Аннотация
Облачные вычисления предоставляют пользователям различные виды услуг. Хранение как услуга – это одна из услуг, предоставляемых облачной инфраструктурой, в которой большой объем электронных данных хранится в облаке. Поскольку ценные и важные данные предприятий хранятся в удаленном облачном хранилище, мы должны быть уверены, что наши данные в безопасности и будут доступны в любое время. В таких ситуациях, как наводнения, пожары, землетрясения или любые неисправности оборудования или случайное удаление, наши данные могут больше не быть доступными. Для обеспечения безопасности данных должна существовать некоторая техника резервного копирования данных для облачной платформы, чтобы эффективно восстанавливать ценные и важные данные в ситуациях, упомянутых выше. В этой статье представлен обзор различных методов резервного копирования, используемых для платформы облачных вычислений.
Ключевые слова: начальный блок, генератор случайных чисел, удаленный сервер, главный сервер, J-битная кодировка
I. ВВЕДЕНИЕ
Облачные вычисления – это компьютерная технология, основанная на Интернете. Она предполагает совместное использование ресурсов в несмотря на наличие собственного локального хранилища и устройств для обслуживания различных услуг. Облачные вычисления стали гигантскими технологиями, которые превосходит все другие старые вычислительные технологии (распределенные вычисления). Облачные вычисления обеспечивают различные преимущества по сравнению с предыдущими компьютерными технологиями. Облачные вычисления обеспечивают суперкомпьютерные вычисления и высокопроизводительные вычислительные мощности для своих клиентов по очень низкой цене.
Облачные вычисления включают в себя сети больших групп серверов, которые, как правило, используют недорогие потребительские ПК-технологии, а также специализированные соединения, которые распределяют между собой хранилище данных. Эта общая облачная инфраструктура содержит большие пулы систем, которые связаны друг с другом. Эти виртуализированные пулы используются для максимизации мощности облачных вычислений, а данные хранятся в форме виртуализированных пулов.
Поскольку облачные вычисления предполагают совместное использование вычислительных ресурсов, большое количество пользователей совместно используют одно и то же хранилище и другие вычислительные ресурсы. Поэтому существует острая необходимость в механизме, который предотвращал бы доступ других пользователей к вашим важным и полезным данным преднамеренно или случайно, а также в случае, если какой-то другой пользователь в облаке обращается к вашим данным и вносит какие-либо изменения или любое удаление, тогда они должны быть восстановимы в исходное состояние эффективным способом. Кроме того, хранимые данные находятся в опасности из-за любых стихийных бедствий, таких как любое наводнение, пожар и т.д. Стихийные бедствия, например, наводнение, могут сделать восстановление данных невозможной задачей. Проливная вода содержит загрязненную воду, которая может содержать пыль, остатки песка и другие материалы, которые могут повлиять на пластины и сектора жесткого диска. Части жесткого диска могут заклинивать так же, как двигатель при загрязнении. Также многие компании, которые полагались на электронные данные, страдают от полной или временной потери данных из-за повреждения и сбоя оборудования. Целостность данных является еще одной проблемой при восстановлении потерянных данных.
II. СВЯЗАННЫЕ РАБОТЫ
В следующих разделах описывается обзор различных работ, касающихся этой проблемы. Ниже предложены различные методы резервного копирования данных для облачных вычислений.
В [1] г-жа Крути Шарма предложила использование архитектуры алгоритма изначальных блоков (Seed Block Algorithm Architecture) вместе с удаленным сервером резервного копирования. Удаленный сервер резервного копирования – это копия исходного облачного сервера, который физически расположен в удаленном месте. Этот метод основан на концепции операции Исключающее ИЛИ (Exclusive-OR) цифровых вычислений. Весь механизм состоит из трех основных частей: 1. Главный облачный сервер 2. Клиенты облака и 3. Удаленный сервер. Алгоритм блока семян использует случайное число и уникальный идентификатор клиента, связанный с каждым клиентом.
