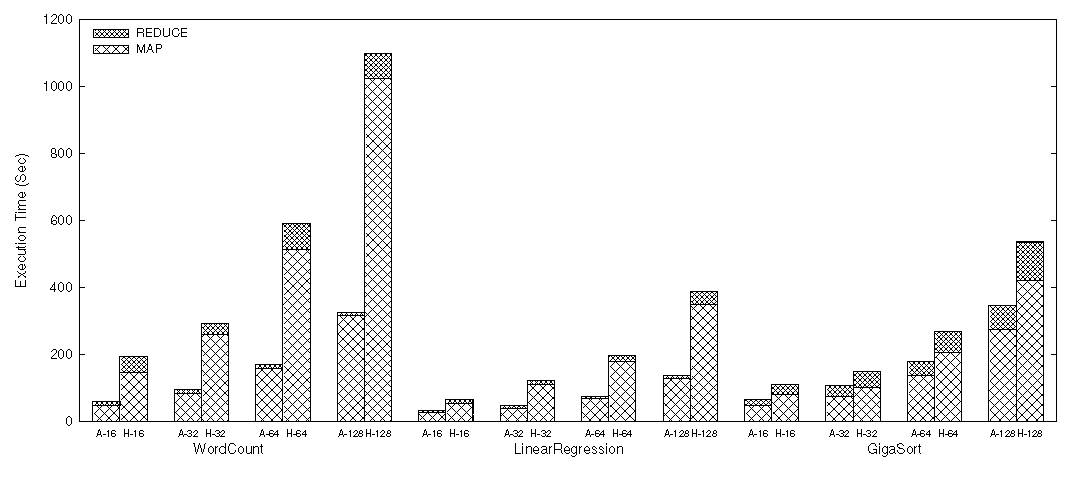
Рисунок 2. Общая производительность WordCount, LinearRegression и GigaSort.
Источник: http://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf
Иерархический подход к максимизации эффективности
MapReduce
Zhiwei Xiao, Haibo Chen, Binyu Zang
Parallel Processing Institute, Fudan University {zwxiao, hbchen, byzang@ftidan.edu.cn
Перевод: Чуприн В.И.
I. Введение
Парадигма MapReduce[1] была широко известна своей гибкой масштабируемостью и отказоустойчивостью, с относительным пренебрежением эффективностью, что, впрочем, столь характерно для облачных систем "оплата по-требованию", таких как Amazon, Elastic MapReduce. В статье утверждается, что есть несколько уровней локальности данных и параллелизма для типичных многоядерных кластеров, которые могут повлиять на производительность.
Характеризуя ограничение производительности типичных приложений MapReduce на многоядерных кластерах Hadoop, мы показываем, что текущая среда осованная на JVM (т.е. TaskWorker) не использует локальность данных и параллелизм задач на уровне одного узла.
В частности, реализация с открытым исходным кодом от MapReduce, Hadoop[2], использует JVM среду выполнения для запуска задач MapReduce, что неоптимально загружает иерархию кэшерования и существующий во многих многоядерных кластерах параллелизм на основе задач. Hadoop необходимы в качестве входных значений объекты ключ-значение при реализации интерфейса Hadoop Writable для поддержки сериализации и десериализации, являющиеся причиной создания дополнительных объектов и накладных расходов памяти.
Более того, некоторые приложения требуют обработки одинакового фрагмента данных многократно, чтобы получить окончательные результаты. Хотя Hadoop использует локальность данных внутри отдельной итерации путем перемещения вычислений к данным, к сожалению, он не учитывает локальность данных в рамках нескольких итераций обработки, и, следовательно, требует те же данные, загруженные несколько раз от сетевой файловой системы на узлы, которые обрабатывают данные.
На основании приведенных выше наблюдений, мы предлагаем Azwraith, иерархический подхода к MapReduce, нацеленный на максимальную локальность данных и паралелизм задач MapReduce в рамках Hadoop. В иерархической модели MapReduce Azwraith, каждая Map или Reduce задача, назначенная одному узлу рассматривается как отдельное MapReduce задание и разбивается на Map и Reduce задачи, которые обрабатываются с помощью среды выполнения MapReduce специально оптимизированной на одном узле. В частности, Azwraith интегрирует эффективню среду выполнения MapReduce (а именно Ostrich[3]) от многоядерных процессоров к Hadoop. Чтобы воспользоваться локальностью данных между узлами одного уровня в сети, Azwraith интегрирует систему которая кэширует данные в памяти, которые, вероятно, будут использованы снова, чтобы избежать ненужных сетевых и дисковых затрат.
