А.Михаилян
Некоторые методы автоматического анализа естественного языка, используемые в промышленных продуктах
Description of state-of-the-art Natural Language Processing Technologies. Topics concerned include POS tagging, Text Parsing, Automatic Text Summarization. A lot of information on successful linguistic enterprises and research groups is also provided.
Исследования и разработки в области автоматической обработки текста в Европе и США привлекают внимание крупнейших частных фирм и государственных организаций самого высокого уровня. Европейский союз уже несколько лет координирует различные программы в области автоматической обработки текста. Например, Human Language Technology Sector of the Information Society Technologies (IST) Programme 1998 - 2000. Один из наиболее интересных проектов в рамках данной программы — SPARKLE (Shallow PARsing and Knowledge Extraction for Language Engeneering). В числе его участников - Dimler-Benz, Xerox Research Centre in Europe и Cambridge University Computer Laboratory. Цель проекта — создание частичных синтаксических анализаторов для основных языков Европейского союза.
В США с 1991 до осени 1998 года существовал проект TIPSTER, организованный DARPA, Департаментом Обороны и ЦРУ совместно с Национальным Институтом Стандартов и Технологий и Центром военно-воздушных и военно-морских вооружений (SPAWAR). В работе консультативного совета программы участвовали также ФБР, Национальный Научный Фонд и некоторые другие организации. Основной целью программы было сравнение и оценка результатов работы различных поисковых систем и систем реферирования.
Необходимо отметить, что такие задачи как распознование и генерации речи, создание поисковых систем до настоящего времени решаются с минимальным участием лингвистов. Это обусловлено использованием при решении вышеупомянутых задач в основном статистических методов.
Несмотря на это, за долгие годы четко определились области, в которых наиболее сильны позиции профессиональных лингвистов. Это лексико-грамматический анализ предложения, синтаксический анализ предложения, нахождение имен собственных в тексте и автоматическое реферирование. В данной статье мы вкратце опишем подходы к лексико-грамматическому анализу предложения, синтаксическому анализу предложения и коснемся проблем автоматического реферирования текста. Статья не претендует на полноту изложения. Вместо описания конкретных алгоритмов приводятся ссылки на первоисточники.
Лексико-грамматический анализ (Part-of-Speech-tagging)
Задача лексико-грамматического анализа — автоматически распознать, какой части речи принадлежит каждое слово тексте. На рис.1 показан пример текста, в котором каждому слову поставлен в соответствие лексико-грамматический класс [Francis and Kucera, 1979].
When/WRB you/PPSS access/VB the/AT BIB/NN record/NN you/PPSS want/VB ,/, you/PPSS can/MD print/VB the/AT screen/NN ,/, write/VB down/RP any/DTI information/NN you/PPSS need/VB ,/, or/CC select/VB the/AT item/NN if/CS you/PPSS are/BER placing/VBG a/AT hold/NN ./.
Обозначения
WRB - Wh-наречие
PSS - личное местоимение 3 л., ед.ч.
VB - инфинитив или глагол не 3-е л., ед.ч.
AT - опр.артикль
NN - существительное ед.ч.
MD - модальный глагол
RP - послелог
DTI - предопределитель
CC - сочинительный союз
CS - подчинительный союз
BER - глагол be, 3 л., ед.ч.
VBG - participle I или герундий
. - точка
Рис 1. Пример текста, в котором каждому слову поставлена в соответствие часть речи.
Данную задачу не представляет труда выполнить для русского языка благодаря его развитой морфологии практически со стопроцентной точностью. В английском языке простой алгоритм, присваивающий каждому слову в тексте наиболее вероятный для данного слова лексико-грамматический класс (син. часть речи) работает с точностью около 90 %, что обусловлено лексической многозначностью английского языка.
Для улучшения точности лексико-грамматического анализа используются два типа алгоритмов: вероятностно-статистические и основанные на продукционных правилах, оперирующих словами и кодами.
