I. ВВЕДЕНИЕ
Оптическое распознавание символов, как правило, сокращенно ОРС, включает в себя компьютерную систему, предназначенную для перевода изображений машинописного или рукописного текста (обычно снятое с помощью сканера) в машиночитаемый и редактируемый текст [1]. ОРС может применяться в таких областях, как распознавание автомобильных номеров транспортного средства, информационный поиск, оцифровка документов, а также в приложениях текст-в-речь.
На протяжении многих лет, ОРС привлекло большое количество исследований, разработаны различные успешные методы распознавания. В этом проекте, я реализую два широко используемых метода ОРС, чтобы перевести изображения букв и цифр в машиночитаемый текст.
II. ПРЕДВАРИТЕЛЬНАЯ ОБРАБОТКА
A. Входные данные
Получены изображения 35 шрифтов из Microsoft Word для машинописных символов и 120 образцов рукописных цифр от 10 человек (захваченных с помощью сканера). Рукописные тексты содержат все заглавные буквы алфавита.
Б. Бинаризация
Отсканированные изображения текстов требуют определенных шагов предварительной обработки, чтобы они находились в подходящем формате для распознавания символов. Так как для большинства алгоритмов ОРС требуются монохромные изображения, мы должны сначала преобразовать цветные или серые изображения в черно-белые, это называется бинаризацией
.
Рис. 1 показывает сравнение между исходным изображением и черно-белым вариантом. После этого оригинальное RGB изображение преобразовывается в серое, бинаризация просто выбирает пороговое значение.

Рисунок 1 – Оригинальное изображение и изображение после бинаризации
C. Морфологические стандартизации
Первоначально отсканированные изображения, как правило, содержат различной толщины линии для символов, даже в рамках отдельных букв. Для начала, я использую bwmorph(img,'thin',inf) для каждой тонкой линии на изображении. Как показано на рис. 2, линии букв теперь уменьшаются до такой же толщины (1-2 точек).

Рисунок 2 – Истонченное изображение
Из-за сокращения пикселей после истончения, имеются дополнительные волоски
в буквах. Чтобы сократить эти нежелательные волоски, я использую алгоритм обрезки Matlab, bwmorph(img, 'spur'), чтобы сократить скелет каждой буквы. Как мы видим, на рис. 3, буквы сейчас значительно легче.

Рисунок 3 – Обрезка волосков
в буквах
В некоторых случаях будет несколько пятен или нежелательных маленьких точек на изображении, которые могут помешать распознаванию. Чтобы избежать этого, я использую функцию bwareaopen
, чтобы удалить все возможные мелкие детали на изображении. Затем, чтобы утолстить разбавленное изображение, используется Matlab's bwmorph(img,'dilate',1) чтобы линии в буквах не исчезали из-за процесса истончения.

Рисунок 4 – Удаление мелких деталей

Рисунок 5 – Детализированное изображение
D. Обнаружение линии
Этот этап необходим, чтобы улучшить расположение выходного изображения. При детектировании линий текста, мы можем определить порядок символов и, возможно, их расположение на изображении в последующих этапах. Это выполняется с помощью горизонтальной проекции слоя. Сначала я предполагаю, что нет перекрытия между линиями текста, который имеет место в большинстве отсканированных печатных изображений. Если сумма всех пикселей в одной строке не равна 0 (нет пикселей на разрывах линий), эта строка считается разрывом между линиями. После того как мы находим разрыв, мы могли бы легко найти и обрезать каждую матрицу линии.
Рисунок 6 – Разделенные линии текста
E. Сегментация символов
Сегментация является наиболее важным шагом в процедуре предварительной обработки. Большинство методов распознавания могут определить только отдельные символы. Например, в методе выявления границ, сегментация позволяет системе определять границы сегментированных букв, а затем классифицировать их. Здесь я реализовываю два метода сегментации символов. Первый подход состоит в использовании regionprops
, операции разрезания изображения на возможные части, представляющие интерес. Во-первых, я вычисляю измерения Area
, Centroid
and BoundingBox
. Если измерения региона удовлетворяют определенным критериям (например, если область содержит определенные пиксели), эта область будет извлекаться из исходного изображения и образовывать subimage и, таким образом, каждая буква в изображении сегментируется. Ниже показаны сегментированные буквы EECS 451
.

