Аннотация
Солтон Г. и Бакли К. Методики, основанные на взвешивании термов в автоматическом поиске текста Экспериментальные данные, накопленные за последние 20 лет, показывают, что системы индексирования текста, основанные на назначении правильно взвешенных отдельных терминов, дают результаты поиска, которые превосходят результаты, полученные с помощью других более сложных текстовых представлений. Эти результаты в решающей степени зависят от выбора эффективных весовых систем. В этой статье обобщаются данные, полученные при автоматическом взвешивании терминов, и представлены базовые модели с одним индексом, с помощью которых можно сравнивать другие более сложные процедуры анализа контента.
1 Автоматический текстовый анализ
В конце 1950-х годов Лун [1] предположил, что автоматические поисковые системы могут быть разработаны на основе сравнения идентификаторов контента, прикрепленных как к сохраненным текстам, так и к информационным запросам пользователей. Как правило, определенные слова, извлеченные из текстов документов и запросов, будут использоваться для идентификации контента; альтернативно, представления содержимого могут быть выбраны вручную обученными индексаторами, знакомыми с объектом. Рассматриваемые области и содержание коллекций документов. В любом случае документы будут представлены терминами векторов формы

Там, где каждый tk идентифицирует термин контента, присвоенный некоторому образцу документа D. Аналогично, информационные запросы или запросы будут представлены либо в векторной форме, либо в виде булевых операторов. Таким образом, типичный запрос Q может быть сформулирован как:

or
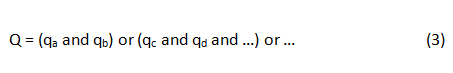
где qk еще раз представляет собой термин, присвоенный запросу Q.
Более формальное представление термина векторов уравнений (1) и (2) получается путем включения в каждый вектор всех возможных допустимых в системе условий содержания и добавления терминальных весовых присвоений для обеспечения различий между членами. Таким образом, если Wdk (или Wqk) представляет вес термина tk в документе D (или запрос Q), а t-термины во всех доступны для представления содержимого, термин векторы для документа D и запрос Q могут быть записаны как: /p>
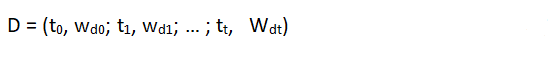
and
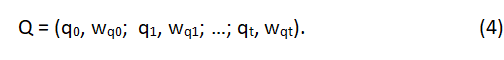
Это исследование частично поддерживалось Национальным научным фондом в рамках грантов IST 83-16166 и IRI 87-02735.
В вышеприведенной формулировке предположение состоит в том, что wdk (или wqk) равно 0, когда термин k не присваивается документу D (или запросу Q) и что wdk (или wqk) равен 1 для назначенных членов.
Учитывая векторные представления уравнения (4), значение подобия для документа запроса может быть получено путем сравнения соответствующих векторов, используя, например, обычную формулу векторного продукта:
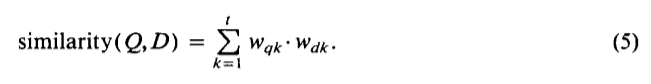
Когда весовые коэффициенты термина ограничиваются 0 и 1, как было предложено ранее, векторный продукт (5) измеряет количество терминов, которые совместно назначены на запрос Q и документ D.
На практике оказалось полезным обеспечивают большую степень дискриминации среди терминов, предназначенных для представления контента, чем это возможно только с весами 0 и 1. В частности, можно было бы назначить весовые коэффициенты в порядке убывания срочного значения, и в этом случае весам wdk (или Wqk) можно было бы непрерывно варьировать между 0 и 1, более высокие весовые присвоения около 1 использовались для наиболее важных терминов, тогда как более низкие веса около 0 будут характеризовать менее важные термины. В некоторых обстоятельствах также может быть полезно использовать нормированные весовые присвоения, где весовые коэффициенты в отдельности в какой-то степени зависят от веса других членов в одном и том же вектор. Типичный вес термина с использованием коэффициента нормировки длины вектора вычисляется следующим образом:
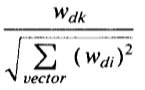
Когда нормализованная длина-(5), получается известная формула подобия косинусного вектора, которая широко использовалась с экспериментальной системой интеллектуального извлечения [2,3]:
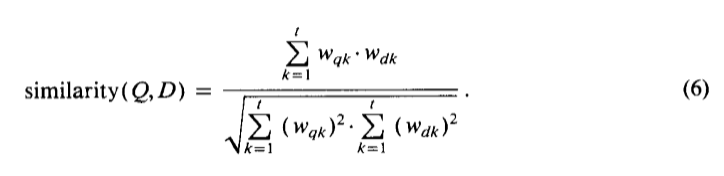
Система векторного сопоставления, выполняющая глобальные сравнения между векторами запроса и документа, обеспечивает ранжированный результат поиска в порядке убывания вычисленных сходств между Q и D. Такой ранжированный результат полезен, поскольку теперь элементы управления доступны по размеру полученного документа набор и итеративные стратегии поиска, основанные на успешных переформатирования запросов. Система, которая сначала извлекает те элементы, которые, как считается, представляет интерес для пользователей, обязательно окажет помощь в интерактивном поиске информации.