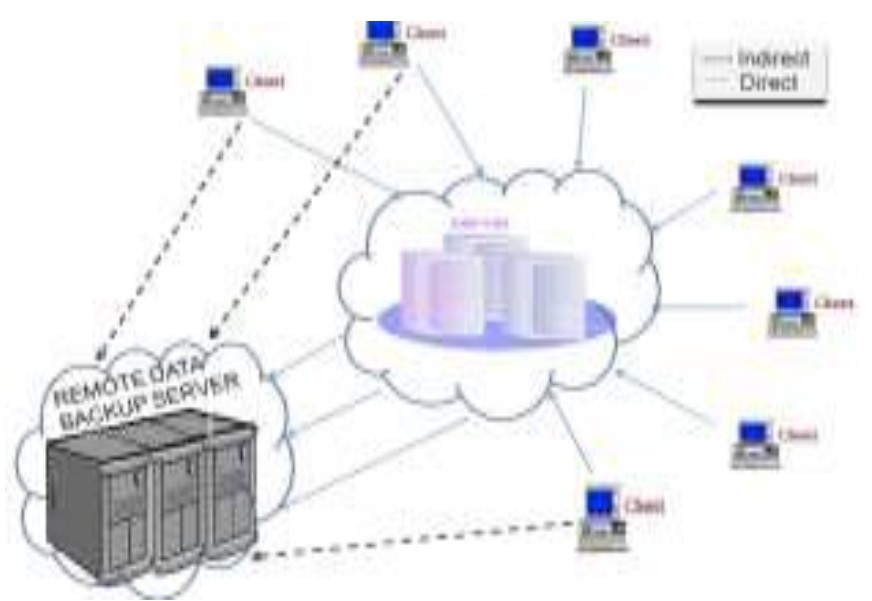
Рисунок 1 – Сервер удаленного резервного копирования и его архитектура
Каждый раз, когда новый клиент регистрируется в облаке, его уникальный идентификатор генерируется с XOR и случайным числом. Результат этой XOR операции называется изначальным блоком, который будет использоваться только для этого конкретного клиента. Всякий раз, когда клиент размещает какие-либо данные в облаке, они сохраняются облаке, и в то же время данные проходят через XOR алгоритм со своим изначальным блоком, и результирующие данные сохраняются на удаленном сервере. Если в главном облаке происходит какая-либо случайная потеря данных, то в таких случаях исходные данные восстанавливаются путем использования XOR алгоритма над данными с изначальным блоком этого конкретного клиента для получения исходных данных.
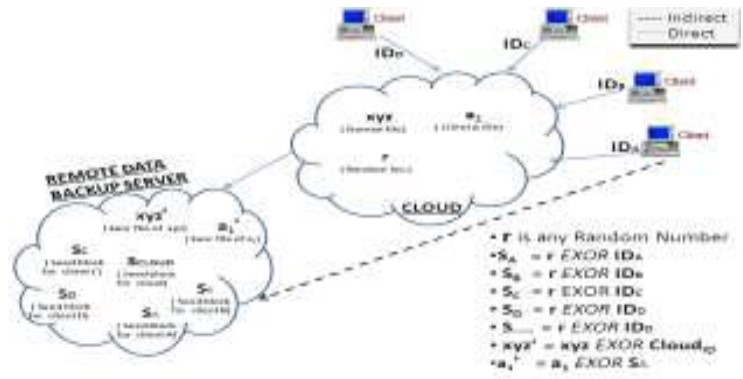
Рисунок 2 – Алгоритм изначального блока и его архитектура
Этот метод полностью способен точно восстанавливать файлы данных в любой ситуации с потерей данных, и в то же время поддерживает целостность данных. Недостаток этого метода заключается в том, что он неэффективен, поскольку файлы данных на удаленном сервере занимают то же пространство, что и в основном облаке, поэтому возникает нехватка места для хранения. Объем памяти на удаленном сервере можно уменьшить, применяя методы сжатия для достижения высокой эффективности.
В [2] Чи-Вон Сонг, Сунгмин Парк, Донг Вук Ким и Суонг Канг, предложили новую платформу службы восстановления данных для облачной инфраструктуры, Облачный Сервис Паритета (Parity Cloud Service – PCS), предоставляющую защищенную конфиденциальность службу восстановления личных данных. В этой предложенной структуре пользовательские данные не требуется загружать на сервер для восстановления данных. Все необходимые серверные ресурсы, которые предоставляют услуги восстановления, находятся в разумных пределах. Преимущества Parity Cloud Service заключаются в том, что он обеспечивает надежное восстановление данных при низких затратах, но недостатком является более высокая сложность его реализации.
В [3] Виджайкумар Джаварайя представил механизм оперативного резервного копирования данных для облака вместе с аварийным восстановлением. При таком подходе стоимость резервного копирования для облачной платформы была снижена, а также она защищает данные от сбоев, в то же время процесс перехода от одного поставщика облачных услуг к другому становится проще и намного проще. При таком подходе потребители не зависят от поставщика услуг, и это также устраняет связанные с этим затраты на восстановление данных. Используется простой аппаратный блок, позволяющий добиться всего этого за небольшую плату.
В [4], Йоичиро Уэно, Норихару Мияхо, Шуичи Сузуки, Музай Гакуэндай, Инзай-ши, Тиба и Казуо Ичихара предложили инновационную концепцию резервного копирования файлов HS-DRT, в которой используется эффективный сверх широко распределенный механизм передачи данных и высокоскоростная технология шифрования. Эта система состоит из двух последовательностей: одна – последовательность резервирования, другая – последовательность восстановления. Данные для резервного копирования принимаются в последовательности резервирования. Последовательность восстановления используется в случае аварии или потери данных, когда Наблюдательный сервер (один из компонентов HS-DRT) запускает последовательность восстановления. У этого подхода есть некоторые ограничения, и поэтому эту модель нельзя объявить идеальной техникой резервного копирования и восстановления в облаке. Хотя эту модель можно использовать для мобильных клиентов, таких как ноутбуки, смартфоны и т.д., стоимость восстановления данных сравнительно увеличена, а также увеличена избыточность.
