Kalaivani S., Dr. Duraiswamy К.
Международная конференция по современным компьютерным технологиям (ICACT) 2011
Труды, опубликованные в международном журнале компьютерных приложений ® (IJCA)
Автор перевода: Непомящий А.А.
В статье предлагается архитектура вопросно-ответной системы для конкретного домена с использованием семантической сети и онтологий. Она определяет систему ответов на запросы с помощью семантической методологии поиска и естественного языка методов обработки. Просмотр в онтологии основан на концептуальном графике соответствующего типа. В репозитории имеется сборник документов, которые содержат информацию, относящуюся к конкретному домену. Основная цель этой модели - задать вопрос на естественном языке, а соответствующий механизм используется для получения правильного ответа на данный вопрос.
Обработка естественного языка, онтология, семантическая сеть, вопросно-ответная система.
В нынешней ситуации, основная часть знаний доступна в Интернете в форме документов, статей, обсуждений, книг и т.д. Но как только проблема касается поиска соответствующей информации из этих ресурсов, нет механизма, удовлетворяющего нашим потребностям. В данной ситуации необходимость вопросно-ответной системы заключается в том, чтобы найти правильную информацию, которая может автоматически извлекаться из интернета с помощью некоторых конкретных механизмов. Механизм поиска уже способен удовлетворить потребности пользователя, однако имеются некоторые недостатки. Он дает как относящуюся к делу информацию, так и наоборот. Пользователь выбирает наиболее подходящий вариант из предложенного, а сам поиск основан на ключевых словах и не проверяет смысл запроса пользователя. В данной ситуации семантический поиск вступает в действие. Вход в предлагаемую вопросно-ответную систему осуществляется пользователем при помощи преобразования естественного языка. С помощью обратной связи с пользователем запрос расширяется и уточняется для получения соответствующего ответа. Это может быть достигнуто как в открытом, так и в закрытом домене.
На сегодня существует два типа вопросно-ответной системы. Это система открытого и закрытого доменов вопросно-ответной системы. Среда открытого домена более сложная по сравнению со средой закрытого Вход к запросу может быть в любой форме, а ответ может изменяться в зависимости от различных доменов. Среда закрытого домена проще, потому что конкретная концепция и обработка естественного языка может быть легко реализована с помощью онтологии. Среда закрытого домена имеет дело с запросами, которые зависят от конкретной онтологии.
Это одна из идей концепции искусственного интеллекта. Наиболее смежные области в обработке естественного языка это машинный перевод, информационный поиск и проверка правописания. Обработка естественного языка позволяет семантическую форму текста для построения онтологии, которая хорошо подходит для концепции семантической паутины. Сущность указанной модели как и стемминг реализуется в нашей системе.
Понятие онтологии происходит от философии. Оно имеет тесные связи с информационными технологиями, инженерными знаниями и искусственным интеллектом, «онтология-это shared explicit specification of a conceptualization общая точнаяспецификация концептуализации). В этом значении «общая» означает,что информация ,описанная онтологией является общепринятой у пользовтелей , «точная» требует точность обеих концепций ,а их взаимосвязи четко определены, «концептуализация» принята за абстрактную модель явления. Следуя степени зависимости от области, онтология может подразделяться на четыре категории, а именно : высший уровень, домен,задача и применение онтологии [5].Онтология определяется в основных терминах и отношениях ,включая словарь конкретной области, а также правила для комбинирования этих условий и отношений , чтобы определить расширенные словари. Онтологии используются для представления знаний в виде класса / концепции, отношений, функций, структур и аксиомы.
Эти онтологии могут быть представлены в виде OWL [6], RDF языки [7] с помощью Protégé Tool. [8].
По словам Тима Бернерс-Ли, семантическая сеть, в которой информация предоставляется с четко определенной смыслом, лучше позволяет компьютерам и людям работать в сотрудничестве. [9] Такие технологии поддерживаются в Семантической паутине, такой как XML ( eXtensible Markup Language — расширяемый язык разметки), RDF( «среда описания ресурса»).
Семантическая паутина- это видение будущего сети, в котором сеть умнее человека.
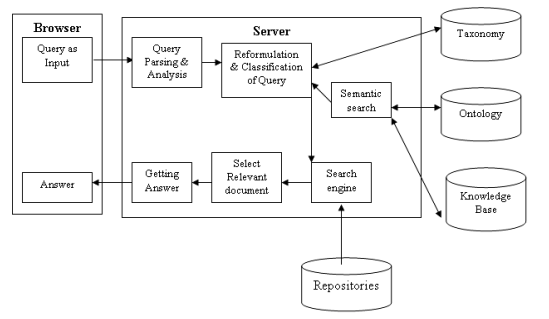
На рисунке 1 представлены общая архитектура персонализированной вопросно-ответной системы с онтологией и базой данных .
а) вопрос как вход
Пользователь вводит вопрос из браузера.В этой фазе идентифицируются тип вопроса, основная концепция вопроса и поиск элемента. Семантическое значение вопроса лежит в основе перехода к следующей стадии.
б )запрос и анализ
На этом этапе находится аналитическая операция вопроса. Этот анализ отвечает за обработку естественного языка (NLP). Это техника для идентификации типа вопроса, типа ответа, предмета, глагола, существительного, фразы и прилагательного исходя из вопроса. Знаки ,разделенные вопросом и значением ,анализируются ,а переформулированный вопрос/запрос отправляется на следующий этап. Вход согласовывается с естественным языком ,а реализуется это с помощью алгоритма сегментации слова. В алгоритме сегментации слова запрос входа от пользователя разделен на ключевые слова ,которые в дальнейшем подразделяются и разыскиваются в базе данных для получения правильных ответов. Данный общий алгоритм сегментации слова реализован в NET среде.
