Придание личности вашему чатботу с использованием рекуррентных нейронных сетей
Автор: Zalando Dublin
Перевод: Оверченко Я.Ю.
Источник: Zalando Dublin. Personality for Your Chatbot with Recurrent Neural Networks
Задачи и типы чатботов
Функциональность чатботов может быть разбита на две отдельные, но зависимые задачи: понять и ответить. Понимание - это интерпретация и присвоение семантического и прагматического значения пользовательскому вводу. Ответ заключается в предоставлении наиболее подходящего ответа на основе информации, полученной на этапе понимания и на основе задач/целей чат-бота.
Для моделей, основанных на поиске, процесс ответа состоит в основном из некоторого поиска (с различной степенью сложности) из предопределенного набора ответов. Чатботы, в настоящее время используемые в производственных средах, представленные или обработанные клиентам и клиентам, наиболее вероятно будут принадлежать к этой категории.
С другой стороны, ожидается, что модели, основанные на генерации, хорошо… генерируют! Чаще всего они основаны на базовых вероятностных моделях или на машинном обучении. Они не полагаются на фиксированный набор ответов, но им все равно необходимо пройти обучение для создания нового контента. Цепи Маркова первоначально использовались для задачи генерации текста, но в последнее время рекуррентные нейронные сети (RNN) приобрели большую популярность после многих многообещающих практических примеров и демонстраций. Генеративные модели для чатботов все еще принадлежат исследовательскому сектору, или игровому полю тех, кто просто любит создавать и демонстрировать тестовые приложения своих моделей. Я считаю, что в большинстве случаев использования в бизнесе они все еще не подходят для производственной среды. Я не могу представить себе клиента, который бы не воспитывал Тэя, если бы он предложил вариант с генеративной моделью.
Модель рекуррентной нейронной сети
Рекуррентная нейронная сеть - это модель глубокого обучения, предназначенная для обработки последовательностей. Здесь внутреннее состояние отвечает за учет и должную обработку зависимости, которая существует между последовательными входами. Помимо относительной элегантности модели, невозможно не быть увлеченным ею, просто посмотрев многочисленные онлайн-демонстрации и примеры, демонстрирующие ее генеративные возможности. От почерка до генерации сценария фильма.
С учетом её свойств, эта модель очень хорошо подходит для различных задач обработки естественного языка, и именно в понимании контекста, что я и начал изучать, играя с основными понятиями, используя Theano и Tensorflow и после — переход к Keras для окончательной подготовки моделей. Keras — это библиотека нейронных сетей высокого уровня, которая может работать поверх Theano или Tensorflow, но если вы хотите учиться и играть с более базовыми механизмами RNN и моделей машинного обучения в целом, я предлагаю попробовать одну из других упомянутых библиотек, особенно если снова следовать замечательным учебникам Денни Бритса.
Для своей задачи я обучил модель к последовательности на уровне слов: я передаю в сеть список слов и ожидаю того же на выводе. Вместо того, чтобы использовать ванильный RNN, я использовал слой долгосрочной краткосрочной памяти (LSTM), который гарантирует лучший контроль над механизмом памяти сети. Окончательная архитектура включает в себя только два уровня LSTM, каждый из которых сопровождается выпадением. На данный момент я все еще полагаюсь на горячее кодирование каждого слова, часто ограничивая размер словарного запаса (<10000). Следующим шагом настоятельно рекомендуется изучить возможность использования встраивания слов.
Я тренировал модель на разных корпусах: личные разговоры, книги, песни, случайные наборы данных и субтитры к фильмам. Первоначально главной целью было создание чистого текста: начинать с нуля и генерировать произвольно длинные последовательности слов, как в статье Карпати. С моей скромной настройкой я всё же получил довольно хорошие результаты, но вы можете увидеть, что этот подход не работает при тех же предположениях генерации текста для чатботов, который в конце концов является сценарием ответа на вопрос.
Обучение чатбота
Выбор методики обучения является еще одной большой проблемой исследования обработки естественного языка, со своей собственной экосистемой сложных и компонентно-неоднородных путей. Даже если фокусироваться только на глубоком обучении, существуют разные решения с разным уровнем сложности. На данном этапе я хотел сначала поэкспериментировать с моим базовым подходом и посмотреть результаты обработки не по теме вопросов.
Я использовал Cornell Movie - Dialogs Corpus и создал обучающий набор данных, основанный на объединении двух последовательных взаимодействий, которые напоминали ситуацию вопрос-ответ. Каждая из таких пар в конечном итоге составляет предложение окончательного тренировочного набора. Во время обучения модель получает в качестве входных данных предложение, усеченное из последнего элемента, в то время как ожидаемый результат аналогичен усеченному из первого слова.
Учитывая такие условия, модель на самом деле не изучает, что является ответом и что является вопросом, но должна создать внутреннее представление, которое может согласованно генерировать текст. Это достигается либо путем создания предложения с нуля, начиная со случайного элемента, либо просто путем завершения начального предложения (потенциальный вопрос), по одному слову за раз, пока не будут выполнены предопределенные критерии (например, создается символ пунктуации). Весь вновь сгенерированный текст затем сохраняется и предоставляется в качестве ответа.
Вы можете найти дополнительные подробности и реализацию WIP в моем репозитории Github. Любая критика и комментарии приветствуются.
Архитектура
Взаимодействие с чатботом так же просто, как и отправка сообщения в Facebook Messanger, но полное решение включает в себя различные гетерогенные компоненты. На рисунке 1 изображен минимальный взгляд на текущую архитектуру.
