Аннотация
Сторожук Н.О., Коломойцева И.А. - Анализ алгоритмов лексической и морфологической обработки текстов c целью определения жанровой принадлежности В работе представлен обзор существующих алгоритмов лексического анализа и стемминга, используемых в поисковых системах и анализаторах текстов. Сделаны выводы о возможности использования комбинации определенных методов в системе, определяющей жанр исследуемого текста.
Общая постановка проблемы
Основной проблемой анализа текстов является большое количество слов в документе и его неоднородность. Автоматизированный анализ текста в исходном виде – трудоёмкий и длительный процесс, учитывая то, что не все слова несут значимую для пользователя информацию. Кроме того, в силу гибкости естественных языков формально различные слова (синонимы и т.п.) на самом деле означают одинаковые понятия, большое число словоформ одного и того же слова усложняют поиск и систематизацию информации. Следовательно, удаление неинформативных слов, а также приведение слов к нормальной форме значительно сокращают время анализа текстов. Устранение описанных проблем для заданной предметной области выполняется на этапе предварительной обработки текста, который описан в данной статье.
Целью данной работы является формирование правил лексического анализа для планируемого программного проекта, анализ различных подходов морфологического анализа текстов, в особенности алгоритмов стемминга для текстов на русском языке.
Введение
Автоматическая обработка текста – это преобразование текста на искусственном или естественном языке с помощью ЭВМ. В настоящее время элементы обработки текста применяются повсеместно: переводчики, текстовые редакторы, программы для антиплагиата и автореферирования, анализаторы новостей, оптимизаторы программного кода и т.д. Следовательно, задачи эффективной автоматизированной обработки текстов остаются актуальными, стабильное увеличение объёма информации требует постоянного совершенствования алгоритмов и подходов.
Для определения жанровой принадлежности текста в планируемой программной системе будет использован следующий базовый алгоритм:
- лексический анализ (разбиение на токены / сегментация);
- морфологический анализ (стемминг);
- статистический анализ;
- алгоритмы для получения целевой информации.
В данной работе будут рассмотрены первые два этапа анализа текста, как основополагающие методы, используемые для автоматизированного анализа информации независимо от конкретной цели исследования. В процессе первых двух этапов следует применить элементы статистического анализа для дальнейшей обработки для получения более точного результата. Алгоритмы для получения целевой информации носят специализированный характер, в зависимости от жанра, объёма исходного материала и преследуемых исследователем целей.
Лексический анализ
Программный модуль, отвечающий за лексический анализ, запускается в первую очередь при автоматической обработке текста и готовит данные для последующих этапов анализа. Входными данными для модуля сегментации является последовательность знаков (букв, символов, пробелов, цифр, и других знаков, предусмотренных кодировкой). Следует отметить, что входной текст должен быть грамотно изложенным на русском языке и представлен в файле формата, доступного для парсинга.
Основная задача лексического анализа - распознать лексические единицы текста. Базовым алгоритмом является лексическая декомпозиция, которая предусматривает разбивку текста на токены. В данном контексте токенами могут быть это слова, словоформы, морфемы, словосочетания и знаки препинания, даты, номера телефонов и пр.
Для проведения такой сегментации, повышения её однородности и качества, были разработаны базовые правила, которые должны быть предусмотрены алгоритмом. В процессе программной реализации и дальнейшего анализа полученных токенов правила будут существенно дополнены и детализованы.
- Знаки препинания, состоящие из одного знака, выделяются в отдельный токен.
- Несколько идущих подряд одинаковых знаков препинания (например, троеточие), группируются в один токен. Исключения составляют скобки и кавычки.
- Числа, включающие точку или запятую в качестве разделителя целой и дробной частей, обыкновенные дроби, числа со степенью, интернет-адреса (https://mail.ru/), адреса электронной почты (mail@domain.com), номера телефонов (0710000000, 071-000-00-00), химические формулы (СО) считаются целыми токенами.
- Имена собственные, содержащие знаки препинания («Санкт-Петербург», «Салтыков-Щедрин», «Yahoo!», «Яндекс. Деньги»), считаются целыми токенами. Эти имена могут быть написаны разными способами и могут включать любые знаки препинания и символы.
- Аббревиатуры считаются одним токеном. При необходимости, на последующих этапах анализа может быть подобрана расшифровка.
