РАЗРАБОТКА СЕМАНТИЧЕСКОГО ЯДРА САЙТА С ДИНАМИЧЕСКИМ КОНТЕНТОМ НА ОСНОВЕ АССОЦИАТИВНЫХ ПРАВИЛ
Автор:Е.А. Арсирий, О.А. Игнатенко, А.А. Леус
Одесский национальный политехнический университет
просп. Шевченко, 1, Одесса, 65044, Украина; e-mail: o-ignatenko@mail.ru
Источник: Informatics and Mathematical Methods in Simulation Vol. 2 (2012), No. 1, pp. 77-86
Аннотация:
В результате анализа проблем продвижения в поисковых системах веб-ресурсов с
динамическим контентом предложена методика разработки семантического ядра
сайта на основе создания ассоциативных правил с помощью алгоритма поиска
популярных наборов Apriori в транзакционной базе данных поисковых запросов.
Применение методики позволило повысить полноту и точность, а также снизить
время разработки семантического ядра сайта типа Интернет-витрины и магазина.
Введение
В век информационных технологий успех практически любого бизнеса в доста- точно большой степени зависит от способов виртуального представления фирмы в сети Интернет. При этом целью разработки контента веб-ресурса фирмы является предоставление информации, которая была бы способна заставить пользователя думать и вести себя в направлении, выгодном реальному бизнесу. С другой стороны, известно, что доля «поискового трафика» любого сайта (число посетителей, пришедших от поисковых выдач, от общей посещаемости сайта) является преобладающей [1,2]. Поэтому при разработке контента сайта большое внимание уделяется SEO (search engine optimization) – комплексу мер, направленных на продвижение веб-ресурса к верхним позициям поисковой системы (ПС) с целью увеличения его посещаемости. Известно, что одним из ключевых этапов SEO является разработка семантического ядра сайта (СЯС), которая, как правило, выполняется специалистами вручную и требует больших временных затрат [3, 4]. Такое положение является особенно недопустимым при разработке СЯС с динамическим контентом, когда SEO-специ- алисты не успевают вовремя реагировать на изменяющиеся наполнение сайта, внешнее Интернет-окружение, а также предпочтения и действия пользователей. Поэтому актуальным является создание методики разработки СЯС, применение которой SEO- специалистами позволило бы сократить время на достижение и поддержание лидирующих позиций сайта в поисковых выдачах, что является целью настоящей работы.
Анализ этапов и процедур работы поисковых систем и разработки семантического ядра сайта
ПС представляет собой сайт, состоящий из веб-интерфейса для пользователя и поисковой машины, которая является движком, обеспечивающим функциональность ПС. Поисковая машина состоит из модуля индексирования, базы данных (БД) проиндексированных документов и поискового сервера, занимающегося анализом и обработкой запросов пользователей. Модуль индексирования состоит из трех вспомога- тельных программ (роботов) – spider (паук), crawler (путешествующий паук) и indexer (индексатор). Spider скачивает веб-документы с помощью протокола НТТР, извлекает ссылки и перенаправления и сохраняет текст в следующем формате: URL, дата скачи- вания, http-заголовок ответа сервера, тело страницы (html-код). Crawler обрабатывает найденные пауком ссылки и осуществляет дальнейшее направление паука. Indexer разбирает html-код страницы на составные части такие как заголовки (title), подзаголов- ки (subtitles), метатэги (meta tags), текст, ссылки, структурные и стилевые особенности и т.д., анализирует их на основе различных лексических и морфологических алгорит- мов с целью последующего ранжирования по степени важности. При этом найденным словам и словосочетаниям присваиваются весовые коэффициенты в зависимости от того, сколько раз и где они встречаются (в заголовке страницы, в начале или в конце страницы, в ссылке, в метатэге и т.п.). В результате формируется файл, содержащий индекс, который может быть довольно большим. Для уменьшения его размеров прибе- гают к минимизации объема информации и сжатию файла, а также решают задачи определения дубликатов и «почти дубликатов». Результаты индексирования записыва- ются в базу данных (БД) проиндексированных документов (рис. 1, а).
Поисковый сервер является важнейшим элементом всей ПС, так как от алгорит- мов, которые лежат в основе его функционирования, зависит качество и скорость поис- ка. Принцип его работы заключается в следующем. Полученный от пользователя запрос (ключевые слова) подвергается морфологическому анализу для получения информационного окружения. При этом выделяются информационные (поиск сведе- ний), транзакционные (совершение действия), нечеткие (общие) и навигационные (прямой адрес) запросы. Поиск документов по их содержанию называется семанти- ческими. Информационное окружение передается специальному модулю ранжирова- ния, задача которого состоит в поиске html-страниц в БД проиндексированных доку- ментов, сортировке и выдаче в порядке релевантности. При этом для оценки релевант- ности найденных документов, как правило, используют TF-IDF-меру, согласно которой релевантность документа будет выше, если слово или словосочетание из запроса чаще встречается в найденном документе (TF) и реже в других документах БД (IDF). Если необходимо, порядок выдачи документов может быть изменен пользователем путем задания дополнительных условий (расширенный поиск). Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются. Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов. Таким образом, основой работы всех ПС является определение так называемых «ключевых слов» веб-ресурса. Из списка таких слов состоит семанти- ческое ядро сайта (СЯС). СЯС представляет собой список ключевых слов и их комби- наций, записанных в метатэги keywords и распределенных в контенте сайта, а именно, в тэге title, в alt-аттрибутах, в ссылочном тексте внутренних и внешних ссылок, в выделениях жирным и наклонным шрифтом, в начале контента сайта, в названии файлов, в URL и др. При этом от полноты и точности разработки СЯС зависит положе- ние сайта в списке выдач ПС.
