
Abstract on the topik of final work
Contents
- 1. Purpose and objectives
- 2. The relevance of the topic
- 3. Prospective scientific novelty
- 4. ПPlanned practical results
- 5. A review of research and development on the subject
- 5.1 A review of research and development on the subject. Global level
- 5.2 A review of researches and development on the subject. National level
- 5.3 A review of researches and development on the subject. Local level
- 6. The problems of access restriction to web resources in the educational systems
- 7. Computer Security of Web resources for users of intelligent educational systems
- 8. Algorithms for determining information security Web resources for users of intelligent education systems
- 9. Directions of the algorithm improvement
- 10. Findings
1. Purpose and objectives
The aim of this paper is to develop algorithms for improving the safety of access to external information resources of corporate educational networks taking into account their security threats, as well as contingent features user security policies, architectural decisions, resource provision.
Based on the aim, the following tasks are resolved:
1. 1. Complete analysis of the major threats to information security in educational networks.
2. Develop a method of restricting access to inappropriate information resources in educational networks.
3. Develop algorithms allowing to scan web pages, search direct connections and download files for further analysis of potentially malicious code on websites.
4. Develop the algorithm for identification of unwanted information resources on the websites.
2. The relevance of the topic
Modern intelligent tutoring systems are Web-based, they provide an opportunity to work with different types of local and remote educational resources for their users. The problem of a secure use of information resources (IR), viewed on the Internet, is becoming ore and more important [1,2]. One of the methods used for solving this problem is to restrict access to inappropriate information resources.
Operators providing educational institutions with Internet access must ensure restricted access to undesirable IR. Restriction is accomplished by filtering operators on lists regularly updated in due course. However, taking into account the users of the educational networks, it is advisable to use a more flexible learning system that will dynamically detect unwanted resources and protect users from them.
In general, access to undesirable resources cause the following threats: illegal propaganda and anti-social activities, such as political extremism, terrorism, drugs, pornography and other materials; distraction of students from the use of computer networks for educational purposes; difficulties in access to the Internet due to overloaded external channels with limited bandwidth; resources listed above are often used for the insertion of malware with its threats [3,4].
Existing systems of access restriction to network resources have the ability to check for compliance with the specified constraints not only individual packages, but also their content – content transmitted through the network. Currently, the following methods of filtering web-content are used for content filtering systems: by DNS name or a specific IP-address, by keywords in web-content, and by file type. To block access to certain web site or a group of web sites, you must specify a number of URL, the content of which is undesirable. URL-filtering provides careful monitoring of network security. However, it is impossible to know in advance all possible unacceptable URL-addresses. Additionally, some web-sites with undesirable content do not work with the URL, and solely use IP-addresses.
One way of solving the problem is to filter content obtained via HTTP. The disadvantage of the existing content filtering systems is the use of access control lists, generated statically. To fill them out, the developers of commercial content filtering systems employ staff who divide content into categories and rank the records in the database [5].
To overcome the disadvantages of existing systems for content filtering education networks, it is relevant to develop filtration systems for web–traffic with dynamic definition of the web-resource category based on the content of its pages.
3. Prospective scientific novelty
The algorithm of access restriction for users of intelligent tutoring systems on undesirable Internet sites based on dynamic development of the list of access to information resources through their deferred classification.
4. Planned practical results
These algorithms can be used in access restriction systems to restrict access to undesired resources in educational computer systems.
5. A review of research and development on the subject
5.1 A review of research and development on the subject. Global level
The problem of information security is analyzed in the works of such famous scientists as: N. N. Bezrukov, P.D. Zegzhda, A.M. Iwashko, A.I. Kostogryzov, VI Kurbatov, Lendver K., D. McLean, A.A. Moldovyan, N.A. Moldovyan, A.A.Malyuk, E.A.Derbin, R. Sandhu, JM Carroll, and others. However, despite of the overwhelming amount of text sources in the corporate and public networks, the field of the development of methods and data protection systems is currently lack of researches aimed at the security threat analysis and researches purposed to restrict access to undesirable in computer education with the ability Web access.
