Автор: Трегубова Ю. A., Вороной С.М.
Источник: Інформаційні управляючі системи та комп’ютерний моніторинг (ІУС КМ - 2014) - 2014 / Матерiали V Всеукраїнської науково-технічної конференції студентів, аспірантів та молодих вчених. – Донецьк, ДонНТУ – 2014, Том 2, с. 297–302.
Трегубова Ю. A., Вороной С.М. Алгоритмы повышения эффективности тематического поиска в Интернет. Рассмотрен метод тематического поиска, основанный на повышении релевантности результатов поиска по ключевым словам путем применения процедур фильтрации и классификации. Рассмотрены модификации алгоритмов Байеса и разделяющих гиперплоскостей, обеспечивающие низкую сложность вычислений.
Ключевые слова: тематический поиск, фильтрация, классификация, метод Байеса, разделяющая гиперплоскость, низкая сложность вычислений.
В области информационного поиска отдельно выделяется задача тематического поиска, то есть целенаправленного поиска документов, относящихся с высокой степенью релевантности к определенной теме, заявленной пользователем. Широко применяемые в Интернет машины поиска по ключевым словам, малоэффективны с точки зрения поиска тематической информации из-за большого уровня шума (ссылок на нерелевантные документы), ограниченных возможностей языков запросов и формы представления результатов поиска [1]. В этих условиях разработка метода тематического поиска в Web, повышающего качество поиска по сравнению с традиционными методами в условиях долговременности информационной потребности пользователя и динамичности пространства поиска, представляется актуальной.
Цель статьи — провести анализ метода повышения эффективности тематического поиска и предложить модификации алгоритмов тематически-ориентированной классификации текстовых документов.
Информационная потребность пользователя представляется в виде пары {q, D}, где q — запрос по ключевым словам, использующийся для первичного отбора документов из Web, D = {D+, D-} — обучающая выборка, описывающая тему, интересующую пользователя. Данная обучающая выборка содержит примеры релевантных теме документов (D+) и нерелевантных документов (D-).
Общий вид технологии тематического поиска на основе предлагаемого метода представлен на рис. 1.
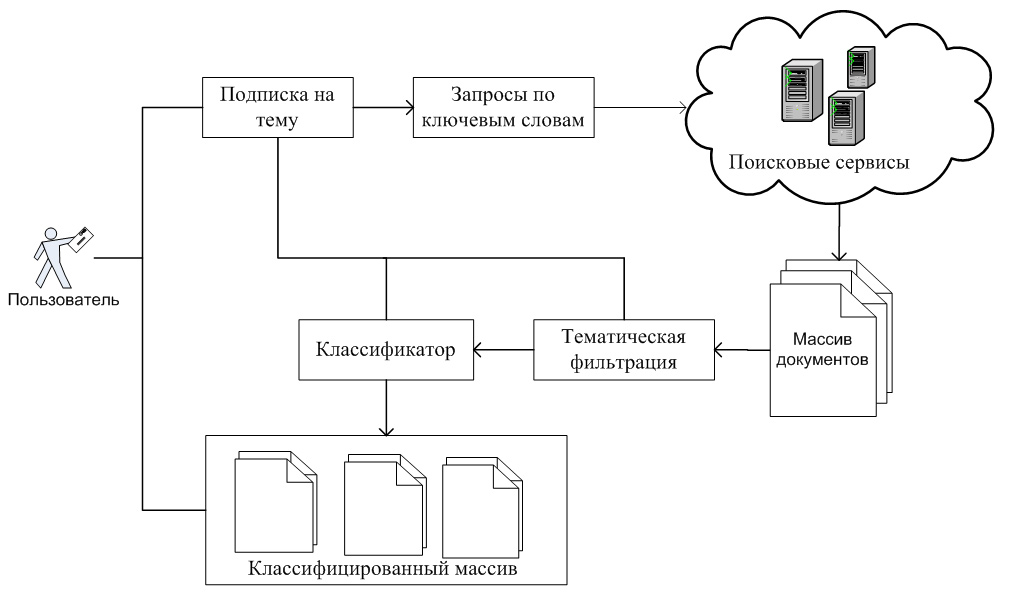
Рис. 1. Основные этапы тематического поиска
Процесс поиска реализуется в два этапа:
1. Отбор документов из Web, соответствующих запросу по ключевым словам q с помощью глобальных систем поиска по ключевым словам. Данный этап позволяет с одной стороны обеспечить высокую полноту поиска, а с другой — существенно сократить объем обрабатываемой на следующем этапе информации.