При проектировании автоматических поисковых систем необходимо решать два основных вопроса. Во-первых, какие соответствующие единицы контента должны быть включены в документы и представления запросов? Во-вторых, определяется ли термин вес, способный отличать важные термины от тех, которые менее важны для идентификации контента?
В первую очередь, выбор условий содержания, необходимо рассмотреть различные возможности. В большинстве ранних экспериментов для представления контента использовались только одни термины, часто состоящие из слов, извлеченных из текстов документов и из формулировок запросов на естественный язык [3-7]. Во многих случаях достаточно эффективный вывод результатов поиска был получен с использованием однократных представлений контента. Однако, в конечном счете, набор единых терминов не может обеспечить полную идентификацию содержимого документа. По этой причине на протяжении многих лет были предложены многие улучшения в анализе контента и процедурах индексации текста в целях создания сложных текстовых представлений. В этой связи были рассмотрены следующие возможности:
- пары букв в их естественных последовательностях в тексте – в словах (в той форме, в которой они употреблены в тексте) и пробелах между ними;
- Генерация множеств, связанных терминов на основе статистических характеристик совпадения слов в определенных контекстах в коллекции документов. Предположение, обычно сделанное, состоит в том, что слова, совпадающие с достаточной частотой в документах коллекции, фактически связаны друг с другом [8-11].
- Формирование терминов, состоящих из одного или нескольких управляющих терминов (головок фразы) вместе с соответствующими зависимыми терминами (фразовыми компонентами). Фразы часто выбираются с использованием числовых значений слов и других статистических методов, возможно дополненных синтаксическими процедурами, предназначенными для обнаружения синтаксических отношений между управляющими и зависимыми компонентами фразы [12-17].
- Использование методов группировки слов, предоставляемых тезаурусами, где классы связанных слов сгруппированы под общим заголовком; эти заголовки классов затем могут быть назначены для идентификации содержимого вместо отдельных терминов, содержащихся в классах [18-20]. Альтернативно, терминальные отношения, полезные для идентификации контента, также могут быть получены с использованием существующих машиносчитываемых диктов и лексиконов [21-24].
- Построение баз знаний и связанных с ними структур искусственного интеллекта, предназначенных для представления содержания рассматриваемой предметной области; записи из базы знаний затем используются для представления содержимого документов и запросов [25-30].
С самого начала было очевидно, что построение и идентификация сложных текстовых представлений было чрезвычайно сложным. В частности, стало ясно, что большинство автоматически полученных зависимостей терминов действительны только локально в документах, из которых первоначально были выделены группы зависимых терминов; это означает, что зависимые члены группы не могут рассчитывать на получение полезных идентификаторов контента в новых контекстах документа, отличных от тех, которые первоначально использовались [11]. Опыт, полученный в результате использования автоматических генерируемых терминов, оказался аналогичным образом обескураживающим: для некоторых коллекций улучшения эффективности извлечения до 20 ~ 0 (при поиске и преодолении поиска) можно было получить, используя фразовые идентификаторы вместо единичные термины; но для других коллекций эти же фразовые процедуры вообще не давали никаких улучшений. Более того, даже сложные программы синтаксического анализа не могли быть использованы для создания полезных сложных идентификаторов контента [16].
Что касается использования заранее подготовленных графиков в словаре и терминологических классификаций, проблема заключается в том, что нет необходимости в жизнеспособных процедурах для создания эффективных инструментов словаря, охватывающих предметные области разумного масштаба. То же самое касается создания баз знаний, предназначенных для отражения структуры областей раскрытия информации. Пока не станет известно о желаемой форме и содержании словарей и тезаурусов, следует ожидать небольшого выигрыша от этих инструментов при анализе текста и индексировании документов.
Рассматривая обширную литературу, накопленную за последние 25 лет в области оценки поисковой системы, подавляющее доказательство состоит в том, что разумное использование однотипных идентификаторов предпочтительнее включения более сложных объектов, извлеченных из самих текстов или полученных из доступных словарный запас [31-37]. При создании сложных текстовых идентификаторов возникают две основные проблемы:
- Когда строгие условия используются для построения сложных идентификаторов, типичных с использованием ограничительных частотных критериев и ограниченных контекстов совпадения для распознавания терминов, тогда мало новых идентификаторов, вероятно, станут доступными, а производительность поисковой системы с комплексными идентификаторами будет незначительно отличаться от результатов, полученных с однократным индексированием.
- С другой стороны, когда критерии построения сложных объектов ослаблены, тогда получаются некоторые хорошие идентификаторы, но также и многие маргинальные, которые не являются полезными. В целом, однократная индексация обычно будет предпочтительной.
