Аннотация
Гума С.Н., Коломойцева И.А. Интернет-сайт для рекомендации фильмов. В данной статье рассмотрены подходы к созданию рекомендательных систем, которые основаны на методах и моделях Data Mining. Проведён анализ существующих методов для решения задачи предсказания интересов пользователя рекомендательной системы, выбрана наиболее действенная комбинация подходов к реализации алгоритмов разрабатываемой системы.
Введение
Системы персонализированных рекомендаций широко применяются для решения проблем информационной перегрузки и для предоставления персонализированных рекомендаций в отношении информации пользователей на сайтах электронной коммерции [2, 3]. Например, Taobao Shopping, Jing Dong Mall и рекомендации книг в Amazon [4] предоставили персональные рекомендации для всех типов пользователей. Выбор подходящего алгоритма рекомендации является ядром системы персонализированных рекомендаций [5]. В настоящее время популярные алгоритмы рекомендаций в основном делятся на основанные на контентной фильтрации, коллаборативной фильтрации (CF), гибридные системы и другие алгоритмы. Контентная (содержательная) фильтрация использует набор отдельных функций элементов, например, жанров, режиссеров и актеров в фильмах, для генерации рекомендаций [6]. Целью наиболее популярной коллаборативной фильтрации является выявление списка интересных элементов для целевых пользователей на основе предпочтений их единомышленников. Эти два подхода часто объединяются, чтобы сделать гибридную систему [7].
Как правило, алгоритм CF делится на рекомендации на основе памяти и на основе моделей по Breese et al. [10]. Рекомендация CF на основе памяти использует исторические данные для поиска похожих объектов. Рекомендация CF на основе памяти может быть разделена на рекомендацию на основе элементов и рекомендацию CF на основе пользователя. Рекомендация CF на основе элементов находит набор элементов, который похож на целевой объект на основе сходства между элементами. Пользовательская рекомендация CF опирается на информацию об активном пользовательском окружении, чтобы делать прогнозы и рекомендации [11]. Выбор соседних областей является одной из важнейших процедур пользовательского подхода CF, который выбирает группу пользователей из соседей-кандидатов, чтобы составить область активного пользователя. Рекомендация CF на основе модели обычно использует преимущества интеллектуального анализа данных, машинного обучения и других методов. Существуют некоторые традиционные меры сходства, такие как косинусное сходство (COS), коэффициент корреляции Пирсона (PCC), евклидово подобие, основанное на расстоянии (EDS), и скорректированное сходство на основе косинуса (ACOS), которые были широко используется в CF для оценки сходства [12].
В этой статье, направленной на улучшение традиционных алгоритмов CF для получения хорошего значения точности, мы предлагаем новый метод измерения сходства, называемый алгоритмом рекомендации совместной фильтрации, основанный на доверии пользователя и временном контексте (UCTC_User), новый подход, который улучшает основной ACOS. UCTC_User не только учитывает влияние того, является ли пользователь более надежным, чем другие, но также учитывает динамику его интересов. Экспериментальные результаты показывают, что UCTC_User не только улучшает меру подобия, но также может находить более точных соседей и повышать точность предсказания.
Предлагаемый метод вычисления подобия
В совместной фильтрации традиционный способ поиска соседей для активного пользователя зависит от информации об оценке общих оцениваемых элементов двумя пользователями. Тем не менее, существуют некоторые недостатки в традиционных методах измерения сходства, то есть фактор доверия пользователя не учитывается, и контекст времени также является важным фактором в информации об оценке.<.p>
В повседневной жизни людей концентрация каждого человека в каждой области различна. Поскольку некоторые люди проводят больше времени и энергии в определенной области, эти люди делают свои слова более авторитетными. Например, в конкурсе Я певец
певцы как оценщики проводят больше времени, чем обычные люди, и у этих экспертов есть свои знаменитые работы. Следовательно, значение каждого пользователя различно для целевого пользователя при расчете сходства между пользователями, и пользователь имеет более высокую достоверность, если пользователь является экспертом в этой области. В результате мы вводим пользовательскую достоверность в метод расчета скорректированного сходства косинусов, чтобы повысить точность рекомендации.
Существующий алгоритм рекомендации совместной фильтрации рассматривает каждый ресурс, к которому обращается пользователь в процессе рекомендации рекомендации, как равный, что, очевидно, неразумно. В целом, элементы, которые недавно посещал пользователь, играют более важную роль в рекомендации ресурсов, которые могут представлять интерес для пользователя в будущем, тогда как записи раннего доступа оказывают относительно небольшое влияние на генерацию рекомендаций.
Мы вводим временной контекст в метод расчета скорректированного косинусного сходства, чтобы повысить важность данных, к которым недавно обращались, в процессе генерации рекомендаций.
