Анализ средств защиты больших данных в распределенных системах
Авторы: Егоров А.А., Чернышова А.В., Губенко Н.Е.
Источник: Программная инженерия: методы и технологии разработки информационно-вычислительных систем (ПИИВС-2016): сборник научных трудов I научно-практической конференции – 2016 – Донецк, ДонНТУ, Том 2, с. 28-33.
Аннотация
Егоров А.А., Чернышова А.В., Губенко Н.Е. Анализ средств защиты больших данных в распределенных системах. В статье описана и проанализирована с точки зрения безопасности распределенная модель обработки данных (MapReduce). Выполнен обзор существующих фреймворков обработки больших данных с описанием основных их возможностей. Представлен анализ существующих средств защиты для распределенных систем.
Ключевые слова: распределенная система, большие данные, обработка данных, MapReduce, NoSQL, распределенная файловая система, безопасность данных, средства защиты, SSL, TLS.
Введение
Концепция больших данных (BigData
) на сегодняшний день активно применяется ведущими технологическими компаниями во многих отраслях. Наиболее популярное их использование замечено в торговле, здравоохранении, телекоммуникациях, в финансовых компаниях, а также в государственном управлении [1].
При использовании данной технологии в розничных магазинах можно накопить множество информации о клиентах, системе управления запасами, поставками товарной продукции. С помощью полученной информации можно прогнозировать спрос или поставки товара, а также оптимизировать затраты.
В финансовых компаниях большие данные предоставляют возможность проанализировать кредитоспособность заемщика, т. е. на основе выявленного оборота денежных средств подобрать выгодные и оптимальные условия кредитования, предложить дополнительные подходящие ему банковские услуги. Применение такого подхода позволит значительно сократить время рассмотрения заявок.
Операторы сотовой связи также как и финансовые организации имеют огромные базы данных, что позволяет им проводить детальный анализ накопленной информации. Помимо использования Big Data в целях предоставления качественных услуг технологию можно применить для выявления и предотвращения мошенничества.
Предприятия горнодобывающей и топливно-нефтяной промышленности могут накапливать информацию о количестве добытой продукции и на основании этих данных делать выводы об эффективности разработки месторождения, следить за состоянием оборудования, строить графики прогнозирования спроса на продукцию.
Все выше перечисленные применения технологии больших данных нуждаются в определенной защите информации. Например, начинающей финансовой компании можно нанести большой материальный ущерб, если конкурирующая фирма получит доступ к накопленным или обработанным данным. Но наибольший урон можно нанести топливно-энергетическим предприятиям, которые непосредственно связаны с государством.
Актуальность работы обусловлена тем, что большие данные, которые обрабатывает распределенная система могут быть:
- конфиденциальными;
- обрабатываться у других провайдеров, предоставляющих облачную инфраструктуру как услугу (IaaS), например Amazon EC2, Google Compute Engine, Microsoft Azure и т. д.
Исходя из этого, необходимо построить/выбрать многоуровневую защиту с возможностью добавления или удаления определенного уровня в зависимости от сетевой инфраструктуры и обрабатываемых данных, решающих определенную задачу.
Цель работы: исследовать существующие средства обработки данных в распределенных системах, проанализировать их с точки зрения защиты данных.
Модель обработки данных и анализ ее безопасности
В основу обработки данных в распределенных системах положена модель MapReduce. Главным достоинством такой модели является простая масштабируемость при наличии нескольких вычислительных узлов. Работа MapReduce состоит в основном из двух шагов: Map (отображение, распределение) и Reduce (свертка, редукция) [2].
На шаге отображения (Map) выполняется предварительная обработка входных данных. Для этого один из главных узлов (обычно называется master или leader node) получает входные данные решаемой задачи и разделяет их на независимые части. Например, файл с логами содержащий 1000 строк, можно разделить на 10 частей по 100 строк. После того, как данные разделены, их передают другим рабочим узлам (slave или follower nodes) для дальнейшей обработки.
На шаге редукции (Reduce) происходит свертка обработанных данных. Узел, отвечающий за решение задачи, получает ответы от рабочих узлов и на их основе формируется результат.
