Simple Rules for Syllabification of Arabic Texts
Authors: Soori H., Platos J., Snasel V., Abdulla H.
Source: International Conference on Digital Information Processing and Communications ICDIPC 2011: Digital Information Processing and Communications pp 97-105
Abstract
The Arabic language is the sixth most used language in the world today. It is also used by United Nations. Moreover, the Arabic alphabet is the second most widely used alphabet around the world. Therefore, the computer processing of the Arabic language or Arabic alphabet is becoming more and more important task. In the past, several books about analyzing of the Arabic language were published. However, the language analysis is only one-step in the language processing. Several approaches to the text compression were developed in the field of text compression. The first and most intuitive is the character-based compression that is suitable for small files. Another approach called word-based compression become very suitable for very long files. The third approach is called syllable-based, which uses the syllable as a basic element. Algorithms for the syllabification of the English, German or other European language are well known, but syllabification algorithms for Arabic and their usage in text compression has not been deeply investigated. This paper describes a new and very simple algorithm for syllabification of Arabic and its usage in text compression.
Keywords: Arabic, syllables, syllabification, text compression.
1 Introduction
The importance of conducting research in the area of syllabification of Arabic is called for two main reasons: the rapidly growing number of computer and internet users in the Arab world and the fact that the Arabic language is the sixth most used language in the world today. It is also one of the six languages used in the United Nations (www.un.org). Another important factor is, after the Latin alphabet (Latin alphabet), Arabic alphabet is the second-most widely used alphabet around the world. Arabic script has been used and adapted to such diverse languages as the Slavic tongues (also known as Slavic languages), Spanish, Persian, Urdu, Turkish, Hebrew, Amazigh (Berber), Swahili, Malay (Jawi in Malaysi and Indonesia), Hausa and Mandinka (in West Africa), Swahili (in East Africa), Sudanese, and some other languages [10].
1.1 Some Possible Challenges to be Considered When Working with Arabic Texts
One of challenges faced by researchers in this area has to do with the special nature of Arabic script in Arabic. Arabic is written horizontally from right to left. The shape of each letter depends on its position in a word—initial, medial, and final. There is a fourth form of the letter when written alone. The letters alif, waw, and ya (standing for glottal stop, w, and y, respectively) are used to represent the long vowels a, u, and i. This is very much different from Roman alphabet which is naturally not linked. Other orthographic challenges can be the persistent and widespread variation in the spelling of letters such as hamza and ta’ marbuTa, as well as, the increasing lack of differentiation between word-final ya and alif maqSura.
Another problem that may appear is that typists often neglect to insert a space after words that end with a non-connector letter [3]. In addition to that, Arabic has eight short vowels and diacritics. Typists normally ignore putting them in a text, but in case of texts where they exist, they are pre-normalized –in value- to avoid any mismatching with the dictionary or corpus in light stemming. As a result, the letters in the decompressed text, appear without these special diacritics.
Diacritization has always been a problem for researches. According to Habash [12], since diacritical problems in Arabic occur so infrequently, they are removed from the text by most researchers. Other text recognition studies in Arabic include, Andrew Gillies et. al. [11], John Trenkle et al. [30] and Maamouri et al. [20].
2 Text Compression
The key to data compression is the ability to model data to improve the efficiency of prediction [25]. The modeling of the data consists of modeling the context [1]. Modeling textual data means the modeling of the language. The most widely analyzed language is English. The first analysis of English was made by Shannon, who computed its entropy [26]. The latter analysis of English was closely related to the PPM compression method. Bell et al., in an excellent survey in [1], describe the state of the modeling of data at the end of the year 1989. They describe the principles of data modeling for context models (such as the PPM compression method). Moreover, the paper describes the principles of other possible models - finite state models like Dynamic Markov Compression [6, 13] and grammar or syntactic models [4, 15]. PPM-based compression usually uses contexts with a limited length. For English, a context with a maximal length of 6 symbols is standard [1]. Cleary et al. [5] and Bloom [2] inspect the possibility of unlimited context length. Skibinski and Grabowski [28] summarize both the previous methods and describe their own improvements based on variable-length context. The problem of the memory requirements of the PPM model is discussed by Drinic et al. in [7]. In [27] Shkarin describes the practical implementation of the PPM method using instruction sets of modern processors and Lelewer and Hirschberg [19] suggest a variation of PPM optimized for speed.