Чтобы преодолеть эти недостатки, в этой статье предложен алгоритм совместной фильтрации, основанный на доверии пользователя и контексте времени. На основе скорректированного косинусного сходства добавляются достоверность пользователя и временной контекст, чтобы учитывать аналогичное эталонное значение пользователя и информацию о временном контексте. На рисунке 1 показана структура предложенного нами алгоритма.
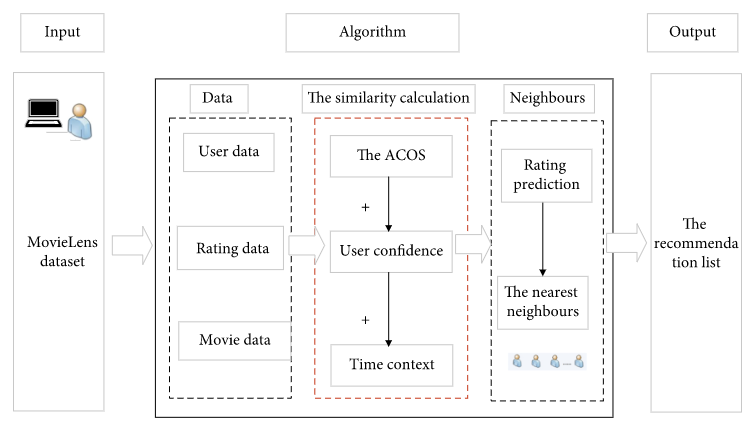
Рисунок 1 — Структура предложенного нами алгоритма.
Полезно учитывать популярность элемента при расчете сходства интересов пользователя для улучшения качества рекомендации. Следовательно, мы добавляем штрафной коэффициент популярных предметов в уравнение ACOS. Рассматривая книги в качестве примера, мы не думаем, что два пользователя схожи по своим интересам, если они когда-либо покупали Оксфордский словарь английского языка, потому что это очень распространенная книга. Однако, если оба пользователя купили Data Mining Введение, то их интерес можно было бы считать более схожим, поскольку только тот, кто изучает Data Mining, купит его. Соответственно, если два пользователя предприняли одно и то же действие с непопулярными предметами, тогда можно лучше проиллюстрировать сходство их интересов. Мы настраиваем числитель ACOS на новое уравнение и определяем его следующим образом:
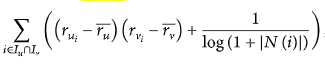
где N(i) это номер объекта i в рейтинге
Временной контекст
В контекстной информации временной контекст является важной информацией. Как правило, интересы людей меняются со временем. Например, молодым людям нравится красить волосы, носить индивидуальную одежду, и со временем выбор одежды постепенно переходит к зрелому стилю. Новые инженеры стремятся покупать книги с вводной классикой, и, проработав некоторое время, они выступают за выбор учебников с глубиной.
За очень короткий промежуток времени пользователи, которые похожи на целевого пользователя, дают приблизительную оценку того же элемента, что показывает, что пользователь больше похож на целевого пользователя, указывая на то, что рейтинг пользователя является более ценным. Более того, если пропорция пересечения между элементами обоих пользователей велика, высокое сходство между ними может быть отражено в некоторых областях. В соответствии с перспективой, мы определяем следующее уравнение:
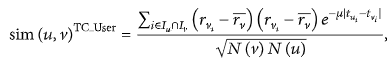
где tu и tv это информация о времени, когда пользователи u и v оценили объект.
Предлагаемы подход
В этой статье предлагается алгоритм рекомендации совместной фильтрации, основанный на доверии пользователя и контексте времени. Основная идея заключается в том, чтобы рассчитать сходство между пользователями, улучшив ACOS, добавив в него доверие пользователей и временной контекст. Определим уравнение следующим образом:
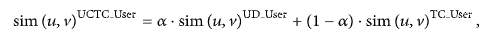
где a - фактор воздействия, который можно отрегулировать, чтобы получить лучший результат при повторных экспериментах.
Чтобы дать четкое описание, мы показываем наш предложенный метод в следующих шагах:
Вход: рейтинговая матрица
Вывод: прогноз для активного пользователя.
Шаг 1: использовать итоговое уравнение для вычисления сходства между пользователями и сгенерированная матрица сходства
Шаг 2: сортировка получившейся матрицы сходства в порядке убывания.
Шаг 3: получить диапазон выбора соседей активного пользователя и затем сгенерировать набор соседей на основе сходства между пользователями.
Шаг 4: используйте следующее уравнение для прогнозирования рейтинга:

где Pu это точность активного пользователя u для целевого элемента i и K является соседним набором активного пользователя u.
