Безопасность данных Hadoop и решение Sentry
Автор: М. Джонс
Источник: IBM DeveloperWorks
Оригинал статьи: Hadoop data security and Sentry
Введение
Во многих проектах по разработке программного обеспечения о безопасности думают в последнюю очередь. Ранние модели использования платформы Apache Hadoop базировались на кластерах машин, которые обрабатывали большие объемы общедоступных данных (веб-страницы, обследованные краулерами) в закрытом центре обработки данных. С учетом того, что собранные таким образом данные до этого уже были доступны для всеобщего использования, защита этих данных и результатов их обработки не относилась к числу обязательных аспектов реализации.
Однако по мере развития платформы Hadoop развивались и модели ее применения. Сегодня Hadoop не только обрабатывает наборы данных частного характера, но и применяется в сценариях множественной аренды, в которых разнообразные наборы данных обрабатываются разными пользователями (каждый из которых имеет свои индивидуальные требования к исходным данным и к обработанным данным). Кроме того, платформа Hadoop все чаще применяется для работы с наборами конфиденциальных данных, т. е. когда информация подлежит шифрованию во избежание утечек. По этим причинам в настоящее время безопасность рассматривается как неотъемлемая часть Hadoop-кластера. В этой статье я рассмотрю некоторые интересные направления в сфере обеспечения безопасности в среде Hadoop. В частности, я рассмотрю такие вопросы, как защита данных, защита периметра и защита доступа к данным.
Большие данные, конфиденциальность и уязвимость информации
Работа с большими данными накладывает большую ответственность. В условиях роста объема данных и соответственно увеличения количества приложений и платформ, обращающихся к этим данным, появляются новые уязвимости, с которыми необходимо бороться. Один из самых известных случаев нарушения конфиденциальности, связанных с большими данными, произошел в 2006 году. В рамках конкурса по совершенствованию своего рекомендательного сервиса по кинофильмам компания Netflix предоставила разработчикам большой набор данных в целях совершенствования поисковых алгоритмов. Этот набор состоял из внутренних данных компании Netflix, которые были анонимизированы с целью удаления из них информации, которая позволяла бы точно идентифицировать клиента. К сожалению, разработчики смогли успешно осуществлять идентификацию клиентов по их идентификаторам пользователей в базе данных Netflix – посредством сопоставления анонимных рецензий в наборе данных Netflix и публично доступных рецензий на сайте Internet Movie Database.
Этот случай наглядно показал, что даже анонимные данные можно отследить вплоть до истинных пользователей посредством коррелирования имеющейся информации со сведениями из других общедоступных источников. Компания Netflix отреагировала на это, исключив из своего набора данных часть информации, однако включила в него другую информацию (почтовый индекс, возраст и пол пользователя), в результате чего и этот подход также оказался уязвимым. Университет Карнеги-Меллона установил, что при наличии такой информации личность можно идентифицировать по почтовому индексу, возрасту и полу в 87% случаев.
Этот пример иллюстрирует одну из опасностей, порождаемых большими данными. Даже после анонимизации данных остается возможным извлечение секретной или приватной информации посредством коррелирования с внешними данными. В тех случаях, когда наборы данных подпадают под действие нормативных требований (таких, например, как Закон о преемственности и подотчётности медицинского страхования [Health Insurance Portability and Accountability Act, HIPAA]), необходимо предпринимать дополнительные меры с целью избежания более серьезных юридических последствий в результате таких утечек.
Начнем с описания проблемы, а затем перейдем к детальному рассмотрению решения под названием Sentry от компании Cloudera.
Безопасность в экосистеме Hadoop
На сегодняшний день платформа Hadoop обеспечивает надежную защиту на уровне файловой системы. Хочу напомнить, что файловая система HDFS (Hadoop Distributed File System) реализуется поверх другой нативной файловой системы (например, ext3). Средства контроля доступа для Hadoop реализуются с использованием разрешений на основе файлов, соответствующих модели разрешений UNIX®. Хотя эта модель предоставляет разрешения на уровне файлов в рамках HDFS, ей не хватает более детализированных средств управления доступом.
В качестве примера рассмотрим файл в системе HDFS, содержащий рецензии на фильмы от множества пользователей. Эти рецензии (помимо собственно рецензии на некоторый фильм с определенным названием) включают в себя идентификатор пользователя, а также его почтовый индекс, пол и возраст. В среде Hadoop доступ осуществляется согласно модели все или ничего
. Если вы способны получить доступ к файлу с использованием модели разрешений, то вы сможете обратиться ко всем полям внутри этого файла. Таким образом, необходима более детализированная модель доступа. Другими словами, если для всей совокупности данных в пределах определенного файла предъявляются более высокие требования безопасности, то для отдельных полей данных могут быть установлены менее строгие требования безопасности (например, для всех данных, кроме идентификатора пользователя и его почтового индекса). Разрешение доступа только к данным с менее высоким уровнем защиты минимизирует возможность утечки информации о пользователе; а доступ к отдельным полям на основе ролей позволяет ограничивать доступ внутри файлов вместо доступа к файлу по принципу все или ничего
.