Compression based on a combination of several models using neural networks was presented by Mahoney [21].This concept is called context mixing. Algorithms based on this principle are the most efficient in several independent compression benchmarks.
Another research study in the field of text compression focuses on analyzing context information in files of various sizes. The main advantage of this approach is that the compression algorithms may be used without any modification. The efficiency (scalability) of the compression methods used for text compression may be related with the selection of the basic elements.
The first approaches focused on the compression of large text files. For large files, words were used as the basic elements. This approach is called word-based compression [14, 8, 31]. All the basic compression methods were adapted to this type of compression. The first modification was a modification of Huffman encoding called Huffword [31]. Later, other methods followed: WLZW as a modification of the LZW method [14, 8], and WBW as a modification of the Burrows-Wheeler transformation-based compression [9, 22]. PPM has its modification for word-based compression[31], too. The last modification for word-based compression was made for LZ77 compression [23]. As written above, all these modifications left the main compression unchanged. The only change is made in the first part of the algorithms, where the input symbols are read. The input file is read as a character sequence. From this sequence several types of elements are decomposed. Usually, two basic element types are recognized - words, which are represented as sequences of letters, and non-words, which are represented as sequences of white spaces, numbers, and other symbols. Algorithms must solve problems with capital letters, special types of words, hapax-legomenons (words which are present only once in the file), etc. A third type of element is sometimes also defined. The most commonly used one is a tag, which is used for structured documents such as XML, HTML, SGML, and others. A very interesting survey of dictionary-based text compression and transformation was presented by Skibinski et al. [29].
The second approach evolved by Lansky [18, 17] is syllable-based compression. Lansky made experiments with LZW, Huffman encoding, and Burrows-Wheeler transformation-based compression methods adapted for using syllables as basic elements [18, 17]. The main problem of this approach is the process of separation of syllables, also called hyphenation algorithms. This algorithm is specific to any language. The rules for word hyphenation may be heuristic, linguistically based, or other. The first two approaches were described for the Czech, English, and German languages in [18, 17]. A soft computing approach to hyphenation is described in [16], where a genetic algorithm is used for preparing the optimal set of syllables for achieving optimum compression using Huffman encoding.

Fig. 1. Context information in text files of various sizes
Three different approaches to text compression, based on the selection of input symbols, were defined - character-based, syllable-based, and word-based. The question is which type is the most suitable for defined texts. In [17], authors compare the single file parsing methods used on input text files of a size 1KB-5MB by means of the Burrows-Wheeler Transform for different languages (English, Czech, and German). They consider these input symbol types: letters, syllables, words, 3-grams, and 5-grams. Comparing letter-based, syllable-based, and word-based compression, they came to the conclusion that character-based compression is the most suitable for small files (up to 200KB) and that syllable-based compression is the best for files of a size 200KB-5MB. The compression type that uses natural text units such as words or syllables is 10-30% better than the compression with 5-grams and 3-grams. For larger files, word-based compression methods are the most efficient.
These findings correspond to the amount of contextual information stored in files. Contextual information in large text files (larger than 5 MB) is very big and therefore it is sufficient to process them using word-based compression (see Figure 1a). Medium-sized text files (200KB-5MB) have less contextual information than large text files, and, therefore, it is insufficient to take the word as a base unit; however, we can take a smaller grammatical part and use syllable-based compression (see Figure 1b). Contextual information in small files (10KB - 200KB) is difficult to obtain. In small files, the contextual information is sufficient only when we process them by characters (see Figure 1c).
The efficiency of the text compression may be improved with simple modification when multiple documents are compressed. In [24], cluster analysis is used for improving the efficiency of the compression methods. All the main compression methods adapted for word-based compression are tested and the compression ratio is improved by up to 4 percent.
3 Rule set
The rules for syllable separation are well defined for English, German, Czech and many other European languages. However, as far as Arabic is concerned, research in this area is still young. Arabic script is different from languages using Roman characters in many aspects, for example: text direction (right to left) and connection of letters in a word.
This study defines several rules for the decomposition of Arabic words into syllables. These rules are based on splitting the text according to some linguistic criteria called here, split markers. The basic criterion for splitting the text is tracing the vowel letter in a text.
