Применение технологии Data Mining для извлечения знаний из медицинской базы данных
Автор: Лебедев В.Е., Федяев О.И.
Источник: Компьютерная и программная инженерия. Сборник материалов международной научно-технической
конференции студентов, аспирантов и молодых учeных 15-16 декабря 2015 года. - Донецк, ДонНТУ - 2015. – 346с.,
с.
108-111.
Аннотация
Лебедев В.Е., Федяев О.И. Применение технологии data mining для извлечения знаний из медицинской базы данных.
В настоящее время накоплен огромный объ?м информации в виде различных баз данных. Как правило, деятельность любого предприятия (коммерческого, производственного, медицинского, научного) теперь сопровождается регистрацией и записью всех подробностей его деятельности. На людей обрушились колоссальные потоки информационной руды в самых различных областях. Стало ясно, что без продуктивной переработки эти потоки сырых данных образуют никому не нужную «свалку информации». Пришло понимание, что сырые данные, как правило, содержат глубинный пласт знаний, при грамотной раскопке которого могут быть обнаружены настоящие самородки полезных для практики знаний. Это привело к появлению современной технологии обработки данных –интеллектуальному анализу данных (Data Mining)[1,2].
Технология Data Mining (переводится как «добыча» или «раскопка данных») – собирательное название обозначающее совокупность методов обнаружения в данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний (закономерностей). Основу методов Data Mining составляют всевозможные методы классификации, моделирования и прогнозирования (деревья решений, искусственные нейронные сети, генетические алгоритмы, нечеткая логика) [1-4].
Цель данной работы состоит в применении методов автоматического выявления знаний в медицинской базе данных, содержащей статистические данные об исходах лечения пациентов после хирургического вмешательства. В частности оценивается эффективность алгоритма C 4.5 , который широко применяется для индуцирования знаний из баз данных [5]. Данный алгоритм по исходным данным, представленным в реляционной форме, автоматически строит деревья решений, которые в настоящее время являются самым распространённым подходом к выявлению и изображению логических закономерностей в данных.
Можно выделить такие достоинства деревьев решений:
- оптимизация;
- обобщение;
- быстрота и эффективность реализации;
- наглядность.
Можно выделить такие достоинства деревьев решений:
- проблема выбора критерия;
- остановки процесса деления на группы;
- проблема отсечения незначимых ветвей;
- построение слишком больших деревьев.
Если рассмотреть каждый путь движения по этому дереву с верхнего уровня (корня) на самые нижние (листья), то можно определить логические правила, т.е. выявленные знания в продукционной форме. Под правилом понимается логическая конструкция, представленная в виде "Если (А) то (В)", где А – цепочка конъюнкций вида «(условие 1) и (условие 2) и … и (условие N)».
Рассмотрим основные понятия алгоритма C4.5, которые используются при построении деревьев решений:
Т – множество примеров (реляционная таблица); |T| - мощность множества (число строк таблицы); целевой атрибут С принимает значения C1, C2, …, Ck ; A1, A2, …, Am – набор условных атрибутов, от которых зависит целевой атрибут С.
Атрибут класса С – это атрибут, по которому проводится классификация.
Обучающая выборка – набор данных, для которых известно значение целевого атрибута. С помощью этого набора данных происходит построение дерева решений.
Следует определить формат исходной обучающей выборки. Данные должны быть представлены в виде реляционной таблицы (табл. 1)
Структура входных данных Таблица 1.
| № п/п | Признак 1 | Признак 2 | … | Призна кm | Целевой атрибут |
| 1 | Признак 1 | Признак 2 | … | Призна кm | Целевой атрибут |
| 2 | Признак 1 | Признак 2 | … | Призна кm | Целевой атрибут |
| … | … | … | … | … | … |
| N | Признак 1 | Признак 2 | … | Призна кm | Целевой атрибут |
Для построения дерева решений необходимо выполнить следующие шаги:
- Выбрать целевой атрибут.
- Выбирается основной признак, по которому производится сортировка.
- Если выбранный признак даёт однозначное соответствие целевому атрибуту, то порождается продукционное правило, а иначе для подмножества примеров, в которых атрибут класса не однозначен, рекурсивно применяется пункт 2.
Достоинство алгоритма С4.5 заключается в том, что он определяет последовательность выбора основного атрибута для сортировки в зависимости от критерия минимизации энтропии. Алгоритм работает для таких таблиц данных, в которых атрибут класса (целевой атрибут) может иметь конечное множество значений.
Рассмотрим основную идею выбора очередного атрибута для сортировки:
Пусть Х – рассматриваемый атрибут, принимающий n значений A1, A2, …, An. Тогда разбиение множества Т по атрибуту Х даст нам подмножества(подтаблицы) T1, T2, …, Tn.
freq(Cj, T) – количество примеров из множества Т, в которых атрибут класса равен Cj.
Тогда вероятность того, что случайно выбранная строка из таблицы Т будет принадлежать классу Cj, равна
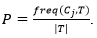
Согласно теории информации, количество содержащейся в сообщении информации зависит от её вероятности log2(1/P) = - log2(P). В качестве единицы энтропии принят бит, что соответствует логарифмам при основании 2 [6].