2. Уточнение результатов поиска с помощью классификатора, обученного на предоставленной пользователем обучающей выборке D. Этот этап позволяет обеспечить высокую точность результатов поиска.
Для реализации классификации результатов поиска пользователю необходимо в обучающей выборке множество релевантных документов D+ разбить на подмножества, описывающие интересующие пользователя подтемы. В этом случае обучающая выборка будет представлять собой множество D={D1+, D2+, D3+,…, Dn+, D-}, где Di+ — обучающая выборка i-ой подтемы, n — общее количество подтем.
Таким образом, в этом случае классификатор будет решать две задачи: задачу тематической фильтрации (бинарной классификации) и задачу разбиения множества релевантных теме документов на подтемы (задачу классификации с большим количеством классов в обучающей выборке).
Рассмотрим более детально второй этап метода — задачу уточнения результатов поиска.
Формальная постановка задачи классификации текстов выглядит следующим образом.
Предполагается, что алгоритм классификации работает на некотором множестве документов D={di}
Все множество документов разбивается на непересекающиеся подмножества классов
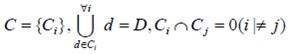
Задачей классификации является определение класса, к которому относится данный документ.
Задачей этапа предварительной обработки документов является выделение признаков документа и сопоставления им весов. В простейшем случае набором признаков документа будет содержащийся в нем набор лексем, а в качестве веса используется количество вхождений лексемы в документ. При обработке Web-страниц необходимо предусмотреть автоматическое определение кодировки, поскольку явно она указывается не во всех документах. Для лексем, входящих в заголовки, названия, ключевые слова, текст ссылки и т.п. производится увеличение веса.
Для обеспечения масштабируемости и приемлемой вычислительной сложности можно использовать в качестве базовых алгоритмы Байеса и разделяющих гиперплоскостей с линейной (O(N)) сложностью обучения.
Метод Байеса это простой классификатор, основанный на вероятностной модели, имеющей сильное предположение независимости компонент вектора признаков [2,3]. Обычно это допущение не соответствует действительности и потому одно из названий метода - Na?ve Bayes (Наивный Байес). Простой байесовский классификатор относит объект X к классу Ci тогда и только тогда, когда выполняется условие: P(Ci|X)>P(Cj|X), где P(Ci|X) — апостериорная вероятность принадлежности объекта X к классу Ci, P(Cj|X) — апостериорная вероятность принадлежности объекта X к произвольному классу Cj, отличному от Ci. Т.е. апостериорная вероятность принадлежности объекта к классу Ci больше апостериорной вероятности принадлежности объекта к любому другому классу.
Алгоритм Байеса в настоящее время оценивается как сравнительно низкокачественный алгоритм. Основными причинами являются проблемы, связанные с принципом независимости признаков и некорректной оценкой априорной вероятности в случае существенно неравномощных обучающих выборок.
Правило определения класса для документа в алгоритме Байеса можно представить следующим образом:
 ,
,
где fw - количество вхождений признака w в документ,

Для борьбы с низким качеством, используется парадигма класса-дополнения, то есть вместо вероятности принадлежности лексемы классу оценивается вероятность принадлежности лексемы классу-дополнению C’ (следует учесть, что p(w|C) ~ 1-p(w|C’)).Используя принцип сглаживания параметров по Лапласу, получаем следующее правило:
 ,
,
где NCw — количество вхождений признака во все классы кроме данного, NC — общее количество вхождений всех признаков в класс-дополнение, |V| — размерность словаря признаков.
Следует отметить, что данная эвристика работает только в том случае, если количество классов |С| >> 2.
Для задачи бинарной классификации рассмотренные модификации не позволяют приблизить метод Байеса по качеству к лучшим показателям т.к. использование классов-дополнений не дает никаких изменений, поэтому для данного случая предлагается использовать алгоритм, основанный на линейном дискриминанте Фишера. В основе алгоритма лежит поиск в многомерном признаковом пространстве такого направления w, чтобы средние значения проекции на него объектов обучающей выборки из классов максимально различались.