Рисунок 7 – Сегментированные символы
Другой способ заключается в использовании bwlable
, чтобы проверить связность букв и меток компонентов связности. Следующим шагом является обрезка каждых меченых групп пикселей, находя минимальные и максимальные значения строки и столбца группы и извлечения букв из неё. Оба метода успешно сегментируют символы.
III. РАСПОЗНАВАНИЕ СИМВОЛОВ
A. Шаблонный метод
Шаблонный метод является классическим методом оптического распознавания символов. Это процесс поиска расположения вложенного изображения, называемого шаблоном внутри изображения. После количества соответствующих шаблонов, можно найти их центры, которые используются в качестве соответствующих точек для определения параметров регистрации [2]. Шаблонный метод включает в себя сравнение сходства между данным набором шаблонов и входного изображения, которое нормализовалось, как того же размера из шаблонов, а затем определяется определённый шаблона, который производит наибольшее сходство.
В данной работе я применяю формулу соответствия, чтобы обнаружить сходство между моделями двух сигналов методом кросс-корреляции, который мы узнали на занятиях, но который реализуется в 2D вместо 1D. Я использую функцию Matlab corr2
для вычисления коэффициентов корреляции каждого сравнения между тестируемым изображением и шаблоном. В приведенной ниже формуле, Amn – входное изображение, Bmn является одним из шаблонов. Функция соответствия r вернет значение показывающее, насколько хорошо Amn. совпадает с Bmn. Если один из коэффициентов корреляции значительно выше, входное изображение идентифицируется как эта буква или цифра.
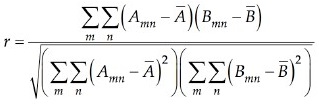
Следуя линии обнаружения и сегментации символов, процесс согласования начинает читать входной сигнал от первой линии текстов к нижней линии, слева направо, что гарантирует порядок каждой буквы и их выходной компоновки каждой строки. Тогда заключительным шагом является написание слова в текстовый файл. Для входного изображения на рис. 1, система может считывать изображение в текст, как показано на рисунке ниже.

Рисунок 8 – Выходной текст
B. Недостатки шаблонного метода
В шаблонном методе распознавание основано на измерении сходства между структурой входного изображения и заданного набора шаблонов. По своей сути, этот метод чувствителен к несоответствию шаблона, когда входные символы имеют не такой же шрифт, как шаблоны. В приведенном ниже примере, ошибки возникают, когда шрифт входного изображения (Arial) отличается от шаблона. Систем неверно распознала I, Q и R на 0, O и P, соответственно. Из-за незначительного изменения в структуре входных символов, самые высокие показатели определенных символов не найдены в их истинных соответствующих шаблонах букв или цифр. Точность распознавания этого метода больше всего страдает от шрифта входных символов.

Рисунок 9 – Несоответствие шаблону
IV. ИЗВЛЕЧЕНИЕ ГРАНИЦ И SVM КЛАССИФИКАТОР
Другой метод заключается в реализации распознавания символов методом выделения границ и классификатором Метода Опорных Векторов (SVM).
A. Набор данных
Обучение набора данных состоит из 1 020 синтетических и рукописных изображений цифр 0-9, а испытательная установка состоит из 120 образцов рукописных цифр от 0 до 9. Перед выделением границ, изображение подвергается аналогичным шагам предварительной обработки изображений, как упоминалось выше: сначала исходное изображение бинаризуется в черно-белый, а затем сегментируется на отдельные символы, и, наконец, изображение масштабируется в размер 16х16 пикселей и готово к процедуре выделения границ.
B. Выделение границ HoG
В методе выделения границ, извлеченные границы используются для обучения классификатора, а позднее идентификации символа. Следовательно, очень важно для определения, какие границы лучше всего представляют символы и являются оптимальными для классификации. Прежде всего, рассмотрим наиболее простой случай, необработанные значения пикселей отдельного символа. Входное изображение – черно-белое изображение 16х16 с разным диапазоном значений пикселей от 0 до 255. Простейшая граница является использование 16x16 пикселей, как вектора границы для обучения классификатора. Тем не менее, можно предсказать, что интуитивно граница необработанных значений пикселей не является наиболее представительной классификацией границы, так как она не может обеспечить много информации о структуре и форме символа. Таким образом, вводится функция гистограммы градиентов.
Я провел эксперимент с границами, построенными с помощью гистограмм ориентированных градиентов с использованием функции Matlab extractHOGFeatures
. Каждый пиксель на изображении назначается ориентацией и величиной, основанной на локальном градиенте и гистограмме, построенные путем объединения ответов пикселей в пределах ячеек различных размеров [3]. Я построил с помощью размера ячейки параметры 2х2, 4х4 и 8х8 и визуализировал результат, чтобы увидеть, какого размера ячейка содержит нужное количество структуры и форме информации символа.