Когда для идентификации контента используются единичные термины, должны быть введены различия между отдельными терминами на основе их предполагаемого значения в качестве дескрипторов документов. Это приводит к использованию терминальных весов, связанных с идентификаторами элементов. В следующем разделе кратко рассматриваются соображения, регулирующие формирование эффективных весовых коэффициентов.
2 Весовые спецификации термов
Основной функцией системы взвешивания терминов является повышение эффективности поиска. Эффективное извлечение зависит от двух основных факторов: один, элементы, которые могут иметь отношение к потребностям пользователя, должны быть восстановлены; два, предметы, которые могут быть посторонними, должны быть отклонены. Обычно используются две оценки для оценки способности системы получать соответствующие данные и отклонять нерелевантные элементы коллекции, известные как отзыв и точность, соответственно. Напомним, что доля соответствующих предметов, полученных, измеряется отношением количества соответствующих извлеченных предметов к общему количеству соответствующих предметов в коллекции; С другой стороны, прецедент представляет собой долю полученных предметов, которые являются релевантными, измеряемые отношением количества соответствующих извлеченных элементов к общему количеству извлеченных предметов.
В принципе, предпочтительной является система, которая производит как высокий отзыв, извлекая все, что имеет значение, так и высокую точность, отклоняя все элементы, которые являются посторонними. Функция отзыва извлечения, по-видимому, лучше всего используется с использованием широких высокочастотных терминов, которые встречаются во многих документах коллекции. Ожидается, что такие условия выдерут много документов, включая многие из соответствующих документов. Однако прецизионный коэффициент лучше всего использовать с использованием узких, весьма специфических терминов, которые способны изолировать несколько релевантных элементов от массы нерелевантных. На практике компромиссы обычно делаются с использованием терминов, которые достаточно широки, чтобы достичь разумного уровня отзыва, в то же время создавая неоправданно низкую точность.
Различные требования к отзыву и точности требуют использования составных весовых коэффициентов, которые содержат компоненты, напоминающие и повышающие точность. В связи с этим важны три основных соображения. Во-первых, термины, которые часто упоминаются в отдельных документах или выдержки из документа, кажутся полезными в качестве устройств, повышающих память. Это говорит о том, что коэффициент частоты (tf) термина используется как часть системы взвешивания по срокам, измеряющей частоту появления терминов в тексте документа или запроса. Долгосрочные весовые коэффициенты использовались в течение многих лет в автоматических средах индексирования [1-4].
Во-вторых, только термические частотные коэффициенты не могут обеспечить приемлемую производительность поиска. В частности, когда высокочастотные термины не сосредоточены в нескольких конкретных документах, но вместо этого преобладают во всей коллекции, все документы, как правило, извлекаются, что влияет на точность поиска. Следовательно, должен вводиться новый зависящий от коллекции фактор, который благоприятствует терминам, сосредоточенным в нескольких документах коллекции. Эта функция выполняет частоту известного частотного коэффициента обратной частоты (idf) (или инверсной частоты сбора). Коэффициент idf изменяется обратно пропорционально количеству документов n, которым присвоен термин в коллекции из N документов. Типичный коэффициент idf может быть задан как log N / n [38].
Терминные соображения о дискриминации указывают на то, что наилучшими условиями идентификации содержания документа являются те, которые могут отличать определенные отдельные документы от остальной коллекции. Это означает, что лучшие условия должны иметь высокочастотные частоты, но низкие общие частоты сбора. Тогда разумную меру термина важности можно получить, используя произведение частоты членов и частоты обратного документа (tf x idf) [39-41].
Термин «дискриминационная модель» подвергся критике, поскольку он не демонстрирует хорошо обоснованных теоретических свойств. Это контрастирует с вероятностной моделью поиска информации, в которой учитываются свойства релевантности документов, и получен вес теоретического обоснованного значения термина [42-44]. Значение релевантности термина, определяемое как доля соответствующих документов, в которых происходит термин, разделенный на долю нерелевантных элементов, в которых происходит этот термин, однако, не сразу вычисляется без знания свойств вхождения терминов в неотъемлемых и нерелевантных частей коллекции документов. Был предложен ряд методов оценки фактора релевантности термина при отсутствии полной информации о релевантности, и они показали, что в четко определенных условиях релевантность термина может быть уменьшена до частотного коэффициента обратного документа формы log ((N - n) / n) [45-46]. Таким образом, составная (tf x idf) система взвешивания по срокам напрямую зависит от других теоретически привлекательных моделей поиска.