- Обозначения единиц измерения («км», «$”, «%», …), а также «+» и «-» перед числами отделяются от числа и становятся отдельными токенами, даже если между ними и числом нет пробелов.
- Частицы, написанные через дефис с другим словом («они-то», «подойди-ка», «он-таки», «точно-с», «он-де» ...) не отделяются.
- Повторяющиеся слова, написанные через дефис («ха-ха-ха», «много- много», «синий-синий») разделяются аналогично предыдущему случаю, чтобы данное явление рассматривалось при последующем синтаксическом анализе.
- Составные слова с изменяемой («кресло-кровать», «ракета-носитель») и неизменяемой первой частью («офис-менеджер», «веб-сайт») разделяются на 3 разных токена.
- Сокращения, включающие в себя числа разделяются на отдельные токены (3-й, 24-летний).
- Основные сокращения не разбиваются («т.е.», « ул.» и пр.).
- Произвольные авторские комбинации («Тот-кого-нельзя-называть», «S.T.A.L.K.E.R.») не отделяются.
- Фрагменты обозначения времени («12:25») и даты («31.12.2011») не отделяются друг от друга.
- Слова иностранных языков («donne-moi») отделяются в токены как обычные слова, однако в дальнейшем стемминге не участвуют.
- Инициалы, сокращения перед личными именами рассматриваются как один токен.
- Устойчивые словосочетания и идиомы должны быть собраны в отдельном файле и распознаваться как один токен. Например, «потому что» целесообразно рассматривать как один токен, поскольку это союзное словосочетание выражает одно значение.
Лексическая сегментация имеет фундаментальное значение для проведения автоматического анализа текста, поскольку лежит в основе большинства других алгоритмов. Следующим шагом обработки исходного произведения является стемминг, на вход которого подается готовый список токенов.
Стемминг
Стемминг — это процесс нахождения основы слова для заданного исходного слова. Основа слова необязательно совпадает с морфологическим корнем слова. Стемминг применяется в поисковых системах для расширения поискового запроса, ускорения времени обработки запроса, является частью процесса нормализации текстаx [1].
Стеммеры принято классифицировать на алгоритмические и словарные. Словарные стеммеры функционируют на основе словарей основ слов. В процессе морфологического анализа такой стеммер выполняет сопоставление основ слов во входном тексте и в соответствующем словаре, а анализ начинается с начала слова. Используя словарный стеммер, повышается точность поиска, однако увеличивается время работы алгоритма и объём памяти, занимаемой словарями основ.
Алгоритмические стеммеры работают на основе файлов данных, которые содержат списки аффиксов и флексий. В процессе анализа программа выполняет сравнение суффиксов и окончаний слов входного текста со списком из файла, анализ происходит посимвольно, начиная с конца слова. Такие стеммеры обеспечивают большую полноту поиска, хотя и допускают допуская больше ошибок, которые проявляются в недостаточном или избыточном стеммировании. Избыточное стеммирование проявляется, если по одной основе отождествляются слова с разной семантикой; при недостаточном стеммировании по одной основе не отождествляются слова с одинаковой семантикой.
Например, ланкастерский стеммер для английского языка выделяет bet как основу better, a childr - как основу children. В первом случае имеет место избыточное стеммирование, поскольку по основе bet прилагательное better отождествляется с глаголом bet и его производными (bets, betting), значение которых не имеет ничего общего со значением прилагательного. Во втором случае имеет место недостаточное стеммирование, так как по основе childr нельзя отождествить формы множественного (children) и единственного числа Сchild) одной лексемы [2].
Несмотря на указанные недостатки, на практике более распространены алгоритмические стеммеры. Это можно объяснить тем, что количество суффиксов и флексий в каждом языке достаточно ограничено и их изменения на уровне морфологической структуры происходят намного медленнее, чем на лексическом уровне. Следовательно, словари основ необходимо обновлять чаще, чем словари аффиксов. Применение словарных стеммеров эффективно в системах, анализирующих достаточно узкие предметные области.
Существуют различные виды реализации идеи стемминга в алгоритмах, которые различаются по производительности, точности, а также путями преодоления конкретных проблем стемминга. На рисунке 1 представлена классификация существующих алгоримов стемминга.
