Авторы: K.L. Sumathy, M. Chidambaram
Перевод: Ю.А. Трегубова
Источник: International Journal of Computer Applications [Электронный ресурс]. – Режим доступа: http://research.ijcaonline.org/volume80/number4/pxc3891685.pdf
В настоящее время наблюдается увеличивающаяся тенденция в использовании компьютеров для того, чтобы хранить документы. Как результат, существенный объем данных хранится в компьютерах в форме документов. Документы могут иметь различное представление, например, структурированные документы, частично структурированные документы и неструктурированные документы. Восстановление полезной информации из огромного объема документов является очень сложной задачей. Интеллектуальный анализ текста является важной областью исследования, поскольку он пытается получить знания из неструктурированного текста. Эта статья дает краткий обзор понятий, приложений, проблем и инструментов, используемых для анализа текста.
Общие термины: Классификация документов, Поиск.
Ключевые слова: Анализ текста, информационный поиск.
В современном мире текст является наиболее распространенным средствам для того, чтобы обмениваться информацией. Данные, хранимые в компьютере, могут быть в любой из форм:
Данные, хранимые в базах данных, являются примером для структурированных наборов данных. Примерами для частично структурированных и неструктурированных наборов данных могут быть электронные письма, большие текстовые документы и файлы HTML и т.д. Огромный объем данных сегодня сохранен в текстовых базах данных, а не в структурированных базах данных.
Анализ текста определяется как процесс обнаружения скрытого, полезного и интересного образца из неструктурированных текстовых документов. Анализ текста также известен как процесс поиска знаний в текстовом интеллектуальном анализе данных. Приблизительно 80% корпоративных данных находится в неструктурированном формате. Информационный поиск в неструктурированном тексте очень сложен, поскольку он содержит большое количество информации, требующей использование специфических методов и алгоритмов обработки для извлечения полезных знаний. Поскольку наиболее распространённой формой для хранения информации является текст, интеллектуальный анализ текста представляется более важным процессом, чем интеллектуальный анализ данных (data mining).
Интеллектуальный анализ текста является междисциплинарной областью, которая включает сбор данных, обработку web-данных, информационный поиск и извлечение, компьютерную лингвистику и обработку естественного языка.
Содержание статьи представлено следующим образом. Во втором раздел описан общий процесс интеллектуального анализа текста. В третьем разделе представлены шаги, необходимые для выполнения анализа текста. В четвертом разделе описана область применения.
Интеллектуальный анализ текста можно разделить на две фазы:
Фаза очистки текста, преобразовывает исходное представление текстовых документов формы в выбранную промежуточную форму. Извлечение знаний, как видно из названия, получает шаблоны или знания из промежуточной формы. Промежуточная форма (Intermediate Form, IF) может быть частично структурированной (например, концептуальное представление графа) или структурированной (например, реляционное представление данных). Промежуточная форма может представлять собой документ, где каждая сущность представляет собой другой документ или может представлять собой определенной понятие, где каждая сущность представляет собой объект или набор данных из определенной предметной области.
Анализ промежуточной формы документов предоставляет образцы и взаимосвязи среди всех документов. Примером является кластеризация, визуализация и категоризация документов.
Анализ промежуточной формы понятий предоставляет образцы и взаимосвязи среди объектов или других понятий. Такие операции как прогнозирующее моделирование и ассоциативное исследование принадлежат этой категории анализа. Промежуточная форма документа может быть преобразована в промежуточную форму понятия путем извлечения релевантной информации, относящейся к объектам из определенной области интересов. Из этого следует, что промежуточная форма документа обычно не зависит от определенной предметной области. Например, набор новостных лент при выполнении фильтрации текста преобразовывает каждый документ в вид, пригодный промежуточной формы в виде документа. Затем можно выполнить обработку знаний с целью организации статей согласно их содержанию для целей визуализации и навигации. Для извлечения знаний в определенной предметной области промежуточная форма документа может быть преобразована в промежуточную форму понятия в зависимости от поставленных требований. Например, можно извлечь информацию, связанную с определенным «товаром» из промежуточной формы документа и сформировать базу данных товаров для предоставления знаний о них.
Общий процесс интеллектуального анализа данных представлен на схеме на рис. 1.