Третий член - весовой коэффициент, в дополнение к частоте и частоте обратного документа, представляется полезным в системах с широким диапазоном длины вектора. Во многих ситуациях краткие документы, как правило, представлены краткосрочными векторами, тогда как для более длинных документов назначаются гораздо более долгосрочные наборы. Когда для представления документа используется большое количество терминов, вероятность совпадения совпадений между запросами и документами высока, и, следовательно, более крупные документы имеют больше шансов на получение, чем короткие. Как правило, все соответствующие документы должны рассматриваться как не менее важные для поисковых целей. Это говорит о том, что фактор нормировки включается в формулу взвешивания по срокам, чтобы уравнять длину векторов документа. Предполагая, что w представляет вес термина t, конечный вес термина может быть затем определен как:
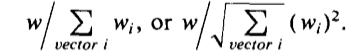
В предыдущем обсуждении систем взвешивания по срокам как документы, так и запросы считались представленными наборами или векторами взвешенных терминов. Системы взвешивания терминов также были применены к булевым операторам запросов, и были разработаны расширенные булевы системы, в которых булевы операторы запроса эффективно сводятся к векторной форме [47-54]. Предыдущие соображения относительно взвешивания по срокам, таким образом, в некоторой степени применимы и к обработке логических запросов.
3. Эксперименты взвешивания терминов
В оставшейся части этой заметки описывается ряд экспериментов с взвешиванием по срокам, в которых сочетания компонентов частоты, частоты сбора данных и длины для термина используются с шестью коллекциями документов различного размера, охватывающими различные предметные области. В каждом случае коллекции пользовательских запросов используются для поиска, а производительность усредняется по количеству доступных пользовательских запросов. Для каждого эксперимента средняя точность поиска вычисляется для трех разных точек отзыва, включая низкий возврат 0,25, средний возврат 0,50 и высокий возврат 0,75. Эта средняя предварительная точность поиска затем усредняется для всех доступных пользователей запросы. Кроме того, в качестве критерия оценки используется ранг весовых методов при уменьшении порядка выполнения. Экспериментально было использовано 1800 различных комбинаций терминальных весовых присвоений, из которых 287 были отличными. Таким образом, ранг 1 обозначает лучшую производительность, а худшее - 287.
В настоящих экспериментах каждая термино-весовая комбинация описывается с использованием двух троек, представляющих соответственно значение частоты, частоты сбора и коэффициентов векторной нормировки для терминов документов (первая тройка) и терминов запроса (вторая тройка). Основные весовые компоненты определены в таблице 1. Используются три разных компонента с временной частотой, включая бинарный вес (b), нормальную частоту (t) и нормированную частоту (n), лежащую между 0,5 и 1. О. Три составляющие частоты сбора представляют собой множители 1 (x), которые не учитывают частоту сбора, обычный коэффициент частоты обратного сбора (f) и вероятностную частоту инверсного сбора (p). Наконец, коэффициент нормировки длины может отсутствовать (x в качестве третьего компонента) или присутствует (c). (В упомянутом выше полном наборе 1800 различных назначений весовых весов также были опробованы дополнительные весовые компоненты, не включенные в Таблицу 1. Эти дополнительные компоненты не предоставили принципиально новых идей и преимуществ).
Таблица 1. Компоненты весов термина
Компонент частоты термина |
|
b 1.0 |
двоичный вес, равный 1 для термов, присутствующих в векторе (термальная частота игнорируется) |
t tf |
необработанная частота (количество раз, когда термин встречается в тексте документа или запроса) |
|
n
|
увеличенная нормализованная частота |
Компонент частоты коллекции |
|
x 1.0 |
никакого изменения веса; использовать компонент исходной термической составляющей (b, t или n) |
f |
умножить исходный коэффициент tf на коэффициент обратного сбора частоты (N - общее количество документов в коллекции, а n - количество документов, которым присвоен термин) |
p |
умножить tf на вероятностный коэффициент инверсной частоты сбора |
Компонент нормализации |
|
x 1.0 |
без изменений; коэффициенты использования, полученные только от частоты и частоты сбора (без нормализации) |
c |
используя косинусную нормализацию, где каждый вес члена w делится на множитель, представляющий длину вектора евклидова |
В таблице 2 приведены фактические формулы для некоторых хорошо известных систем взвешивания терминов. Совпадение на уровне координации, которое просто отражает количество совпадающих терминов, присутствующих в документах и запросах, соответственно, описывается блоком bxx ~ bxx. Аналогично, вероятностная система независимости двоичных членов, которая использует двоичные термины документа, но вероятностный вес инверсной частоты сбора для условий запроса, представлен как bxx * bpx. Типичная комплексная схема взвешивания слов, описываемая как tfc * nfx, использует нормированный вес tf x idf для терминов документа и расширенный, но ненормализованный фактор tf x idf для запросов. (Поскольку векторы запросов остаются постоянными для всех документов коллекции, нормализация запроса просто добавляет постоянный фактор ко всем измерениям сходства между запросами и документами, что оставляет окончательный рейтинг документа незатронутым.)