В [5], Джузеппе Пирро, Паоло Трунфио, Доменико Талия, Паоло Миссе и Кэрол Гобл предложили эффективную маршрутизацию, основанную на таксономии (ERGOT), которая полностью основана на семантическом анализе и не фокусируется на времени и сложности реализации. Эта система основана на семантике, обеспечивающей поддержку обнаружения служб в облачных вычислениях. Эта модель построена на трёх компонентах: первый – протокол DHT (распределенная хэш-таблица), второй – SON (семантическая оверлейная сеть) и третий – мера семантического сходства в описании услуг. Мы фокусируемся на этом методе, потому что это не просто простая технология, а скорее эффективный поиск данных, полностью основанный на семантическом сходстве между описаниями сервисов и запросов сервисов. ERGOT предлагает семантически управляемый ответ на запросы в системах на основе DHT путем построения SON поверх DHT, но он не подходит для моделей поиска семантического сходства. Недостатком этой модели является сокращение времени и сложности реализации.
В [6], Элени Палкопулуи, Доминик А. Шупке и Томас Баушерти предложили один метод, который в основном сфокусирован на значительном снижении стоимости и сценарии сбоя маршрутизатора, другими словами (SBBR). Он включает в себя логическое подключение IP, которое останется неизменным даже после сбоя маршрутизатора. Наиболее важным фактором этой модели является то, что она обеспечивает систему управления сетью через многоуровневую сигнализацию. Кроме того, эта модель показывает, как сервис предъявляет максимальные требования к простоям, которые напрямую влияют на настройку архитектуры SBRR (например, навязывает минимальное количество общих ресурсов маршрутизатора для всей сети). Проблема модели заключается в том, что она не может включить концепцию оптимизации в сокращение затрат.
В [7], Шехерьяр Малик, Фабрис Уе, предложил модель с наименьшими затратами для модели «Сдача в аренду арендуемых ресурсов». Этот метод направлен на снижение денежных затрат облачного сервиса. Он предлагает модель для объединения кросс-облачных вычислений, которая состоит из трех этапов: 1) обнаружение, 2) установление соответствия и 3) аутентификация. Эта модель основана на концепции поставщиков облачных услуг, которые арендуют ресурсы у разных предприятий и после виртуализации сдают их клиентам в качестве облачных сервисов.
В [8], Лили Сунь, Цзяньвэй Ань, Ян Ян и Мин Цзэн предложили метод, в котором постепенно увеличивается стоимость при увеличении объема данных, т.е. стратегия холодного и горячего резервного копирования, которая выполняет резервное копирование и восстановление при обнаружении неисправностей. В CBSRS (Стратегии замены службы холодного резервного копирования) процесс восстановления запускается при обнаружении сбоя службы и не запускается при отсутствии сбоя, т.е. когда служба доступна. HBSRS (Стратегия замены службы горячего резервирования) – это трансцендентная стратегия восстановления для структуры службы, которая используется для динамической сети. Во время реализации процесса, службы резервного копирования остаются в активированном состоянии, и первые возвращенные результаты служб будут использоваться для обеспечения успешной реализации композиции служб.
III. ОЦЕНКА И ОБСУЖДЕНИЕ
Преимущества и недостатки всех описанных выше методов описаны в Таблице 1. Из-за высокой применимости и необходимости процесса резервного копирования во многих компаниях и предприятиях роль удаленного сервера резервного копирования данных с эффективным методом очень важна и является актуальной темой исследования.
Таблица 1. Сравнение различных методов резервного копирования и восстановления
| № | Подход | Преимущество | Недостатки |
| 1 | SBA[1] | Прост в реализации | Неэффективность |
| 2 | Parity Cloud Service[2] | Конфиденциальность, низкая стоимость | Высокая сложность |
| 3 | LINUX BOX[3] | Низкая стоимость | Высокая пропускная способность, полное резервное копирование сервера за раз |
| 4 | HSDRT[4] | Используется для передвижных клиентов | Стоимость, большая избыточность |
| 5 | ERGOT | Точный поиск соответствия, конфиденциальность | Повышенная сложность |
| 6 | Cold/Hot Backup Strategy[8] | Срабатывает только при обнаружении сбоя | Стоимость увеличивается по мере увеличения данных |
IV. ЗАКЛЮЧЕНИЕ
Все вышеперечисленные методы охватывают различные вопросы резервного копирования и восстановления данных для облачных вычислений, такие как поддержание стоимости внедрения и сложности реализации как можно ниже. Однако каждое из решений резервного копирования для облачных вычислений не может решить все проблемы удаленного резервного копирования данных с меньшим объемом дискового пространства.