Энтропия таблицы Т, т. е. среднее количество информации, необходимой для определения класса, к которому принадлежит строка из таблицы Т:
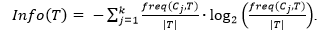
Энтропия таблицы Т после её разбиения по атрибуту Х на n подтаблиц равна
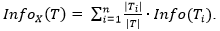
Критерий для выбора атрибута Х – следующего атрибута для разбиения:

Шаги алгоритма С4.5 [7]:
- Для всех условных атрибутов таблицы Т вычисляем критерий разбиения Gain(Xi). Выбираем такой атрибут Х, для которого Gain(Xi) максимально.
- Разбиваем таблицу по выбранному атрибуту на N подтаблиц. Проверяем каждую
подтаблицу
следующим образом:
- Если подтаблица монотонна (все строки относятся к одному классу), то порождаем правило.
- Иначе рекурсивно применяем алгоритм С4.5 к полученной подтаблице.
С помощью описанного алгоритма были выявлены закономерности в собранных статистических данных по лечению больных, которые перенесли хирургические операции.
Таблица 2
Данные об исходах лечения пациентов, перенёсших хирургические операции
| Возраст | Длительность операции | Комбинация операций | Наличие сопутствующей патология | Исход лечения |
| молодой | 60-90 мин. | резекция прямой кишки+холецистэктомия | нет | благоприятный |
| молодой | 60-90 мин. | резекция прямой кишки+холецистэктомия | есть | благоприятный |
| молодой | 91-120 мин. | резекция сигмовидной кишки+холецистэктомия | нет | благоприятный |
| средний | 60-90 мин. | резекция сигмовидной кишки+холецистэктомия | нет | благоприятный |
| средний | 91-120 мин. | резекция сигмовидной кишки+холецистэктомия | есть | благоприятный |
| средний | 121-180 мин. | резекция прямой кишки+холецистэктомия | есть | удовлетворительный |
| средний | 181-240 мин. | резекция прямой кишки+холецистэктомия | нет | удовлетворительный |
| средний | 241-300 мин. | резекция прямой кишки+холецистэктомия | есть | не удовлетворительный |
| пожилой | 60-90 мин. | резекция прямой кишки+холецистэктомия | нет | благоприятный |
| пожилой | 121-180 мин. | резекция прямой кишки+холецистэктомия | есть | удовлетворительный |
| пожилой | 181-240 мин. | резекция прямой кишки+холецистэктомия | есть | удовлетворительный |
| старческий | 60-90 мин. | резекция прямой кишки+холецистэктомия | есть | благоприятный |
| старческий | 91-120 мин. | резекция прямой кишки+холецистэктомия | есть | благоприятный |
| старческий | 181-240 мин. | резекция прямой кишки+холецистэктомия | есть | не удовлетворительный |
| старческий | 181-240 мин. | резекция прямой кишки+холецистэктомия | есть | не удовлетворительный |
По алгоритму С4.5 было построено дерево решений, которое показано на рис. 1:
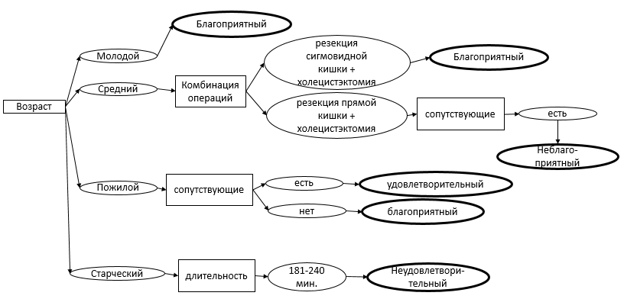
Рис. 1 Дерево решений, построенное алгоритмом С4.5
Обход этого дерева по каждой ветви от корня к листу порождает 6 продукционных правил, часть из которых приведена ниже:
-
Если (Возраст = молодой)
то (Исход лечения = благоприятный);
-
Если (Возраст = пожилой) и (Сопутствующие патологии = есть)
то (Исход лечения = удовлетворительный).
Выявленная закономерность будет использоваться для прогнозирования тактики лечения новых пациентов в зависимости от значений показателей, характеризующих состояние больного и проводимую операцию. Для этого будет разработана соответствующая экспертная система, наполняемая извлечёнными знаниями из базы медицинских данных.
Литература
1. В.Дюк, А.Самойленко. Data mining: учебный курс. – СПб: Питер, 2001. 368 с.
2. Т.А.Гаврилова, В.Ф.Хорошевский. Базы знаний интеллектуальных систем. СПб.: Питер, 2000. – 384 с
3. Г.В.Рыбина. Основы построения интеллектуальных систем: учеб. пособие. – М.: Финансы и статистика; ИНФРА-М,
2010.- 432 с.
4. Т.А.Гаврилова, К.Р.Червинская Извлечение и структурирование знаний для экспертных систем. – М.: Радио и
связь, 1992.
5. J. R. Quinlan. C4.5: Programs for Machine learning. Morgan Kaufmann Publishers 1993.
6. Ю.М. Коршунов. Математические основы кибернетики. - М. Энергия, 1980. – 424 с.
7. И.В.Бибиков, Р.Ю.Черевко, О.И.Федяев, И.Ю.Бондаренко. Автоматизированное извлечение знаний из реляционных
баз данных.// Інформаційні управляючі системи та комп’ютерний моніторинг 2013 (ІУСКМ -2013): IV Міжнар.
науково-технічна конф. студентів та молодих вчених/ 24-25 квітня 2013р. м. Донецьк : зб. доп./ Донец.
націонал. техн. ун-т; редкол. В.А. Світлична. – Донецьк: ДонНТУ, 2013. – в 2 тт, - Т.1. – С. 405-410.