Сжатие текста, основанное на цифровой стенографии
Авторы: Rathore Y., Pandey R., Ahirwar M.
Перевод: Воронков В. А.
Источник: International Journal of Computer Science and Information Security, Vol. 12, No. 7, July 2014.
Аннотация
С ростом спроса на передачу и хранение текста в результате появления сетевых технологий, сжатие текста приобрело свой собственный импульс. Обычно текст кодируется в традиционном коде для формата обмена данными. Секретное письмо Хаффмана или другие методы секретного письма сжимают простой текст [6] [11]. Мы запланировали совершенно новую технику для сжатия простого текста, которая вдохновлена идеями стенографии Питмана. В этом методе мы предлагаем более эффективную стратегию кодирования, которая может обеспечить более высокие коэффициенты сжатия и высокий уровень безопасности для всех возможных способов атак во время передачи. Целью этого метода является разработка более эффективного преобразования, обеспечивающего большее сжатие и дополнительную безопасность [11]. Основная идея сжатия состоит в том, чтобы преобразовать текст в некоторую промежуточную форму, которая может быть сжата с более высокой эффективностью и безопасным кодированием, которое использует естественную избыточность языка при создании этого преобразования.
Ключевые слова: сжатие, кодирование, REL, RLL, Хаффман, LZ, LZW, стенография Питмана, сжатие.
1. Введение
Сжатие данных – метод сокращения размера информации, которая будет сохранена или будет передана через сеть. Почти 70-80% интернет-пользователей посылают и получают текстовые документы. Существует растущий спрос на быструю передачу данных, что может быть возможно с помощью сжатия.
Есть много доступных методов для преобразования текста в сжатый формат [4]. Большинство этих методов использует формат ASCII (Американский стандартный код для обмена информацией), который является 8-битным кодом. Каждый символ текста закодирован в 8-битном формате. ASCII – четко определенный набор кодов, который является общепринятым.
Методы сжатия текста должны быть контекстно-зависимыми. В кодирующем методе Хафмана [4], входной текст анализируется с начала до конца, и определяется частота вхождения каждого символа (гистограмма). Впоследствии, применяется новая схема кодирования – у часто появляющихся символов будет код с меньшим числом битов, а у наименее часто появляющихся символов будет код с большим количеством битов. Также методами сжатия текстовых данных являются арифметическое кодирование, преобразование Барроуза-Уилера, LZW и т.д. [9].
Стенографы обычно используют метод стенографии Питмана [1], чтобы записывать быструю речь [2][3]. Очевидно, английский или любой другой язык, основанный на наборе символов, не может использоваться для создания заметок на такой скорости. Стенография Питмана является проверенным решением для этого требования. В этом методе используются специальные графические символы для представления фонетических композиций продиктованного текста за определенный интервал времени (может составлять 500 миллисекунд). Подобная стенография представляет собой сжатый и зашифрованный формат английского текста. Это вдохновило нас расширить концепцию стенографии Питмана [1] для сжатия простого английского текста. В этом исследовании определяется новый набор кодов, и эти коды используются вместо графических символов. Сжатие также служит для шифрования.
2. Компрессия и декомпрессия
Сжатие может быть технологией, с помощью которой размер одиного или нескольких файлов, или каталога будет уменьшен, что позволит легче работать с ними. Целью сжатия является уменьшение количества битов, необходимых для представления информации. Сжатие достигается посредством кодирования информации и, следовательно, информация распаковывается до ее первоначального вида путем дешифрования. Сжатие увеличивает пропускную способность линий связи за счёт передачи сжатого файла. Стандартный сжатый файл, который используется на сегодняшний день, имеет расширения, заканчивающиеся на .Sit, .Tar, .Zip. Существует два основных типа сжатия данных: с потерями и без потерь.
A. Методы сжатия без потерь
Методы сжатия без потерь восстанавливают исходную информацию из сжатого файла без потери данных [17]. Таким образом, данные не изменяются в процессе сжатия и распаковки. Методы сжатия без потерь применяются для сжатия изображений, например, текстовых и медицинских изображений, которые сохраняются по юридическим причинам, и так далее [9] [15].
B. Методы сжатия с потерями
Методы сжатия с потерями восстанавливают исходную информацию с потерей некоторых данных. Используя процесс декодирования, невозможно восстановить исходные данные. Это может быть полезно, когда могут быть проигнорированы данные некоторых диапазонов, которые не воспринимаются человеческим мозгом. Такие методы могут быть использованы для сжатия мультимедийных даных: аудио, видео и изображений [7] [8].
