Аннотация
Генетические алгоритмы представляют собой семейство алгоритмов, использующих некоторые из генетических принципов, присутствующих в природе для решения специфичных вычислительных задач. Этими естественными принципами являются: наследование, кроссовер, мутация, выживание наиболее приспособленных, миграция и другое. В статье описаны наиболее важные аспекты генетического алгоритма как стохастического метода решения различных классов задач оптимизации. В ней также описывается выбор основных генетических операторов селекции, кроссовера и мутации, служащие для нового поколения особей для достижения оптимального или достаточно хорошего решения проблемы оптимизации, о которой идет речь.
Ключевые слова: Генетический алгоритм, Особи, Генетический оператор, Селекция, Кроссовер, Мутация.
1. Введение
Слово эвристический происходит от греческого слова ευριεσκω, которое имеет значение Я нахожу. Отсюда сразу можно предположить, что эвристические алгоритмы, по сути дела, были получены из экспериментов, чтобы получить приемлемое решение. Важной особенностью эвристических алгоритмов является то, что они могут приблизительно, но все же достаточно хорошо решать проблемы экспоненциальной сложности. Однако следует подчеркнуть, что для некоторых проблем эвристические алгоритмы не могут привести к приемлемому решению, а для некоторых из проблем эвристические алгоритмы дают относительно низкие результаты.
Генетические алгоритмы – это надежные и адаптивные методы, которые в дополнение к другим областям применения могут быть использованы для решения комбинаторных задач оптимизации. Центральным понятием в описании генетических алгоритмов является популяция особей, которая обычно составляет от 10 до 200; каждая особь представляет собой возможное решение в пространстве поиска для задачи (пространство всех решений).
Эти алгоритмы могут быть использованы для решения различных классов задач, поскольку они носят общий характер. По способу действия генетические алгоритмы являются одним из методов случайных поиска в пространстве решений для поиска глобального оптимума. В этой же группе можно классифицировать несколько других методов, основанных на аналогичных принципах, таких как:
- эволюционные стратегии,
- имитированный отжиг,
- генетическое программирование.
Эволюционные стратегии, разработанные в Германии в шестидесятые годы прошлого века, имеют множество общих черт с генетическим алгоритмом. Трудно определить границу между двумя подходами, имея в виду их различные варианты. Оба метода работают с совокупностью решений, над которыми реализованы определенные операции, которые периодически повторяются. Фазы этого процесса, имеющие модель в естественных эволюционных потоках, называются поколениями.
Имитированный отжиг – это процесс, который нашел основание в термодинамическом движении вещества к энергетическому минимуму при постепенном понижении температуры в качестве параметра системы. Метод работает с единственным решением, из которого на каждой итерации требуется соседнее
решение. Старое решение всегда заменяется новым, если оно подходит для удовлетворения критериев и, возможно, лучшее решение заменить худших лучше, если некоторые из стохастики удовлетворяет, регулированию температуры
системы. Более высокая температура дает более высокую вероятность того, что новое, даже худшее решение, заменит старое. Процесс начинается с определенной температуры, что позволяет относительно высокую вероятность принятия (более 50%), этот параметр должен экспоненциально уменьшаться, пока движение не станет почти детерминированным. Процесс начинается с определенной температуры, которая допускает относительно высокую вероятность принятия (более 50%), этот параметр должен экспоненциально уменьшаться, пока движение не станет почти детерминированным.
Генетическое программирование – это автоматизированный процесс оптимизации компьютерных программ, целью которого является решение наиболее сложных проблем в области вычислительной техники, а также проблемы, с которыми мы сталкиваемся каждый день. Концепция основана на идеях, взятых из общей теории генетических алгоритмов и других эволюционных методов. Проще говоря, конечной целью генетического программирования (как продукта) является универсальная компьютерная программа, которая находит решения проблем в качестве входных данных.
К генетическому программированию можно подходить несколькими способами и с разных точек зрения, таких как из линейных – большинство из них являются универсальным подходами к компьютерной программе, как формальное дерево в контексте теории графов. Фактически, любую компьютерную программу можно рассматривать как дерево или лес деревья (в широком смысле), где внутренние узлы дерева играют роль оператора (или функция нескольких переменных) и оставляют роль операндов. В этом случае набор операторов (набор функций, F) и операнды (набор терминалов, T) являются предопределенными наборами окончания.