Таблица 2. Типичные формулы взвешивания термов
Система взвешивания |
Вес термина в документе |
Вес термина в запросе |
Лучший полностью взвешенный (tfc*nfx) |
|
|
Лучший взвешенный вероятностный (nxx*bpx) |
|
|
Классический вес (bfx * bfx) |
|
|
Двоичная вероятностная независимость (bxx*bpx) |
1 |
|
Стандартный вес tf (txc*txx) |
|
tf |
Уровень согласования (bxx*bxx) |
1 |
1 |
.png)
Шесть сборников, используемых экспериментально, характеризуются статистикой таблицы 3. Наименьшая коллекция представляет собой биомедицинскую (MED) коллекцию, состоящую из 1033 документов и 30 запросов, тогда как самая большая коллекция (INSPEC) включает 12684 документа и 84 запроса, охватывающих компьютер инженерных областях. Во всех случаях векторы запросов намного короче, чем соответствующие векторы вектора.
Таблица 3. Статистика коллекций (включает среднюю длину вектора и стандартное отклонения размера вектора)
Коллекция |
Количество в векторе (документе или запросе) |
Средняя длина вектора (число терминов) |
Стандартное отклонение размера вектора |
Средняя частота терминов в документе |
Процент терминов в векторе с частотой 1 |
CACM Документы Запросы |
3.204 64 |
24.52 10.80 |
21.21 6.43 |
1.35 1.15 |
80.93 88.68 |
CISI Документы Запросы |
1.460 112 |
46.55 28.29 |
19.38 19.39 |
1.37 1.38 |
80.27 78.36 |
CRAN Документы Запросы |
1.398 225 |
53.13 9.17 |
22.53 3.19 |
1.58 1.04 |
69.50 95.69 |
INSPEC Документы Запросы |
12.684 84 |
32.50 15.63 |
14.27 8.66 |
1.78 1.24 |
61.06 83.78 |
MED Документы Запросы |
1.033 30 |
51.60 10.10 |
22.78 6.03 |
1.54 1.12 |
72.70 90.76 |
NPL Документы Запросы |
11.429 100 |
19.96 7.16 |
10.84 2.36 |
1.21 1.00 |
84.03 100.00 |
Коллекция NPL (Национальная физическая лаборатория) из 11429 документов и 100 стран была доступна только в индексированной форме (т. Е. В виде векторов документов и запросов), а не в оригинальной форме на естественном языке. Это может объяснить его несколько своеобразный макияж. И документ, и вектор запроса намного меньше в коллекции NPL, чем в других коллекциях, а изменение длины запроса (2.36 для среднего числа 7.16 запросов) очень мало. Кроме того, термин «частота» особенно мал для коллекции NPL: каждый термин запроса появляется точно один раз в запросе, а средняя частота терминов в документах составляет всего 1,21. В этих условиях термин «операции взвешивания по частоте и операции нормализации длины» не может выполнять свою предполагаемую функцию. Можно предположить, что термины индекса NPL тщательно выбраны и могут фактически представлять собой специально контролируемые термины, а не свободно выбранные записи на естественном языке.
Таблица 4. Результаты работы по восьми методам взвешивания терминов, усредненных по 5 коллекциям
Методы взвешивания терминов |
Ранг метода и средняя точность |
CASM 3204 док. 64 запр. |
CISI 1460 док. 112 запр. |
CRAN 1397 док. 225 запр. |
INSPEC 12684 док. 84 запр. |
MED 1033 док. 30 запр. |
Среднее для 5 коллекций |
1. Лучший полностью взвешенный (tfc*nfx) |
Rank P |
1 0.360 |
14 0.2189 |
19 0.8341 |
3 0.2626 |
19 0.5628 |
11.2 |
2. Взвешенный с обратной частотой f, не используемой для документов (txc*nfx) |
Rank P |
25 0.3252 |
14 0.2189 |
7 0.3950 |
4 0.2626 |
32 0.5542 |
16.4 |
3. Классический tf*idf без нормализации (tfx*tfx) |
Rank P |
29 0.3248 |
22 0.2166 |
219 0.2991 |
45 0.2365 |
132 0.5177 |
84.4 |
4. Лучший взвешенный вероятностный (nxx*bpx) |
Rank P |
55 0.3090 |
208 0.1441 |
11 0.3899 |
97 0.0293 |
60 0.5449 |
86.2 |
5. Классический idf без нормализации (bfx * bfx) |
Rank P |
143 0.2535 |
247 0.1410 |
183 0.3184 |
160 0.1781 |
178 0.5062 |
182 |
6. Двоичная вероятностная независимость (bxx*bpx) |
Rank P |
166 0.2376 |
262 0.1233 |
154 0.3266 |
195 0.1563 |
147 0.5116 |
159 |
7. Стандартная косинусная нормализация (оригинальная Smart) (txc*txx) |
Rank P |
178 0.2102 |
173 0.1539 |
137 0.3408 |
187 0.1620 |
246 0.4641 |
184 |
8. Бинарные векторы уровня согласования (bxx*bxx) |
Rank P |
196 0.1848 |
284 0.1033 |
280 0.2414 |
258 0.0944 |
281 0.4132 |
260 |
Таблица 5: Результаты эффективности сбора NPL (11429 точек, 100 запросов)
Оценка |
Лучший полностью взвешенный (tfc*nfx) |
Взвешенный с обратной частотой f, не используемой для документов (txc*nfx) |
Классический tf*idf без нормализации (tfx*tfx) |
Лучший взвешенный вероятностный (nxx*bpx) |
Классический idf без нормализации (bfx * bfx) |
Двоичная вероятностная независимость (bxx*bpx) |
Стандартная косинусная нормализация (оригинальная Smart) (txc*txx) |
Бинарные векторы уровня согласования (bxx*bxx) |
Ранг |
116 |
62 |
149 |
2 |
2 |
8 |
172 |
83 |
Средняя точность |
0.1933 |
0.2170 |
0.1846 |
0.2752 |
0.2406 |
0.2596 |
0.1750 |
Типичный результат оценки показан в таблицах 4 и 5. С несколькими незначительными исключениями результаты для пяти сборников таблицы 4 являются однородными в том смысле, что наилучшие результаты получаются с помощью тех же систем взвешивания по срокам для всех коллекций и то же самое относится и к самым бедным результатам. Однако результаты Таблицы 4 существенно отличаются от результатов, полученных для коллекции NPL в Таблице 5. С учетом первых результатов таблицы 4 очевидны следующие выводы:
- Методы 1 и 2 дают сопоставимые характеристики для всех коллекций, нормализация длины важна для документов, а расширенный вес запроса эффективен для запросов. Эти методы рекомендуются для обычных текстовых текстов и текстовых рефератов.