Рисунок 10 – Сравнение различных размеров ячеек
На рис. 8 показана визуализация 3 размерных параметров ячеек. Во-первых, размер ячейки 8х 8 не содержит много о форме символов. Размер ячейки 2х2, кажется, самая представительная фигура среди трех размеров клеток. Однако, поскольку HoG работает путём декомпозиции входного изображения на квадратные ячейки размером CellSize
, вычисляется гистограмма ориентированного градиента в каждой ячейке, а затем переномеровываются ячейки, глядя в смежные блоки [4]. Уменьшение размера ячейки означает значительное увеличение в размерности вектора границ HoG. Таким образом, с целью снижения угрозы, я выбираю размер ячейки 4х4, поскольку он ограничивает размеры векторов границ HoG, а также содержит достаточно информации для определения формы символа.
C. SVM классификатор
После выбора оптимального размера клеток, мы начинаем обучать SVM классификатор, используя выделенные границы HoG и необработанные значения пикселей границ. Машина опорных векторов представляет собой классификатор определения разделяющей гиперплоскости. Учитывая обученные данные, алгоритм SVM выводит оптимальную гиперплоскость, классифицирует другие тестовые данные [5]. Функция Matlab svmtrain
реализована для обучения классификатора. Так как Matlab поддерживает только 2 класса SVM классификатора, обычно используют мультикласс метода классификации SVM под названием один-ко-всем
, который используется в работе, чтобы классифицировать цифры 0-9. Идея один-ко-всем в том, что мы обучаем SVM классификатор каждой цифре, так для классификатора SVM (0), образец распознавания этого класса (0) считается положительным, тогда как образцы всех других классов (1-9) отрицательны. При цикле через все SVM классификаторы (0-9), цифра может быть классифицирована в один из этих 10 классов.
Затем мы тестируем SVM классификатор, обученный выше. Процедура аналогична: сначала выделяются границы HoG и необработанные пиксели границ тестового набора, а затем классифицируются тестовые изображения в зависимости от их особенностей со стороны SVM классификатора, использующего функцию Matlab svmclassify.
Рисунок 11 – Процесс классификации цифр
D. Результаты
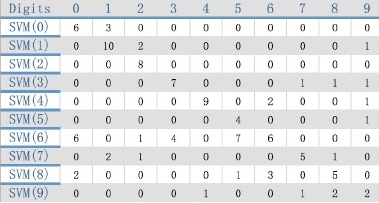
Строки таблиц содержат результаты каждого SVM классификатора для необработанных пиксельных значений границ и границы HOG. Идеальная система классификации должна представлять собой диагональную линию 12 (количество тестовых изображений каждой цифры) в матрице, с 0 в других местах. Как видно в приведенных ниже таблицах есть ложные срабатывания в обоих случаях. Как и предполагалось, SVM классификаторы, обученные пиксельными значениями границ, не признаны удовлетворительными. Они только имеют относительно высокую точность классификации цифр 0
, 1
и 4
.
Таблица 1 – Необработанные пиксельные значения