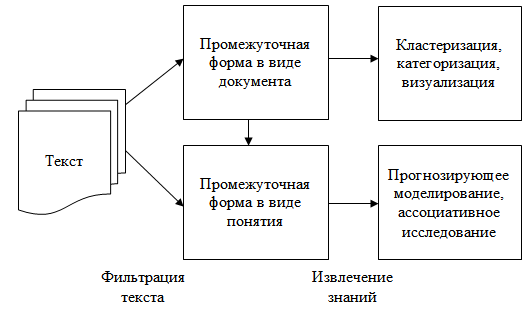
Рис. 1. Общий процесс интеллектуального анализа текста
Шаги выполнения анализа текста представлены ниже.
Предварительная обработка разделена на следующие шаги:
Первый шаг предварительной обработки текста далее разделен на:
Токенизация. Текстовые документы содержат набор сущностей. На этом шаге выполняется разделение текста на отдельные слова с удалением пробелов и знаков препинания.
Удаление «стоп-слов». На этом шаге производится удаление HTML и XML тегов, которые могут быть, если анализируется текст, полученный из сети Интернет. Далее из текста удаляются артикли (например, для английского языка это «a», «is», «of» и другие).
Определение происхождения слов представляет собой процесс идентификации корней определенных слов. Есть в основном два типа происхождения: флективный и деривационный. Наиболее распространённым алгоритмом определения происхождения слов является алгоритм швейцара.
Текстовый документ представляется словами, из которых он состоит и информации об их происхождении. Есть два подхода, используемые для представления документа: мешок слов и векторные пространства слов.
Это также известно как поиск переменных. Это — процесс отбора подмножества важных признаков для использования в создании моделей. Эта фаза, в основном выполняет удаление тех признаков, которые избыточны или не важны. Выбор признаков является подмножеством более общей области извлечения признаков.
В этом пункте интеллектуальный анализ текста становится сбором данных. Методы распознавания данных, такие как кластеризация, классификация, информационный поиск и т.д., могут использоваться также и для интеллектуального анализа текста.
На этом шаге происходит анализ результатов в зависимости от поставленных целей.
Интеллектуальный анализ текста является междисциплинарной областью, которая включает такие области как информационный поиск, извлечение знаний, сбор данных, компьютерная лингвистика и обработка естественного языка. Области применения анализа текста представлены ниже.
Это процесс автоматического извлечения структурированной информации из неструктурированных и/или частично структурированных текстовых документов. Система IE включает в себя идентификацию сущностей, таких как имена людей, компаний и местоположений, признаков и отношений между сущностями. Это выполняется благодаря распознаванию образов. IE — процесс поиска предопределенных последовательностей текста в документах. Так как IE рассматривает проблему преобразования набора текстовых документов в более структурированную базу данных, то база данных, построенная модулем извлечения информации, может быть предоставлена модулю извлечения знаний для дальнейшего анализа и обработки.
Представляет собой методы, используемые для представления, хранения и доступа единиц информации, где данные представлены в основном в формате текстовых документов, новостных лент и книг, и которые могут быть получены из базы данных по запросу пользователя. Информационный поиск рассматривается как расширение поиска по документам, где документы обрабатываются для сохранения или извлечения определенной информации, запрошенной пользователем. Система IR позволяет нам сужать набор документов, которые относятся к определенной проблеме. Наиболее известными системами информационного поиска являются поисковые системы Google. Системы IR могут значительно ускорить анализ, сокращая количество обрабатываемых документов.
Обработка естественного языка является самой активной проблемой в области искусственного интеллекта. NLP — исследование естественного языка таким образом, чтобы компьютеры могли понять естественные языки, подобные тем, которые использует человечество. Обработка естественного языка используется вместе с генерацией (Natural Language Generation, NLG) и распознаванием естественного языка (Natural Language Understanding, NLU). NLG удостоверяется, что произведенный текст грамматически правилен и быстр. Большинство систем NLG включает синтаксический анализатор, чтобы убедиться, что таким грамматическим правилам, как подчиненное соглашение о глаголах повинуется текстовый планировщик, чтобы решить, как строить предложения, параграф и другие части. Самым распространенным примером использования NLG является машинный перевод. NLU состоит из, как минимум, одного из следующих компонент: токенайзер, лексический анализатор, синтаксический и семантический анализатор.
Относится к нахождению релевантной информации или обнаружению знания в больших объемах данных. Интеллектуальный анализ данных пытается обнаружить статистические правила и образцы автоматически от данных. Инструменты интеллектуального анализа данных могут предсказать поведение и будущие тенденции позволяя принимать позитивные решения на основе полученных знаний. Общая цель процесса анализа данных состоит в извлечении информации из набора данных и её преобразования для дальнейшего анализа.