Эффективный метод обнаружения лингвистической стеганографии
Источник: Natural Science Foundation of Jiangsu Province of China. – Anhui, University of Science and Technology of China – 2010.
Аннотация
Лингвистическая стеганография скрывает секретные сообщения. Она использует свойства естественного языка, такие как языковая структура, чтобы скрыть сообщения. В этой статье, предложен эффективный метод для обнаружения стеганографии. Метод был сосредоточен на обнаружение небольших размеров текстовых сегментов, до сотни слов. Он выполняется быстро и достаточно точно. Данный метод может быть использован в качестве общего метода для обнаружения наличия скрытых сообщений.1 Введение
Стеганография появилась еще до появления компьютера. В настоящее время, у нас есть огромное количество доступных данных для использования стеганографии и более изощренные методы для ее реализации. Большая часть последних исследований в стеганографии, особенно языковой стеганографии была сосредоточена на том, как скрыть секретные сообщения в обложке СМИ, важно использовать эффективные подходы, чтобы стегоанализ, который обычно пытается обнаружить статистические аномалии в данных обложках, не смог обнаружить скрытое сообщение. Эта статья фокусируется на расследовании обнаружения лингвистической стеганографии в сообщениях. В данной статье предложен метод обнаружения лингвистической стеганографии, с помощью статистических показателей анализа текста. Для работы алгоритма не требуются ни какие дополнительные данные, кроме самого сегмента текста.2 Похожие работы
2.1. Лингвистическая стеганография
Самый простой метод изменения текста для встраивания сообщения – замена слов их синонимами так, чтобы значение измененного предложения сохранилось как можно больше. Один подход стеганографии, который основывается на синонимах, предложен Винштайном [2]. Есть некоторые другие подходы. Среди них NICETEXT и TEXTO являются самыми известными.Система NICETEXT [3], [4] генерирует как будто естественный текст шифрования, используя смесь замены слов и вероятностные бесконтекстные грамматики . В системе используется таблица словаря и шаблон стиля. Шаблон стиля может быть сгенерирован, используя вероятностные бесконтекстные грамматики или демонстрационный текст. Словарь в произвольном порядке генерирует последовательность слов, в то время как стиль шаблона выбирает естественные последовательности частей речи, или управляет генерацией слов. Система NICETEXT была предназначена, чтобы защитить частную жизнь криптограмм, чтобы избежать обнаружения цензорами.
TEXTO [5] - текстовая программа стеганографии разработанная для преобразования, кодируемых программой uuencode или pgp, ASCII данных в английские предложения. Это было сделано, чтобы упростить обмен двоичными данными, особенно зашифрованными. Работает TEXTO точно так же, как и простой шифр подстановки. Не все слова в получающемся тексте значительные, только те существительные, глаголы, прилагательные и наречия, которые раньше заполняли предварительно установленные структуры предложения. Пунктуация и "соединение" слов (или любых других слов не в словарь), проигнорированы.
2.2. Лингвистический стегоанализ
В статье [7] представлена атака против систем на основе замены синонимов, особенно система представленная Винштеймом. Экспериментальная точность этого метода на классификации составляла 84.9% , для неизмененного предложения – 61.4%. Другой алгоритм обнаружения был предложенный в статье [8], предложено использовать измерения корреляция между предложениями. Точность обнаружение, используя этот алгоритм, составила 76%. Кроме того, первый метод потребовал, чтобы большая партия вычисления вычислила большое количество параметров языка модели, в то время как второй требует базы данных правил.Это исследование показали недостатки последних двух подходов стеганографии, стремясь точно обнаруживать скрытое сообщение в маленьком текстовом сегменте. Для создания нового метода использовалась подобная энтропия и информация о статистических переменных, чтобы различить stego-текст сегменты и нормальные текстовые сегменты.
3 Предложенный метод
3.1 Определение статистических переменных
Сначала определяется измерение счета, чтобы указать вхождение слов в тексте обложки. Пусть C общее количество вхождений всех слов в тексте обложке, слово x одно из слов. У слова x есть n вхождений, тогда роль для слова x вычисляется с помощью формулы на рисунке 1.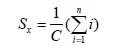
Рисунок 1 – Формула для расчета роли слова x
Уравнение подобно уравнению, которое вычисляет частоту слова x, за исключением того, что увеличивается счет, из-за количества вхождений x. Мы можем расценить Sx как вероятность слова x, без рассмотрения того, в каком диапазоне значений это находится. Статистическая переменная об обнаружении (Detection Information, DI), вычисляется по формуле на рисунке 2.
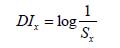
Рисунок 2 – Формула для расчета DI
С вышеупомянутыми определениями Sx и DIx, мы можем определить функцию классификации. Пусть текст обложки содержит слова N. "Информационная энтропия " как статистическая переменная (Detection Entropy,DE), текста обложки определяется по формуле на рисунке 3.
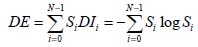
Рисунок 3 – Формула для расчета DE
DE дисперсия, как статистическая переменная, вычисляется по формуле на рисунке 4.
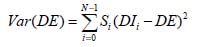
Рисунок 4 – Формула для расчета дисперсии DE
3.2 Описание метода обнаружения
В нашем методе мы применяем следующую процедуру по каждому обнаруженному текстовому сегменту, чтобы вычислить две функции классификации, описанные в разделе 3.1. Во-первых, текстовый сегмент проанализирован к словам, игнорирующим всю пунктуацию и пробелы. Тогда все найденные отличные слова, которые могут быть различными словами первоначально или различные формы тех же слов, и общее количество вхождений всех слов, число вхождения каждого отличного слова вычисленный, счет каждого отличного слова вычисляется уравнением, представленным на рисунке 1.Во-вторых, мы расцениваем счет каждого отличного слова как его вероятность, несмотря на то, что значение не находится в диапазоне [0, 1].