In this study, the term Arabic vowels includes the following: vowels, long vowels and diphthongs:
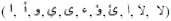
It is to be mentioned here that the letters 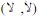 are dual letters, i.e., they both contain two letters of which the first is a consonant letter and the second is a vowel.
are dual letters, i.e., they both contain two letters of which the first is a consonant letter and the second is a vowel.
It is also worth mentioning here that, interestingly enough, the Unicode value of the dual letters is not always equal to the total value of two letters if taken separately. While the total Unicode value of the letters in are the same if taken separately, dual letter characters such as 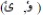 carry a new Unicode value.
carry a new Unicode value.
Split markers include also some other kinds of vowels which are indicated by diacritical marks called, short vowels. These are placed above or below the letter, such as, 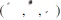 . Other diacritical marks that are included among the split markers in this study are nunations such as
. Other diacritical marks that are included among the split markers in this study are nunations such as 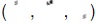 . In written Arabic, nunation is indicated by doubling the vowel diacritic at the end of the word. These diacritical marks mentioned above are used in fully vocalized texts in Arabic.
. In written Arabic, nunation is indicated by doubling the vowel diacritic at the end of the word. These diacritical marks mentioned above are used in fully vocalized texts in Arabic.
4 Algorithm
The rule set defined in the previous section leads to an algorithm which may be defined as follows:
- Read the input file and process all words by the following steps.
- When the length of the word is less than 3 characters, ignore it.
- When the second and third letters are vowels, make a split between the second and third letter.
- Otherwise, make a split after the third letter.
As may be seen, the algorithm is quite simple. The example of the syllabification using this algorithm may be seen in the Figure 2. The hyphens are used as splitting marks.

Fig. 2. Example of the syllabification
5 Processing of Text Files
For testing purposes, we test several text files written in Arabic language. The first group comprises short texts from Arabic newspapers. The second group contains several larger files. The statistics of the used files is shown in Table 1. For each file we test decomposition into 2-grams, 3-grams, characters, syllables using described algorithm and decomposition into words. The whitespaces are handled as a one syllable/word in syllable and word decomposition. The size of the alphabet extracted from the testing files using the methods referred to is also depicted in Table 1. The testing files are selected from two sources. The first source is four short texts taken from the web pages of Arabic international news channels, and the long text is taken from shareware Arabic books from the web. All texts are encoded using CodePage 1256 - Arabic Script.
Table 1. Statistics of Testing Files
| File: | Short1 | Short2 | Short3 | Short4 | Long1 | Long2 |
| File size (B) | 1922 | 7926 | 2910 | 12278 | 1547552 | 845431 |
| Unique Chars | 45 | 64 | 51 | 71 | 95 | 60 |
| Unique Syllables | 320 | 898 | 490 | 1117 | 9342 | 6521 |
| Unique Words | 232 | 837 | 391 | 1187 | 55006 | 28336 |
| Unique 2-grams | 301 | 623 | 425 | 712 | 2208 | 1251 |
| Unique 3-grams | 429 | 1397 | 680 | 1843 | 19377 | 11113 |
As may be seen from Table 1, the number of the extracted unique syllables is rather high, but it is always less than the number of 3-grams. As for the files bigger than 10kB, it is also lower than the number of words.
6 Compression Experiments
In this section, experiments using two different compression algorithms will be performed. The first algorithm is based on Burrows-Wheeler transformation with combination Huffman encoding and Move-To-Front and RLE transformation. This algorithm is chosen because its efficiency is based on the relationships between sibling symbols. The second algorithm is LZW compression algorithm which gains its efficiency from repetitions of symbols.
During experiments, we use a large enough dictionary for LZW algorithm and large enough block size for BWT based algorithm to avoid clearing of dictionary and splitting input into several blocks.
The results of the experiment are shown in Table 2. For comparison purposes, it is necessary to compare sizes of the compressed texts together with the size of the dictionary used.