Разработка СЯС является ключевым этапом SEO и состоит из ряда интеллекту- альных, трудноформализуемых этапов и процедур, для реализации которых необхо- димы большие временные и человеческие ресурсы (рис. 1, б).
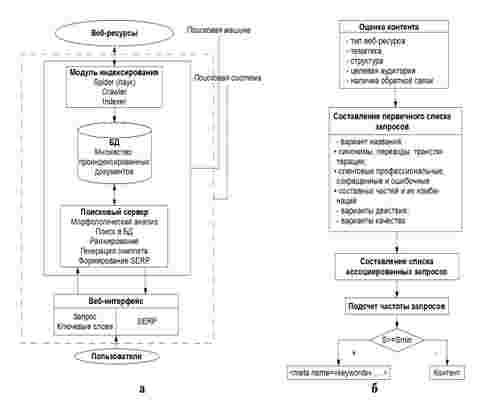
Рисунок - 1. Обобщенная схема этапов и процедур: а – работы ПС; б – разработки СЯС
На первом этапе необходимо оценить контент сайта, определив его тип (магазин, новостной блог, сайт-визитка и пр.), тематику, структуру, целевую аудиторию и необходимость обратной связи с пользователями. Следующим этапом будет создание первичного списка запросов. Для этого можно использовать различные варианты назва- ний товаров, услуг, самого сайта, различные действия, предоставляемые пользователям и варианты качества товара или услуг [1]. Затем составляется список ассоциированных запросов с помощью средств статистики поисковых систем (wordstat.yandex, adstat.rambler, adwords.google и др.) и подсчитывается частота ключевых слов. Ключе- вые слова с наибольшей частотой помещают в метатэги keywords, с меньшей – распределяют по контенту сайта. Однако, для сайтов с динамическим контентом, таких как Интернет-витрина и магазин, новостной блог, где меняется ассортимент товаров, их популярность, новости, заголовки и пр., перечисленные этапы разработки СЯС необхо- димо повторять достаточно часто. При этом длительность выполнения каждого этапа может значительно задерживать необходимую периодичность повторения, что приво- дит к снижению полноты и точности СЯС, а сайт теряет свои позиции в SERP. Для сокращения времени разработки СЯС с динамическим контентом без потери полноты и точности в данном исследовании предлагается использовать анализ связей (link analysis), позволяющий сгенерировать правила количественного описания взаимной связи между двумя и более ключевыми словами, объединенными в одном семанти-
Методика разработки семантического ядра сайта на основе алгоритма Apriori
Реализация двухэтапного анализа связей для поиска популярных наборов с помощью алгоритма Apriori и разработки АП на основе найденных популярных наборов нашла свое отражение в аналитическом приложении Deductor Academic, версия 5.2, которого была использована для создания методики разработки СЯС.
Методику разработки СЯС можно представить в виде следующих шагов:
1) Формирование ТБД поисковых запросов с помощью средств статистики поис-
ковых систем;
2) Конвертация ТБД поисковых запросов в текстовый формат;
3) Создание нового сценария в аналитическом приложении Deductor Academic;
4) Использование «Мастера импорта» для импорта ТБД в текстовом формате в
приложение Deductor;
5) Использование «Мастера экспорта» для экспорта результатов обработки в текс-
товом формате;
6) Использование «Мастера обработки» для реализации «Ассоциативных
правил», как одного из методов «Data Mining»;
7) Формирование результирующей ТБД на основе текстового файла;
8) Перезапись атрибута content мета тэг keywords на основе результирующей ТБД.
Выводы
Реализация предлагаемой методики разработки СЯС с динамическим контентом позволила поднять позиции Konica-Digital в SERP на 25% для 70% информационных, 85% транзакционных и 60% нечетких запросов, вводимых пользователем в основные поисковые системы Yandex и Google. При этом в 1.5 раза сократились затраты рабочего времени специалиста по SEO, необходимые для достижения заявленных результатов.
Ограниченный объем статьи не позволил показать другие приложения методики разработки СЯС с динамическим контентом. Однако необходимо заметить, что при реализации предлагаемой методики для Интернет-магазина Vsedetali в качестве ТБД использовалась таблица заказов, а автоматизированное формирование атрибута content мета тэгов keywords на основе АП также позволило повысить полноту и точность, снизить время разработки семантического ядра сайта. Таким образом, предложенная методика разработки СЯС является достаточно универсальной, и с небольшими доработками может быть применена для эффективного продвижения сайтов с динами- ческим контентом специалистами по SEO.
Литература
1. Ашманов И.С. Оптимизация и продвижение сайтов в поисковых системах / И.С. Ашманов, А.А. Иванов. – 3-е изд. – СПб. : Питер, 2011. – 463 с.
2. Как работают поисковые системы – сниппет, алгоритм обратных индексов, индексация страниц, особенности работы поисковиков [Электронный ресурс] / Режим доступа: ktonanovenkogo.ru
3. Паклин Н.Б. Бизнес-аналитика: от данных к знаниям / Н.Б. Паклин, В.И. Орешков. – СПб.: Питер, 2009. – 624 с.
4. Chung D. Suchmaschinen-Optimierung: Der schnell Einstieg / D. Chung, A. Klunder. – Heidelberg : REDLINE/mitp, 2007. – 224 S.
5. Aden T. Google Analytics: Implementieren. Interpretieren. Profitieren. – Auflage: 2., aktualisierte und erweiterte Auflage. – Munchen : Carl Hanser Verlag, 2010. – 463 S.
6. R. Agrawal, T. Imielinski, A. Swami. Mining Associations between Sets of Items in Massive Databases // Proc. of the ACM-SIGMOD 1993 Int'l Conference on Management of Data, Washington D.C., May 1993. – PP. 207-216.