Современные тенденции в технологии машинного обучения
Автор: Егорова М.С., Мартыненко Т.В.
Источник: Материалы X Международной научно-технической конференции Информатика, управляющие системы, математическое и компьютерное моделирование
(ИУСМКМ-2019). – Донецк: ДонНТУ, 2019.
Аннотация
Егорова М.С., Мартыненко Т.В. Современные тенденции в технологии машинного обучения. В статье рассмотрены основные новации в области методологии машинного обучения. Выполнен анализ современной научной литературы, посвященной вопросам развития методологии и областей прикладного использования рассматриваемых тем. Сформулированы предположения о будущих тенденциях и предложены наиболее перспективные направления исследований.
Постановка проблемы в общем виде
Все большее внимание исследователей занимает вопрос методологий или метамоделей (от англ. metamodel): принципов использования, комбинирования и выбора конкретных моделей и методов машинного обучения. Многолетний прогресс в разработке методов машинного обучения породил не только разнообразные решения, но и встретил на своем пути немало препятствий.
Основная трудность, с которой сталкивается человек в процессе знакомства с областью машинного обучения, огромное количество разрозненных методов, каждый из которых обладает своими особенностями, областью использования и преимуществами. С развитием математических и алгоритмических методов становится все труднее хорошо ориентироваться во всех нюансах применяемых алгоритмов.
Цель статьи – обзор актуальных приемов, технологий и методик, применяемых при решении прикладных задач машинного обучения, по материалам научных статей в высокорейтинговых журналах зарубежных исследователей, аналитических и обзорных заметок из открытых источников, а также технической документации и пресс-релизов технических и программных решений.
Проблема интерпретируемости
В качестве математической и инструментальной основы машинного обучения сегодня центральное место занимают искусственные нейронные сети. Они стали своеобразным универсальным языком представления обучаемых моделей. И хотя искусственный интеллект и машинное обучение как области знаний гораздо шире и включают целые семейства других методов, нейросетевые модели в настоящий момент так или иначе фигурируют в 90% научных публикаций в данных областях [1].
С разработкой все более сложных и глубоких архитектур нейронных сетей вместе с несомненными достоинствами все явственнее проявляются общие проблемы этого подхода. Наиболее существенной из них можно назвать принцип работы любой нейросети как «черного ящика» ? даже должным образом обученная сеть не дает исследователям информации о внутренней структуре проблемы и выявленных зависимостях в данных. Обученная нейросеть является набором матриц весов, и смысловая интерпретация этих весов в общем случае не предполагается. С этой точки зрения нейросети представляют собой лишь инструмент решения конкретной задачи машинного обучения, но не дают экспертам аналитической информации для исследования проблемы. Этот недостаток заставляет исследователей заниматься проблемами интерпретируемости нейросетевых моделей [2, 3].
В настоящее время выделяют класс так называемых «естественно интерпретируемых моделей» – моделей, человеческая интерпретация которых не представляет труда в силу самой архитектуры модели. К ним относят, в частности: линейные и логистические регрессии, деревья решений, наивные байесовские классификаторы, k ближайших соседей, модели правил вывода и другие [3]. Объяснение внутреннего устройства других типов моделей, в том числе глубоких нейронных сетей, представляет собой открытую научную задачу. Основные методы для построения моделенезависимых объяснительных механизмов (англ. model-agnostic methods) представлены в таблице 1.
| Метод | Назначение |
| Функции и графики частичных зависимостей | Показывают предельное влияние признаков на результирующее значение |
| Механизм индивидуального условного ожидания | Расширение метода функций частичных зависимостей на локальный анализ отдельных предсказаний |
| Исследование уверенности модели (англ. model class reliance) | Моделенезависимый вариант алгоритма важности признаков, который позволяет оценить зависимость средней ошибки модели в зависимости от дисперсии отдельных признаков |
| Метод LIME (от англ. local interpretable model-agnostic explanations) | Основан на обучении локальных интерпретируемых моделей по предсказаниям модели, исследуемой для объяснения конкретных предсказаний |
В целом, область исследований интерпретируемости моделей машинного обучения можно назвать очень актуальной. Несомненно, данная проблематика получит свое развитие в дальнейших исследованиях в ближайшее время.