Большинство вероятностно-статистических алгоритмов [Linda Van Guilder, 1995] использует два источника информации:
1. Словарь словоформ языка, в котором каждой словоформе соответствует множество лексико-грамматических классов, которые могут иметься у данной словоформы. Например, для словоформы
well в словаре указано, что она может быть наречием, существительным, прилагательным и междометием. Для каждого лексико-грамматического класса словоформы указывается частота его встречаемости относительно других лексико-грамматических классов данной словоформы. Частота обычно подсчитывается на корпусе текстов, в котором предварительно вручную каждому слову приведен в соответствие лексико-грамматический класс. Таким образом, словоформа well в словаре будет представлена следующим образом:well noun 4 occurences in corpus well adverb 1567 occurences in corpus well adjective 6 occurences in corpus well interjection 1 occurences in corpus
2. Информацию о встречаемости всех возможных последовательностей лексико-грамматических классов. В зависимости от того, как представлена данная информация, разделяют биграмную, триграмную и квадриграмную модели. В биграмной модели используется информация о всех возможных последовательностях из двух кодов:
…
неопр.артикль + сущ.ед.ч 35983 occurences in corpus
неопр.артикль + сущ.мн.ч 7494 occurences in corpus
опр.артикль + сущ.ед.ч 13838 occurences in corpus
неопр.артикль + сущ.мн.ч 47 occurences in corpus
неопр.артикль + глагол 3 л., ед.ч 0 occurences in corpus
глагол 3 л., ед.ч + предлог 3744 occurences in corpus
…
В триграмной модели и квадриграмной модели используется соответственно информация о всех возможных последовательностях из 3-х и 4-х кодов.
Данная информация обрабатывается программой, использующей статистические алгоритмы, чаще всего алгоритм скрытых цепей Маркова [Linda Van Guilder, 1995] для нахождения наиболее вероятного лексико-грамматического класса для каждого слова в предложении.
Алгоритмы, основанные на продукционных правилах, используют правила собранные автоматически с корпуса текстов [Brill, 1995], либо подготовленные квалифицированными лингвистами [Tapanainen and Voutilainen, 1994]. Примером могут быть следующие правила:
Если словоформа может быть как глаголом, так и существительным, и перед ней стоит артикль, эта словоформа в данном случае является существительным.
Если словоформа может быть как предлогом, так и подчинительным союзом, и если после нее до конца предложения нет глагола, эта словоформа в данном случае является предлогом.
Оба подхода дают примерно одинаковый результат [Samuelsson and Voutilainen, 1997] [Volk and Schneider, 1998]. При их использовании раздельно либо в различных комбинациях точность лексико-грамматического анализа улучшается до 96-98 %. Поскольку точность при лексико-грамматическом анализа текста вручную также имеет определенную погрешность (0,5-2 %) согласно сведениям, предоставленным создателями Penn Treebank), можно считать, что точность лексико-грамматического анализа в автоматическом режиме достигла практически точности лексико-грамматического анализа в ручном режиме.
Синтаксический анализ (Text Parsing)
В отличие от лексико-грамматического анализа текста, синтаксический анализ — развивающаяся область прикладной лингвистики. Цель синтаксического анализа — автоматическое построение функционального дерева фразы, т.е. нахождение взаимозависимостей между разноуровневыми элементами предложения. Считается, что имея успешно построенное функциональное дерево фразы, можно выделить из предложения смысловые элементы: логический субъект, логический предикат, прямые и косвенные дополнения и различные виды обстоятельств. Существует большое количество различных количество подходов к синтаксическому анализу текстов. Ниже перечислены несколько известных методов построения функционального дерева фразы.
