
Abstract
Content
- Introduction
- 1. Theme urgency
- 2. Goal and tasks of the research
- 3. Expected scientific innovation and practical importance
- 4. Review of existing algorithms for reducing the sample size
- 4.1 Methods for solution of the problem data reduction
- 4.2 Аlgorithm STOLP
- 4.3 Аlgorithm FRiS-STOLP
- 4.4 Algorithm of the crushing etalons
- 4.5 Аlgorithm NNDE
- 5. The method of sampling w-objects
- Conclusion
- References
- Important note
Introduction
People faced with the task of pattern recognition constantly. For example, the work of the various life-support systems, human-computer interaction, the emergence of robotic systems and others. Most modern applications that can be solved by building recognition systems, а characterized by a large volume of source data. This significantly reduces the system efficiency and significantly increases the time required to perform recognition.
1. Theme urgency
Now the main scientific direction is research and development of algorithms and methods for constructing software data mining. The relevance of this topic is determined by the presence of a number of important practical problems, the solution of which requires to analyze large volumes of heterogeneous data. Most modern applications to be solved by the construction of the recognition systems, a characterized by a large volume of raw data and the ability to add new data is already in the process of systems. That is why the basic requirements for a modern detection systems are adaptability (the ability of the system in the process of changing their characteristics, and for the recognition of learning systems – correct classification decision rules, changing the environment), work in real time (the possibility of formation of classification decisions for a limited time) and high efficiency classification for linearly separable and overlapping classes in the feature space [1, 2].
Adding new objects being for most applications sufficiently intense, results in a significant increase in the size of the training sample, which in turn leads to the increase in the time adjustment of decision rules (especially if used teaching method requires the construction of a new decision rule, rather than the partial adjustment) and deterioration in the quality of the solutions due to the problem of retraining on samples of large volume [3]. That is why the task of data preprocessing by reducing the sample size is the actual scientific and technical problem, requiring the development of modern approaches to its solution.
2. Goal and tasks of the research
Object of research is the problem of data processing in learning recognition systems.
Subject of research – existing algorithms for forming weighted samples in learning recognition systems.
The purpose of the graduation Master’s work is development of the algorithm for forming of weighted samples in learning recognition systems. In the course of work it is necessary to solve the following problems:
– to explore the existing algorithms for forming weighted training samples;
– to explore methods of use the weighted training samples in adaptive recognition systems;
– to develop an algorithm for constructing the weighted training samples in learning recognition systems;
– to develop a software system;
– to perform a comparative analysis of the proposed algorithm and existing algorithms for solution of this problem.
3. Expected scientific innovation and practical importance
Scientific novelty of this work is to develop a method for constructing weighted training samples in learning recognition systems. As the growth in the size of training sample leads to an increase in training time and the deterioration of its quality, it is assumed that on the basis of weighted samples can be built an efficient algorithm to select a subset of samples of actual objects and removing the rest.
The practical importance of work consists in the increase of efficiency of classification in learning recognition systems. Developed a method for forming weighted samples can be used for software implementation the classification system for processing the results of a variety of sociological, economic and statistical research, developing digital libraries, building spam filters, etc.
4. Review of existing algorithms for reducing the sample size
4.1 Methods for solution of the problem data reduction
Compression tasks and combining the data provided unchanging dictionary of attributes can be solved in two ways. The first way is to select some set of objects in the original training set. The best known algorithms that implement this method are STOLP [4], FRiS-STOLP [5, 6], NNDE (Nearest Neighbor Density Estimate) [7, 10, 11] and MDCA (Multiscale Data Condensation Algorithm) [7]. The second way consists in the construction of new objects on selected objects from initial sample. Algorithm of the crushing etalons [4], LVQ (learning vector quantization) [8] and w-GridDC [9].
4.2 Аlgorithm STOLP
Algorithm STOLP – algorithm selection of etalon objects for the metric classifier. Etalons of the i-th class in the classification of the nearest neighbor method can serve as a subset of the objects of this class that the distance from any object belonging to him from the sample X L to the nearest etalon in its class smaller than the distance to the nearest etalon of another class [4].
The input data for the algorithm are:
– sample X L;
– reasonable error l0;
– cutoff emission δ;
– classification algorithm;
– formula for calculation of risk size W.