II. Архитектура Azwraith
Вместо того чтобы писать новую среду выполнения с нуля, мы повторно использовали и адаптировали эффективную реализацию MapReduce для разделяемой многопроцессорной памяти на Hadoop, называемой Ostrich. Ostrich использует "стратегию окна" для MapReduce на многоядерных процессорах и агрессивно эксплуатирует параллелизм задач и локальность данных. Чтобы свести к минимуму сложность, Azwraith следует рабочему процессу Hadoop и оставляет большинство компонентов (например, TaskTracker, HDFS) нетронутыми. Hadoop с расширением Azwraith может также работать на оригинальной основанной на Java среде выполнения в обычном порядке.
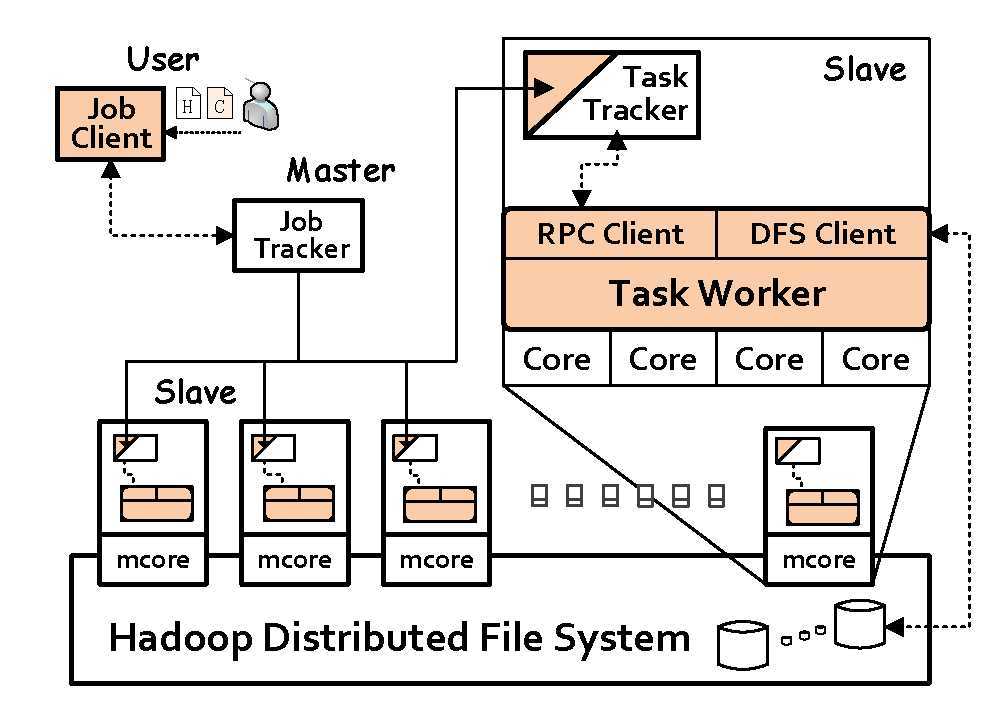
Рисунок 1. Архитектура Azwraith : сплошные (цветные) компоненты, которые должны быть скорректированы для Azwraith: Azwraith заменяет TaskWorker на Ostrich, который использует локальность данных и многоядерный параллелизм; RPC Client делает TaskWorker совместимым с протоколом RPC Hadoop и предоставляет доступ RPC к TaskWorker ", Клиент DFS предоставляет HDFS доступ для TaskWorker. Пользователь может отправить задание Azwraith или оригинальное Hadoop задание MapReduce с JobClient.
На рисунке 1 показана общая архитектура Azwraith, которая напоминает оригинальный Hadoop. Запуск заданий Azwraith также следует рабочему процессу в Hadoop. Клиент должен указать тип задания (Azwraith или Hadoop) перед отправкой на выполнение. TaskTracker, в зависимости от типа работы, может продублировать процесс (в случае задания Azwraith) или запустить экземпляр JVM (в случае задания Hadoop), чтобы выполнить поставленное задание.