Предобученные модели
Использование нейронных сетей неразрывно связано с процессом их обучения. Даже самая продвинутая и сложная глубокая нейронная сеть, будучи необученной на правильно выбранном наборе данных, не может решить даже самых простых задач анализа данных. Эффективность работы обученных нейросетей напрямую зависит от объема и качества обучающей выборки и времени обучения. А время обучения, в свою очередь, зависит от вариативности модели. Чем более вариативная, глубокая и сложная модель используется, тем больше времени на обучение она требует и тем больший объем данных нужен для предотвращения переобучения.
Таким образом, перед исследователями стоит не только задача поиска качественной обучающей выборки и очистки данных, но и выбора архитектуры сети и проведения довольно затратного в плане процессорного времени обучения сети. Это приводит к вполне естественному предположению о возможности повторного использования обученных нейросетей. Существует несколько способов использования предобученных моделей в зависимости от размера доступной исследователям выборки и схожести выборок, используемых для предобучения и непосредственно для анализа (таблица 2).
| Наименование | Описание |
| Автоматизированное создание признаков | Предобученные модели могут использоваться для автоматического извлечения значимых признаков из анализируемой выборки данных для последующего анализа |
| Использование только архитектуры | Предобученные модели, показавшие свою эффективность на определенном модельном наборе данных, могут послужить образцом архитектуры для построения новой модели и обучения ее на анализируемом наборе |
| Частичное дообучение | Предобученные модели используют частично, а обучение происходит для части слоев такой сети. Обычно веса начальных слоев замораживают, а конечных обучают на непосредственно анализируемой выборке |
| ANN-HMM (от англ. artificial neural networks – hidden Markov models) | Использование глубоких сетей доверия для начальной инициализации весов нейронной сети с последующим дообучением методом обратного распространения ошибки |
Использование предобученных нейронных сетей, несомненно, является актуальным направлением развития технологии машинного обучения. Однако в настоящее время широкое распространение переноса обучения затруднено, в частности, отсутствием общепринятого формата хранения и распространения моделей нейронных сетей.
Мультизадачные сети
Одной из характеристик классических систем машинного обучения является специфичность модели для определенной задачи. Более того, различные архитектуры нейронных сетей имеют свою специфику в отношении предметной области. Естественным является вопрос о построении универсальной нейронной сети, которую можно было бы с минимальным переобучением использовать для решения многих различных задач.
В 2017 г. произошел прорыв в области многозадачного обучения. Команда Google Brain выпустила работу [4], в которой представила универсальную многокомпонентную архитектуру нейронной сети, названную MultiModel, которая достигает высоких результатов в одновременном обучении задачам из совершенно разных областей: обработка естественного языка, машинный перевод, распознавание лиц на изображении, распознавание речи. Важным методологическим результатом стало то, что такая сеть способна улучшать результаты одной задачи с обучением другой, совершенно, на первый взгляд, с ней не связанной.
Область мультизадачного обучения в ближайшие годы получит дальнейшее развитие. Представляется весьма интересным анализ мультизадачных сетей методами интерпретации черного ящика, развивающихся сегодня параллельно.
Нейроэволюция
Искусственные нейронные сети доказали свою эффективность в решении многих задач, однако эта эффективность в большой мере зависит от умения подбирать правильную архитектуру сети под каждую конкретную задачу анализа данных. При проектировании архитектуры сети эксперт сталкивается с необходимостью принять множество решений, как количественных, так и качественных, от реализации которых напрямую зависит производительность результирующей модели. В процессе такого проектирования задача эксперта – балансирование между вариативностью модели и склонностью к переобучению.
Пространство возможных нейронных сетей, в котором ведется поиск, огромно. При проектировании нейронных сетей специалисты используют определенные эвристические правила и инструменты диагностики, однако полноценной методологией такой поиск назвать сложно, это скорее творческий процесс.
Главным недостатком нейроэволюционного подхода являются весьма высокие требования к вычислительной мощности для поддержки данного процесса до сходимости. Развитие глубоких нейронных сетей и распространение больших данных еще выше поднимает эту планку. Поэтому, в настоящее время наблюдается спад интереса к эволюционному программированию искусственных нейронных сетей: время программиста и специалиста в области анализа данных сейчас стоит дешевле, нежели требуемое процессорное время.
Однако большие корпорации, располагающие высокими вычислительными мощностями, могут позволить себе эксперименты с нейроэволюцией. C ростом производительности вычислительной техники интерес к эволюционным методам в машинном обучении будет возвращаться (возможно итерационно), пусть не в ближайший год, но в обозримом будущем.