МОВ классификаторы, обученные выделением границ HoG работают гораздо лучше, чем классификаторы необработанных пиксельных значений. Цифры 1
, 2
и 4
имеют самую высокую точность классификации. Самые трудные цифры для чтения – 9
и 5
, а МОВ (6) имеет самое большое количество ложных срабатываний.
Таблица 2 – Границы HOG
V. ОБСУЖДЕНИЕ
В данной работе, я реализую два способа оптического распознавания символов. Шаблонный метод является одним из классических методов распознавания текста. Теория проста для понимания и реализации. Но шаблонный метод имеет очевидный недостаток. Точность распознавания этого способа во многом зависит от сходства между входным изображением и шаблонами.
Во второй реализации, классификаторы, созданные выделением границ, кажется, имеют относительно низкую точность распознавания с максимальной точности будучи 83,3% (SVM (1) границ HoG). Основной причиной этого может быть следующее: мы выбираем не большой и достаточно представительный обучающий набор и есть довольно большой разрыв в сходстве между обучающим набором и испытательной установкой. Больший набор данных может улучшить производительность классификаторов. Хотя с относительно низкой точностью классификации двух наборов классификаторов, преимущество выделения границ HoG над пиксельными значениями границ по-прежнему превалирует.
VI. ДРУГИЕ КЛАССОВЫЕ DSP ИНСТРУМЕНТЫ
Я действительно заинтересован в матрице свертки, известной как ядро свертки, о которых узнал на занятиях, так что я пробовал некоторые ядра на моем изображении букв.

Рисунок 12 – Горизонтальные и вертикальные обнаружения краёв
Эти два фильтра могут выполнять локальные разностные операции с помощью матриц свертки [1,1; -1,-1] и [1,-1; 1,-1]. При большом скачке в соседнем пиксельном значении, выходной сигнал будет большим. Выявление горизонтальных и вертикальных ребер ясно показано буквой Е на картинке. Реализация другой матрицы: [-1,-1,-1;-1,8,-1;-1,- 1,-1]. Также путем обнаружения большого скачка в соседних пиксельных значениях, выходной сигнал предоставляет нам очертания букв.
Рисунок 13 – Выделение краев
VII. ВЫВОДЫ
Оптическое распознавание символов – это интересный проект для обучения и реализации. Есть различные подходы идентификации символа, но они всегда начинают с процедуры предварительной обработки изображении. Правильные шаги предварительной обработки, такие как, бинаризация, морфологическая стандартизация и сегментация, имеют решающее значение для последующих шагов распознавания. Шаблонный метод распознавания является одним из старейших подходов в области оптического распознавания символов. Простая, но мощная теория для сравнения входного изображения с сохраненным шаблоном и определения символа в соответствии с его высоким показателем в сходстве. Очевидным недостатком этого способа является то, что точность распознавания сильно зависит от сходства между входным изображением и сохраненными шаблонами. Другой подход – это выделения границ со последующей SVM классификацией. Гистограмма ориентированного градиента границ является более представительным и ценным, чем пиксельные значения границ в обучении системы распознавания. Хотя точность этого подхода не идеальна из-за небольшого набора данных и несоответствия между обучающим набором и испытательной установкой, мы могли увидеть возможности этого метода. В будущем при реализации ОРС, я хотел бы попробовать больше классификаторов и исследовать больше аспект машинного обучения, например, нейронные сети.
СПИСОК ИСПОЛЬЗУЕМЫХ ИСТОЧНИКОВ
Kumar, R., & Singh, A. (2010). Detection and segmentation of lines and words in Gurmukhi handwritten text. doi:10.1109/IADCC.2010.5422927
Patel, Krunal M. and Amrut N. Patel
Approaches for Multi-Font/Size Character Recognition:A Review .
Quest International Multidisciplinary Research Journal 1.2 (2012) : 189 – 193.Maji, Subhransu, Author Malik, Jitendra, Author. (n.d.). Fast and Accurate Digit Classification. EECS Department, University of California.
VLFeat - Documentation > C API. (n.d.). Retrieved from http://www.vlfeat.org/api/hog.html
Introduction to Support Vector Machines — OpenCV 2.4.9.0 / documentation. (n.d.). Retrieved from http://docs.opencv.org/doc/tutorials/ml/introduction_to_svm/introducti on_to_svm.html