Для адаптации среды выполнения Ostrich в TaskWorker из Hadoop, мы модифицировали Ostrich, чтобы соответствовать рабочему процессу и коммуникационным протоколам Hadoop, в том числе отчетам о состоянии и форматах вывода. Для связи с TaskTracker, новый TaskWorker встраивается в клиент RPC (Remote Procedure Call). Клиент RPC используется, чтобы сделать новый TaskWorker соответствовующим протоколу RPC Hadoop и предоставлять сервисы RPC TaskWorker. TaskWorker имеет доступ к HDFS (Hadoop Distributed File System) с клиентским модулем DFS, который перенаправляет обращения к HDFS.
Далее мы повысили производительность среды выполнения Azwraith при помощи нескольких оптимизаций. Во-первых, Azwraith перекрывает голодание CPU и I/O, чтобы скрыть блокировки I/O времени как можно эффективнее. Во-вторых, Azwraith может агрессивно повторно использовать данные в памяти между операциями, и таким образом избежать копирования большого объема памяти и наслаждаться хорошей локальностью кэша. В-третьих, Azwraith требуется от приложений реализоции комплекса агрегатных интерфейсов для (де)сериализации набора данных вместе, что позволяет экономить огромное количество вызовов функций и получить лучшую локальность данных, чем в Hadoop.
Рисунок 2. Общая производительность WordCount, LinearRegression и GigaSort.

Рисунок 3. Производительность Azwraith System Cache на K-Means
Чтобы включить повторное использование данных между задачами, мы спроектировали и реализовали сервер кэширования как процесс-демон на каждом подчиненном узле, для ослуживания всех доступов на чтение к HDFS. Кэш-сервер использует интерфейсы разделяемой памяти и механизм семафоров операционной системы, чтобы обеспечить управление клиентам кэша (то есть, TaskWorkers), которые обращаются к разделяемой памяти, управляемsй кэш-сервером на пути доступа к локальной памяти. Использование разделяемой памяти также увеличивает выгоду от использования памяти, так как все задачи на том же узле могут разделять одну единственную копию данных и, таким образом оставить больше памяти, доступной для кэширования и вычислений.
Мы также расширяем поддержку расписания Hadoop, для планирования задачи для узлов, где кэшируются входные данные. Azwraith отслеживает информацию о нахождении кэша, с отображением ее на информацию о нахождении данных для дисковой подсистемы Hadoop. При получении запроса на назначение задачи от подчиненного узла, планировщик сначала получает список Map задач для запрашивающего подчиненного узла, и назначит задачу для которой есть данные в локальном кеше, если таковые имеются. В противном случае, планировщик работает как обычно. Расширение к системе планирования, составляет около 50 строк кода изменений в Hadoop.
III. Оценка
Мы провели эксперименты на малом кластере из одного главного узла и 6 подчиненных узлов. Каждая машина была оснащена двумя 12-ядерными процессорами AMD Opteron, 64 Гб оперативной памяти и 4 SCSI жесткими дисками. Каждая машина подключена к общему коммутатору через 1Gb Ethernet. Мы использовали Hadoop версии 0.20.1 который был запущен на Java SE 1.6.0. Azwraith также был построен для той же версии Hadoop.
Как показано на рисунке 2, Azwraith получает существенное ускорение над Hadoop при различных размерах входных данных, начиная от 1,4 x до 3,5 x. Задачи, ориентированные на вычисления, такие как WordCount и LinearRegression получили больший прирост скорости, чем I/O ресурсоемкие приложений ввода/вывлда такие как GigaSort.
Как показано на рисунке 3, при поддержке системы кэширования, Azwraith получает 1.43X для 1.55X ускорения над Azwraith без кэширования, и 2.06X для 2.21X над Hadoop.
IV. Заключение
В этой статье, мы утверждали, что Hadoop имеет ограничения в эксплуатации локальных данных и параллелизма задач для многоядерных платформ. Затем мы расширили Hadoop иерархической схемой MapReduce. Схема кэширования в памяти также интегрируется для кэширования данных, которые, вероятно, будут доступны в памяти. Оценка показала, что иерархическая схема превосходит Hadoop от 1.4x до 3.5x.
Ссылки
[1] J. Dean and S. Ghemawat, “MapReduce: simplified data processing on large clusters,” Communications of the ACM, vol. 51, no. 1, pp. 107-113, 2008.
[2] A. Bialecki, M. Cafarella, D. Cutting, and O. OMalley, “Hadoop: a framework for running applications on large clusters built of commodity hardware,” http://lucene. apache. org/hadoop, 2005.
[3] R. Chen, H. Chen, and B. Zang, “Tiled mapreduce: Optimizing resource usages of data-parallel applications on multicore with tiling,” in Proc. PACT, 2010.