
Abstract
Content
- Introduction
- 1. Theme urgency
- 2. Goal and tasks of the research
- 3. Expected scientific innovation
- 4. Review of existing algorithms for constructing the weighted sample
- 4.1 Аlgorithm STOLP
- 4.2 Аlgorithm FRiS-STOLP
- 4.3 Аlgorithm NNDE
- 5. The method of sampling w-objects
- Conclusion
- References
- Important note
Introduction
Recognition systems are finding increasing application in the area of daily life (e-mail, library, internet access, voice control system). Recognition system is in medicine, anti-virus computer protection in video surveillance systems.
Signs of recognized objects are constantly changing, making it difficult to recognize and correct classification. This brings up the question of the development of such systems, with minimal changes that could detect objects with the same high reliability as before, that is, to adapt to new conditions. Such systems are called adaptive recognition systems [11].
The ability to self-adaptive systems is due to the fact that all the detected changes in the state have already studied objects are added to the training set. Before you add a new feature, you need to determine if it should be added. With each new element added as the need arises to adjust the existing classification decision rules, and in the case of global differences – still a need for new dictionary characters [1].
1. Theme urgency
Most modern applications to be solved by the construction of the recognition systems, characterized by a large volume of raw data and the ability to add new data is already in the process of systems. That is why the basic requirements for a modern detection systems are adaptability (the ability of the system in the process of changing their characteristics, and for the recognition of learning systems – correct classification decision rules, changing the environment), work in real time (the possibility of formation of classification decisions for a limited time) and high efficiency classification for linearly separable and overlapping classes in the feature space [5].
Adding new objects being for most applications sufficiently intense, results in a significant increase in the size of the training sample, which in turn leads to:
- The increase in the time adjustment of decision rules (especially if used teaching method requires the construction of a new decision rule, rather than the partial adjustment);
- Deterioration in the quality of the solutions due to the problem of retraining on samples of large volume.
These features adaptive learning recognition systems make the necessary pre-processing training samples by reducing their size.
2. Goal and tasks of the research
The purpose of the final work is to develop a master algorithm for constructing the weighted temporal training samples in adaptive recognition systems. In operation, the need to solve the following tasks:
- Тo investigate the existing algorithms for the weighted training samples;
- To investigate methods of using the weighted training samples in adaptive recognition systems;
- To develop an algorithm for constructing the weighted temporal training samples in adaptive recognition systems;
- To develop a prototype of a software system testing of algorithms for constructing the weighted temporal training samples in adaptive recognition systems;
- Perform a comparative analysis of the proposed algorithm and the known algorithms for solving this problem.
3. Expected scientific innovation
Scientific novelty of this work is to develop a method for constructing weighted temporal training samples in adaptive recognition systems. As the growth in the size of training sample leads to an increase in training time and the deterioration of its quality, it is assumed that on the basis of weighted temporal samples can be built an efficient algorithm to select a subset of samples of actual objects and removing the rest.
4. Review of existing algorithms for constructing the weighted sample
4.1 Аlgorithm STOLP
Let a training set
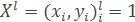
where xi – objects, yi=y*(xi) – classes that belong to these objects.
Furthermore, given the metric ρX*X→R, such that the compactness of the hypotheses. In the classification of objects metric classifier
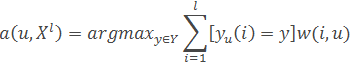
for example, the nearest neighbor method to calculate the distance from the classified object to all objects of the training sample. The time spent on this for each of the classified object is proportional to the size of the training set. In addition, it appears necessary to store large amounts of data [8].
But not all objects are equivalent training set. Among them are the most typical representatives of the class, that is, the standards; uninformative objects when deleting that the quality of the training set classification does not change, emissions or noise objects – objects that are in the midst of a "foreign" class, only worsening the quality of the classification [7].
It is therefore necessary to reduce the amount of training sample, leaving only the reference objects for each class.
The standards – is a subset of the sample Xl, that all objects Xl (or most of them) are classified correctly when used as a training sample set of standards.