Чтобы все составляющие функции MapReduce могли корректно и совместно выполнять вычисления, необходимо принять некоторое соглашение о единой структуре обрабатываемых данных. Оно должно быть достаточно гибким и общим, а также отвечать потребностям большинства приложений обработки данных. В MapReduce в качестве основных примитивов используются списки и пары ключ / значение. В роли ключей и значений могут выступать целые числа, строки или составные объекты, часть значений которых может быть проигнорирована при дальнейшей обработке [3].
На рисунке 1 показана упрощенная схема потока данных в модели MapReduce [4].
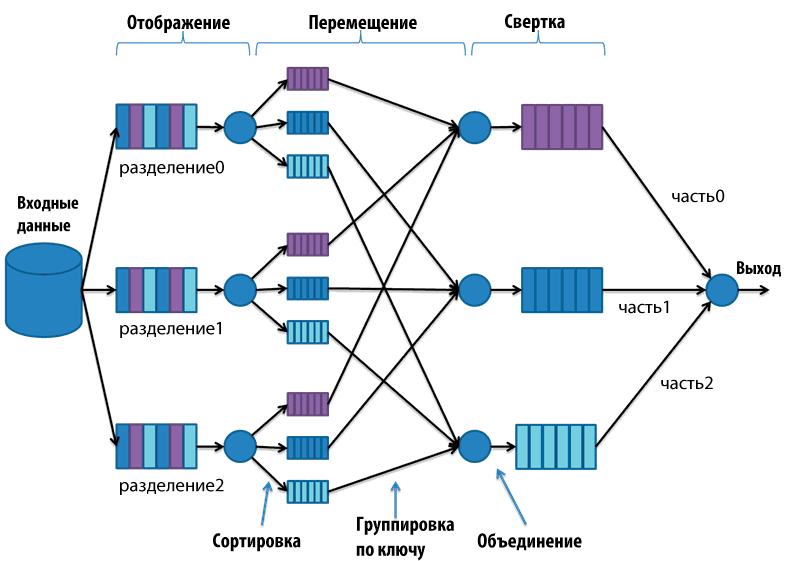
Рисунок 1 – Схема потока данных в модели MapReduce
Как видно из рисунка 1, данная модель имеет много точек передачи данных и поэтому нуждается в определенной защите информации. Например, при передачи данных по сети после группировки по ключу, злоумышленник может добавить или убрать обработанные данные и тем самым нарушить общий результат задачи. Ситуацию может усугубить факт того, что обработка происходит не в своей частной локальной компьютерной сети, а используется инфраструктура других провайдеров. Одно из очевидного и простого решения может служить разделение конфиденциальных данных (имени, логина пользователя) и его обрабатываемых данных (количество взятых кредитов и т. д.). При этом в качестве ключа может использоваться хеш-значение конфиденциальных данных. Но данный подход не решает проблему, если сами значения обрабатываемых данных являются секретными. При такой ситуации необходимо шифровать и расшифровывать симметричными алгоритмами передаваемые данные во время обработки данных узлом.
Обзор инструментов для обработки данных
Большинство документно-ориентированных баз данных, например, как CouchDB, поддерживают упрощенную распределенную модель обработки данных MapReduce. Это позволяет производить параллельные вычисления на многоядерном процессоре. Но как таковое распределение вычислений на несколько узлов не производится, вместо этого используется механизм репликации [5].
Помимо NoSQL баз данных, существуют и различные фреймворки, которые упрощают написание и сопровождение распределенных программ. Большинство программных каркасов имеют открытый исходный код (Open Source) и поддерживаются огромным сообществом программистов со всего мира. Приведём анализ основных свойств и особенностей некоторых из этих систем.