В соответствии с общей теорией эволюционных алгоритмов можно сказать, что роль хромосомного генетического программирования с нелинейными структурами играют графы и деревья. Это свойства деревьев как строгих математических объектов, такие как простой рекурсивный тур, изолировали ход развития генетического программирования в явном направлении.
Генетические алгоритмы имитируют естественный эволюционный процесс. Эволюционный процесс можно определить следующим образом:
- существует популяция особей;
- некоторые особи лучше других (лучше приспособлены к окружающей среде);
- лучшие особи имеют более высокую вероятность выживания и размножения;
- свойства особей записываются в хромосомах с использованием генетического кода;
- потомки наследуют свойства (характеристики) родителей;
- Мутация может повлиять на особь.
Особи представляют собой потенциальные решения для генетического алгоритма, тогда как окружающая среда является целевой функцией.
Все данные об особи записываются в одну хромосому. В наиболее общем случае хромосомой может быть любая структура данных, которая описывает характеристики одной особи. Хромосома представляет собой возможное решение данной проблемы для генетического алгоритма. Для каждой структуры данных необходимо определить генетические операторы.
Эти генетические операторы должны быть определены так, чтобы особи не создавали новые решения, которые невозможны, потому что таким образом значительно снижается эффективность генетического алгоритма.
Независимо от того, какого вида генетического алгоритма работает, алгоритм имеет следующие параметры: размер популяции, количество поколений или итераций и вероятность мутации. Для поколений генетического алгоритма следует упомянуть, и вероятность гибридизации. В исключающем генетическом алгоритме вместо вероятностей скрещивания задается количество особей для исключения.
2. Кодирование и Фитнес функции
Важным аспектом генетического алгоритма является определение функции шифрования (кодирование) и адаптивность (приспособленность), которые очень важны для адаптации к характеру конкретной проблемы. И как было сказано, обычно используют двоичное кодирование или же более сложный алфавит. Предпочтительно связью между генетическими кодами и решениями проблемы являются инъективы и картирование. Тогда возможно, что применение генетических операторов в определенном поколении называется некорректной особью или особи, генетический код которой не соответствует ни одному решению. Преодоление этой проблемы возможно несколькими способами. Один из способов заключается в определении таких особей, у которых функция приспособленности равна нулю, так что операторы уже используют такую селекцию для исключения особей. Этот подход оказался подходящим только тогда, когда отношение числа плохих и хороших особей в популяции слишком велико, что на практике бывает не часто. Возможно, однако, неправильное включение индивидов в популяцию, так что каждой плохой особи назначено значение штрафной функции. Цель состоит в том, чтобы все особи имели возможность участвовать в скрещивании, но подвергались дискриминации по отношению к правильной особи. Следует учитывать, баланс в значении штрафных функций, поскольку слишком маленькие значения могут привести к тому, что некоторые из генетических алгоритмов кодируют неправильную декальвацию решения, с другой стороны, чрезмерное наказание может привести к потере полезной информации из неправильных особей. Существует еще один способ решить эту проблему – плохих особей изменить таким образом, чтобы они стали хорошими или плохими но с возможностью корректной замены.
Вычисление функции приспособленности возможно несколькими способами. Некоторые из этих методов: прямая загрузка, линейное масштабирование, масштабирование интервалов, отсечение сигмы и другие. Простейшим способом измерения функции приспособленности является прямая загрузка, которая означает, что значение функции для адаптации образца берется из его значения целевой функции. Однако на практике этот подход дает плохие результаты.
Приспособленность для некоторых особей рассчитывается как линейная функция значений целевой функции и особей в случае линейного масштабирования. Для этого существуют различные подходы к выбору коэффициентов, которые точно определяют линейную функцию.
Масштабирующие функции в виде единиц измерения отображаются на интервале [0, 1], причем лучшая особь имеет приспособленность равную 1, а худшая имеет значение в 0.
Если формирование функций приспособленности происходит с использованием отсечения сигмы, то она рассчитывается по формуле (1)
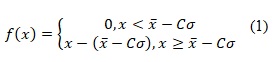
где x̄ и ? – среднее значение целевой функции и стандартное отклонение в популяции.
3. Селекция
Селекция напрямую связана с функцией приспособленности, и основным способом реализации этого генетического оператора является простой выбор рулетки. Этот метод использует распределение, где вероятность выбора пропорциональна приспособленности особи. Особи участвуют в соответствии со своим шансом и проходят либо не проходят процесс создания нового поколения. Недостаток селекции простой рулетки – это возможность преждевременной конвергенции из-за постепенного преобладания высокоприспособленных особей в популяции, которые не соответствуют глобальному оптимуму.