Ergo Linguistic Technologies Parser
Синтаксический анализатор (parser), разработанный Дереком Бикертоном и Филипом Браликом из Университета Гонолулу использует схему аннотации, принятую в Penn Treebank. Данная схема широко известна и имеет очень наглядное представление. Наибольший интерес представляет маркетинговая политика фирмы. ERGO ориентирует свой парсер на использование в вопросно-ответных интерфейсах. Данная особенность привлекла к ERGO внимание производителей компьютерных игр, VRML Consortsium, HAPTEK, и позволила ERGO получить "Первую техническую премию" на Конференции по Виртуальной Реальности и Мультимедиа (Virtual Reality and Multi-Media Conference in Japan - 98). ERGO пока является единственной компанией, которая имеет парсер, способный определять тип вопроса (вопрос к подлежащему, субъекту, прямому или косвенному дополнению, или обстоятельству) и конструировать "на лету" ответ. Наиболее известная система, использующая парсер ERGO — Virtual Friend — выпускается фирмой HAPTEK Technologies и представляет собой виртуальную игрушку.
ERGO не предоставляет информацию об алгоритмах, использующихся в продуктах компании, но предлагает всем желающим - участвовать в конкурсе на лучший синтасксический анализатор, устроенном самой ERGO. На рис.2 представлен пример разбора текста синтаксическим анализатором ERGO. Подчиненные элементы сдвинуты вправо и заключены в скобки.
(S (NP-SBJ there)
(VP is
(NP-PRD a dog
(PP-LOC on
(NP the porch)))))
Обозначения
S - предложение
NP - именная группа
NP-SBJ - именная группа - субъект
VP - verb phrase
NP-PRD - именная группа - объект
PP_LOC - предложно-именная группа, локатив
Рис 2. Пример анализа текста синтаксическим анализатором
ERGO.Functional Dependency Grammar
Создан исследователями из Хельсинского Университета, позднее основавшими две фирмы: Lingsoft и Conexor. Один из наиболее удачных синтаксических анализаторов. Ранняя версия под названием ENGCG (English Constraint Grammar) была использована для аннотации самого большого в мире корпуса — Bank of English, принадлежащего издательству Collins/Harper Publishers. Отличительной особенностью данного синтаксического анализатора является то, что в случаях, когда невозможно снять многозначность, синтаксический анализатор либо выдает несколько вариантов анализа, либо не достраивает дерево для данной части предложения. В основе FDG лежит теория зависимостей, впервые предложенная Л.Теньером
[Tesniere, 1959], позднее описанная Герингером [Heringer, 1993] и реализованная в рамках контекстно-зависимой грамматики [Tapanainen and Jarvinen, 1997]. На рис. 3 и 4 показан пример разбора фразы синтаксическим анализатором FDG.0
1 Lots+of lots+of det:>2 @DN> DET
2 people people subj:>3 @SUBJ N
3 act act main:>0 @+FMAINV V
4 well well man:>3 @ADVL ADV
5 but but cc:>3 @CC CC
6 very very @AD-A> ADV
7 few few det:>8 @DN> DET
8 people people subj:>9 @SUBJ N
9 talk talk cc:>3 @+FMAINV V
10 well well man:>9 @ADVL ADV
$.
Обозначения
Идентификаторы дерева фразы:
det: - определитель
subj: - субъект
main: - основной элемент
man: - обстоятельство образа действи
сс: - сочинительный союз
Функциональные идентификаторы:
@DN> - определитель
@SUBJ - субъект
@+FMAINV - личный предикатор
@ADVL - обстоятельство
@CC - сочинительный союз
@AD-A> - интенсификатор
Рис 3. Пример анализа текста синтаксическим анализатором
FDG;текстовое представление.
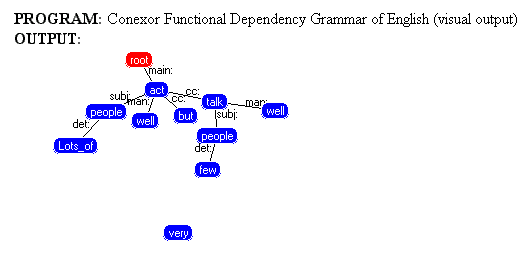
Рис 4. Пример анализа текста синтаксическим анализатором
FDG;визуальное представление.