Standards of i -th class in the classification of the nearest neighbor method can serve as a subset of objects Xl the class that the distance from any object belonging to him from the sample to the nearest "their" standard is less than the nearest "foreign" reference.
A simple case for the selection of standards is not effective, as the number of ways to select for t эstandards for each class (the class number of k) is П(j=1)kCtmj.
The amount of risk (W ) — a quantity characterizing the degree of risk to the object to be classified in the wrong class to which it belongs.
When using the nearest neighbor method can be considered
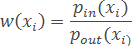
where pin – distance from the object xi to its closest object (or reference) of "their" class; pout – to the nearest object (or reference) "foreign" class.
When using either method, you can put a metric

where M(xi,μ)=Гyi - max(y∈Y\yi) Гy(xi) – indentation at the site xi in the training set μ (μ – set of standards).
Furthermore, depending on the method of classification, we can choose other risk evaluation value. The main thing is that they take large values on objects, emissions, lower – at facilities located on the border of the class, and even less – on the objects that are in the depths of his class [4].
The input to the algorithm is applied sample Xl, allowable error rate l0, cutoff emissions δ, classification algorithm, and the formula for calculating the amount of risk W.
You must first drop the emissions (objects Xl, W >δ), then form an initial approximation μ – of sampling sites Xl, choose one of each class with objects of this class of maximum risk value or a minimum value of risk.
Further built up a lot of standards (as the number of sampling sites Xl, recognized properly, will not be less than l0,). Then classify objects Xl, using as a training set μ, count the amount of risk for all objects Xl \μ, taking into account the changes in the learning sample. Among the objects of each class detected correctly, objects selected with the maximum value of risk and add to μ.
As a result, a lot of standards μ∈Xl, for each class represents a collection of objects located on the border of the class, and if the initial approximation selected objects with a minimum amount of risk, one object at the center of the room.
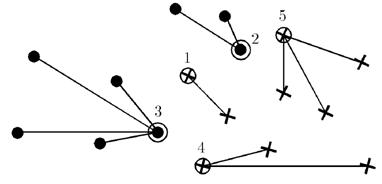
Picture 1 – The result of the algorithm STOLP
4.2 Аlgorithm FRiS-STOLP
The algorithm FRiS-STOLP – algorithm selection of reference objects for the metric classifier based on FRiS-function. From classical algorithm STOLP it features the use of auxiliary functions [10].
Function NN(u,U) returns the nearest object u from the set U.
Function FindEtalon (xy,μ) from a set of existing standards μ and set Xy members of the class Y, returns a new standard for the class Y the following algorithm:
- For each object x∈Xy evaluated two characteristics – "defense" and "tolerance" (as far as the object in a class reference standards does not prevent other classes) of the object:
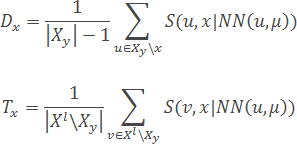
- Based on the computed performance "efficiency" of the object x:
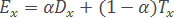
- Function FindEtalon returns an object x∈Xl with maximum efficiency Ex:
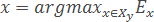
Parameter α∈[0,1] quantitatively determines the relative "importance" of the characteristics of objects ("defense" and "tolerance"). Can be selected based on the specifics of a particular task.
4.3 Аlgorithm NNDE
The method of nearest neighbors – the simplest metric classifier, based on the evaluation of the similarity of objects.
Classed object belongs to the class which owns the nearest objects to it training sample. In problems with two classes of number of neighbors take odd that there have been situations of ambiguity, when the same number of neighbors belong to different classes. In problems with a number of classes of 3 or more odd does not help, and the ambiguity of the situation can still occur. Then the i -th neighbor assigned weight w, usually decreasing with increasing neighbor rank i. The object belongs to the class that is gaining greater total weight of the nearest neighbors [9].
Given a training set of pairs "object–response" Xm={(x1,y1),…,(xm,ym)}.
