Автор: Avi Bleiweiss
Автор перевода: А. А. Койбаш
Источник: Avi Bleiweiss: GPU Accelerated Pathfinding. NVIDIA Corporation, Graphics Hardware (2008) / Editors: David Luebke and John D. Owens, NTNU, TDT24 Presentation by Lars Espen Nordhus - [Электронный ресурс]. – Режим доступа: http://www.idi.ntnu.no/...
Одной из наиболее сложных проблем в играх реального времени является автономная навигация и планирование многих тысяч агентов в сцене с неподвижными и динамическими движущимися препятствиями
В идеале мы хотели бы, чтобы каждый агент мог независимо перемещаться без какой-либо глобальной координации или синхронизации всех задействованных агентов или их подмножества.
Глобальный путь вычисляется с использованием графа карты, который представляет статические объекты в сцене без присутствия агентов.
Интеграция глобального и локального планирования осуществляется путем вычисления вектора предпочтительной скорости для каждого агента, который находится в направлении следующего узла вдоль глобального пути агента.
Матрица смежности представляет собой двумерный массив булевых элементов, в котором хранится топология не взвешенного графа. Матрица обладает дополнительным свойством быстро идентифицировать наличие ребра на графе. Однако для больших разреженных графов матрица смежности имеет склонность быть неэкономной
Списки смежных вершин обычно являются более предпочтительными, обеспечивая компактное хранилище для более широкого распространения разреженных графов за счет меньшей эффективности обхода. Структура данных смежных списков экономически более растяжима и адаптированна для представления взвешенных графов для обхода ребра, который связан со стоимостью перехода от одного узла к другому.
| Поиск | BFS | Дейкстра | A* |
|---|---|---|---|
| Старт | нет | да | да |
| Финиш | да | нет | да |
| Эвристика | да | нет | да |
| Оптимальность | нет | да | да° |
| Скорость | удовл. | медл. | быстр. |
Поиск по алгоритму A* более эффективен при балансировании стоимости при определении наилучшего пути как от старта, так и до конечного результата; A* без эвристики вырождается в алгоритм Дейкстры
Для оптимальности A* эвристика должна быть допустимой. Допустимость означает оптимизм в том смысле, что истинная стоимость будет как минимум такой же, как и оценка.
1: f = priority queue element {node index, cost}
2: F = priority queue containing initial f (0,0)
2: G = g cost set initialized to zero
3: P, S = pending and shortest nullified edge sets
4: n = closest node index
5: E = node adjacency list
6: while F not empty do
7: n < F.Extract()
8: S[n] < P[n]
9: if n is goal then return SUCCESS
10: foreach edge e in E[n] do
11: h < heuristic(e.to, goal)
12: g < G[n] + e.cost
13: f < {e.to, g + h}
14: if not in P or g < G[e.to] and not in S then
15: F.Insert(f)
16: G[e.to] < g
17: P[e.to] < e
18: return FAILURE
Выше вы видите псевдокод алгоритма A*: g(n) – это стоимость от начала до узла n, h(n) – это эвристическая стоимость от узла n до цели; f – сущность для сортировки в приоритетной очереди, которая просчитывается как сумма g(n) и h(n).
Верхний элемент очереди извлекается, перемещается на разрешенный кратчайший узел (или ребро), и если текущая позиция узла соответствует цели, поиск завершается успешно. Распространенная ошибка заключается в том, чтобы проверить положительное совпадение при добавлении соседа, тем самым разрушая оптимальность алгоритма.
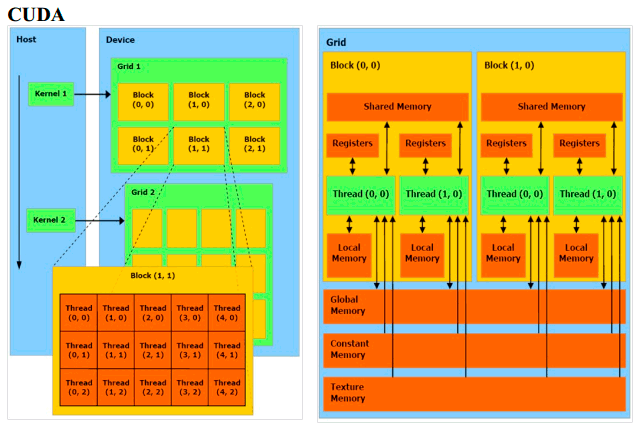
Редко когда граф карты инкапсулирован в структуру данных списков смежности. Будучи доступным только для чтения, граф хранится как набор областей памяти линейного устройства, привязанных к текстурным ссылкам
Доступ к текстуре в ядре поиска путей последовательно использует предпочтительное и эффективное семейство функций tex1Dfetch() CUDA.