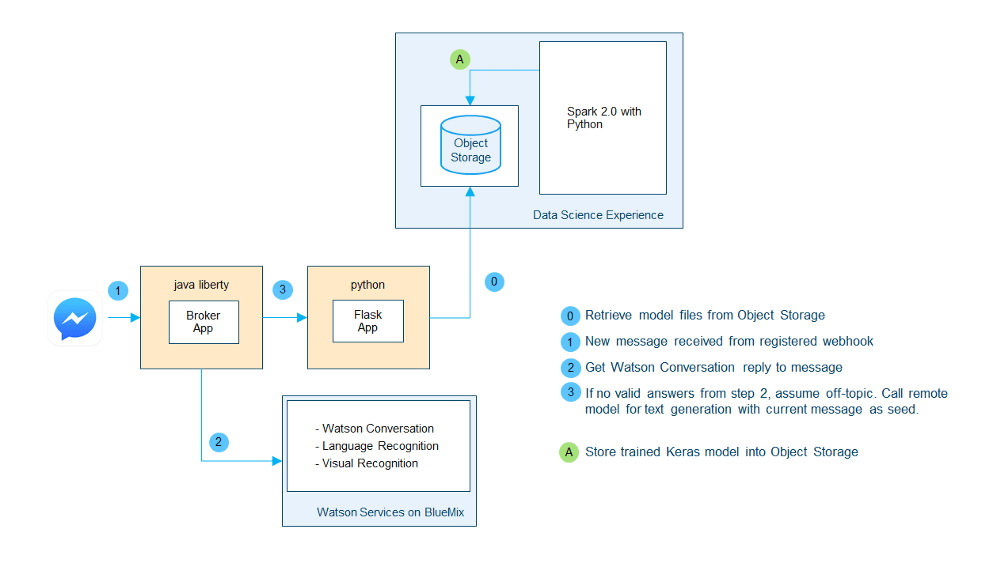
Архитектура решения
Обработка данных и обучение модели RNN проводились на экземпляре Spark, размещенном на платформе IBM Data Science. Я взаимодействовал с ним напрямую через Jupyter Notebooks. Используя систему обратных вызовов Keras, я автоматически отслеживал характеристики модели во время тренировки и, при необходимости, создавал резервные копии весов. В конце каждого обучения лучший моментальный снимок (веса модели) постоянно перемещался в хранилище объектов, связанное с экземпляром Spark, вместе с архитектурой модели Keras и дополнительными данными, относящимися к корпусу обучения (например, индексирование словарного запаса).
Вторая часть — это компонент модель услуга — базовый API RESTful Flask, который предоставляет обученные модели для генерации текста через вызовы REST. Каждая модель представляет собой отдельную конечную точку и принимает разные параметры для использования в задаче генерации. Примеры параметров:
- seed: начальный текст для использования в задаче генерации;
- temperature: показатель дисперсии, или сколько «свободы» вы хотите дать модели во время прогнозирования;
- sentence minimum length: минимальная длина, приемлемая для сгенерированного предложения.
Внутренне это приложение отвечает за извлечение и загрузку в память моделей из удаленного хранилища объектов, так что они готовы генерировать текст при вызове соответствующих конечных точек.
Последний компонент — это веб приложение Java Liberty, которое выступает в качестве посредника для платформы Facebook Messanger. Он отвечает за обработку веб-хитов Facebook и подписок, хранение истории чатов пользователей и реализацию логики ответов на задачи. С одной стороны, он опирается на систему, описанную в моей предыдущей статье, с использованием сервисов IBM Watson, таких как распознавание и разговор языка, с другой, когда определенные требования выполняются или когда не был предоставлен действительный ответ, может полагаться на бит генерации текста, и вызов Flask API в наиболее удобной конечной точке.
Как приложение Java, так и приложение Python размещены в Bluemix, а в отношении первого я сейчас работаю над освещением дополнительных платформ обмена сообщениями, таких как Slack, Whatsapp и Telegram.
Демонстрация чатбота
Вы можете взаимодействовать с чатботом просто через Facebook Messanger, но для того, чтобы сделать вашего бота публичным (доступным для всех, кто попадет на его страницу), требуется некоторая работа, демонстрационные видеоролики и последующее официальное одобрение Facebook. На данный момент я должен вручную добавить людей в качестве тестеров моего приложения, чтобы позволить им использовать его, поэтому, если вам интересно, просто напишите мне.
Тем не менее, я должен признать, что уже наблюдение взаимодействия нескольких нынешних тестеров было довольно интересным опытом, хорошими эмоциональными «американскими горками» развлечений, стыда, жуткости, гордости…
В работе текущей модели чатбота наблюдается смешанное поведение: ответ «Выходи за меня» основан на классификации естественного языка, а все остальные генерируются. Уже есть грамматически неправильные предложения. Иногда ответы кажутся совершенно случайными, но все же создают приятное взаимодействие, симуляцию застенчивой, растерянной и стыдной личности, возможно, немного романтичной. Учитывая обучающие данные, чатбот также выучил правильную пунктуацию, поэтому может ответить предложением, начинающимся с символа пунктуации, если предыдущий ввод не заканчивался одним из них. Он также может придумать некоторые, казалось бы, глубокие вещи, которые затем с треском провалились, особенно с учетом новых высоких ожиданий.
Я осознаю, что во всем этом нет прорыва, и результаты могут меня «мхе», но, в конце концов, очень многие люди безумно взволнованы своими «первыми словами ребенка», которые, насколько мне известно, намного ниже того уровня, который я здесь установил. Мое приличное понимание механизмов, стоящих за чатботом делает все еще более увлекательным наблюдение.