Совокупная проблема безопасности данных в среде Hadoop становится еще более трудной, если учитывать ее реализацию. Платформа Hadoop и ее обеспечивающая файловая система – это сложная распределенная система с большим количеством точек контакта. С учетом сложности и масштабности системы реализация обеспечения безопасности в ней сама по себе является сложной задачей. Любая реализация безопасности должна интегрироваться со всей архитектурой, чтобы гарантировать надлежащий уровень защиты.
Инфраструктуры авторизации и доступ на основе ролей
Решение Sentry поддерживает созданную ранее модель доступа на основе ролей под названием (RBAC) (Role-based Access Control), которая функционирует поверх
формы представления данных, характерной для реляционных баз данных (базы, таблицы, представления и т. д.). Модель RBAC поддерживает несколько функций, необходимых для защиты корпоративной среды больших данных. Первая функция – это защищенная авторизация, которая обеспечивает обязательное управление доступом к данным для аутентифицированных пользователей. Пользователям присваиваются роли, а затем предоставляются соответствующие полномочия по доступу к данным. Такой подход позволяет при помощи шаблонов масштабировать модель, разделяя пользователей на категории в соответствии с их ролями. Это избавляет администраторов от необходимости выделения детализированных полномочий каждому пользователю. Кроме того, эта функция упрощает управление разрешениями и уменьшает нагрузку на администраторов, а также сводит к минимуму возможность ошибок и непреднамеренного предоставления доступа.
Следующая функция позволяет организовать администрирование пользовательских полномочий таким образом, чтобы распределить эту задачу между несколькими администраторами на уровне схемы или на уровне базы данных. Управление высокодетализированным контролем доступа к данным и к метаданным можно осуществлять на уровне баз данных. Например, определенная роль может разрешать пользователю применение к данным операции select, а другая роль может разрешать применение к данным операции insert (в масштабе сервера, базы данных и таблиц). Применительно к моему примеру с компанией Netflix это означает, что для менее строгих уровней безопасности роли могут быть определены таким образом, чтобы ограничивать видимость информации, идентифицирующей личность.
И, наконец, Sentry реализует аутентификацию с помощью давно существующего и проверенного протокола аутентификации Kerberos, интегрированного в Hadoop.
Применение решения Sentry в среде с HDFS, Hive и Impala
На рис. 1 показана базовая архитектура решения Sentry. Как вы вскоре узнаете, эта архитектура была спроектирована в расчете на расширяемость (с целью поддержки широкого разнообразия приложений на базе Hadoop) и на переносимость (для различных форм поставщиков данных).

Рисунок 1. Базовая архитектура решения Sentry
К сегодняшнему дню в проекте Cloudera реализована поддержка многих широко применяемых механизмов с открытым исходным кодом для выполнения SQL-запросов, в том числе для Apache Hive (посредством RPC-интерфейса HiveServer2 на базе thrift) и для Cloudera Impala. Каждое приложение защищено посредством набора связываний, реализованных для этого конкретного приложения. Эти связывания взаимодействуют с механизмом политик с целью оценки и валидации заранее заданной политики безопасности, а затем, после санкционирования доступа, работают посредством абстрагирования политики с целью получения доступ к нижележащим данным. Современные основанные на файлах абстракции интегрируют поддержку доступа к HDFS или к локальной файловой системе в соответствии с политикой безопасности.
Итак, какое значение это имеет для Hive и для Impala? Sentry обеспечивает высокодетализированную авторизацию с возможностью задания средств управления безопасностью для сервера, для базы данных, для таблицы и для представления, включая такие возможности, как специфицирование селективных полномочий для представлений и для таблиц, вставка полномочий в таблицы и преобразование полномочий на серверах. Каждая база данных и каждая схема могут иметь раздельные политики авторизации. Кроме того, Sentry обеспечивает поддержку для архитектуры метахранилища Hive.
С целью поддержки более высокой степени расширяемости решение Sentry обеспечивает защиту новых приложений, таких как Apache Pig (с помощью набора Pig-связываний), и доступ к новым абстракциям для использования в политиках безопасности (например, к базам данных). Все эти возможности реализованы как подключаемые интерфейсы.
В настоящее время решение Sentry доступно в составе выпуска Cloudera CDH v4.3 для использования с Hive и Impala v1.1. Кроме того, решение Sentry можно загрузить отдельно с веб-сайта Cloudera в виде дополнения. Решение Sentry выпускается в соответствии с лицензией Apache 2.
Другие аспекты безопасности в среде Hadoop
Sentry предоставляет инфраструктуру авторизации на основе ролей, однако это не единственная инновация в области безопасности, появившаяся в последнее время в Hadoop. Рассмотрим еще один современный проект в сфере защиты и контроля доступа к большим данным.
Project Rhino
Проект с открытым исходным кодом Project Rhino осуществляется компанией Intel с целью совершенствования платформы Hadoop с помощью дополнительных механизмов защиты. Цель этого проекта состоит в устранении брешей безопасности в стеке Hadoop и в обеспечении многокомпонентной безопасности в рамках экосистемы Hadoop. С этой целью Intel осуществляет разработку в сфере безопасности по нескольким направлениям и ориентируется на криптографические возможности.