Link Parser
Один из наиболее оригинальных подходов к синтаксическому анализу текста —
Link Parser, разработанный в Carnegie-Melon University. Этот синтаксический анализатор — единственный, чьи исходные коды были опубликованы он-лайн. Тогда как большинство систем синтаксического анализа используют структуры уровня именных и глагольных групп, при построении дерева фразы, Link Grammar, лежащая в основе Link Parser'а, использует информацию о типах связей, которые каждое слово может иметь со словами, находящимися справа или слева и несколько общих грамматических правил. На рис.5 показано предложение, анализированное с помощью Link Parser.+-----------------Xp-----------------+ | +--------Sp--------+ | +--Wd--+-Mp-+--Jp-+ +--MVa-+ | | | | | | | | ///// lots.n of people.p talk.v well.e .
Обозначения
Xp - связь между началом и концом предложени
Sp - связь между существительным и глаголом
Wd - связь между началом предложения и предложением
Mp - связь между именной группой и модифицирующей ее предложно-именной группой
Jp - связь между предлогом и относящейся к нему именной группой
MVa - связь между глаголом (прилагательным) и модификатором
Рис 5. Пример анализа текста с помощью Link Parser
В последнее время над задачами синтаксического анализа предложения работает множество исследовательских групп
, и на настоящий момент можно считать, что в рамках синтаксического анализа предложения успешно решена и уже нашла применение в производстве задача автоматического выделения именных групп. Что же касается полного синтаксического разбора предложения, данная проблема разрабатывается все еще скорее в стенах университетских экспериментальных лабораторий, чем в лабораториях промышленных предприятий.Автоматическое реферирование(Automatic Text Summarization)
На рынке присутствует очень небольшое количество традиционных программ реферирования, то есть таких, которые выделяют наиболее весомые предложения из текста используя статистические, алгоритмы, либо слова-подсказки
. Inxight Summarizer [Kupiec, Pedersen and Chen, 1995] — одна из наиболее известных коммерчески распространяемых систем реферирования. Inxight Summarizer был создан в Исследовательском центре Ксерокса в Пало Альто. Причин успеха данной системы несколько:- Наличие одного из наиболее совершенных алгоритмов оценки качества реферата.
- Параллельное использование нескольких широко известных алгоритмов реферирования; непосредственная связь между алгоритмами реферирования и алгоритмом оценки качества реферата.
- Продажа не готовых программных продуктов, а модулей реферирования (динамических библиотек для Win32 и Solaris платформ).
Среди коммерческих
систем также можно отметить Prosum — систему реферирования, разработанную British Telecommunications Laboratories в рамках экспериментальной коммерческой он-лайн платформы TranSend и представляет собой cgi-скрипт, встроенный в веб-страницу. Каждый реферат стоит 0,25 пенсов и оплачивается с помощью кредитных карточек MicroCredit.Так как интерес к традиционным системам автоматического реферирования неуклонно снижается, многие компании предлагают другие подходы. Одним из нетрадиционных решений является использование именных групп, выделенных с помощью частичных синтаксических анализаторов. подобные алгоритмы используются в программных продуктах Extractor и TextAnalyst.
Extractor
Extractor создан в Институте Информационных Технологий Национального исследовательского Совета Канады. Он представляет собой модуль, выделяющий из представленного ему на вход текста наиболее информативные именные группы. По умолчанию количество таких групп — 7 вне зависимости от длины текста.
Extractor используется в программных продуктах фирм ThinkTank Technologies и Tetranet, а также в поисковой системе Журнала Исследований в Области Искусственного Интеллекта.TextAnalyst
Данная программа создана в московском Научно-производственном инновационном центре "МикроСистемы".
