Применение генетических алгоритмов для обучения нейронных сетей
Авторы: Г.А. Поллак
Источник: Поллак Г.А. Применение генетических алгоритмов для обучения нейронных сетей
/ Поллак Г.А. // Издательский центр ЮУрГУ, 2011 год, С. 174–178
Авторы: Г.А. Поллак
Источник: Поллак Г.А. Применение генетических алгоритмов для обучения нейронных сетей
/ Поллак Г.А. // Издательский центр ЮУрГУ, 2011 год, С. 174–178
Генетические алгоритмы применяются для решения оптимизационных задач с помощью метода эволюции, т.е. путем отбора из множества решений наиболее подходящего. Они отличаются от традиционных методов оптимизации следующими свойствами [1]:
Генетические алгоритмы для обучения нейросети применяются как альтернатива методу обратного распространения ошибки. Целью обучения является минимизация функции стоимости E(n)= 1/2*ek2(n), где ek(n) = dk(n) – yk(n) – ошибка, dk(n) – желаемый выход нейросети, yk(n) – реальный выход нейросети, n – номер итерации.
Обучение методом обратного распространения ошибки сводится к подбору значений весов прямонаправленной нейронной сети, основываясь на принципах наискорейшего спуска. Один из основных недостатков этого классического алгоритма состоит в возможном попадании в локальные минимумы функции стоимости.
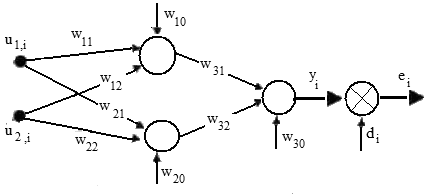
Применение генетического алгоритма позволяет избежать этой опасности. Рассмотрим в качестве примера нейронную сеть, которая реализует операцию XOR(рис. 1).
Для сети требуется подобрать оптимальные веса w11, w11, w12, w21, w22, w31, w33, w10, w20, w30, минимизирующиe значение целевой функции, определяемой среднеквадратичной погрешностью
(1)
Параметрами задачи являются веса, которые определяют точку пространства поиска и, следовательно, представляет собой возможное решение.
Блок-схема, реализующая классический генетический алгоритм, показана на рис. 2.
Допустим, что веса принимают действительные значения из интервала [–1, +1]. Тогда каждая хромосома будет комбинацией из 9 двоичных последовательностей (генотипов), кодирующих конкретные веса. Соответствующие им фенотипы представлены значениями отдельных весов, т.е. множествами соответствующих действительных чисел из интервала [–1, +1]. Длина хромосом зависит от условия задачи. Допустим, что требуется найти решение с точностью до q = 2 знаков после запятой для каждой переменной wik. Следовательно интервал [a, b] необходимо разбить на (b – a)·10q одинаковых подынтервалов. Это означает применение дискретизации с шагом r = 10–q. Наименьшее натуральное число mi, удовлетворяющее неравенству (b - a) * 10q ≤ 2m - 1 определяет необходимую и достаточную длину двоичной последовательности, требуемой для кодирования числа из интервала [a, b] с шагом r. Результаты расчетов приведены в табл. 1.
| a | b | n | r | q | m |
| -1 | 1 | 256 | 0,007843 | 2 | 7,65105 |
Как видно из табл. 1 длина двоичной кодирующей последовательности составляет 8 бит.
При кодировании действительных чисел в качестве значения гена берется целое число, определяющее номер интервала (используется код Грея). В качестве значения фенотипа примем число, являющееся серединой этого интервала.
Исходная популяция хромосом задается случайным образом (табл. 2).
| Код Грея | Номер интервала | Левая граница | Правая граница | Среднее значение | ||
| w1 | 11001100G | CCh | 204 | 0,5922 | 0,6000 | 0,5961 |
| w12 | 01100010G | 62h | 98 | 0,2392 | 0,2314 | 0,2353 |
| w21 | 00110011G | 33h | 51 | 0,6078 | 0,6000 | 0,6039 |
| w22 | 01110111G | 77h | 119 | 0,0745 | 0,0667 | 0,0706 |
| w31 | 00100010G | 22h | 34 | 0,7412 | 0,7333 | 0,7373 |
| w32 | 01010101G | 55h | 85 | 0,3412 | 0,3333 | 0,3373 |
| w10 | 01100010G | 62h | 99 | 0,2314 | 0,2235 | 0,2275 |
| w20 | 10100010G | A2h | 162 | 0,2627 | 0,2706 | 0,2667 |
| w30 | 00101010G | 2Ah | 42 | 0,6784 | 0,6706 | 0,6745 |
Отклик сети на входные сигналы y1 = 0,4592, y2= 0,2631, y3 = 0,3463, y4= 0,3551, среднеквадратичная ошибка Е = 0,2704. При вычислении выходных значений нейросети использовалась логистическая функция акти- вации с параметром скорости обучения η= 1.
Наибольшую роль в успешном функционировании алгоритма играет этап отбора родительских хромосом для создания новой популяции. Наиболее часто используется метод отбора, называемый рулеткой. Однако вследствие некоторых недостатков [1] этот метод плохо приспособлен для решения задачи минимизации. Поэтому предлагается использовать турнирный метод. Суть метода заключается в следующем. Все особи популяции разбиваются на подгруппы по 2–3 особи в каждой. Выбор родителей осуществляется случайно с вероятностью, меньшей 1.
В классическом генетическом алгоритме применяются два основных генетических оператора: оператор скрещивания и оператор мутации. Веро- ятность скрещивания достаточно велика (обычно 0,5 ≤ рс ≤ 1), вероятность мутации устанавливается весьма малой (чаще всего 0 ≤ рm ≤ 0,1). Это означает, что скрещивание в классическом алгоритме производится практически всегда, тогда как мутация – достаточно редко.
Оператор скрещивания действует следующим образом.
Например для lk = 4
Оператор мутации с вероятностью рm изменяет значение гена в хромосоме на противоположное. Вероятность мутации может вычисляться случайным выбором числа из интервала [0, 1] для каждого гена и отбором для выполнения этой операции тех генов, для которых разыгранное число оказывается меньше или равным значению рm.
Хромосомы, полученные в результате применения генетических операторов к хромосомам временной родительской популяции, включаются в состав новой популяции. Она становится текущей популяцией для данной итерации генетического алгоритма. На каждой очередной итерации рассчитывается значение функции приспособленности для всех хромосом этой популяции, после чего проверяется условие остановки алгоритма. В качестве такого условия применяется либо ограничение на максимальное число эпох функционирования алгоритма, либо определяется сходимость алгоритма путем сравнения значений функции приспособленности популяции на нескольких эпохах. При стабилизации этого параметра алгоритм останавливается.
Следует подчеркнуть, что алгоритм обратного распространения ошибки, как правило, выполняется быстрее генетического, который просматривает все множество возможных решений. Однако градиентный метод не всегда приводит к ожидаемому результату, который зависит от выбора начальной точки. Кроме того, принципиальным недостатком метода обратного распространения ошибки является «застревание» в локальных оптимумах. Можно предложить гибридный метод обучения нейронных сетей, когда генетический алгоритм применяется для выбора начальной точки (исходного множества весов на каждой итерации), а затем применяется метод обратного распространения ошибки. Гибридный метод может позволить найти глобальное решение за приемлемое время.