Наконец, DE и Var (DE) вычисляются уравнениями на рисунках 3 и 4, используя Ss и DIs, вычисленные в первый и второй шаг.
После того, как вышеупомянутая процедура применена к обработанному текстовому сегменту, мы получаем функции DE ,классификации и Var (DE), эти значения мы будем использовать позже для SVM классификация. Классификация SVM включает два процесса: обучение и тестирование. Схема SVM представлена на рисунке 5.
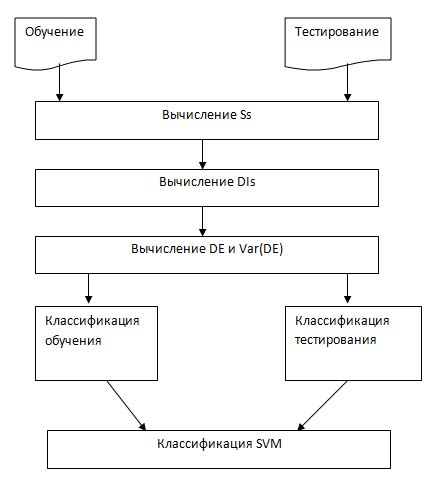
Рисунок 5 – Схема SVM
4. Результаты исследований
4.1. Структура экспериментальных данных
В нашем эксперименте набор экспериментальных данных содержит обучающий набор данных и тестирующий набор данных, оба из которых состоят из хорошего набора данных и набора неправильных данных.Таблица 1 – Экспериментальные данные
| Набор данных | Тип данных | Количество файлов |
| Обучение | Хороший набор | 117 |
| Обучение | Плохой набор | 100 |
| Тестирование | Хороший набор | 146 |
| Тестирование | Плохой набор | 322 |
Как показано в таблице 1, набор данных обучения содержит хороший набор со своими 117 текстовыми сегментами, и плохой набор с его 100 текстовыми сегментами. Набор данных тестирования содержит 146 текстовых сегменты, прибывающие из S-корпуса в хорошем наборе и 322 текстовые сегменты, прибывающие из плохого набора.
4.2. Результаты и обсуждение
Как описано в разделе 4.1, есть сотни текстовых файлов, которые будут протестированы. В эксперименте мы стремимся обнаружить текстовые сегменты с размером, меньшим, чем 5 КБ. Различный размер текстовых сегментов должен быть обнаружен, когда точность обнаружения достаточно высока. Для каждого протестированного текстового файла мы читаем определенный размер сегмента. Результаты обнаружения из текстовых сегментов размера 1 КБ, 2 КБ, 3 КБ, 4 КБ и 5 КБ показаны в таблице 2.Таблица 2 – Результаты обнаружений
| Размер сегмента, КБ | Оценка подсчитанных слов | Удачно | Неудачно | Доля, % |
| 1 | 150-250 | 333 | 135 | 71.15 |
| 2 | 350-450 | 371 | 97 | 79.27 |
| 3 | 500-600 | 403 | 65 | 86.11 |
| 4 | 650-800 | 426 | 42 | 91.03 |
| 5 | 800-1000 | 435 | 33 | 92.95 |
В таблице 2 мы видим, что текстовый размер сегмента довольно маленький для статистического алгоритма, чтобы работать. Каждый текстовый сегмент содержит сотни слов, однако точность относительно высока, особенно когда размер сегмента не меньше, чем 3 КБ.
5 Заключение
В этой статье, был представлен статистический алгоритм для обнаружение лингвистической стеганографии. Алгоритм использует статистические переменные текстового сегмента. Алгоритм базируется на подобных методах NICETEXT, TEXTO. Общая точность на обнаружение stego-текстовых сегментов и нормального текста, 90% когда сегмент размером не больше, чем 5 КБ.Много интересных и новых проблем включены в анализ лингвистических алгоритмов стеганографии, который известен как лингвистический стегоанализ. Производительность методов стегоанализа строго зависит от многих факторов, таких как длина скрытого сообщения и способ генерации текста-обложкии т.д. Наш алгоритм центрируется при обнаружении маленького текстового сегмента.
Список литературы
- K Bennett. Linguistic steganography: Survey, analysis, and robustness concerns for hiding information in text. Purdue University, CERIAS Tech. Report, 2004
- Winstein, Keith. Lexical steganography through adaptive modulation of the word choice hash. Access:http://alumni.imsa.edu/~keithw/tlex/lsteg.ps. Ms.
- Chapman, Mark. Hiding the Hidden: A Software System for Concealing Ciphertext as Innocuous Text. Access:http://www.NICETEXT.com/NICETEXT/doc/thesis.pdf. 1997.
- Chapman, Mark, George Davida and Marc Rennhard. A Practical and Effective Approach to Large-Scale Automated Linguistic Steganography. Lecture Notes in Computer Science, Volume 2200, Springer-Verlag: Berlin Heidelberg. Jan 2001. 156-167.
- K. Maher. TEXTO. Access:ftp://ftp.funet.fi/pub/crypt/steganography/texto.tar.gz
- W. Shu-feng, H. Liu-sheng. Research on Information Hiding. Degree of master, University of Science and Technology of China, 2003.
- C. Taskiran, U. Topkara, M. Topkara et al. Attacks on lexical natural language steganography systems. Proceedings of SPIE, 2006.
- ZHOU Ji-jun, YANG Zhu, NIU Xin-xin et al. Research on the detecting algorithm of text document information hiding. Journal on Communications. Dec. 2004 Vol.25, No. 12, 97-101.