TextAnalyst работает только с русским языком, выделяя именные группы и строя на их основе семантическую сеть — структуру взаимозависимостей между именными группами.Библиография
- Eric Brill Unsupervised learning of disambiguation rules for part of speech tagging, — Proceedings of ACL-95, 1995.
- From Language Engeneering to Human Language Technologies (European Commisson report) — MIKADO SA, Luxemburg, 1998.
- Christer Samuelsson, Atro Voutilainen Comparing a Linguistic and a Stochastic Tagger — Proceedings of 35 Annual Meeting of the Association for Computational Linguistics and 8th conference of the European Chapter of the Association for Computational Linguistics, ACL, Madrid, 1997.
- W. N. Francis H. Kucera Manual of Information to accompany A Standard Corpus of Present-Day Edited American English, for use with Digital Computers.— Brown University Providence, Rhode Island Department of Linguistics Brown University, 1979.
- Linda Van Guilder Automated Part of Speech Tagging: A Brief Overview (Handout for LING361, Fall 1995 Georgetown University) — Georgetown University, 1995.
- Julian Kupiec, Jan Pedersen, Francine Chen A Trainable Document Summarizer — Xerox Palo Alto Research Centre, Palo Alto, CA, 1995.
- Hans Jurgen Heringer Dependency syntax - basic ideas and the classical model. — Joachim Jacobs, Arnim von Stechow, Wolfgang Sternefeld, and Theo Venneman, editors // Syntax — An International Handbook of Contemporary Research, volume 1, chapter 12, pages 298-316. Walter de Gruyer, Berlin — New York.
- Lucien Tesniere Elements de syntaxe structurale. — Editions Klincksieck, 1959, Paris.
- Daniel D.K.Sleator, David Temperly Parsing English with a Link Grammar — School of Computer Studies, Carnegie-Melon University, Pittsburg, PA, 1991.
- Pasi Tapanainen, Timo Jarvinen A non-projective dependency parser — Proceedings of Fifth Conference on Applied Natural Language Processing, Washington, D.C., 1997
- Pasi Tapanainen, Atro Voutilainen Tagging accurately - Don’t'guess if you know. — Computational and Language E-print Archive, 1994
- Martin Volk, Gerold Schneider Comparing a statistical and a rule-based tagger for German — Proceedings of KONVENS-98, Bonn, 1998.
- Ellen M.Voorhes, Donna Harman. Overview of Sixth Text Retrieval Conference (TREC-6). — National Institute of Standards and Technology Gaithersburg, MD 20899, 1998
URLs
- Human Language Technology Sector of the Information Society Technologies (IST) Programme 1998 - 2000 — http://www.linglink.lu
- SPARKLE (Shallow PARsing and Knowledge Extraction for Language Engeneering) — http://www.ilc.pi.cnr.it/sparkle/sparkle.html
- TIPSTER Text Program archive — http://www.nist.gov/itl/div894/894.02/related_projects/tipster/
- Linda Van Guilder Handout for LING361, Fall 1995 Georgetown University http://www.georgetown.edu/cball/ling361/tagging_overview.html
- Teragram Corporation (OEM POS tagger)— http://www.teragram.com/w3/home.htm
- ERGO Linguistic Technologies — http://www.ergo-ling.com
- Virtual Reality and Multimedia Conference — http://www.vsmm.vsl.gifu-u.ac.jp/vsmm98
- Lingsoft (ENGCG)— http://lwww.lingsoft.fi
- Conexor (Functional Dependency Grammar) — http://www.conexor.fi
- Link Grammar Homepage — http://bobo.link.cs.cmu.edu/link
- Inxight — http://www.inxight.com
- Prosum Summarizer — http://transend.labs.bt.com/cgi-bin/prosum/prosum
- Extractor — http://ai.iit.nrc.ca/II_public/extractor.html
- TextAnalyst — http://www.host.ru/~analyst/
- Computational and Language E-print Archive http://xxx.lanl.gov/find/cmp-lg