
Abstract
When writing this essay master's work is not yet completed. Final Completion: June 2019. The full text of the work and materials on the topic can be obtained from the author or his manager after the specified date.
Content
- Introduction
- 1. Theme urgency
- 2. Goal and tasks of the research
- 3. Analysis of methods for extracting knowledge from the Internet and their storage
- 3.1 Automatic collection and processing of information
- 3.2 Database models and storage of sports information
- Conclusion
- References
Introduction
Nowadays there is a huge amount of information that is on the global Internet. The data are unstructured material, among which there is usually a large amount of repetitive information, as well as not relevant to the user. There is also a process of continuous growth of information, which means that there is a need for the development of technologies that will allow data to be used to perform certain tasks.
1. Theme urgency
Pre-processing of information is divided into several stages, such as consolidation, transformation and cleaning. The most difficult is consolidation, since it includes the acquisition and collection of information.
In order to manually collect and analyze data from at least one source will take a large amount of time, so automatic collection and processing of information is essential for modernity. The chosen topic is relevant, as the information obtained can be used in various directions, including to predict future events, for example, sports scores.
2. Goal and tasks of the research
The purpose of the study is to analyze the stages of information processing, as well as forecasting methods from the point of view of their application in the system of prediction of sports competitions.
The main objectives of the study:
- consider the methods and algorithms for extracting knowledge from html pages;
- to study approaches to the primary processing of the information received, its systematization and filtering;
- consider storage approaches;
- highlight and explore further directions for using the data.
3. Analysis of methods for extracting knowledge from the Internet and their storage
3.1 Automatic collection and processing of information
As mentioned earlier, information processing is divided into 3 stages, such as consolidation, transformation and purification.
Consolidation - a set of methods and procedures aimed at extracting data from various sources, ensuring the necessary level of their informativeness and quality, conversion into a single format in which they can be loaded into a data warehouse or analytical system [1].
Data consolidation is the initial stage of the implementation of any analytical task or project. The consolidation is based on the process of collecting and organizing data storage in the form that is optimal in terms of processing it on a specific analytical platform or solving a specific analytical task. Related consolidation tasks are data quality assessment and enrichment.
Basic criteria for optimality in terms of data consolidation [1]:
- ensuring high speed data access;
- compact storage;
- automatic support for data structure integrity;
- control data consistency.
The key concept of consolidation is a data source — an object containing structured data that may be useful for solving an analytical problem. It is necessary that the analytical platform used can access data from this object directly or after converting it to another format [2].
Analytical applications, as a rule, do not contain developed means of data input and editing, but work with already formed samples. Thus, the formation of arrays of data for analysis in most cases falls on the shoulders of customers of analytical solutions. In the process of data consolidation, the following tasks are solved [1]:
- selection of data sources;
- development of a consolidation strategy;
- data quality assessment;
- enrichment;
- cleaning;
- transfer to the data store.
First, the selection of sources containing data that may be relevant to the problem being solved is carried out, then the type of sources and the organization of access to them are determined.
When developing a data consolidation strategy, it is necessary to take into account the nature of the location of data sources - local, when they are located on the same PC as the analytical application, or remote, if the sources are available only through local or global computer networks. The nature of the location of data sources can significantly affect the quality of the collected data (loss of fragments, inconsistency in the time of their updating, inconsistency, etc.).
Another important task that needs to be addressed as part of consolidation is to assess the quality of the data in terms of their suitability for processing using various analytical algorithms and methods. In most cases, the source data is dirty
, that is, they contain factors that prevent them from properly analyzing, detecting hidden structures and patterns, establishing relationships between data elements and performing other actions that may be required to obtain an analytical solution. These factors include input errors, omissions, anomalous values, noise, inconsistencies, etc. Therefore, before proceeding with the analysis of data, it is necessary to assess their quality and compliance with the requirements of the analytical platform. If the quality assessment process reveals factors that do not allow to apply certain analytical methods to the data correctly, it is necessary to perform an appropriate data cleansing [1].
Transformation - a set of methods and algorithms aimed at optimizing the presentation and data formats in terms of tasks and analysis goals. Transformation is not intended to change the information content of the data. Its task is to present this information in such a way that it can be used most effectively. This stage is important in the analysis process, because the effectiveness of the analysis, the accuracy and accuracy of the results depends on how well this stage is performed [3].
Data cleansing - a set of methods and procedures aimed at eliminating the causes that prevent correct processing: anomalies, gaps, duplicates, contradictions and noise [1].
Automatic collection of information would be much easier if there was a unified system for building sites and placing information in them. However, there are no such standards, which means that it is necessary to extract information in another way. This approach has its advantages and disadvantages. The advantages include:
- processing speed is quite high;
- automatic system configuration allows you to extract information from virtually any source;
- the data obtained can be analyzed and used for further prediction.
The disadvantages are that you need to clearly catch exceptions and errors, since the smallest of them can lead to data loss.