СПИСОК ЛИТЕРАТУРЫ
[1] Ms. Kruti Sharma, Prof. Kavita R Singh, 2013 “Seed Block Algorithm: A Remote Smart Data Back-up Technique for Cloud Computing” International Conference on Communication Systems and Network Technologies IEEE.
[2] Chi-won Song, Sungmin Park, Dong-wook Kim, Sooyong Kang, 2011, “Parity Cloud Service: A Privacy-Protected Personal Data Recovery Service,” International Joint Conference of IEEE TrustCom-11/IEEE ICESS-11/FCST-11.
[3] Vijaykumar Javaraiah, Brocade Advanced Networks and Telecommunication systems (ANTS), 2011,“Backupforcloud and Disaster Recovery for Consumers and SMBs,” IEEE 5th International Conference, 2011.
[4] Yoichiro Ueno, Noriharu Miyaho, Shuichi Suzuki,Muzai Gakuendai, Inzai-shi, Chiba,Kazuo Ichihara, 2010, “Performance Evaluation of a Disaster Recovery System and Practical Network System Applications,” Fifth International Conference on Systems and Networks Communications, pp 256-259.
[5] Giuseppe Pirr?o, Paolo Trunfio , Domenico Talia, Paolo Missier and Carole Goble, 2010, “ERGOT: A Semantic-based System for Service Discovery in Distributed Infrastructures,” 10th IEEE/ACM International Conference on Cluster, Cloud and Grid Computing.
[6] Eleni Palkopoulouy, Dominic A. Schupke, Thomas Bauscherty, 2011,“Recovery Time Analysis for the Shared Backup Router Resources (SBRR) Architecture”, IEEE ICC.
[7] Sheheryar Malik, Fabrice Huet, December 2011, “Virtual Cloud: Rent Out the Rented Resources," 6th International Conference on Internet Technology and Secure Transactions,11-14 ,Abu Dhabi, United Arab Emirates.
[8] Lili Sun, Jianwei An, Yang Yang, Ming Zeng, 2011, “Recovery Strategies for Service Composition in Dynamic Network,” International Conference on Cloud and Service Computing
[9] Y.Ueno, N.Miyaho, and S.Suzuki, , 2009, “Disaster Recovery Mechanism using Widely Distributed Networking and Secure Metadata Handling Technology”, Proceedings of the 4th edition of the UPGRADE-CN workshop, pp. 45-48.
[10] Xi Zhou, Junshuai Shi, Yingxiao Xu, Yinsheng Li and Weiwei Sun, 2008, "A backup restoration algorithm of service composition in MANETs," Communication Technology ICCT 11th IEEE International Conference, pp. 588-591.
[11] M. Armbrust et al, “Above the clouds: A berkeley view of cloud computing,” http://www.eecs.berkeley.edu/Pubs/TechRpts/2009//EECS-2009-28.pdf.
[12] F.BKashani, C.Chen,C.Shahabi.WSPDS, 2004, “Web Services Peer to Peer Discovery Service ,” ICOMP.
[13] P.Demeester et al., 1999, “Resilience in Multilayer Networks,” IEEE Communications Magazine, Vol. 37, No. 8, p.70-76.
[14] S. Zhang, X. Chen, and X. Huo, 2010, “Cloud Computing Research and Development Trend,” IEEE Second International Conference on Future Networks, pp. 93-97.
[15] T. M. Coughlin and S. L. Linfoot, 2010, “A Novel Taxonomy for Consumer Metadata,” IEEE ICCE Conference.
[16] K. Keahey, M. Tsugawa, A. Matsunaga, J. Fortes, 2009, “Sky Computing”, IEEE Journal of Internet Computing, vol. 13, pp. 43-51.
[17] M. D. Assuncao, A.Costanzo and R. Buyya, 2009, “Evaluating the Cost- Benefit of Using Cloud Computing to Extend the Capacity of Clusters,” Proceedings of the 18th International Symposium on High Performance Distributed Computing (HPDC 2009), Germany.
[18] Wayne A. Jansen, 2011, “Cloud Hooks: Security and Privacy Issues in Cloud Computing, 44th Hawaii International Conference on System Sciences.Hawaii.
[19] Jinpeng et al, 2009, “Managing Security of Virtual Machine Images in a Cloud Environment”, CCSW, Chicago, USA.
[20] Ms..Kruti Sharma,Prof K.R.Singh, 2012, “Online data Backup And Disaster Recovery techniques in cloud computing: A review”, IJEIT, Vol.2, Issue 5.