- Метод 3 не включает операцию нормализации длины вектора, а также расширенные веса запросов. Этот ненормализованный (tf x idf) метод взвешивания является плохим для коллекций, таких как CRAN и MED, где используются очень короткие векторы запросов с небольшим отклонением длины запроса. В таких случаях важны повышенные веса запросов (n фактор).
- Метод 4 представляет собой наилучшую из вероятностных систем взвешивания. Этот метод менее эффективен, чем расширенные схемы взвешивания методов 1 и 2. Это особенно не подходит для таких коллекций, как CISI и INSPEC, где используются длинные векторы запросов, а термин «дискриминация по срокам запроса» имеет важное значение.
- Методы 5-7 представляют собой, соответственно, классическое взвешивание частоты обратного документа, вероятностную систему бинарной термической независимости и классическое взвешивание частоты термина. Как видно, эти методы обычно уступают всем коллекциям.
- Координация уровня согласования двоичных векторов представляет собой одну из наихудших возможных стратегий поиска.
Результаты таблицы 5 для коллекции НПЛ существенно отличаются от результатов табл. 4. Здесь предпочтительными являются вероятностные схемы, использующие бинарные запросы и ненормализованные векторы документов. Это напрямую связано с особым характером запросов и документов для этой коллекции: очень короткие запросы с небольшим отклонением длины требуют полностью взвешенных терминов запроса (b = l), и следует избегать нормальных эффективных весов частоты, поскольку многие важные тогда термины будут понижены в векторах коротких документов. Поэтому предпочтительным является вес расширенного члена (n factor) или полный вес (b = 1). Результаты поиска, полученные для НПЛ, использовались ранее, чтобы претендовать на превосходство для вероятностной весовой системы [55]. Результаты таблиц 4 и 5 не подтверждают этого утверждения для обычных документов и запросов на естественном языке.
4 Рекомендации
Из экспериментальных данных, представленных в этом исследовании, можно сделать следующие выводы:
Векторы запросов:
- Частотная составляющая термина
- Для коротких векторов запросов каждый термин важен; Таким образом, предпочтительны расширенные весовые коэффициенты запроса: первый компонент n.
- Длинные векторы запросов требуют большей дискриминации среди условий запроса на основе частот возникновения термина: первый компонент t.
- Частотно-частотный коэффициент можно игнорировать, когда все члены запроса имеют частоты, равные 1.
- Частотная составляющая коллекции
- Частотный коэффициент обратной частоты f очень похож на вероятностный коэффициент неопределенности термина p: лучшие методы используют f.
- Компонент нормализации
- Нормализация запросов не влияет на ранжирование документа запроса для общей производительности; используйте x.
Векторы документов:
- Частотная составляющая термина
- Для технической лексики и значимых терминов (коллекции CRAN, MED) используйте расширенные весовые коэффициенты: первый компонент n.
- Для более разнообразного словарного запаса выделяйте термины обычными частотными весами: первый компонент t.
- Для коротких векторов документов, возможно, основанных на контролируемой лексике, используйте полностью взвешенные термины: первый компонент b = 1.
- Частотная составляющая коллекции
- Обратный частотно-частотный коэффициент f подобен вероятностному весу термина p: обычно используется f.
- Для динамических коллекций со многими изменениями в составе коллекции документов фактор f требует обновления; в этом случае игнорируйте второй компонент: используйте x.
- Компонент нормализации
- Когда отклонение в длинах векторов велико, как обычно в системах индексирования текста, используйте коэффициент нормировки длины c.
- Для коротких векторов вектора однородной длины коэффициент нормировки можно пренебречь; в этом случае используйте x.