Набор хранилищ графов карты был намеренно переоборудован для повышения согласованного доступа к графическому процессору. Набор текстур включает в себя список узлов, один список ребер, который сериализует все списки смежности в одну коллекцию ребер и каталог смежности, который предоставляет индекс и номер списка смежности для определенного узла.
Параметр входа в каталог смежности отображается непосредственно на параметры управления внутренним контуром A*. Как результат, один доступ к текстуре смежности амортизируется по нескольким выборкам текстуры из списка ребер. Узлы и ребра хранятся в виде четырех компонентов IEEE float, а текстура смежности является двойной целочисленным компонентом.

Выше вы видите, что набор текстур карты состоит из четырех или двух компонентов для соответствия с функцией tex1Dfetch() CUDA. Показанный макет компонента имеет узел с уникальным идентификатором и трехкомпонентное положение IEEE float; ребро имеет пару идентификаторов узла направления {from, to}, стоимость float и зарезервированное поле; смежность состоит из смещения в списке ребер и количества ребер в текущем списке смежности.
Этот макет несет дополнительную стоимость в 8*N байтов по сравнению с эквивалентной реализацией на центральном процессоре; взамен, это способствует более эффективному обходу карты.
Ядро A * имеет пять входов и два выхода, которые вместе образуют рабочий набор.
Вход:
• список путей, каждый из которых определяется идентификатором узлов старта и финиша, один путь для каждого агента;
• список стоимостей из начальной позиции (G), инициализированной нулем;
• список стоимостей, объединенных от начала до конца (F), инициализируется нулем;
• пара списков указателей для каждой из ожидающих и кратчайших наборов ребер P и S, соответственно. Инициализируются нулями.
Выход:
• список накопленной стоимости для рассчитываемого оптимального пути ядра, одно скалярное значение стоимости для каждого агента;
• список поддеревьев, каждый из которых представляет собой набор трехмерных позиций узлов, которые формулируют разрешенные построенные путевые точки агента.
Привлеченные структуры данных - это память, выровненная с размером любого из 4, 8 или максимум 16 байтов, чтобы ограничить несколько инструкций по загрузке и хранению на передачу памяти. Организация глобальных папок памяти, одновременно выпущенных каждым потоком варп, выровненная в непрерывную память транзакция крайне необходима для обеспечения оптимальной пропускной способности памяти. Объединенный 4-байтный доступ обеспечивает максимальную пропускную способность, по сравнению с 8-байтным и 16-байтовым доступами, способствующими более низкой полосе частот. Выполнение требований объединения в дивергентное ядро ??A* остается задачей программирования.
| Нитей на блок | 128 |
|---|---|
| Регистров на блок | 2560 |
| Варпов на поток | 4 |
| Нитей на мультипроцессор | 384 |
| Блоков на мультипроцессор | 3 |
| Блоков на графический процессор | 48 |
Инструмент подсчета занятости NVIDIA CUDA NVIDIA сгенерировал вывод для блока нахождения пути по умолчанию для 128 потоков, работающих на GPU текущего поколения
Доступная глобальная память является атрибутом свойств устройства, предоставляемых CUDA. Программное обеспечение для поиска пути проверяет общую память, необходимую для сетки потоков, и автоматически разбивает вычисления на множественные задачи. Каждый запуск в последовательности синхронизирован и частичные результаты поиска копируются с устройства на хост в предопределенном смещении на на выходные списки списки.
| Граф | Узлов | Рёбер | Агентов | Блоков |
|---|---|---|---|---|
| G0 | 8 | 24 | 64 | 1 |
| G1 | 32 | 178 | 1024 | 8 |
| G2 | 64 | 302 | 4096 | 32 |
| G3 | 129 | 672 | 16641 | 131 |
| G4 | 245 | 1362 | 60025 | 469 |
| G5 | 340 | 2150 | 115600 | 904 |
Выше вы видите список параллельных контрольных значений, изображающий для каждого тестового графа количество узлов и ребер, число агентов (потоков) и блоков (128 потоков на блок).
