Программное средство распознавания печатного текста
Авторы:Бычкова Е.В., Шумский А.А.
Источник:Сборник материалов VIII Международной научно-технической конференции в рамках III Международного Научного форума ДНР, 2017. – С. 402.
Аннотация
Бычкова Е.В., Шумский А.А. Программное средство распознавания печатного текста. Выполнен анализ проблемы распознавания печатного текста. Проанализированы существующие популярные системы распознавания печатного текста. Приведены конкурирующие варианты реализации программного средства.
Постановка проблемы
В наш век информационных технологий и электронных подписей обычные бумажные документы ничуть не утратили своей силы. Работникам различных сфер деятельности зачастую приходится вручную набирать объемные тексты из-за отсутствия или невозможности достать электронные исходники. Для автоматизации данного процесса существуют системы распознавания печатного текста. Данные системы бывают в виде сервисов и приложений под разные платформы (Windows, Android и другие).
На текущий момент большинство подобных приложений и сервисов платное, с закрытым исходным кодом и имеет ограничения по объему обрабатываемых данных. В связи с этим создание бесплатной системы для распознавания печатного текста с открытым исходным кодом является крайне востребованной задачей.
Цель статьи
Исследование существующих проблем и способов распознавания печатного текста, анализ разрабатываемого программного средства и сравнение с конкурирующими продуктами на рынке программного обеспечения.
Метод распознавания текста
В теории распознавания образов [1] можно выделить два основных направления:
- изучение способностей к распознаванию, которыми обладают живые существа, объяснение и моделирование их;
- развитие теории и методов построения устройств, предназначенных для решения отдельных задач в прикладных целях.
Распознавание текста принадлежит ко второму направлению. В качестве методов распознавания текста выделяют:
- сравнение с шаблоном;
- распознавание по критериям;
- распознавание при помощи самообучающихся алгоритмов.
Последний из методов подразумевает использование нейронных сетей, что позволяет значительно повысить качество распознавания текста.
Работу программного средства распознавания печатного текста можно поделить на несколько этапов (см. рис. 1).
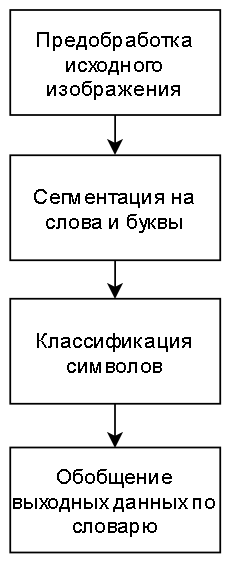
Рисунок 1 – Этапы работы программного средства распознавания печатного текста
Входными данными являются фотографии исходного текста. Для повышения точности распознавания необходимо провести обработку изображения, что позволяет избавиться от шумов. Обычно применяется медианный фильтр с последующим восстановлением изображения, а затем монохромный. Далее обработанное изображение поступает на модуль сегментации, где выделяются сгустки пикселей в потенциальные буквы, а сами сгустки объединяются в потенциальные слова. Данные буквы классифицируются с помощью нейронной сети, а затем идет поиск и сравнение итоговых слов со словарем.
Описание работы фильтров предобработки
Монохромный фильтр преобразует исходное цветное изображение в новое, содержащее свет одного цвета (длины волны), воспринимаемый как один оттенок.
Монохромный фильтр необходимо реализовать с применением метода препарирования [2], в котором граница перехода высчитывается путем нахождения среднего значения яркости всех пикселей изображения (см. рис. 2). Такой подход позволяет при сегментации выделить буквы даже при плохом освещении на цветной бумаге.
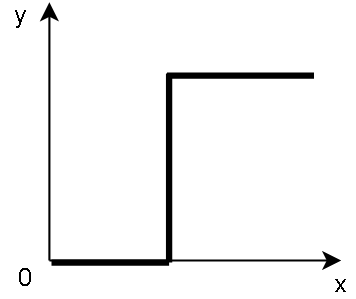
Рисунок 2 – Функция препарирования в монохромном фильтре
Медианный фильтр [3] позволяет избавиться от импульсного шума. Значения отсчётов внутри окна фильтра сортируются в порядке возрастания или убывания. Значение, находящееся в середине упорядоченного списка, поступает на выход фильтра. В случае чётного числа отсчётов в окне выходное значение фильтра равно среднему значению двух отсчётов в середине упорядоченного списка. Окно перемещается вдоль фильтруемого сигнала и вычисления повторяются. Последующее восстановление не позволяет тексту размыться, поскольку фильтр затрагивает лишь сильно измененные пиксели.
Характеристики существующих мобильных приложений по распознаванию печатного текста
Сравнение наиболее распространенных мобильных программных средств по распознаванию печатного теста с фотографий представлено в табл. 1.
Таблица 1 – Описание распространенных графических форматов
| название |
достоинства |
недостатки |
| finescanner |
1. высокая точность распознавания текста. 2. поддержка различных расширений. 3. множество фильтров и настроек сканирования. 4. мультиязычность. |
1. функция распознавания текста платная. 2. распознавание длится дольше, чем у конкурентов. |
| image to text |
приложение бесплатное. |
1. низкая точность распознавания. 2. отсутствие настроек. 3. поддержка только одного языка. 4. низкая стабильность. |
| pdf scaner + ocr |
1. приложение бесплатное. 2. поддерживает большое количество языков. 3. большое количество настроек. |
1. низкая точность распознавания. 2. низкая скорость распознавания. 3. устаревший дизайн. |
Описание разрабатываемой системы распознавания печатного текста
Данная система предназначена для использования на мобильных устройствах. Главная задача системы - автоматическое распознавание печатного текста и сохранение его в файл для последующей обработки пользователем.
Графический интерфейс приложения будет предоставлять следующие возможности:
- загрузка изображения для распознавания из галереи устройства;
- загрузка изображения для распознавания напрямую с камеры устройства;
- сохранения результирующего текста в файл;
- загрузка результирующего файла в облако Google Drive;
- исправление ошибок распознавания программы посредством ее обучения.
Выводы
Проведено исследование существующих проблем и способов распознавания печатного текста. Осуществлен анализ разрабатываемого программного средства и сравнение с конкурирующими продуктами на рынке программного обеспечения.
Список использованной литературы
- Теория распознавания образов [электронный ресурс] // Википедия – свободная энциклопедия: [сайт]. [2017]. URL: http://www.wikipedia.org/wiki/Графические_форматы
- Препарирование изображения [электронный ресурс] // Научная библиотека: [сайт]. [2009]. URL: http://www.kletsel.com/articles/formats.html
- Медианный фильтр [электронный ресурс] // Википедия – свободная энциклопедия: [сайт]. [2017]. URL: http://www.wikipedia.org/wiki/Графические_форматы
- Препарирование изображения [электронный ресурс] // Научная библиотека: [сайт]. [2009]. URL: http://www.kletsel.com/articles/formats.html