On the set of objects defined function of the distance ρ(x,x′). This function should be sufficiently adequate model of similarity of objects. The higher the value of this function, the less similar the two objects are (x,x′).
For any object u arrange the objects of training set xi ascending distances u: ρ(u,x1;u)≤ρ(u,x2;u)≤...≤ρ(u,xm;u) where a xi;u indicated by the object of training sample, which is the i-th neighbor of the object u. Introduce a similar notation for the answer to the i-th neighbor: yi;u. Thus, any object u generates a renumbering of the sample.
In the most general form of the nearest-neighbor algorithm is:
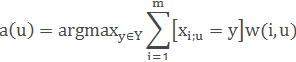
where w(i,u) — given weight function, which evaluates the degree of importance of the i -th neighbor to classify object u. It is natural to assume that this function is non-negative and non-increasing in i.
By setting different weighting function can receive various embodiments of the method of nearest neighbors.
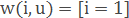 – simple nearest neighbor method.
– simple nearest neighbor method.
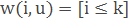 – method of k nearest neighbors.
– method of k nearest neighbors.
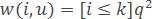 – method exponentially weighted k nearest neighbors where it is supposed q<1.
– method exponentially weighted k nearest neighbors where it is supposed q<1.
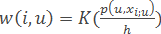 – method parzen window fixed width h.
– method parzen window fixed width h.
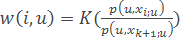 – method parzen window of variable width.
– method parzen window of variable width.
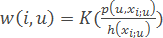 – method potential functions, wherein the width of the window h(xi) зdepends not classified object and object of the training xi.
– method potential functions, wherein the width of the window h(xi) зdepends not classified object and object of the training xi.
Here K(r) – given a non-negative monotonically increasing function on [0,∞), kernel smoothing.
5. The method of sampling w-objects
The above algorithms do not allow for the sampling density distribution of objects in the feature space and the dynamics of change of attribute values to add. Using this approach, we can reduce the key elements of the sample.
To avoid this, you can use the method of reduction of the sample by constructing a weighted sample w-objects [2], that allows for the reduction of training set for non-worsening of the quality of the classification. Also, this method solves the problem of adding new objects in the sample with a minimal increase of its size.
The basis of the method of constructing a weighted training set w-objects to reduce the large volume of samples in adaptive recognition systems is the choice of sets of close ups of the original sample, and their replacement by a weighted object of a new sample. The values of the new features of each object are the centers of mass of the sample values of the attributes of the objects of the original sample, which it replaces. Introduced an additional parameter – the weight is defined as the number of objects in the original sample, which were replaced by another object of the new sample. The proposed method is aimed at reducing both the initial training set, and the analysis of the need to adjust the sample and the rapid implementation of this adjustment when replenishing the sample during operation.
The initial data for the proposed method will take a set of objects M, called the training sample. Each object Xi from M described by a system ofn attributes Xi={xi1,xi2,...,xin}, and represented by a point in the linear feature space Xi∈Rn. For each object Xi known for its classification yi∈[1,l], l – the number of classes in the system.
Building w-object consists of three successive stages:
- The construction of the image of the set Wf, contains a number of objects d of the original sample belonging to the same class;
- Forming a vector XiW={xi1,xi2,...,xin}, feature values w-object XiW and the calculation of its weight pi ;
- Adjustment of the initial training set – removing objects included in the image of the set X=X \Wf.
Construction of the image of the set Wf consists in finding a starting point Xf1 w-forming object, defining the competing point Xf2 and choosing to form a set of Wf such objects in the original sample, the distance to each of which the starting point is smaller than their distance from the point of contention. The starting point Xf1 w-forming object, use the object of the original training set, the most remote of all the objects of other classes. Competing point Xf2 chosen by finding the nearest Xf1 object that does not belong to the same class as itself Xf1, that is yf1≠yf2.