Следующие унифицированные системы взвешивания следует использовать в качестве стандарта для сравнения с усовершенствованными системами анализа текста с использованием тезаурусов и других инструментов знаний для создания сложных многотомных идентификаторов контента:
Наилучший вес документа tfc, nfc (или tpc, npc)
Наилучший вес запроса nfx, tfx, bfx (или npx, tpx, bpx)
Список использованной литературы
- Luhn, H.P. A statistical approach to the mechanized encoding and searching of literary information. IBM Journal of Research and Development 1:4; 309-317; October 1957.
- Salton, G., ed. The Smart Retrieval System-Experiments in Automatic Document Retrieval. Englewood Cliffs, NJ: Prentice Hall Inc.; 1971.
- Salton, G., McGill, M.J. Introduction to Modern Information Retrieval. New York: McGraw-Hill Book Co.; 1983.
- van Rijsbergen, C.J. Information Retrieval, 2nd ed. London: Butterworths; 1979.
- Luhn, H.P. A new method of recording and searching information. American Documentation 4:l; 14-16; 1955.
- Taube, M.; Wachtel, IS. The logical structure of coordinate indexing. American Documentation 3:4; 213-218; 1952.
- Perry, J.W. Information analysis for machine searching. American Documentation 1:3; 133-139; 1950.
- van Rijsbergen, C.J. A theoretical basis for the use of cooccurrence data in information retrieval. Journal of Documentation 33:2; 106-i 19; June 1977.
- Salton, G.; Buckley, C.; Yu, C.T. An evaluation of term dependence models in info~ation retrieval. Lecture
- Notes in Computer Science, in: Salton, G.; Schneider, H.J., eds. 146, Berlin: Springer-Verlag, 151-173; 1983.
- Yu, C.T.; Buckley, C.; Lam, K.; Salton, G. A generalized term dependence model in information retrieval. Information Technology: Research and Development 2:4; 129-154; October 1983.
- Lesk, M.E. Word-word associations in document retrieval systems. American Documentation 20:l; 27-38; January 1969.
- Klingbiel, P.H. Machine aided indexing of technical literature. Information Storage and Retrieval 9:2; 79-84; February 1973.
- Klingbiel, P.H. A technique for machine aided indexing. Information Storage and Retrieval 9:9; 477-494; September 1973. Dillon, M.; Gray, A. Fully automatic syntax-based indexing. Journal of the ASIS 342; 99-108; March 1983.
- Sparck Jones, K.; Tait, J.I. Automatic search term variant generation. Journal of Documentation 4O:l; 50-66; March 1984.
- Fagan, J.L. Experiments in automatic phrase indexing for document retrieval: A comparison of syntactic and non-syntactic methods. Doctoral thesis, Report 87-868, Department of Computer Science, Cornell Uni-versity, Ithaca, NY; September 1987.
- Smeaton, A.F. Incorporating syntactic information into a document retrieval strategy: An investigation. Proc. 1986 ACM-SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, Associ-ation for Computing Machinery, New York; 103-113;.1986.
- Sparck Jones, K. Automatic Keyword Classillcation for Information Retrieval. London: Butterworths; 1971.
- Salton, G. Experiments in automatic thesaurus construction for information retrieval. Information Processing 71, North Holland Publishing Co., Amsterdam; 115-123; 1972.
- Dattola, R.T. Experiments with fast algorithms for automatic classification. In: Salton, G., ed. The Smart Retrieval System-Experiments in Automatic Document Processing. Chapter 12, pp. 265-297. Englewood Cliffs, NJ: Prentice Hall Inc.; 1971. Walker, D.E. Knowledge resource tools for analyzing large text files. In: Nirenburg, Sergei, ed. Machine
- Translation: Theoretical and ~~ethodoIogi~1 Issues, pp. 247-261. Cambridge, England: Cambridge University Press; 1987.
- Kucera, H. Uses of on-line lexicons. Proc. First Conference of the U.W. Centre for the New Oxford English Dictionary: Information in Data, pp. 7-10. University of Waterloo; 1985.
- Amsler, R.A. Machine-readable dictionaries. In: Williams, M.E., ed. Annual Review of Information Science and Technology, Vol. 19, pp. 161-209. White Plains, NY: Knowledge Industry Publication Inc.; 1984.
- Fox, E.A. Lexical relations: Enhancing effectiveness of information retrieval systems. ACM SIGIR Forum,15:3; 5-36; 1980.
- Croft, W.B. User-specified domain knowledge for document retrievai. Proc. 1986 ACM Conference on Research and Development in Information Retrieval, pp. 201-206; Pisa, Italy. New York: Association for Computing Machinery; 1986.
- Thompson, R.H.; Croft, W.B. An expert system for document retrieval. Proc. Expert Systems in Govern-ment Symposium, pp. 448-456. Washington, DC: IEEE Computer Society Press; 1985.