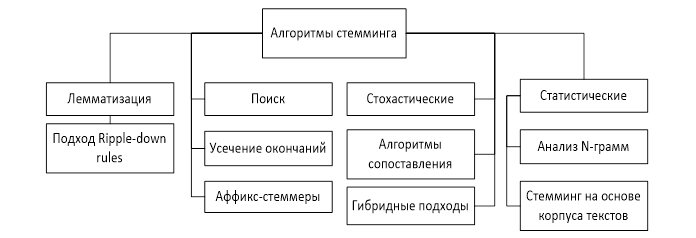
Лемматизация – это получение начальной формы слова – леммы [3]. Классические алгоритмы лемматизации, кроме изменения формы слова, предполагают его дополнительных анализ – определение части речи или других показателей, в зависимости от конкретной задачи.
Алгоритм поиска предполагает поиск флективной формы в таблице. Преимущество этого подхода – простота и скорость, однако все флективные формы должны быть явно перечислены в таблице: новые или незнакомые слова не будут найдены, даже если они являются правильными.
Алгоритмы усечения окончаний не используют справочную таблицу, которая состоит из флективных форм и отношений корня и формы. Такие алгоритмы гораздо эффективнее, однако для разработки такого алгоритма программисту необходимо хорошо разбираться в лингвистике и правильно установить правила усечения. Одним из улучшений алгоритма является подстановка суффиксов и окончаний, однако при некорректной постановке правил такой алгоритм может приобрести рекурсивный характер. [4]
Аффикс – стеммеры отсекают префиксы и суффиксы для получения нормальной формы слова. Данному подходу может следовать алгоритм усечения окончаний, который обрабатывает не только аффиксы, но ещё и окончания [5].
Стохастические алгоритмы связаны с вероятностным определением корневой формы слова. Для таких алгоритмов строится вероятностная модель и необходимо обучение с помощью таблицы соответствия корневых и флективных форм. Стемминг выполняется посредством ввода измененных форм и генерацией корневой формы в соответствии с внутренним набором правил модели. Решения, связанные с применением наиболее соответствующего правила, последовательности правил или выбором основы слова, применяются на основании того, что результирующее верное слово будет иметь самую высокую вероятность.
Алгоритмы сопоставления используют базу данных основ слов. С целью выявления правильной основы слова, алгоритм сопоставляет слово с основами из базы, применяя различные ограничения: например, длину искомой основы [6].
Некоторые алгоритмы стемминга используют анализ N-грамм, для того чтобы выбрать подходящую основу для слова. При использовании этого подхода для моделирования языка предполагается, что появление каждого слова зависит только от предыдущих слов [7].
Основная идея стемминга на основе корпуса текстов состоит в создании классов эквивалентности для слов классических стеммеров, а затем «разбить» некоторые слова, объединенные на основе их встречаемости в корпусе [8]. Применение такого подхода помогает предотвратить конфликтные ситуации алгоритма Портера, например, как «policy/police», так как шанс встретить данные слова вместе является довольно низким.
Комбинирование описанных подходов формирует алгоритм, который относится к гибридным подходам.
Стеммеры русского языка
В русском языке преобладает словоформирование на основе аффиксов, сочетающих сразу несколько грамматических значений. Например, добрый — окончание «ый» указывает одновременно на единственное число, мужской род и именительный падеж, поэтому данный язык способствует использованию алгоритмов стемминга. Однако, в силу сложной морфологической изменяемости слов для минимизации ошибок следует использовать дополнительные средства [9], например, лемматизацию. Ниже рассмотрены наиболее популярные реализации стеммеров, основывающиеся на различных принципах и допускающие обработку несуществующих слов для русского языка.
Основная идея стеммера Портера заключается в том, что существует ограниченное количество словообразующих суффиксов, и стемминг слова происходит без использования каких-либо баз основ: только множество существующих суффиксов и правила, заданные вручную. Алгоритм состоит из пяти шагов, на каждом из которых отсекается словообразующий суффикс и оставшаяся часть проверяется на соответствие правилам [10]. Например, для русских слов основа должна содержать не менее одной гласной. Если полученное слово удовлетворяет правилам, происходит переход на следующий шаг, иначе — алгоритм выбирает другой суффикс для отсечения. На первом шаге отсекается максимальный формообразующий суффикс, на втором — буква «и», на третьем — словообразующий суффикс, на четвертом — суффиксы превосходных форм, «ь» и одна из двух «н». Недостатком является то, что часто обрезается больше необходимого, что затрудняет получение правильной основы слова. Например «кровать-крова» при этом реально неизменяемая часть — «кроват», но стеммер выбирает для удаления наиболее длинную морфему [11].
