Analysis of methods for constructing a custom portrait of the Internet. Identify the basic principles of personalization based on user logs.
Введение
Задача персонализации - одна из важных задач в улучшении эффективности работы интернет ресурса. Персонализация дает возможность решить множество практических задач. Это задачи о подборе информации; кластеризации пользователей; формировании тематической направленности; прогнозировании;
Построение портрета пользователя необходимо при работе с большими объёмами данных как для системы так и для пользователя, для снижении временных затрат при поиске и фильтрации информации.
Наиболее явно используется персонализация в рекламных целях. Проанализировав поисковые запросы и тематику сайтов посещенные пользователем, поисковые системы отображают ту рекламу, которая должна быть интересна человеку.
Построение портрета пользователя
Исходными данными являются данные о действии пользователя. Необходимо выявить набор атрибутов для построение портрета пользователя u. Основными атрибутами будут одинаковые слова или словосочетания в запросе и название выбранной страницы tn, наиболее повторяющиеся слова в тексте wn, а также все теги к этой страницы mn. Также можно учитывать другие атрибуты: время проведенное на странице, расположение в тексте, расстояние между словами. На основе этих данных выявить тематики данной статьи Rj(ui)= F(t,w,m), после чего записать их в матрицу пользователя и присвоить им коэффициент 1. Каждый раз, когда пользователь будет переходить на новые страницы, алгоритм будет добавлять тематику и пересчитывать вес всех тематик в матрице данного пользователя:
где k – количество просмотренных статей с данной тематикой.
Для решения поставленной задачи и определения тематики запроса предлагается использовать нейронную сеть (рис.1). А для определения резонансности статьи использовать основные принципы алгоритма PageRank.
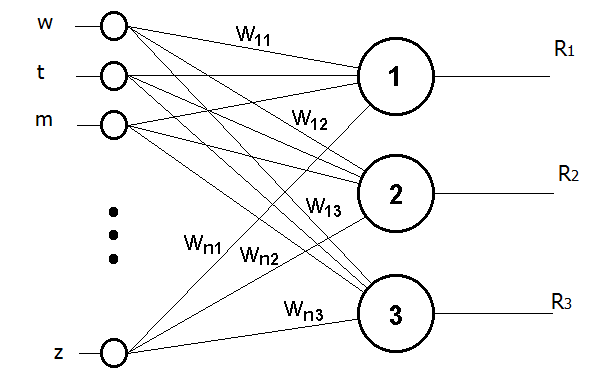
Рисунок 1 – Многослойная нейронная сеть
После многоразового выполнения алгоритма при переходе по страницам были получены результаты наиболее интересных категорий для пользователя (таблица 1).
На этом этапе система уже может предоставлять информацию пользователям, которая соответствует его интересам
| Таблица 1 – Веса категорий относительно предпочтений пользователя | |
| Название категории | Вес |
| Cloud Computing | 0.95 |
| API | 0.72 |
| Steve Jobs | 0.62 |
| Microsoft | 0.44 |
| 0.40 | |
| iPhone | 0.24 |
| Startups | 0.18 |
| Manu Ginobili | 0.17 |
Следующим этапом будет поиск тех категорий, которые могли бы подходить пользователю, но он еще ниразу не попадал на эти страницы. При выполнении данного метода используется структура данных дерево. Корневым узлом служит основная страница. Переход между узлами осуществляется за счет ссылок на странице. Для поставленной задачи требуется построить дерево хотя бы на один уровень. Анализируются все внутренние узлы дерева и выявляются список категорий по этим узлам, среди этих категорий выявляются общие. Все общие категории заносим в отдельную таблицу, она имеет такую же структуру, как и основная таблица категорий. В конечном итоге можно предполагать, что выявленные общие категории могут быть интересны пользователю.
Выводы
Проведен анализ систем персонализации и методов анализа запросов пользователей. Были выявлены огромный потенциал данных систем. А так же преимущество сервисов с системой персонализации перед системами, в которых она отсутствует.
В настоящее время существуют всевозможные системы анализа пользовательских данных, в большинстве литературы называют метод кластеризации, как самый надежный и эффективный. Хотя у данного метода есть свои недостатки. Метод удобен для большинства задач персонализации, за исключением гибкости в построения портрета пользователя с учетом большего количества пользовательских параметров.
Разрабатываемый алгоритм подходит лишь для узкого числа интернет сервисов. Сервис Wikipedia хорошо подходит для тестирования алгоритма персонализации. Все ссылки в основной части страницы ведут на другие статьи данного ресурса, которые схожи по своей структуре. Исходя из этого, вероятность некорректной работы алгоритма снижается. Также на корректность алгоритма влияет построение большего числа уровней дерева, поэтому на этапе разработке и тестирования было взято за конечную точку алгоритма построение дерева на один уровень относительно корневого узла. Благодаря этому снижается временные затраты на работу алгоритма, но увеличивается погрешность.
Список использованных источников
[1] Лексин В.А. Технология персонализации на основе выявления тематических профилей пользователей и ресурсов в интернете. 2007.
[2] Дмитрий Ночевнов. Методы и средства сегментации пользователей web-сайтов
[3] Сегаран Т. Программируем коллективный разум. – Пер. с англ. – СП: Символ-Плюс,2008. – 368 с.
[4] Анализ данных и процессов: учеб. пособие / а. а. барсегян, м.с. куприянов, и. и. холод, м. д. тесс, с. и. елизаров. — 3-е изд., перераб. и доп. — спб.: бхв-петербург, 2009. — 512 с.
[5] Xuehua Shen, Bin Tan, ChengXiang Zhai. Implicit User Modeling for Personalized Search.