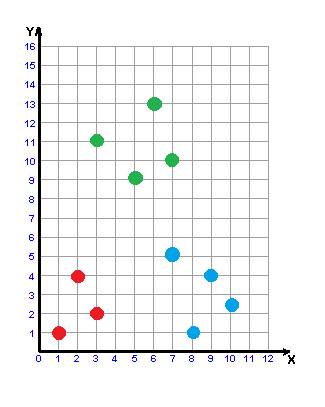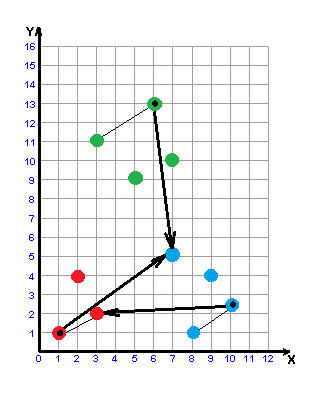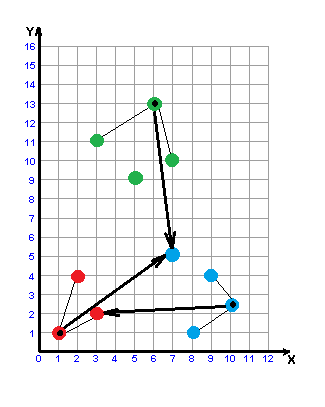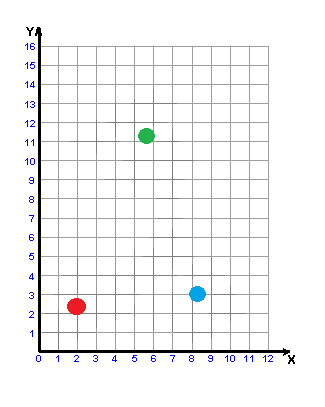
Result of the algorithm – dividing the entire set of objects X L on the etalon, noise (emissions) and uninformative objects.
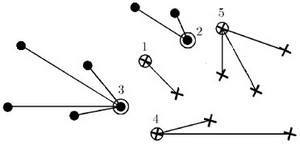
Picture 1 – The result of the algorithm STOLP
4.3 Аlgorithm FRiS-STOLP
The algorithm FRiS-STOLP – algorithm selection of reference objects for the metric classifier based on FRiS-function [5]. From classical algorithm STOLP it features the use of auxiliary functions. Use such auxiliary functions:
– NN(u,U) – returns the object nearest to u from the set U;
– FindEtalon (Хy,μ) – returns a new etalon for the class Y.
Function FindEtalon (Хy,μ) is used in the following algorithm:
- For each object x ∈ Хy evaluated two characteristics – "defense" Dx and "tolerance" Tx (as far as the object in a class reference standards does not prevent other classes) of the object:
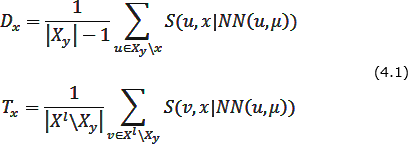
- Based on the computed performance "efficiency" of the object x:

- Function FindEtalon returns an object x ∈ X l with maximum efficiency Ex:

Parameter α ∈ [0,1] quantitatively determines the relative "importance" of the characteristics of objects ("defense" and "tolerance"). Can be selected based on the specifics of a particular task.
4.4 Algorithm of the crushing etalons
Algorithm of the crushing etalons is based on the coating image of each training sample simple figures that can complicate. Training sample is a set of objects described by set of attributes. Each training sample to be represented as a point in the feature space: X = (x1, x2, x3,..., xp), where p – the number of characters. As coating figures usually use a set of hyperspheres.
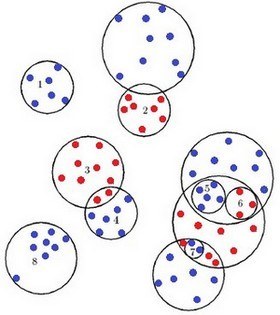
Picture 2 – The result of the algorithm of the crushing etalons
4.5 Аlgorithm NNDE
The method of nearest neighbors – the simplest metric classifier, based on the evaluation of the similarity of objects. Classified object belongs to the class that owns the nearest objects of the training sample [10]. To use multiple neighbors to improve reliability of classification. In tasks with two classes take odd number of neighbors to avoid any ambiguity situations when the same number of neighbors belong to different classes. In tasks with the number of classes 3 or more odd does not help, and the ambiguity of the situation can still arise. In this case, use weighted nearest neighbors.
5. The method of sampling w-objects
In article [14] describes a method of constructing a weighted training sample w-objects to reduce the large volume samples. The basis of this method is the selection of closest objects sets from the original sample and replacing them by a weighted object of the new sample.The values of each object attributes of the new sampleare the centers of mass of the objects attributes values from the original sample, which it replaces.Weight is defined as the number of objects in the original sample, which were replaced by an object of the new sample.
The construction of w-object consists of three successive stages:
1) creation of a forming set Wf, containing a number of objects in the original sample belonging to the same class;
2) formation of the vector Xі W = {xi1, xi2,...,xin}, of the w-object feature values Xі W and calculation of its weight pі;
3) correction of the initial training sample by the removing of objects that are included in the forming set X = X \Wf.