Алгоритм Stemka основан на вероятностной модели: слова из обучающего текста разбираются анализатором на пары «последние две буквы основы» + «суффикс». При этом, если такая пара уже есть в модели – её вес увеличивается. Полученный массив данных ранжируется по убыванию веса и маловероятные модели отсекаются. Результат — набор потенциальных окончаний с условиями на предшествующие символы — инвертируется для удобства сканирования словоформ «справа налево» и представляется в виде таблицы переходов конечного автомата [12].
Алгоритм MyStem является собственностью компании Яндекс. На первом шаге при помощи дерева суффиксов во входном слове определяются возможные границы между основой и суффиксом, после чего для каждой потенциальной основы начиная с самой длинной бинарным поиском по дереву основ проверяется её наличие в словаре либо нахождение наиболее близких к ней основ мерой близости является длина общего «хвоста». Если слово словарное — алгоритм заканчивает работу, иначе — переходит к следующему разбиению [13].
Выводы
В статье представлен обзор существующих подходов и алгоритмов, применяемых для парсинга текста для удобства его последующего анализа. Для разработки собственной системы будет использован лексический анализ, согласно перечисленным правилам и усовершенствованный алгоритм Портера для поиска основ слова.
Список использованной литературы
- Математические модели текста [Электронный ресурс] // Математические модели текста – Режим доступа: http://lab314.brsu.by/kmp-lite/kmp2/JOB/CModel/BoW-Q.htm
- Яцко, В.А., Алгоритмы и программы автоматической обработки текста // Вестник иркутского государственного лингвистического университета: Том 1, номер 17. – Иркутск: Евразийский лингвистический институт в г. Иркутске, 2012. – 150-160 с.
- Лемматизатор в грамматическом словаре. [Электронный ресурс] // Лемматизатор в грамматическом словаре. – Режим доступа: http://www.solarix.ru/for_developers/api/lemmatizator-api.shtml
- Стемминг. [Электронный ресурс] // intellect.ml – Режим доступа: https://intellect.ml/stemming-stemmer-portera-6235
- Батура, Т.В. Математическая лингвистика и автоматическая обработка текстов на естественном языке / Т. В. Батура ; Новосиб. гос. ун-т. – Новосибирск : РИЦ НГУ, 2016. – 166 с.
- Алгоритмы интеллектуальной обработки больших объемов данных [Электронный ресурс] // ИНТУИТ – Режим доступа: http://www.intuit.ru/studies/courses/3498/740/info
- Гудков В.Ю, Гудкова Е.Ф. N-граммы в лингвистике / Е. Ф. Гудкова, В.Ю. Гудков; Вестник Челябинского государственного университета, вып.57, 2011. – 67-71 с.
- К задаче создания корпусов русского языка. [Электронный ресурс] // К задаче создания корпусов русского языка – Режим доступа: https://www.mccme.ru/ling/mitrius/article.
- Федотов, Р.Г. Классификация текстовых документов. Уменьшение размерности задачи и повышение производительности [Электронный ресурс] // Nauka-rastudent.ru – Режим доступа: http://nauka-rastudent.ru/4/1310/
- Стеммер Портера для русского языка. [Электронный ресурс] // Medium – Режим доступа: https://medium.com/@eigenein/
- Стеммер Портера для русского языка. [Электронный ресурс] // О программировании, алгоритмах и не только – Режим доступа: http://www.algorithmist.ru/2010/12/porter-stemmer-russian.html
- Стемминг текстов на естественном языке. [Электронный ресурс] // L-Tips – Режим доступа: http://r.psylab.info/blog/2015/05/26/text-stemming/
- Segalovich I., A fast morphological algorithm with unknown word guessing induced by a dictionary for a web search engine [Электронный ресурс] // Yandex-Team – Режим доступа: http://cache-mskdataline03.cdn.yandex.net/download.yandex.ru/company/iseg-las-vegas.pdf