Disco – распределенная система для обработки данных (MapReduce framework), написанная на языках Python/Erlang [6]. Как и оригинальная, распределенная MapReduce-система, опубликованная компанией Google [7-8], поддерживает параллельные вычисления над большими объемами данных на кластере компьютеров. Это делает ее идеальным инструментом для анализа и обработки больших наборов данных без необходимости заботиться о сложных технических вопросах, связанных с распределенной обработкой, например, таких, как транспортные протоколы, балансировка нагрузки, блокировка, расписание задач или отказоустойчивость. Проект Disco был создан в 2008 году центром исследования Nokia для решения значимых проблем при работе с большими объемами данных. Распределенная система активно развивается и поддерживается компанией Nokia и другими компаниями, которые используют ее для целей анализа логов пользователей, вероятностного моделирования, интеллектуального анализа данных (Data Mining) и полнотекстового индексирования. Среди особенностей данной системы необходимо отметить следующие:
- простая установка на Linux, Mac OS X, и FreeBSD;
- эффективное распределение данных за счет распределенной файловой системы Disco Distributed Filesystem;
- поддержка профилирования и отладки заданий MapReduce;
- запуск задач, написанных на разных языках, использующих собственный протокол заданий;
- построение запросов и индексов для миллиардов ключей и значений, используя базу данных DiscoDB [9].
Glow – MapReduce-система, которая проста в использовании и полностью написана на языке GoLang. Данная система предоставляет библиотеку для удобного вычисления в параллельных потоках на многоядерном процессоре или для распределенного вычисления на нескольких кластерах [10]. Автор также советует использовать еще одну систему, работающую на Go+Luajit – Gleam, которая является более гибкой и производительной. Gleam сочетает параллелизм Go с высокой производительностью Luajit (динамический компилятор для Lua), система также позволяет запускать программы автономно и на нескольких узлах [11]. Проекты Glow/Gleam находятся на начальной стадии, но стремительно развиваются.
Hadoop – наиболее известная программная платформа, с помощью которой можно построить распределенные приложения для массово-параллельной обработки (Massive Parallel Processing, MPP) данных. Создана на основе докладов программистов Google [7-8]. Работа над проектом была начата в 2005 году. С 2008 года Hadoop является проектом верхнего уровня Apache Software Foundation. Проект Hadoop включает в себя такие модули:
- Hadoop Common: общие утилиты и сценарии для поддержки управления распределенной обработкой, файловой системой, развертывания инфраструктуры;
- Hadoop Distributed File System (HDFS): распределенная файловая система, которая предоставляет высокоскоростной доступ к данным приложения;
- Hadoop YARN: фреймворк для планирования заданий и управления ресурсами кластера;
- Hadoop MapReduce: система для параллельной обработки больших наборов данных.
Можно выделить такие основные технические характеристики платформы Hadoop:
- масштабируемость: платформа масштабируется линейно, что позволяет хранить и обрабатывать петабайты данных;
- устойчивость к сбоям: все хранящиеся данные избыточны (дублируются на нескольких узлах), все неудачно выполненные задания по обработке данных перезапускаются;
- кроссплатформенность: библиотеки Hadoop написаны (в основном) на Java, и могут выполняться в любой операционной системе, поддерживающей Java Runtime Environment;
- автоматическое распараллеливание выполнения задачи: Hadoop создает
чистые
абстракции для разработчиков, снимая с них работу по планированию, контролю и агрегатированию результатов параллельной обработки данных.
Используя Hadoop, можно получить такие бизнес-выгоды:
- гибкость: хранение и анализ структурированных и неструктурированных типов данных;
- эффективность: в большинстве случаев более низкая стоимость хранения и обработки терабайта данных;
- низкая стоимость создания кластера: для создания Hadoop-кластера не требуется дорогое серверное аппаратное обеспечение;
- сравнительная легкость адаптации: Hadoop имеет широкую и активно развивающуюся систему проектов;
- минимальные риски, связанные с некорректной работой ядра платформы: на сегодняшний день платформа Hadoop успешно используется для обработки петабайт информации;
Open Source
лицензирование: низкая стоимость внедрения и владения платформой Hadoop, большоеdeveloper community
[12].
Хранилище данных (Data Storage) и обработка данных (Data Processing) – одни из главных уровней системы. В Hadoop реализовано хранение как неструктурированных данных в распределенной файловой системе HDFS, так и структурированных данных в нереляционной базе данных HBase. Делать запросы к хранящимся на Hadoop-кластере наборам данных можно с помощью следующих инструментов, входящих в систему Hadoop: Pig, Hive (имеет свой SQL-подобный язык запросов HiveQL). С помощью инструмента Sqoop можно передавать большое количество данных.