Это может быть использовано селекцией основываясь на ранжирования генетических кодов в соответствии с их приспособленностью, чтобы избежать этой проблемы. Функция приспособленности особи равна диапазону заранее заданного диапазона рангов и зависит только от положения индивидов в популяции. Это можно использовать в линейном способе, а также в других формах ранжирования.
Турнирная селекция – это еще одна форма селекции. В ней случайно сгенерированных подмножествах N единиц (N – это предопределенное число), и в каждом подмножестве принципом турнира выбирается лучшая особь, которая участвует в создании нового поколения. Обычно проблема заключается в выборе N, так чтобы уменьшить неблагоприятные эффекты стохастичности и чтобы более лучший и разнообразный генетический материал перешел к следующему поколению. В тех случаях, когда размер турнира является не целым числом, более правильным будет использование хорошо градуированного турнирного отбора (ХГТО). Подробное описание этих и других типов селекции и их теоретических аспектов можно найти в [1]. Применение точно градуированной турнирной селекции и практическое сравнение с другими операторами отбора приведены в [2-4].
4. Кроссовер
Процесс обмена генетическим материалом между особями родителями для формирования новых потомков, осуществляется оператором кроссовера. Наиболее распространенный тип оператора кроссовера: одноточечный, двухточечный, многоточечный и однородный кроссовер, а также может использоваться смешенный кроссовер (перемешивания), сокращенный суррогатный скрещивание, скрещивание с родителем, промежуточная рекомбинация и линейная рекомбинация.
Оператор скрещивания, который реализован в простом генетическом алгоритме, является одноточечным кроссовером. В одноточечном кроссовере определяется так называемое позиция сркщивания. Все гены с этой позиции меняются местами и создаются два потомка. В двухточечном кроссовере устанавливаются две позиции и происходит обмен генетическим материалом между родителями используя две позиции.
Следует отметить, что для каждой родительской пары определяется двоичный массив длины такой же, как у генетических родителей, и также у однородного кроссовера . Этот диапазон называется маской. Обмен генов выполняется только на тех позициях, где маска равна 0, а в тех местах, где она определена, родители сохраняют свои гены.
Интерференция в пересечении (или перетасовке), выбирает только одну точку пересечения, но прежде чем родители обмениваются генами, они перемешиваются
(разворачиваются). Гены потомства, возвращаясь в прежнее место после кроссовера, таким образом, также устраняют так называемое позиционное предпочтение (см. [5]).
Кроссовер с сокращенным суррогатом делает пересечение моря, когда это возможно, дает новое потомство. Обычно это пересечение реализуется местам ограниченного пересечения, в которых значения разных генов, об этом методе больше в [6].
Существует также метод пересечения с родителем. Он имитирует распространение насекомых (пчел), в которых одна особь (родитель) с лучшей характеристикой приспособленности участвует во всех скрещиваниях с другими особями (дронами). В некоторых примерах этот тип операторов пересечения достигает значительно лучших результатов, чем другие методы.
В промежуточной рекомбинации (скрещивании) используется у животных с реальными значениями генов и позволяет производить новые фенотипы вокруг и между значениями родительских фенотипов. Потомство получается по формуле O_1=P_1??(P_1-P_2), где ? – коэффициент масштабирования, который выбирается равномерно и случайным образом из интервала, обычно [-0,25, 1,25], а P_1 и P_2 являются родительскими особями. Каждая переменная семени является результатом объединения переменных родителей таким образом, который указан в формуле, по которой вновь выбирается ? для каждой родительской пары, больше об этим операторе в [7].
Линейная рекомбинация или кроссовер похожи на посредника, за исключением того, что они используют только одно значение для ? на пересечении [8].
Выбор оператора скрещивания должен быть адаптировано к характеру решаемых задач, как в случае определения функций приспособленности и других операторов.
5. Мутация
Оператор мутации считается одним из самых важных и поэтому может оказать решающее влияние на работу генетического алгоритма. Если генетический алгоритм использует двоичное кодирование, а у популяции нет некорректных единиц, то он обычно реализуется простым оператором мутации, который проходит через гены генетического кода особи и изменяет их либо не изменяет. Вероятность генной мутации Pmut представляет собой заданный небольшой размер, обычно взятый из интервала [0,001, 0,01]. Простую мутацию иногда можно реализовать через двоичное число – маску, которая произвольно генерируется для каждой особи и несет информацию о положении, в котором генетический код делается между генами.