- Croft, W.B. Approaches to intelligent information retrieval. Information Processing & Management 23:4; 249-254; 1987. Sparck Jones, K. Intelligent retrieval. In: Intelligent Information Retrieval: Proc. Informatics, Vol. 7; 136142; Aslib; London: 1983.
- Fox, E.A. Development of the coder system: A testbed for artificial intelligence methods in information retrieval. Information Processing & Management 23:4; 341-366; 1987.
- Salton, G. On the use of knowledge based processing in automatic text retrieval. Proc. 49th Annual Meet-ing of the ASIS, Learned Information, Medford, NJ: 277-287; 1986.
- Swanson, D.R. Searching natural language text by computer. Science 132:3434; 1099-l 104; October 1960.
- Cleverdon, C.W.; Keen, E.M. Aslib-Cranfield research project, Vol. 2, Test Results. Cranfield Institute of Technologv-. Cranfield. England; 1966.
- Cleverdon, C.W. A computer evaluation of searching by controlled languages and natural language in an exoerimental NASA database. Renort ESA l/432. European SDace Agency. Frascati, Italy; July 1977.
- Lancaster, F.W. Evaluation of the_Medlars demand search service, Nat~na~Library of Medicine, Bethesda, MD; January 1968.
- Blair. D.C.: Maron, M.E. An evaluation of retrieval effectiveness for a full-text document retrieval system. Comnmnications of the ACM 28:3; 289-299; March 1985.
- Salton, Cr. Another look at automatic text retrieval systems. Communications of the ACM, 29:7; 648-656; July 1986.
- Salton. G. Recent studies in automatic text analysis and document retrieval. Journal of the ACM 20:2; 258-278; April 1973.
- Sparck Jones, K. A statistical interpretation of term specificity and its application in retrieval Journal of Documentation 28:l; 1l-21: March 1972.
- Salton, G.; Yang, C.S. On the specification of term values in automatic indexing. Journal of Documenta-tion 29:4; 351-372; December 1973.
- Salton, G. A theory of indexing. Regional Conference Series in Applied Mathematics, No. 18, Society for Industrial and Applied Mathematics, Philadelphia, PA; 1975.
- Salton, Cl.; Yang, C.S.; Yu, C.T. A theory of term importancein automatictext analysis. Journal of the ASIS 26~1; 33-44; January-February1975.
- Bookstein, A.; Swanson, D.R. A decision theoretic foundationfor indexing. Journal of the ASIS 26:l; 45-50; January-February 1975.
- Cooper, W.S.; Maron, M.E. Foundation of probabilistic and utility theoretic indexing. Journal of the ACM 67-80; 25:l; 1978.
- Robertson,S.E.; Sparck Jones, K. Relevance weighting of search terms. Journal of the ASIS 27:3; 129-146; 1976.
- Croft, W.B.; Harper, D.J. Using probabilisticmodels of informationretrieval without relevance information. Journal of Documentation35:4; 285-295; December1975.
- Wu, H.; Salton, G. A comparison of search term weighting: Term relevance versus inverse document fre-quency. ACM SIGIR Forum 16:l; 30-39; Summer 1981.
- Noreault, T.; Koll, M.; McGill, M.J. Automaticranked output from Boolean searches in SIRE. Journal of the ASIS 2716; 333-339; November1977.
- Radecki, T. Incorporationof relevance feedback into Boolean retrieval systems. Lecture Notes in Computer Science, 146, G. Salton and H.J. Schneider,eds., pp. 133-150. Berlin: Springer-Verlag;1982.
- Paice, C.D. Soft evaluationof Boolean search queries in informationretrieval systems. InformationTechnology: Research and Development3:l; 33-41; 1983.
- Cater, S.C.; Kraft, D.H. A topologicalinformationretrieval system (TIRS) satisfying the requirements of the Waller-Kraftwish list. Proc. Tenth Annual ACM-SIGIRConferenceon Research and Development in Information Retrieval,C.T. Yu and C.J. van Rijsbergen,eds. pp. 171-180. Associationfor Computing Machinery,New York: 1987.
- Wong, S.K.M.; Ziarko, W.; Raghavan,V.V.; Wong, P.C.N. Extended Boolean query processing in the generalized vector space model, Report, Departmentof Computer Science, University of Regina, Regina, Canada; 1986.
- Wong, S.K.M.; Ziarko, W.; Wong, P.C.N. Generalizedvector space model in informationretrieval. Proc.
- Eighth Annual ACM-SIGIRConferenceon Research and Developmentin InformationRetrieval, Association for ComputingMachinery,New York; 18-25; 1985.
- Wu. H. On query formulation in information retrieval. Doctoral dissertation, Cornell University, Ithaca, NY: January- 1981.
- Salton, G.; Fox, E.A.; Wu, H. Extended Boolean informationretrieval. Communicationsof the ACM 26:ll; 1022-1036;November1983.
- Croft, W.B. A comparisonof the cosine correlation and the modified probabilisticmodel. InformationTechnology: Research and Development3:2; 113-I 14; April 1984.