В наших тестах центральный процессор был двухъядерным AMD Athlon 64 X2 4000+ с тактовой частотой 2.11 ГГц и 2 ГБ памяти в системе. В качестве графического процессора была видеокарта NVIDIA 8800 GT, работающая на шейдерных с частотой 1,5 ГГц и подключенными 512 мегабайт глобальной памяти. В 8800 GT мы использовали 112 шейдерных процессоров, которые составляют до 14 мультипроцессоров (более скрытая версия 16-процессорных микропроцессорных процессоров). Производительность графического процессора сравнивалась с работой на одном процессоре с оптимизированным скаляром C ++ и встроенным компилятором, настроенная программа SIMD intrinsics (SSE) с потенциалом векторного арифметического ускорения. Кроме того, мы проверили производительность CPU при скалировании на двух потоках, по одному на каждое ядро ??процессора Intel Core Duo T7300 с тактовой частотой 2,0 ГГц в системе из 2 ГБ памяти и 4 Мбайт кэша L2; скорость фронтальной шины (FSB) составляла 1,12 ГГц. Программное обеспечение для поиска пути запускалось в среде Windows XP, а показания ускорения отображали время работы экрана, измеренное с использованием высокопроизводительных счетчиков Windows для обоих типов процессоров.
| Граф | Карта (КБайт) | Рабочий сет (МБайт) | Глобальная память (МБайт) | Запуски |
|---|---|---|---|---|
| G0 | 0.576 | 0.021 | 0.021 | 1 |
| G1 | 3.616 | 1.319 | 1.322 | 1 |
| G2 | 6.368 | 10.518 | 10.519 | 1 |
| G3 | 13.848 | 86.001 | 86.001 | 1 |
| G4 | 27.672 | 588.726 | 588.726 | 2 |
| G5 | 42.560 | 1573.086 | 1573.086 | 3 |
Глобальная емкость памяти G4 и G5 превосходит доступную память GPU (512 Мбайт), тем самым разбаясь на множественные запуски траектории, каждый из которых отвечает за подмножество всего агента.

Сравнительная производительность GPU, выполняющая алгоритм Дейкстры с использованием CUDA против процессора C ++, скомпилированным с оптимизацией.

Производительность двухпоточного алгоритма поиска A * с использованием эвклидовой эвристики, по одному потоку на процессор ядро с настраиваемым встроенным SIMD-интерфейсом (SSE) с ручным компилятором, по сравнению с однопоточным запуском.
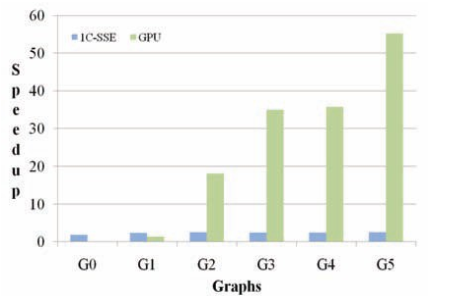
Производительность графического процессора с использованием алгоритма поиска CUDA A *с использованием эвклидовой эвристики по сравнению с ЦП, оптимизированный для C ++-кода и настраиваемый встроенный интерфейс SIMD (SSE).
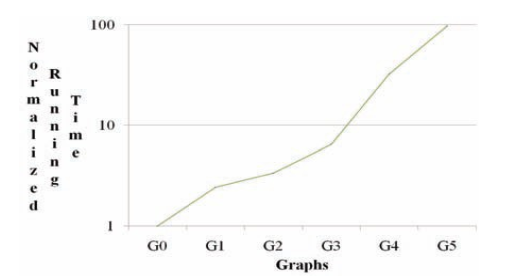
Текущая логарифмическая шкала времени выполнения графического процессора, нормированная на G0, демонстрирует (близкий к) линейному подъёму с растущей сложностью дорожной карты
Ядро поиска A* демонстрирует больший масштаб производительности графического процессора по сравнению с алгоритмом Дейкстры, что в основном объясняется повышенной интенсивностью арифметической скорости первого
Реализация процессора A* включает встроенные вызовы SIMD (SSE) в эвристических методах и как результат, это способствовало среднему ускорению в 2,3 раза во всех тестах по сравнению со скаляром C++.
Ускорение производительности GPU для алгоритма Дейкстры (против скалярного C ++) и A* (по сравнению с SSE-реализацией) достигло 27X и 24X соответственно.
• суммарное копирование памяти с устройства на хост и с хоста на устройство было связано с накладными расходами, сравнимыми с временем работы ядра для некоторых рабочих нагрузок. Копирование карты на устройство и копирование с устройства на хост отображается небольшим процентом общей стоимости копирования (менее 1%);
• не объединенные загрузки глобальной памяти и хранилища глобальной памяти намного превосходят совместные обращения. Тем не менее, многие из непоследовательных доступов имеют 8 или 16 байт и меньше страдают от падения скорости пропускания;
• чередующееся ядро показало преимущество 1,15X по сравнению с доступным рабочим сетом. Чередование нитей улучшает объединенные нагрузки и сохраняет по существу, но по-прежнему оставается небольшой частью общих транзакций глобальной памяти, и как результат, получается умеренное ускорение.