The selecting of objects {X1,Xf2,...,Xd} from the forming set Wf is carried by the following rule: an object Xі include in Wf if:
– it belongs to the same class as the starting point Xf1;
– the distance from considered object to the initial point is less, than to a competing point Xf2.
Thus, the forming set Wf is formed by the rule:
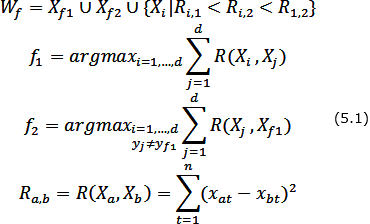
The features values {xi1,xi2,...,xin} of the new w-object XіW are forming on the forming set Wf and they are calculated like the coordinates of the mass center of the pf = |Wf | material points, where |Wf | – is a the cardinality of a set Wf

After the formation of the next w-object, all objects forming its set are removed from the original training set, X=X\Wf. The algorithm finishes its work when X∈∅.
Picture 3 - Building a w-object
(animation: 6 frames, 6 cycles of repeating, 32.8 kilobytes)
Conclusion
In this paper, various algorithms to reduce the samples in recognition systems have been investigated. Such algorithms as STOLP, FRiS-STOLP аre easy to implement, but give a large error in the solution of problems with large amounts of input data, the algorithm NNDE hardly suited for solving such problems. The method of constructing a weighted training sample w-objects to reduce the large volume of samples recognition systems has been studied. It has been found that the presence in the samples weights w-objects can save information about the number of replaceable objects and let characterize the area in which they are located.
References
- Горбань А.Н. Обучение нейронных сетей. / А.Н. Горбань – М.: СП ПараГраф, 1990. – 298 с.
- Pal S.K. Pattern Recognition Algorithms for Data Mining: Scalability, Knowledge Discovery and Soft Granular Computing / S.K. Pal, P. Mitra – Chapman and Hall / CRC, 2004. – 280 p.
- Александров А.Г. Оптимальные и адаптивные системы. / А.Г. Александров – М.: Высшая школа, 1989. – 263 с.
- Загоруйко Н.Г. Методы распознавания и их применение. – М.: Сов. радио, 1972. – 208 с.
- Алгоритм FRiS-STOLP [Электронный ресурс]. – Режим доступа: http://www.machinelearning.ru/...
- Zagoruiko N.G., Borisova I.A., Dyubanov V.V., Kutnenko O.A. Methods of Recognition Based on the Function of Rival Similarity // Pattern Recognition and Image Analysis. – 2008. – Vol. 18. – № 1. – P. 1–6.
- Larose D.T. Discovering knowledge in Data: An Introduction to Data Mining / D.T. Larose – New Jersey, Wiley & Sons, 2005. – 224 p.
- Kohonen T. Self-Organizing Maps. – Springer-Verlag, 1995. – 501 р.
- Волченко Е.В. Сеточный подход к построению взвешенных обучающих выборок w-объектов в адаптивных системах распознавания // Вісник Національного технічного університету «Харківський політехнічний інститут». Збірник наукових праць. Тематичний випуск: Інформатика i моделювання. – Харків: НТУ «ХПІ», 2011. – № 36. – С. 12–22.
- Метод ближайших соседей. Материал из профессионального информационно-аналитического ресурса, посвященного машинному обучению, распознаванию образов и интеллектуальному анализу данных. [Электронный ресурс]. – Режим доступа: http://www.machinelearning.ru/wiki/index.php?title=Метод_ближайших_соседей
- k-nearest neighbors algorithm. Материал из свободной энциклопедии Википедии. [Электронный ресурс]. – Режим доступа: http://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
- Информационно-аналитический ресурс, который посвящен вопросам ИИ – [Нейронные сети Электронный ресурс]. – Режим доступа: http://neural-networks.ru/Arhitektura-LVQ-seti-51.html
- Потапов А.С. Распознавание образов и машинное восприятие. – СПб.: Политехника, 2007. – 548 с.
- Волченко Е.В. Метод построения взвешенных обучающих выборок в открытых системах распознавания // Доклады 14-й Всероссийской конференции «Математические методы распознавания образов (ММРО-14)», Суздаль, 2009. – М.: Макс-Пресс, 2009. – С. 100–104.
- Загоруйко Н.Г. Прикладные методы анализа данных и знаний. – Новосибирск: Издательство Института математики, 1999. – 261 с.
- Семенова А.П., Волченко Е.В. Исследование принципов формирования образующих множеств при построении взвешенной обучающей выборки w-объектов // Інформаційні управляючі системи та ком'пютерний моніторинг (ІУС-2014). Матерiали V мiжнародної науково-технiчної конференцiї студентiв, аспiрантiв та молодих вчених. – Донецьк, ДонНТУ – 2014. – Т. 1 – С. 464–469.
Important note
The master's work is not completed yet. Final completion is on December 2014. Full work text and subject materials can be obtained from the author or her adviser after this date.
