., New Zealand, pages 711-717, Sep. 2004, Part I, Springer LNAI 3213.
24. KAAREL KALJURAND and NORBERT E. FUCHS. Bidirectional mapping between OWL DL and Attempto Controlled English. In Fourth Workshop on Principles and Practice of Semantic Web Reasoning, Budva, Montenegro, 2006.