3.2 Database models and storage of sports information
A database is a collection of data organized in accordance with a conceptual structure that describes the characteristics of this data and the relationship between them, and this is a collection of data that supports one or more applications.[4].
For a data model, consider this classification:
- hierarchical;
- network;
- object-oriented;
- relational.
A hierarchical data model is a data model that uses a database representation in the form of a tree-like (hierarchical) structure consisting of objects at different levels [5]. The computer's file system is a good example of a hierarchical database.
This type of database is well optimized for reading information, which makes it possible to quickly select and issue the necessary information to the user. However, the disadvantage of this structure is that it is impossible to quickly sort through information, since it is necessary to consistently go through the entire branch, which requires a lot of time and resources. Figure 1 shows the hierarchical database structure.
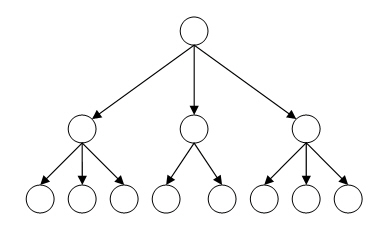
Figure 1 – The structure of the hierarchical data model
Network databases are a kind of modification of the hierarchical database, if you compare the structures of the hierarchical and network data models (fig. 1-2), you can see that they are similar to each other, the only difference is that in the network model the child can to be several ancestors, that is, elements standing above it.
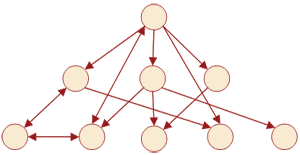
Figure 2 - Structure of the network data model
Object-oriented databases are databases in which information is presented in the form of objects, as in object-oriented programming languages. The main advantages of this approach are the following characteristics:
- There is no problem with inconsistency of the data model in the application and database. All data is stored in the database in the same form as in the application model;
- it is not required to separately support the data model on the DBMS side;
- all objects at the data source level are strongly typed (no column names are required);
- Automated refactoring of object-oriented database and running code [6].
However, there are a number of disadvantages:
- minimal query optimization;
- lack of standard query algebra;
- lack of means to provide requests;
- lack of view support;
- security issues;
- limited support for integrity constraints, etc [7].
A relational database is a collection of interrelated tables, each of which contains information about objects of a particular type. The row of the table contains data about one object (for example, product, customer), and the columns of the table describe various characteristics of these objects - attributes (for example, name, product code, customer information). Records, that is, rows of a table, have the same structure - they consist of fields that store the attributes of an object. Each field, that is, a column, describes only one characteristic of the object and has a strictly defined data type. All records have the same fields, only they display different information properties of the object [8].
Databases are a rather abstract concept, since the table is intended for storing information, while the set of tables that are related to each other is a database.
Designing a database structure is the most time consuming task when working with the relational model. At this stage, it is necessary to think over and create a set of tables, links, so that increasing information does not lead to a great slowdown of the system. The relational model allows you to modify the data, that is, add, delete records without much effort. This enables high-quality work with the storage of information obtained from the pages of the Internet about sports, as this area requires constant updating and adding information. Such data include the following characteristics and statistics:
- command name;
- number of wins / losses / draws;
- number of goals scored / missed;
- championship rating;
- % wins / losses / draws (for the last 10 matches);
- average% of possession;
- average% accurate gear;
- the number of key matches in the coming month;
- presence / absence of key players;
- the average number of goals scored / conceded in the last 5 matches;
- the average number of goals scored / missed in the last 5 matches face-to-face;
- match results, etc.
The database should be as informative as possible and at the same time compact and not redundant. This will make it easier to work with it and process data that can be used in the future to predict the results of competitions.
Conclusion
An analysis of the sources showed that the topic of obtaining information from web pages and its processing is relevant both in the international, national and local scientific communities.
In this paper, we analyzed the stages of information processing, each of which will be used in one way or another to obtain the necessary, structured information; analyzed data models and storage of information about sports. The most appropriate model is the relational approach, since it tends to modify the data, is easy to understand, and use. Indicators and characteristics that are to be obtained from the Internet pages and stored in a database were highlighted.
References
- Консолидация данных – ключевые понятия [Электронный ресурс]. – Режим доступа: http://www.cfin.ru/itm/olap/cons.shtml.
- Задачи консолидации [Электронный ресурс]. – Режим доступа: http://bourabai.kz/tpoi/olap01.htm.
- Трансформация данных [Электронный ресурс]. – Режим доступа: https://basegroup.ru/community/glossary/transformation.
- База данных [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/База_данных.
- Иерарическая модель данных [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Иерархическая_модель_данных.
- Введение в объектно-ориентированные базы данных [Электронный ресурс]. – Режим доступа: https://habr.com/post/56399/.
- Объектно-ориентированные базы данных: достижения и проблемы [Электронный ресурс]. – Режим доступа: https://www.osp.ru/os/2004/03/184042/.
- Реляционная база данных и ее особенности. Виды связей между реляционными таблицами [Электронный ресурс]. – Режим доступа: http://www.yaklass.ru/materiali?chtid=511&mode=cht.