Для ускорения реализации простого оператора мутации можно использовать биномиальное или нормальное распределение. Мутация с использованием биномиального распределения с использованием того факта, что случайная величина Xind = число мутированных генов имеет двоичное распределение особи, B(n, Pmut), где n – это длина генетического кода, Pmut – уровень мутации. Пусть F(K) будет функцией распределения. С F-1 мы найдем, что nmut = количество генов для мутации в данном генетическом коде. Позиции генов, которые мутированы, выбираются равномерно из {0, 1, …, n-1}. В случае длинного генетического кода могут возникнуть ошибки, при расчете количества nmut, поэтому удобно использовать мутацию с нормальным распределением. Если n > ?, тогда случайная величина Xind может быть аппроксимирована нормальным распределением.
N(n* Pmut; n* Pmut*(1- Pmut)), при условии, что n достаточно велико и при достаточно малом Pmut. Как и в предыдущем случае, мы используем обратную функцию нормальных функций распределения, чтобы вычислить количество мутантных генов и определить их позиции таким же образом. Это разработанный вариант этого оператора, который применяется ко всей популяции, поскольку мутация, использующая генетические коды всех образцов, может рассматриваться как одна сущность.
Если мутация не является однородной, что обычно происходит, когда гены генетического кода не эквивалентны, но некоторые части кода необходимы для мутации с меньшей или большей вероятностью, обычно используют обычную мутацию (применяемую в соответствии с нормальным распределением), экспоненциальная мутация (количество мутированных генов в коде экспоненциально уменьшается) и другое.
Когда генетический алгоритм использует целочисленное кодирование или реальными числами (с плавающей запятой), необходимо было разработать другие концепции мутации, которые и были сделаны. Это замена генов случайным образом выбранным числом (случайная замена), добавление или вычитание небольшого значения (ползучесть), умножение числа близко к одному (геометрическая ползучесть) и другое. Для обоих операторов мутаций ползучести требуемые значения являются случайными и могут иметь равномерное, экспоненциальное, гауссовское или биномиальное распределение (см. [9,10]).
В некоторых случаях гены полезны в зависимости от положения в генетическом коде, имеют разные уровни мутации. В связи с этим особенно важно понятие замороженного гена. А именно, если в положении генетического кода у всей или большей части популяции один и тот же ген, будет полезным иметь для мутации гена более высокий уровень, чем у остальной части генетического кода. Эта концепция используется для восстановления утраченного многообразия генетического материала, и эти гены называются замороженными.
6. Другие аспекты генетических алгоритмов
Успешное применение генетического алгоритма во многом зависит от выбора политики замены. Некоторые из наиболее важных политик поколения: генетический алгоритм поколений, генетический алгоритм устойчивого состояния и элитарная стратегия. Конечно, возможно объединить эти принципы./p>
Если применяется генетического алгоритма поколений, тогда применяется ко всем особям все генетические операторы, то есть нет привилегированных особей, которые собираются в следующее поколение, или особей, которые непосредственно проходят процесс отбора.
Напротив, генетический алгоритм устойчивого состояния благоприятствует лучшим особям в популяции, поэтому к ним не следует применять оператор селекции, но они переходят непосредственно на следующий этап, в то время как другие особи применяют селекцию, и они занимают остальные места.
Элитарная стратегия обеспечивает прямой переход в следующее поколение одних из лучших особей. К этим особям не применяются операторы селекции, кроссовера и мутации. Применяя генетические операторы к популяции особей, заполняйте оставшиеся места в следующем поколении.
Такой подход оставляет место для еще одного возможного улучшения генетического алгоритма, который кэшируется. Поскольку элитные особи переходят из поколения в поколение без изменений, Их значение остается неизменными. Поэтому было бы полезно вычислить значение элитных особей и запомнить их, а не постоянно вычислять, тем самым экономя время, необходимое для всего вычисления. Этот процесс называется кэшированием, и более подробная информация содержится в [11] и [7].
В частности, значения целевой функции особей хранятся в так называемой таблице хэш-строк с использованием кодов ЦКИ (примечание переводчика: циклический контроль избыточности), которые связаны с генетическим кодом особей. Если во время работы генетического алгоритма мы снова получаем один и тот же генетический код, то значение целевой функции берется из хеш-таблицы через код ЦКИ.