 Переформулировка и классификация запросов. По выбору пользователя переформулировка запроса
генерируется с помощью таксономии на заданную тему. Семантический поиск. На заключительном этапе, данный вопрос взят в качестве формата слова и соответствующая концепция вычисляется в онтологии и базе данных. Существуют три алгоритма ,доступных для семантического поиск. Поиск осуществляется с помощью графика алгоритма соответствия [10],который является лучшим технически,сравнивая с тремя вышеупомянутыми алгоритмами. Графические шаблоны являются важной частью семантического поиска. RDF модель и графические шаблоны используются для разработки и кодирования ограниченных запросов для размещения суб графика в RDF сеть. База данных. База данных предлагаемой системы –это определенный домен.
Хранение онтологии является необходимым условием для
извлечения нужного и верного ответа от базы данных [11].
В нашей системе используется база данных, которая может легко быть связанной с Protégé .Этот шаг от Protégé к базе данных представлен на рис 2.
Переформулировка и классификация запросов. По выбору пользователя переформулировка запроса
генерируется с помощью таксономии на заданную тему. Семантический поиск. На заключительном этапе, данный вопрос взят в качестве формата слова и соответствующая концепция вычисляется в онтологии и базе данных. Существуют три алгоритма ,доступных для семантического поиск. Поиск осуществляется с помощью графика алгоритма соответствия [10],который является лучшим технически,сравнивая с тремя вышеупомянутыми алгоритмами. Графические шаблоны являются важной частью семантического поиска. RDF модель и графические шаблоны используются для разработки и кодирования ограниченных запросов для размещения суб графика в RDF сеть. База данных. База данных предлагаемой системы –это определенный домен.
Хранение онтологии является необходимым условием для
извлечения нужного и верного ответа от базы данных [11].
В нашей системе используется база данных, которая может легко быть связанной с Protégé .Этот шаг от Protégé к базе данных представлен на рис 2.
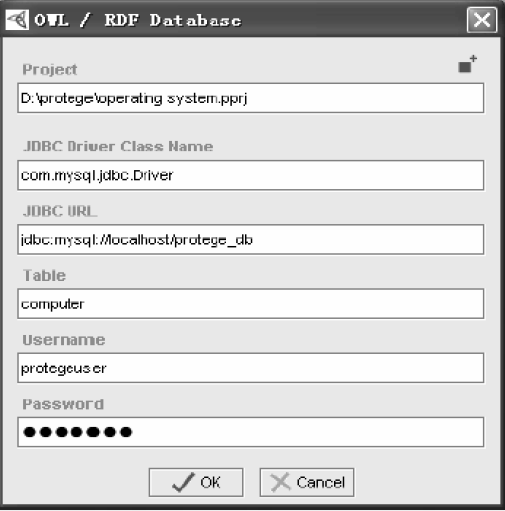
Хранилища содержат все документы, связанные с полем структурных данных. Предлагаемый документ может быть структурированным или в неструктурированном формате, который можно получить в поисковой системе.
Поисковая система. Пользователь может искать ответы на естественном языке. Если понятие существует в базе данных, система может ответить на вопрос быстро, в противном случае пользователь должен применить поисковую сеть. Пользователь вызывает мета-поисковую систему через веб-поиск интерфейса.Выбор соответствующего документа. Используя некоторые правила преобразования, возможность ответа будет определена из различных документов, а знаки препинания извлекаются. Эти документы восстанавливаются определенным образом.
Получение ответа. Это простой шаблон выбора ,соответствующий технике выбора нужного ответа с точки зрения точности и простоты.
Ответ. Наконец, ответ будет отображаться в текстовом поле браузера. Пользователь может принять ответ, или если он нуждается в большей информации, его запрос будет дан на сервер еще раз. Правильный ответ может быть выбран исходя из удовлетворенности пользователя.
Эта система реализована в. NET среде для Front
end design с подключением MySQL.
Онтология с 1000 узлами строится с помощью инструмента Protégé .
Отношения, ассоциативность для каждого узла правильно установлены и протестированы.Онтология в моделе RDF / OWL , представление онтологии может быть использовано как Jena Code with Eclipse
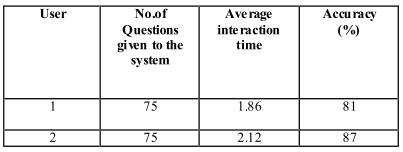
Мы реализовали наш тест в базе данных, которая имеет 1000 узлов в онтологии. Взятые параметры : a=0.5, b=0.3, and c=0.6. В процессе концептуальной диаграммы соответствия, выбирается вопрос, который имеет большое сходство (предельное значение > = 0,67) . После нескольких повторов результат дается в виде таблицы. Если максимальное сходство меньше ,чем 0,65, то принимается,что в базе данных нет решения. Точность принимается более чем на 80%. Два пользователя с 75 вопросами тестируются соответственно. Результат показан на рисунке 3.
Использование онтологии и семантической паутины в вопросно-ответной системе является новой областью для улучшения поиска, а также для получения соответствующего результата. Для этого, NLP техника является основой . Существует необходимость определенного стандарта для получения документов из хранилищ. База данных, которая помогает получить ответ с помощью некоторого алгоритма поиска,который может классифицировать этот вопрос и позволяет найти вопрос в концепции. В предварительной работе, мы будем создавать доменную конкретную онтологию ,а также будем получать результат из документов . После успешной реализации этого проекта, он будет продлен, чтобы найти реальную поисковую систему для использования сети.