Компоненты, относящиеся к взаимодействию управления (Management), отвечающие за доступ к данным (Data Access), а также нереляционная база данных HBase представлены отдельными проектами. На рисунке 2 показана часть системы проектов Hadoop [13].

Рисунок 2 – Часть системы проектов Hadoop
Анализ существующих средств защиты
Многие документно-ориентированные базы данных на сегодняшний день уже поддерживают встроенное в свой дистрибутив SSL/TLS шифрование. Например, CouchDB, начиная с версии 1.3, изначально поддерживает (при определенной настройке) передачу по протоколу HTTPS [14]. MongoDB также позволяет выбрать версию дистрибутива, как с поддержкой SSL/TLS, так и без нее [15]. Но помимо этого, в коммерческой версии (MongoDB Enterprise Server) существуют дополнительные средства защиты: шифрование данных в состоянии покоя, интеграция с протоколом LDAP и аутентификацией Kerberos [16]. Для остальных NoSQL БД, которые не поддерживают встроенное SSL/TLS шифрование, можно использовать SSL-туннель или VPN, если используется своя (доверенная) локальная сеть. При использовании услуг облачного провайдера, например BaaS (Backend as a service), неизвестно, как защищена сетевая инфраструктура за обратным прокси-сервером (reverse proxy). Если передача данных и хранения данных на сервере не защищены дополнительными средствами, то это существенно повышает вероятность возникновения следующих рисков:
- утечки данных;
- подмены данных при ее обработке;
- полного или частичного уничтожения данных.
На рисунке 3 показан пример взаимодействия клиента с услугой облачного хранения данных.

Рисунок 3 – Взаимодействие клиента с сервером БД через обратный прокси-сервер
В MapReduce-системе Disco взаимодействие между главным и рабочими узлами осуществляется посредством SSH. Только отправка задачи на главный узел от пользователя реализуется через незащищенный HTTP [17]. Но эта проблема не является уязвимостью, если отправка задачи происходит с главного узла, то HTTP-запрос не выходит в сеть (обращение происходит к самому себе – loopback). Если отправка задания происходит с другого компьютера, то на главном узле необходимо запустить отдельным процессом обратный прокси-сервер с настроенным SSL-сертификатом.
Проект Glow при обмене данными с другими узлами использует встроенную библиотеку TLS, это существенно уменьшает вероятность возникновения утечки и подмены данных при ее обработке. А проект Gleam не использует шифрование при передачи данных, так как ориентирован на высокую производительность. Как один из вариантов, исправить эту уязвимость можно с помощью VPN.
Как и все распределенные системы, Hadoop использует сеть для взаимодействия между узлами. В качестве протокола передачи данных по умолчанию используется HTTP, но можно настроить поддержку и HTTPS [18]. Как и в выше упомянутых распределенных системах, Hadoop позволяет шифровать данные при передачи между узлами, но помимо этого у него есть решения, предназначенные для защиты данных с помощью инфраструктуры высоко детализированной авторизации.
Решение Sentry поддерживает созданную ранее модель доступа на основе ролей под названием (RBAC) (Role-based Access Control), которая функционирует "поверх" формы представления данных. Модель RBAC имеет ряд функций, предназначенных для защиты корпоративной среды больших данных. Первая функция – это защищенная авторизация, которая обеспечивает обязательное управление доступом к данным для аутентифицированных пользователей. Пользователям присваиваются роли, а затем предоставляются соответствующие полномочия по доступу к данным. Такой подход способствует при помощи шаблонов, масштабированию модели, разделяя пользователей на категории в соответствии с их ролями. Другая функция позволяет организовать администрирование пользовательских полномочий таким образом, чтобы распределить эту задачу между несколькими администраторами на уровне схемы или на уровне базы данных. Также Sentry реализует аутентификацию с помощью протокола аутентификации Kerberos, интегрированного в Hadoop.
Apache Knox Gateway – это решение для защиты периметра Hadoop. В отличие от решения Sentry, которое предоставляет средства для высокодетализированного контроля доступа к данным, решение Knox Gateway обеспечивает контроль доступа к сервисам платформы Hadoop. Цель Knox Gateway – предоставить единую точку безопасного доступа к Hadoop-кластерам. Данное решение реализовано в виде шлюза, который представляет доступ к Hadoop-кластерам посредством REST API [19].