3. Введение в метод стенографии
Стенография – это метод сокращённого письма, который увеличивает скорость и краткость написания по сравнению с обычным способом написания текста. Термин стенография образовался от греческого stenos (узкий) и graphe или graphie. Её также называют брахографией, от греческого brachys (короткий) и тахиографией, от греческого tachys (быстрый), в зависимости от того, что является целью: сжатие или скорость письма. На рис. 1 показаны несколько английских предложений, написанных стенографическим методом [1] [2] [3] [16].

Рисунок 1 – Несколько английских предложений, написанных методом стенографии Питмана
4. Предлагаемый подход
Основная философия сжатия заключается в том, чтобы преобразовать текст в некоторую промежуточную форму, которая может быть сжата с большей эффективностью и более безопасным кодированием. При выполнении этого преобразования используется естественная избыточность языка [19].
Определяется частота встречаемости каждого слова. Затем используется новая схема кодирования – часто появляющееся слово будет иметь код с меньшим количеством специальных символов, а наименее часто появляющееся слово будет иметь код с большим количеством специальных символов. В следующем примере показано подобное преобразование.
The = ! said = *
And = “ light = :
God = >)
Алгоритм, который мы разрабатываем, состоит из трех этапов:
Шаг 1: Составление таблицы.
Шаг 2: Кодирование введенных текстовых данных.
Шаг 3: Дополнительное сжатие с использованием существующего метода.
Шаг 1: Составление таблицы
- Прочитать все слова одно за другим из входного файла и поместить в таблицу.
- Если слово уже есть в таблице – увеличить количество встречаемости на единицу, в противном случае – добавить его в таблицу и установить количество встречаемости равным единице.
- Сортировать таблицу по частоте появления в порядке убывания.
- Распределить коды следующим способом:
- Создать новую таблицу, содержащую только слова и их коды. Храните эту таблицу, потому что словарь в самом файле.
- Конец.
i) каждому из первых 153 слов назначить один из символов ASCII;
ii) оставшимся словам назначить два символа из ASCII (от 33 до 64 и от 128 до 248).
Если остались ещё слова – назначить им каждую перестановку из трёх символов ASCII и, наконец, при необходимости перестановку из четырёх символов.
Шаг 2: Кодирование введенных текстовых данных
- Пока файл не пуст
- Переименовать файл.
- Конец.
i. Считать слово из файла.
ii. Если слово длиннее одного символа – искать слово в таблице.
Если слово не найдено – записать слово в файл.
Иначе – записать в файл код, соответствующий слову.
iii.Иначе – записать слово в файл.
Шаг 3: Дополнительное сжатие с использованием существующего метода
Мы используем Gzip для дополнительного сжатия.
5. Анализ эффективности
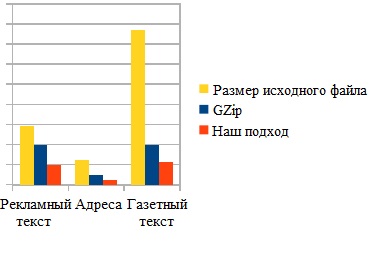
Данный метод реализован с использованием языка Java, в качестве входных данных используются три типа текстов, а именно рекламный текст (который обычно используется в электронной почте), адреса и газетный текст. Работоспособность алгоритма для трех различных типов текстовых данных приведена в таблице и на гистограмме ниже. Грамматически богатый текст дает наибольшее сжатие.
| № | Тип текста | Размер файла | Средняя степень сжатия методом GZip | Средняя степень сжатия предложенным методом |
| 1 | Рекламный текст | 29 КБ | 93.1% | 96.55% |
| 2 | Адреса | 1.25 КБ | 52.1% | 61.2% |
| 3 | Книга | 7 МБ | 72.28% | 85.71% |
| 4 | Газетный текст | 76.8 КБ | 72.28% | 86.58% |
На рис. 2 представлено главное окно нашей программы. Оно отображает единое меню для сжатия и распаковки. Сначала мы выбрали опцию сжатия.
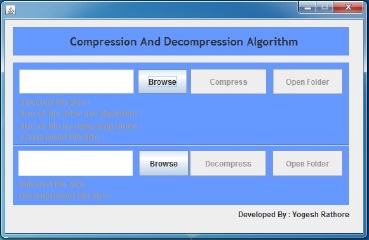
Рисунок 2 – Главное окно программы
На рис. 3 представлено окно программы после выбора файла для сжатия. Это окно показывает размер выбранного файла.