Техника, используемая для кэшированных генетического алгоритма, хорошо известная технология ННИ – Наименьше Недавно Использованная стратегия. Существует предел для этой концепции генетического алгоритма, и это то, что количество кешированных значений целевой функции ограничено Ncache, которое зависит от реализации.
7. Выводы
Механизм отбора благоприятствует особям с параметрами выше среднего и их выше среднего скорректированным частям (генам), которые получают более высокую вероятность сыграть роль в формировании нового поколения. Таким образом, плохо адаптированные особи и их гены уменьшают шансы на размножение, следовательно, постепенно вымирают.
Вклад в разнообразие генетического материала дает оператор кроссовера, который представляет собой рекомбинацию генов особей. Получается обмен генетическим материалом между особями с возможностью того, что хорошо приспособленные особи генерируют лучших особей как результат кроссоера, хотя и недетерминированный. С механизмом операторов кроссовера и совмещения менее адаптированных особей с более приспособленными особями, можно с некоторым шансом рекомбинировать хорошие гены чтобы получить хорошо адаптированную особь.
Однако, множественное применение операторов селекции и кроссовера может привести к потере генетического материала, и некоторые области в пространстве поиска становятся недоступными. Оператор мутации выполняет случайное изменение определенного гена, учитывая низкую вероятность Pmut, которая может восстановить потерянный генетический материал в популяции. Это основной механизм предотвращения преждевременной конвергенции генетического алгоритма в локальный экстремум.
Генетические операторы обеспечивают потомство, но не идентичных с их родителями, что позволяет популяции вырабатывать решение, отсутствовавшее в исходном наборе объектов (особей).
Эволюционный подход позволил генетическим алгоритмам сформировать правильный метод глобальной оптимизации, который способен прийти к решению, близкому к глобальному оптимуму или идентичному ему. Генетические алгоритмы могут применяться в традиционных проблемных областях, таких как задачи с большим количеством локальных оптимумов и разрывов, как и не зависеть от локальной информации.
Использованная литература
1. V. Filipovic, A Proposal to Improve Operator Tournament Selection in Genetic Algorithms,
Msa Thesis, Faculty of Mathematics, University of Belgrade, 1998, (in Serbian).
2. V. Filipovic, J. Kratica, D. Tosic and I. Ljubic, Fine Grained Tournament Selection for the Simple Plant Location Problem,
Proceedings on the 5th Online World Conference on Soft Computing Methods in Industrial Application—WSC5, 2000, pp. 152-158.
3. V. Filipovic, D. Tosic and J Kratica, Experimental Results in Applying of Fine Grained Tournament Selection,
Proceedings of the 10th Congress of Yugoslav Mathematicians, Belgrade, 21-24 January 2001, pp. 331-336.
4. V. Filipovic, Fine-Grained Tournament Selection Operator in Genetic Algorithms,
Computing and Informatics, Vol. 22, No. 2, 2003, pp. 143-161.
5. F.J. Burkowski, Shuffle Crossover and Mutual Information,
Proceedings of the 1999 Congres on Evolutionary Computation, 1999, pp. 1574-1580.
6. L. Booker, Improving Search in Genetic Algorithms: In Algorithms and Simulated Annealing,
Morgan Kaufmann Publichers, San Mateo, 1987, pp. 61-73.
7. H. Muhlenbein and D. Schlierkamp-Voosen, Predictive Models for the Breeder Genetic Algorithm: I. Continuous Parameter Optimization,
Evolutionary Computation, Vol. 1, No. 1, 1993, pp. 25-49. doi:10.1162/evco.1993.1.1.25
8. C. Hohn and C. R. Reeves, Embedding NeighbourHoodsearch Operators in a Genetic Algorithm for Graph Bipartitioning,
Ctac Technical Report, Coventry University, Reeves, 1995, pp. 33-34.
9. J. Kratica, Parallelization of Genetic Algorithms for Solving Some NP-complete Problems,
Ph.D. Thesis, Faculty of Mathematics, Belgrade, 2000, (in Serbian).
10. D. Tosic, N. Mladenovic, J. Kratica and V. Filpovic, Genetic Algorithm,
Institute of Mathematics SANU, Beograd, 2004, (in Serbian).
11. J. Kratica, Improvement of Simple Genetic Algorithm for Solving the Uncapacitated Warehouse Location Problem,
In: R. Roy, T. Furuhachi and P. K. Chawdhry, Eds., Advances in Soft Computing—Engineering Design and Manufactining, Springer-Verlang London Limited, London, 1999, pp. 390-402.