Мерой разделения спроецированных точек служит разность средних значений выборки. Желательно, чтобы проекции на прямой были хорошо разделены и не очень перемешаны. Проекцией произвольного вектора X на направление w является отношение (wXt)/|w|). В качестве меры различий проекций классов на w используется функционал — индекс Фишера [4,5]:
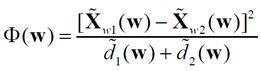 , (1)
, (1)
где 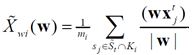 — среднее значение проекции векторов, описывающих объекты из класса
— среднее значение проекции векторов, описывающих объекты из класса  ,
,
 — выборочная дисперсия проекций векторов, описывающих объекты из класса.
— выборочная дисперсия проекций векторов, описывающих объекты из класса.
Линейный дискриминант Фишера определяется как линейная разделяющая функция wtx, максимизирующая функционал Ф(W). Для более полного разделения классов в алгоритме строится несколько направлений соответствующих дискриминанту Фишера. Вдоль одного направления можно эффективно разделить часть обучающих экземпляров. Точки отсечения для положительных и отрицательных экземпляров вдоль каждого направления запоминаются при обучении алгоритма.
Схема обучения алгоритма представлена на рис. 2.
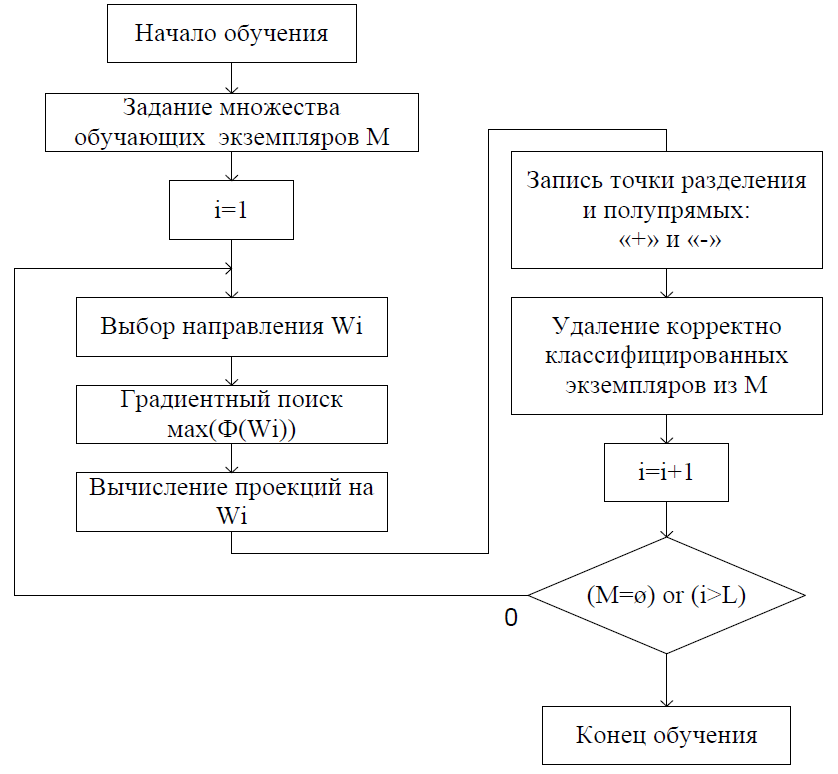
Рис. 2. Блок схема обучения алгоритма бинарной классификации
Классификация экземпляра производится по следующему алгоритму:
цикл i = 1... L (количество направлений)
Анализируем i-oe направление:
В дальнейшем предполагается усовершенствование подготовки документов к применению методов машинного обучения путем выбора более эффективной формы оценки весов признаков документа, учитывающей ссылки. Проведение экспериментов по усовершенствованию байесовского классификатора документов для тем с большим количеством неравномощных подтем. Разработка критериев оценки качества поиска с применением предложенных алгоритмов.
Проведен анализ существующих подходов к повышению релевантности тематического поиска путем классификации результатов выдачи поисковых систем. Разработаны алгоритмы фильтрации и классификации с малой вычислительной сложностью. Классификация результатов поиска позволяет существенно сократить время поиска нужной информации. Таким образом, введение дополнительной классификации на получаемые пользователем документы позволяет повысить удобство использования поисковой системы и позволяет быстрее ориентироваться в полученных результатах.