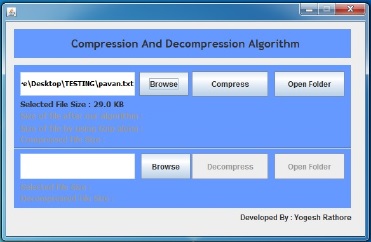
Рисунок 3 – Выбор файла для сжатия
После выбора файла для сжатия нажимаем кнопку «Сжать». Когда процесс сжатия завершается, программа показывает размер сжатого файла. Для сжатия она использует наш алгоритм и алгоритм Gzip. Это показано на рис. 4.
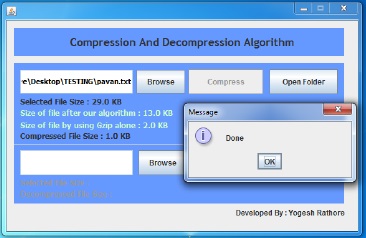
Рисунок 4 – Окно, отображающее сообщение о завершении сжатия
На рис. 5 представлено окно, отображающее сообщение о завершении декомпрессии файла.
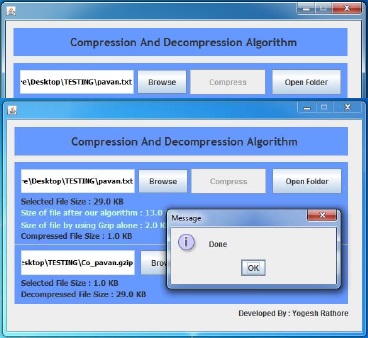
Рисунок 5 – Окно, отображающее сообщение о завершении декомпрессии
4. Выводы
Предлагаемый метод основан на понятиях стенографии. Он способен обеспечить сжатие на 15-50% больше, чем при использовании другого метода сжатия текста. Список используемых слов и их кодов может быть изменен в зависимости от ситуации. Однако существуют определенные ограничения при сжатии с использованием этого метода, такие как кодирование. В будущей работе стоит снять это ограничение.
Ссылки:
- HemanthaKumar G., PhD thesis supervision by Dr. Nagabhushan., On Automation of Text Production from Pitman Shorthand Notes. PhD thesis, University of Mysore, Mysore. 1998.
- Isaac Pitman, Shorthand Instructor and Key., Wheeler and Co., 1989
- Leedham C G and A Nair “Evaluation of dynamic programming algorithms for the recognition of Short forms in itman’s shorthand.” Journal of Pattern Recognition Letters, Vol 13, 1992
- Gonzalvez ”Image processing” McGraw-Hill publications 2”d edition
- Nagabhushan P and Murali S “Detection of intersection and sequence of stroke segments in Pitman’s shorthand document using Hough Transformation”, International conference on Cognitive Systems-1999.
- Knuth, D. E. 1985. Dynamic Huffman Coding. J. Algorithms 6, 2 (June), 163-180.
- Llewellyn, J. A. 1987. Data Compression for a Source with Markov Characteristics. Computer J. 30, 2, 149-156.
- Pasco, R. 1976. Source Coding Algorithms for Fast Data Compression.Ph. D. Dissertation, Dept. of Electrical Engineering, Stanford Univ., Stanford, Calif.
- Rissanen, J. J. 1983. A Universal Data Compression System. IEEE
- Trans. Inform. Theory 29, 5 (Sept.), 656-664.
- Tanaka, H. 1987. Data Structure of Huffman Codes and Its Application to Efficient Encoding and Decoding. IEEE Trans. Inform. Theory 33,1 (Jan.), 154-156.
- Ziv, J., and Lempel, A. 1977. A Universal Algorithm for Sequential Data Compression. IEEE Trans. Inform. Theory 23, 3 (May), 337-343.
- Giancarlo, R., D. Scaturro, and F. Utro. 2009. Textual data compression in computational biology: a synopsis. Bioinformatics 25 (13): 1575-1586.
- Burrows M., and Wheeler, D. J. 1994. A Block-Sorting Lossless Data Compression Algorithm. SRC Research Report 124, Digital Systems Research Center.
- S. R. Kodifuwakku and U. S. Amarasinge, “Comparison of loosless data compression algorithms for text data”.IJCSE Vol 1 No 4416-225.
- en.wikipedia.org/wiki/shothand
- RISSANEN, J., AND LANGDON, G. G. 1979. Arithmetic coding. IBM J. Res. Dev. 23, 2 (Mar.), 149-162.
- RODEH, M., PRATT, V. R., AND EVEN, S. 1981. Linear algorithm for data compression via string matching. J. ACM 28, 1 (Jan.), 16-24.
- Bell, T., Witten, I., Cleary, J., "Modeling for Text Compression", ACM Computing Surveys, Vol. 21, No. 4 (1989).