Table 2. Experimental Results (all sizes are in bytes)
| File: | Short1 | Short2 | Short3 | Short4 | Long1 | Long2 |
| File size (B) | 1922 | 7926 | 2910 | 12278 | 1547552 | 845431 |
| Chars Dict. | 90 | 128 | 102 | 142 | 190 | 120 |
| Chars BWT | 961 | 3837 | 1554 | 5666 | 616079 | 307654 |
| Chars LZW | 1119 | 4484 | 1801 | 6696 | 727257 | 362236 |
| Syllables Dict. | 1110 | 3311 | 1764 | 4124 | 48115 | 27950 |
| Syllables BWT | 814 | 3549 | 1358 | 5430 | 608502 | 308506 |
| Syllables LZW | 904 | 3947 | 1511 | 6032 | 734357 | 359564 |
| Words Dict. | 1433 | 5049 | 2357 | 7566 | 369092 | 186962 |
| Words BWT | 438 | 2190 | 765 | 3318 | 533775 | 265799 |
| Words LZW | 602 | 2801 | 1048 | 4236 | 644161 | 307962 |
| 2-grams Dict. | 903 | 1869 | 1275 | 2136 | 6624 | 3752 |
| 2-grams BWT | 900 | 3849 | 1485 | 5764 | 634955 | 303076 |
| 2-grams LZW | 987 | 4325 | 1648 | 6595 | 768174 | 374316 |
| 3-grams Dict | 1715 | 5588 | 2720 | 7371 | 77507 | 44450 |
| 3-grams BWT | 687 | 3216 | 1133 | 5078 | 649286 | 311581 |
| 3-grams LZW | 751 | 3527 | 1246 | 5610 | 812509 | 389112 |
As may be seen from the results, the most efficient compression algorithm for small files (Short1-Short4) is character-based compression. All other approaches achieved worse results. This corresponds with information mentioned in Section 2. The best results for larger files (Long1 and Long2) were achieved by 2-grams approach, but the character and syllable approach have almost the same efficiency. These experiments show that our syllabification algorithm needs to be improved and more experiments will have to be performed.
7 Conclusion
This paper describes a new simple set of rules for syllabification of Arabic language. The algorithm uses only two basic rules, but it achieves very good results in the identifying of syllables. We used this algorithm in text compression for 2 types of input files. The short files contain up to 12,000 characters. The long files are more than 800,000 characters. We compare efficiency of the compression using the syllable approach with characters, words, 2-grams and 3-grams approaches on these two groups of files. The best result for short files were achieved by character based approach, as was expected. For long files, the best results were achieved by 2-grams approach, but character approach and syllable approach were also very efficient. In the future, a correction must be done especially in non-word and non-syllable handling and more sophisticated syllabification algorithm must be tested.
Acknowledgment: This work was supported by the Grant Agency of the Czech Republic, under the grant no. P202/11/P142.
References
- Bell, T., Witten, I.H., Cleary, J.G.: Modeling for text compression. ACM Comput. Surv. 21(4), 557–591 (1989)
- Bloom, C.: Solving the problems of context modeling (March 1998), http://www.cbloom.com/papers/index.html
- Buckwalter, T.: Issues in arabic morphological analysis. In: Ide, N., Veronis, J., Soudi, A., Bosch, A.v.d., Neumann, G. (eds.) Arabic Computational Morphology, Text, Speech and Language Technology, vol. 38, pp. 23–41. Springer Netherlands (2007), http://-dx.doi.org/10.1007/978-1-4020-6046-5_3, 10.1007/978-1-4020-6046-5_3
- Cameron, R.: Source encoding using syntactic information source models. Information Theory, IEEE Transactions on 34(4), 843 –850 (jul 1988)
- Cleary, J.G., Teahan, W.J., Witten, I.H.: Unbounded length contexts for ppm. In: DCC ’95: Proceedings of the Conference on Data Compression. p. 52. IEEE Computer Society, Washington, DC, USA (1995)
- Cormack, G.V., Horspool, R.N.S.: Data compression using dynamic markov modelling. Comput. J. 30(6), 541–550 (1987)
- Drinic, M., Kirovski, D., Potkonjak, M.: Ppm model cleaning. In: Data Compression Conference, 2003. Proceedings. DCC 2003. pp. 163 – 172 (march 2003)