5.2 A review of researches and development on the subject. National level
In Ukraine, a leading researcher in this area is Domarev V.V. [6]. His doctoral research is dedicated to the development of the integrated security systems. He is the author of the books: "Safety of information technology. Protection systems design methodology", "Safety of information technology. System Approach", etc., and the author of over 40 scientific articles and publications.
5.2 A review of researches and development on the subject. Local level
In the Donetsk National Technical University, Himka S.S. worked on the development of models and methods to create a system of information security for corporate network according to various criteria [7]. Protection of information in educational systems was examined by Zanyala Y.S. [8].
6. The problems of access restriction to web resources in the educational systems
Today the development of information technology allows us to talk about two aspects of the description of Internet resources – content and access infrastructure. The access infrastructure is commonly interpreted as the set of hardware and software tools that provide data in the format of IP-packets; and content is defined as the set of representation forms (e.g., in the form of a sequence of characters in a particular encoding) and content (semantics) of information. Among the characteristic features of this description it is necessary include the following:
1. The independence of content from infrastructure access;
2. Continuous qualitative and quantitative changes of content;
3. Emergence of new interactive information resources ("living magazine", social networking, free encyclopedia, etc.), in which users are directly involved in the creation of online content.
In solving problems of access control of information resources issues of security policy are important, they can be solved with respect to the characteristics of the network infrastructure and the content. The higher description level of the information security model is, the more access control focuses on semantics network resources. Obviously, the MAC-and IP-addresses (network and channel levels of interaction) of the network devices interfaces can not be bound to a data category, as one and the same address may represent different services. Port numbers (transport lavel, as a rule, give an idea of the type of service, but does not characterize the quality of information provided by this service. For example, it is impossible to put a certain Web-site to one of the semantic categories (media, business, entertainment, etc.) only on the basis of information transport layer. The ensuring of information security at the application level becomes very close to the concept of content filtering, that is the access control, which takes into account the semantics of network resources. Therefore, the more the content is focused on the access control system, the more differentiated approach with respect to different categories of users and resource information can be realized with its help. In particular, semantically oriented control system is able to effectively restrict students' access to the resources which are not connected with the educational process.
To provide flexible control of using Internet resources, the operating company is required to establish proper policy of resources usage by the educational institution. This policy can be implemented either "manually" or automatically. "Manual" realization means that the company has a dedicated staff who are monitoring the activity of users of the educational institution by means of live or magazines routers, proxy servers or firewalls. Such monitoring is problematic because it requires much work. To provide flexible control of the use of Internet resources, the company must give the administrator a tool for implementing the policy of resources organization. Content filtering serves this purpose. Its essence lies in the decomposition of objects on the information exchange components, content analysis of these components determining their compliance with the policy parameters which states the adopted rules of Internet resources usage and implementation of an action based on the results of such analysis. In the case of filtering Web traffic the information exchange objects are Web requests, the contents of the Web pages, files transmitted by users, etc.
The members of education organization have access to the Internet only through proxy–server. Every time you try to access one or another resource, proxy-server checks if the resource is not listed in a special database. If a resource is located at the base of banned resources, the access is blocked, and the user gets a message on the screen.
ВIf the requested resource is not in the database of prohibited content, the access is available, but a record of your visit to this resource is fixed in the special service log. Once a day (or other period) proxy-server generates a list of the most visited resources (in the form of a list of URL) and sends it to the experts. Experts (system administrators) use the appropriate method to check the a list of resources and determine their character. If the resource is non targeted, expert performs its classification (pornography, games, etc.) and makes a change to the database. After making changes, an update of the database is automatically forwarded to all proxy-servers connected to the system.
The problems of filtering of non–target resources are mentioned below. The centralized filtering requires high performance equipment of the central node, high bandwidth communication channels at the central site, the failure of the central node leads to a complete failure of the entire filtration system.
In case of decentralized filtering "on the ground" directly on workstations or organization serves greater cost of deployment and support can be viewed.
ПWhen address filtering on the "submitting a request" stage is made, no preventive response to unwanted content is viewed and there are difficulties while filtering "masquerading" websites.
Content filtering requires processing large amounts of information in the preparation of each resource and complex processing of resources prepared using such means as Java, Flash, etc.