For the case of two classes of site selection {Xf1,Xf2,...,Xd} forming a plurality of Wf carried out by the following rule: the object Xi included in Wf, where:
- It belongs to the same class as the starting point Xf1;
- Distance from the object in question to the start point Xf1 less than before the contention point Xf2;
- Distance Ri,1 of the object in question to the start point is less than the distance Ri,2 of the object in question to the point of competing and less than the distance R1,2 between the primary and competing points (for the case where the classes are composed of several separate areas of the feature space).
Thus, the image of the set Wf formed by the rule:
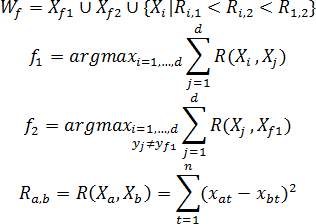
Characteristic values {xi1,xi2,...,xin} new w-object XiW are formed by the image of the set Wf and calculated the coordinates of the center of mass of pf=|Wf|material points (assuming that the objects of the original training set in feature space are material points, have a mass equal to 1), where |Wf| – cardinality of the set Wf
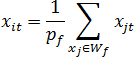
After the formation of the next w-object, all objects forming his set are removed from the original training set X=X\Wf. The algorithm completes its work when the original training set there will be no object X∈∅ [3].

Picture 2 – Building w-object (animation)
The principle of forming images of the set, selecting closely spaced objects in the feature space is an effective way of dividing the sample into groups. Introduction weights can not only store information on the number of replaceable objects, but also to characterize the region in which these objects reside. Based on this, it is effective to use the weighted training samples w-objects to solve the problem of constructing the weighted temporal samples in adaptive recognition systems.
Conclusion
In this paper, various algorithms have been investigated to reduce the samples in adaptive recognition systems. Such algorithms as STOLP, FRiS-STOLP easy to implement, but give a large error in the solution of problems with large amounts of input data, the algorithm NNDE hardly suited for solving such problems [6]. In comparison with these algorithms, group method of data gives much better results because of its flexibility and ability to change the parameters of the algorithm to the specific conditions of the problem.
On the basis of the described algorithms to reduce the adaptive sampling, it was concluded that the group method of data is the most flexible, versatile and is best suited for modification to meet the challenges of building the weighted temporal samples in adaptive recognition systems.
References
- Александров А.Г. Оптимальные и адаптивные системы. / А.Г. Александров – М.: Высшая школа, 1989. – 263 с.
- Волченко Е.В. Расширение метода группового учета аргументов на взвешенные обучающие выборки w-объектов / Е.В. Волченко // Вісник Національного технічного університету "Харківський політехнічний інститут". Збірник наукових праць. Тематичний випуск: Інформатика i моделювання. – Харків: НТУ "ХПІ", 2010. – № 31. – С. 49 – 57.
- Волченко Е.В. Метод сокращения обучающих выборок GridDC / Е.В. Волченко, И.В. Дрозд // Штучний інтелект. –2010. – №4. – С. 185-189.
- Глушков В.М. Введение в кибернетику. / В.М. Глушков – К.: Изд-во АН УССР, 1964. – 324 с.
- Горбань А.Н. Обучение нейронных сетей. / А.Н. Горбань – М.: СП ПараГраф, 1990. – 298 с.
- Горелик А.Л. Методы распознавания. Учебное пособие для вузов. / А.Л. Горелик, В.А. Скрипкин – М.: Высшая школа, 1977 – 222 с.
- Кокрен У. Методы выборочного исследования. / У. Кокрен – М.: Статистика, 1976. – 440 с.
- Советов Б.Я. Моделирование систем. / Б.Я. Советов, С.А. Яковлев – М.: Высшая школа, 1985. – 271 с.
- Тынкевич М.А. Численные методы анализа. / М.А. Тынкевич – Кемерово: КузГТУ, 1997. – 122 с.
- Алгоритм FRiS-STOLP [Электронный ресурс]. – Режим доступа: http://www.machinelearning.ru/
- Теория распознавания образов [Электронный ресурс]. – Режим доступа: http://ru.wikipedia.org/
Important note
The master's work is not completed yet. Final completion is on December, 2013. Full work text and subject materials can be obtained from the author or her adviser after this date.