Автоматизированное обучение
На протяжении последнего времени автоматизация машинного обучения стала широко обсуждаемой темой и одной из наиболее быстрорастущих областей теоретических и практических разработок. Р. Олсон, один из разработчиков библиотеки автоматизированного машинного обучения, выделяет три главных процесса, автоматизация которых возможна и высвобождает большое количество временных ресурсов экспертов:
- подбор гиперпараметров моделей;
- испытание большого количества разных моделей;
- использование разных признаков, выделенных из данных [5].
Сложность традиционного подхода к построению систем машинного обучения состоит в необходимости знания всех существующих алгоритмов искусственного интеллекта, умения их правильно применить и настроить. Предлагаемые методы автоматизации машинного обучения связаны с существующими инструментальными средствами моделирования. Большинство из них ориентируется на библиотеку scikit-learn языка Python. Также существуют решения, основанные на генетическом подходе [6].
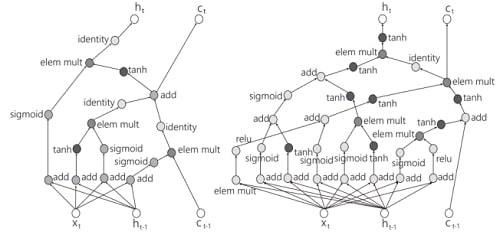
Рисунок 1 – Принципиальная схема одного элемента нейронной сети распознавания изображений, созданная человеком (слева) и с помощью Google AutoML (справа)
Активным направлением исследований в области автоматизации машинного обучения является проработка вопроса использования сложных нелинейных конвейеров обработки данных. Преимущественным методом нахождения таких конвейеров является генетическое программирование. В середине прошлого года исследовательский отдел Google представил архитектуру AutoML, основанную на обучении с подкреплением [7]. Эта система строит рекуррентные сети, схожие по своей архитектуре с построенными человеком, но более сложные. В конце 2017 г. усовершенствованная система AutoML смогла построить сеть, превосходящую все существующие в задачах распознавания объектов на изображении. Схема элемента представлена на рисунке 1.
Конечно, инструменты автоматизации машинного обучения не способны полностью вытеснить человека как участника процесса обработки данных. Также один из барьеров перед использованием систем AutoML – повышенные требования к вычислительным ресурсам. Однако с учетом экономии времени проектирования преимущество использования автоматизированного машинного обучения неоспоримо. Таким образом, можно с уверенностью назвать автоматизацию машинного обучения актуальной и активно развивающейся областью исследований. Поиск новых методов выбора моделей, перекрестной проверки, эволюционного и аналитического подбора алгоритмов обучения представляет как научный, так и чисто практический интерес.
Заключение
В настоящее время наблюдается прогресс в развитии методик автоматизированного поиска путей построения эффективных обучающихся моделей анализа данных, применимых ко многим практическим задачам интеллектуального анализа данных. В ходе обзора современных тенденций в машинном обучении нами выделены следующие перспективные направления фундаментальных и прикладных исследований в данной области:
- Теоретические исследования в области интерпретируемости моделей искусственного интеллекта в сочетании с анализом автоматически построенных моделей.
- Практические исследования мультизадачных, генеративных моделей.
- Распространение автоматизированных средств машинного обучения.
- Развитие и унификация инструментальных средств, в том числе облачных средств и сервисов интеллектуального анализа данных.
- Разработка новых интеллектуальных продуктов пользовательского уровня, основанных на вышеперечисленных достижениях методологии машинного обучения.
Литература
- Хохлова Д., «Бум нейросетей: Кто делает нейронные сети, зачем они нужны и сколько денег могут приносить».
- Koh P.W., Liang P., “Understanding black-box predictions via influence functions” // Proceedings of the 34th International Conference on Machine Learning, PMLR. Vol. 70. P. 1885–1894.
- Molnar C., “Interpretable machine learning”.
- Kaiser L. [и др.], “One model to learn them all”.
- Olson R., “TPOT: A Python tool for automating data science”.
- Olson R.S., Moore J.H., “TPOT: A tree-based pipeline optimization tool for automating machine learning”. P. 66–74.
- Zoph B. & Le Q.V., “Neural architecture search with reinforcement learning”.