- Dvorsky, J., Pokorny, J., Snasel, V.: Word-based compression methods and indexing for text retrieval systems. In: ADBIS. pp. 75–84 (1999)
- Dvorsky, J., Snasel, V.: Modifications in burrows-wheeler compression algorithm. In: Proceedings of ISM 2001 (2001)
- Encyclopedia Britannica Online: Alphabet. Online (Feb 2011), http://-www.britannica.com/EBchecked/topic/17212/alphabet
- Gillies, A., Erl, E., Trenkle, J., Schlosser, S.: Arabic text recognition system. In: Proceedings of the Symposium on Document Image Understanding Technology (1999)
- Habash, N.Y.: Introduction to Arabic natural language processing. Synthesis Lectures on Human Language Technologies 3(1), 1–187 (2010), http://www.morganclaypool.com/-doi/abs/10.2200/S00277ED1V01Y201008HLT010
- Horspool, R.N.S., Cormack, G.V.: Dynamic Markov modeling - a prediction technique pp. 700–707 (1986)
- Horspool, R.N.: Constructing word-based text compression algorithms. In: Proc. IEEE Data Compression Conference. pp. 62–81. IEEE Computer Society Press (1992)
- Katajainen, J., Penttonen, M., Teuhola, J.: Syntax-directed compression of program files. Softw. Pract. Exper. 16(3), 269–276 (1986)
- Kuthan, T., Lansky, J.: Genetic algorithms in syllable-based text compression. In: DATESO (2007)
- Lansky, J., Chernik, K., Vlickova, Z.: Comparison of text models for bwt. In: DCC ’07: Proceedings of the 2007 Data Compression Conference. p. 389. IEEE Computer Society, Washington, DC, USA (2007)
- Lansky, J., Zemlicka, M.: Compression of small text files using syllables. In: DCC ’06: Proceedings of the Data Compression Conference. p. 458. IEEE Computer Society, Washington, DC, USA (2006)
- Lelewer, D., Hirschberg, D.: Streamlining context models for data compression. In: Data Compression Conference, 1991. DCC ’91. pp. 313 –322 (apr 1991)
- Maamouri, M., Bies, A., Kulick, S.: Diacritization: A challenge to Arabic treebank annotation and parsing. In: IN PROCEEDINGS OF THE BRITISH COMPUTER SOCIETY ARABIC NLP/MT CONFERENCE (2006)
- Mahoney, M.V.: Fast text compression with neural networks. In: Proceedings of the Thirteenth International Florida Artificial Intelligence Research Society Conference. pp. 230–234. AAAI Press (2000)
- Moffat, A., Isal, R.Y.K.: Word-based text compression using the burrows-wheeler transform. Inf. Process. Manage. 41(5), 1175–1192 (2005)
- Platos, J., Dvorsky, J.: Word-based text compression. CoRR abs/0804.3680, 7 (2008)
- Platos, J., Dvorsky, J., Martinovic, J.: Using Clustering to Improve WLZ77 Compression. In: 2008 FIRST INTERNATIONAL CONFERENCE ON THE APPLICATIONS OF DIGITAL INFORMATION AND WEB TECHNOLOGIES, VOLS 1 AND 2. pp. 315–320. IEEE Commun Soc, IEEE, 345 E 47TH ST, NEW YORK, NY 10017 USA (2008), 1st International Conference on the Applications of Digital Information and Web Technologies, Ostrava, CZECH REPUBLIC, AUG 04-06, 2008
- Rissanen, J., Langdon, G., J.: Universal modeling and coding. Information Theory, IEEE Transactions on 27(1), 12 – 23 (jan 1981)
- Shannon, C.E.: Prediction and Entropy of Printed English. Bell System Technical Journal 30, 50 – 64 (1951)
- Shkarin, D.: Ppm: one step to practicality. In: Data Compression Conference, 2002. Proceedings. DCC 2002. pp. 202 – 211 (2002)
- Skibinski, P., Grabowski, S.: Variable-length contexts for ppm. Data Compression Conference 0, 409 (2004)
- Skibinski, P., Grabowski, S., Deorowicz, S.: Revisiting dictionary-based compression: Research articles. Softw. Pract. Exper. 35(15), 1455–1476 (2005)
- Trenkle, J., Gilles, A., Eriandson, E., Schlosser, S., Cavin, S.: Advances in Arabic text recognition. In: Symposium on Document Image Understanding Technology. pp. 159–168 (April 2001)
- Witten, I.H., Moffat, A., Bell, T.C.: Managing Gigabytes: Compressing and Indexing Documents and Images. Morgan Kaufmann, 2nd edn. (May 1999)