7. Computer Security of Web resources for users of intelligent educational systems
It’s vital to consider the ability to control access to information resources using common solution based on the principle of hierarchical aggregation means to control access to Internet resources. The access restriction to unwanted IR of ITS can be achieved through a combination of technologies such as firewalling, the use of proxy servers, analysis of abnormal activities to intrusion detection, bandwidth limiting, filtering based on content analysis, filtering based on access lists. Thus, one of the key problems is the formation and use of topical lists of restricting access.
Filtering the unwanted resources is conducted in accordance with existing regulations on the basis of published lists in the prescribed manner. Access restriction to other information resources is based on specific criteria developed by educational network operator.
User access to the potentially forbidden resource with a frequency below the set is valid. Analysis and classifications are a subject only for requested resources, those for which the number of user requests exceeds a certain threshold value.
Scanning and analysis are carried out some time after exceeding the number of queries the threshold value (between minimum load external channels).
Automated classification of resources is made at the corporate client's server – the system owner. Time classification is determined by the method used, which is based on the concept of deferred resource classification. It is assumed that users access to even unwanted resources with a frequency below the set is valid. This avoids costly classification "on the fly". Analysis and automated classification are made for only requested resources, that is resources, frequency of user requests of which exceeds a predetermined threshold. Scanning and analysis carried out some time after exceeding the number of queries according to the threshold value (in the period of minimum load external channels). The method implements the scheme and dynamically build three lists: the "black", "white" and "gray". Resources located in the "black list" are of prohibited access. "White" list contains proven resources. The "gray" list contains resources that had been demanded by the users at least once, but did not pass classification.
Initial formation and further "manual" adjustment of the "black" list is based on official information about the addresses of illicit resources provided by the Authority. The initial contents of the "white" list are made of recommended for use resources. Any request for a resource not related to the "black list" is satisfied. In case the resource is not in the "white" list, it is placed in the "gray" list, where the number of requests to the same resource is fixed. If the demand exceeds a certain threshold, the automated classification of the resource is made, the resource goes to "black" or "white" list after this procedure.
8. Algorithms for determining information security Web resources for users of intelligent education systems
АAlgorithm of access restrictions. The access restriction to undesirable Internet sites is based on the following definition of risk of unwanted access to IR. The risk of unwanted access to the i IR, referred to the k class of IR, will be called an amount proportional to the expert evaluation of damage to this type of unwanted IR or the user's identity and the number of requests to the resource within a given period of time:

By analogy with the classical definition of risk as the product of the probability of a threat on the cost of damage caused, this definition treats risk as the expectation of possible damage from access to inappropriate IR. The magnitude of the expected loss is determined by the degree to which the individual IR user, which in turn is directly proportional to the number of users who have experienced this effect.
In analyzing any web resource, in terms of the desirabile of unwanted access, you must consider the following basic components of each of its page content, such as text and other (graphics, photos, video) information provided on this page; content posted on other pages of the same website (internal links to get the content of the pages can be downloaded on regular expressions); Connection to other sites (both in terms of the ability to download viruses and Trojans), and in terms of having inappropriate content.
An algorithm for determining undesirable webpage. To classify the content of web pages it is necessary to solve the following problems: the setting of classification categories; the extraction of information which can be automatically analyzed; the creation of the collections of classified texts; building and training of the classifier, working with the obtained data sets.
Training set to classify texts is analyzed, highlighting the terms – the most frequently used word forms as a whole and for each classification the category separately. Each source text is represented as a vector which components are the characteristics of the occurrence of this term in the text. To avoid the sparse vectors and reduce their dimensionality, it is advisable to make word forms lead to the initial form of morphological analysis methods. Thereafter, the vector must be normalized, that allows to achieve a more accurate result of classification. For one web page it is possible to generate two vectors for the information displayed to the user and for the text provided by the search engines.