Среди всего разнообразия работ, выполняемых в рамках Project Rhino, наиболее интересны новые возможности для шифрования/дешифрования файлов в рамках нескольких моделей использования. Например, добавление общего уровня абстракции для криптографических кодеков реализует API-интерфейс, посредством которого несколько таких кодеков можно зарегистрировать и использовать в определенной среде. Для поддержки этой возможности разрабатывается соответствующая среда для распределения ключей и управления ими.
Кроме того, в стадии разработки находится криптографическая файловая система Hadoop (под названием CFS Hadoop)? которая будет предоставлять низкоуровневые криптографические сервисы для файлов в рамках HDFS. На этом уровне любой пользователь Hadoop сможет прозрачно задействовать новые средства безопасности данных (от приложений MapReduce до Hive, Apache HBase и Pig).
И, наконец, в стадии разработки находятся такие сервисы, как прозрачное шифрование моментальных снимков и журналов транзакций на диске, а также новые возможности Pig для поддержки функций загрузки и хранения с учетом возможностей шифрования.
Apache Knox Gateway
Apache Knox Gateway – это решение для защиты периметра Hadoop. В отличие от решения Sentry, которое предоставляет средства для высокодетализированного контроля доступа к данным, решение Knox Gateway обеспечивает контроль доступа к сервисам платформы Hadoop. Цель Knox Gateway – предоставить единую точку безопасного доступа к Hadoop-кластерам. Это решение реализовано в виде шлюза (или небольшого кластера шлюзов), который представляет доступ к Hadoop-кластерам посредством API-интерфейса в стиле REST (Representational State Transfer). Этот шлюз поддерживает брандмауэр между Hadoop-кластерами и пользователями (см. рис. 2) и позволяет управлять доступом к кластерам, на которых исполняются разные версии Hadoop
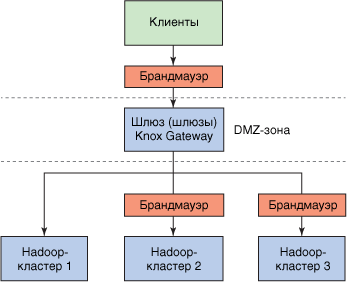
Рисунок 2. Защита периметра с помощью решения Apache Knox Gateway
Решение Knox Gateway дополняет Sentry, реализуя внешний уровень защиты доступа. В качестве шлюза в DMZ-зоне решение Knox Gateway обеспечивает контролируемый доступ к одному или более Hadoop-кластерам, отделенным друг от друга сетевыми брандмауэрами.
Технология делегируемых токенов
Решения Apache Knox Gateway и Sentry обеспечивают защиту периметра и защиту доступа к данным. Помимо этого необходимо защищать доступ к HDFS-данным со стороны задач MapReduce. Одно такое решение, используемое в Oozie, базируется на концепции делегируемых токенов (delegation token). Технология делегируемых токенов базируется на протоколе двухсторонней аутентификации, что позволяет пользователю аутентифицировать себя на узле Namenode (с использованием Kerberos); после получении delegation token пользователь может предоставить данный токен в узел JobTracker, в результате чего Hadoop-задания для этого пользователя смогут использовать этот токен для безопасного доступа к данным в рамках HDFS.
Планировщик потока работ для управления Hadoop-заданиями Oozie использует делегируемые токены при представлении Oozie-заданий в Hadoop. После определения аутентифицированный пользователь предоставляет задание в планировщик Oozie, результатом чего является запрос на делегируемый токен от узла JobTracker. В рамках представления задания делегируемый токен, предоставленный для будущего задания Hadoop, обращается к HDFS. Результирующие задачи MapReduce для этого задания используют соответствующий делегируемый токен, чтобы обеспечить полную защиту результирующей работы.
Делегируемые токены опираются на двухстороннюю аутентификацию, которая проще и эффективнее, чем трехсторонняя аутентификация, используемая в Kerberos. Это различие сводит к минимуму трафик Kerberos, а также улучшает масштабирование и уменьшает нагрузку на активы Kerberos.
Что дальше
Решение Sentry, предоставленное в Apache Incubator компанией Cloudera, представляет собой большой шаг по направлению к расширяемой платформе аутентификации. В условиях роста Hadoop-кластеров и увеличения количества их арендаторов Sentry обеспечивает фундамент для защиты конфиденциальных данных и сводит к минимуму потенциальные возможности утечек, которые ранее были возможны. Для развертываний в медицинских, финансовых или государственных учреждениях, обязанных соблюдать строгие требования по защите данных (такие как HIPAA и закон Сарбейнса-Оксли), Sentry является желанным дополнением к экосистеме Hadoop. Решение Sentry не способно преодолеть все проблемы, возникающие в такой сложной системе, как Hadoop, однако представляет собой значительный шаг в правильном направлении. Применение Sentry в сочетании с другими средствами защиты Hadoop (такими как Knox Security Gateway и Project Rhino) приближает момент, когда Hadoop станет безопасной платформой с возможностями защиты корпоративного уровня.