Выводы
В статье описана и проанализирована с точки зрения безопасности распределенная модель обработки данных (MapReduce). Выполнен обзор существующих фреймворков обработки больших данных с описанием их основных возможностей. Представлен анализ существующих средств защиты для распределенных систем. При проектировании средств защиты данных для распределенных систем необходимо учитывать то, что с одной стороны они должны надежно сохранять конфиденциальные данные, с другой – поддерживать многоуровневую защиту с возможностью добавления или удаления определенного уровня в зависимости от сетевой инфраструктуры и обрабатываемых данных.
Литература
1. Аналитический обзор рынка Big Data // Хабрахабр. [Электронный ресурс]. – Режим доступа: https://habrahabr.ru/company/moex/blog/256747/ 2. MapReduce // Википедия. [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/MapReduce 3. Чак Лэм. Hadoop в действии. – М.: ДМК Пресс, 2012. – 424 с.: ил. 4. Introduction to MapReduce // sci2s. [Электронный ресурс]. – Режим доступа: http://sci2s.ugr.es/BigData#Big%20Data%20Technologies 5. CouchDB // Википедия. [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/CouchDB 6. Disco // Github. [Электронный ресурс]. – Режим доступа: https://github.com/discoproject/disco 7. MapReduce: Simplified Data Processing on Large Clusters // Google Research. [Электронный ресурс]. – Режим доступа: http://research.google.com/archive/mapreduce.html 8. The Google File System // Google Research. [Электронный ресурс]. – Режим доступа: http://research.google.com/archive/gfs.html 9. Disco // Discoproject. [Электронный ресурс]. – Режим доступа: http://discoproject.org/ 10. Glow // Github. [Электронный ресурс]. – Режим доступа: https://github.com/chrislusf/glow 11. Gleam // Github. [Электронный ресурс]. – Режим доступа: https://github.com/chrislusf/gleam 12. Платформа Hadoop. Обзор // Codeinstinct. [Электронный ресурс]. – Режим доступа: http://www.codeinstinct.pro/2012/08/hadoop-overview.html 13. What You Need To Know About Hadoop and Its Ecosystem // Savvycom. [Электронный ресурс]. – Режим доступа: https://savvycomsoftware.com/what-you-need-to-know-about-hadoop-and-its-ecosystem/ 14. Native SSL Support // CouchDB. [Электронный ресурс]. – Режим доступа: http://docs.couchdb.org/en/1.3.0/ssl.html 15. MongoDB Support // MongoDB. [Электронный ресурс]. – Режим доступа: https://docs.mongodb.com/v3.2/tutorial/configure-ssl/#mongodb-support 16. MongoDB Download Center // MongoDB. [Электронный ресурс]. – Режим доступа: https://www.mongodb.com/download-center#enterprise 17. Setting up Disco // Disco Readthedocs. [Электронный ресурс]. – Режим доступа: http://disco.readthedocs.io/en/latest/start/install.html#background 18. Sandeep Karanth. Mastering Hadoop. – Packt Publishing, 2014. – 374 pages. 19. Безопасность данных Hadoop и решение Sentry // IBM developerWorks. [Электронный ресурс]. – Режим доступа: http://www.ibm.com/developerworks/ru/library/se-hadoop/
Егоров А.А., Чернышова А.В., Губенко Н.Е. Анализ средств защиты больших данных в распределенных системах. В статье описана и проанализирована с точки зрения безопасности распределенная модель обработки данных (MapReduce). Выполнен обзор существующих фреймворков обработки больших данных с описанием основных их возможностей. Представлен анализ существующих средств защиты для распределенных систем.
Ключевые слова: распределенная система, большие данные, обработка данных, MapReduce, NoSQL, распределенная файловая система, безопасность данных, средства защиты, SSL, TLS.
Yegorov A.A., Chernyshova A.V., Gubenko N.E. Analysis means of protection big data in distributed systems. The article describes and analyzes the security model of a distributed data processing (MapReduce). A review of existing frameworks to handle big data describing the main features. The analysis of the existing means of protection for distributed systems.
Keywords: distributed systems, big data, data processing, MapReduce, NoSQL, distributed file system, data security, means of protection, SSL, TLS.