There are various approaches to building web page classifiers. The most commonly used are [9–13]: a Bayesian classifier; neural networks; linear classifiers; a support vector machine (SVM). All of the above methods require training on the training collection and testing on a test collection. For binary classification, you can choose a naive Bayesian decision, suggesting independence for each characteristic in the vector space. We assume that all resources should be classified as desirable and undesirable. Then the entire collection of samples of web page text is divided into two classes: C = {C1, C2} and the a priori probability of each class P (Ci), i = 1,2. With a sufficiently large sample collections we can assume that P (Ci) is the ratio of the number of samples of class Ci to the total number of samples. For a sample to be classified as D of the conditional probability P (D / Ci), according to Bayes' theorem value P (Ci / D) may be derived:

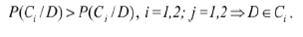
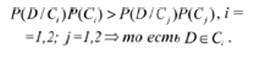
Assuming independence of terms of the vector space, we can obtain the following:

In order to more accurately classify texts whose characteristics are similar (for example, to distinguish between pornography and literature, which describes the erotic scenes), you must enter the weights:
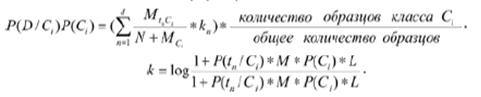
9. Directions of the algorithm improvement.
In future it is supposed to develop an algorithm to detect the introduction of malicious code into web-page and compare the Bayesian classifier with support vector method.
10.Findings
The analysis of the problem of limiting access to web resources in the educational systems is made. We’ve distinguished the basic principles of filtration for earmarked resources for proxy-servers based on the formation and use of relevant lists of access restriction. We developed the access restriction algorithm to restrict the usage of undesirable resources by using lists, allowing dynamically generate and update IR lists on the basis of their content to the frequency of visits and user characteristics. To identify inappropriate content an algorithm based on the naive Bayesian classifier is developed.
Список источников
- Зима В. М. Безопасность глобальных сетевых технологий / В. Зима, А. Молдовян, Н. Молдовян. – 2–е изд. – СПб.: БХВ–Петербург, 2003. – 362 c.
- Воротницкий Ю. И. Защита от доступа к нежелательным внешним информационным ресурсам в научно-образовательных компьютерных сетях / Ю. И. Воротницкий, Се Цзиньбао // Мат. XIV Межд. конф. «Комплексная защита информации». – Могилев 2009. – С. 70–71.
- Varatnitsky Y. Web Application Vulnerability Analysis and Risk Control / Y. Varatnitsky, Xie Jinbao // J. of Computer Applications and Software. – 2010, №10. – P. 279–280, 287.
- Varatnitsky Y. Based on source code analysis detection method of web–based malicious code / Y. Varatnitsky, Xie Jinbao //J. of Computer & Information Technology. – 2010, №1–2. – P. 49–53.
- Hill B. Solutions for Web–content filtering / / Open systems [electronic document] (http://www.osp.ru/win2000/2004/05/177073/).
- Домарев В.В."Безопасность информационных технологий. Системный подход" – К.:ООО ТИД «Диасофт», 2004.–992 с
- Химка С. С. Разработка моделей и методов для создания системы информационной безопасности корпоративной сети предприятия с учетом различных критериев // реферат выпускной работы магистра Факультет вычислительной техники и информатики ДонНТУ. 2009.
- Заняла Ю.С.Защита информации в обучающих системах // реферат выпускной работы магистра Факультет вычислительной техники и информатики ДонНТУ. 2007.
- Маслов М. Ю. Автоматическая классификация веб-сайтов / М. Ю. Маслов, А. А. Пяллинг, С. И. Трифонов. – Режим доступа: rcdl.ru/doc/2008/230_235_paper27. pdf. – Дата доступа: 08.11.2011.
- Wu lide. Large Scale Text Process / Wu lide. ShangHai: Fudan University Press, 1997. – 180 p.
- Zhang Yizhong.The automatic classification of web pages based on neural networks / Zhang Yizhong, Zhao Mingsheng, Wu Youshou // Neural Information Processing, ICONIP2001 Proceedings, 2001. – Р. 570–575.
- Hwanjo Yu. Web Page Classification without N Chang // IEEE Transactions on Knowledge and Data Engineering, January, 2004. – Vol. 16, №1. – P. 70–81.
- Воротницкий Ю. И. Принципы обеспечения безопасности образовательных информационных сетей / Ю. И. Воротницкий, Се Цзиньбао // Межд. конф.–форум
Информационные системы и технологии
. – Минск, 2009. – Ч. 2.– С.26–29.