УДК 004.942
Применение параллельных архитектур вычислительных систем для расчета параметров движения транспортного средства
М. К. Кравченко, С. В. Кривошеев
Донецкий Национальный Технический университет, факультет компьютерных
наук и технологий, кафедра компьютерной инженерии.
E-mail: kravchenko_misha_1996@mail.ru
Аннотация
Кравченко М.К., Кривошеев С.В. Применение параллельных архитектур вычислительных систем для расчета параметров движения транспортного средства. В данной статье рассмотрены проблемы, связанные с автоматизацией движения транспортных средств. Определены способы ускорения вычислений, для расчетов параметров движения. Выполнен анализ современных параллельных вычислительных устройств и способы их применения.
Ключевые слова: параллельные вычислительные системы, CUDA, GPU,транспортное средство, анализ направления движения.
Актуальность темы
В наше время количество транспортных средств растет с большой скоростью. На глобальный уровень становятся проблемы составления маршрутов, анализ движения. Грамотно спланированный маршрут и автоматизация управления позволят избежать лишних затрат топлива, а соответственно и уменьшить вред экологии, свести к минимуму аварии и катастрофы [2]. Все больше различных институтов по всему миру развивает это направление. Большой проблемой остается скорость, с которой будут выполняться расчеты движения и анализ выбора маршрута. Каждую секунду на транспортное средство действуют внешние факторы, изменяется обстановка. Поэтому необходимо постоянно пересчитывать и анализировать большое количество данных. Использование параллельных вычислительных систем позволяет увеличить скорость расчетов, не прибегая к увеличению вычислительных мощностей процессора.
Цель статьи
Провести анализ современных параллельных вычислительных устройств и систем для работы с ними. Определить способы взаимодействия CPU и GPU. Оценить возможности применения параллельных вычислений для расчета параметров движения транспортного средства.
Обзор параллельных вычислительных систем
Сейчас практически любой гаджет имеет многоядерный процессор. Это дает возможность выполнять параллельные вычисления. Ядром называют часть процессора, которая выполняет один или несколько потоков команд. В простой многоядерной системе ядро выполняет один поток команд независимо от других ядер и имеет собственную кэш-память первого и второго уровней. В многоядерных системах с общей памятью каждое ядро имеет собственную кэш- память первого и общую память второго уровня, а ядро может выполнять несколько потоков команд.
Все большую популярность набирает вычисление на графических процессорах (GPU). Эти процессоры изначально создавались, как многоядерные, поскольку для обработки графики необходимо производить большое количество вычислений. Можно подумать, есть ли смысл использовать CPU, если графические процессоры производят вычисления гораздо быстрее. Но следует учитывать, что GPU являются SIMD системой (одиночный поток команд, множественный поток данных). То есть работают с большим количеством различных данных, выполняя при этом одинаковые команды над ними. Разница в структуре CPU и GPU (рис. 1) очевидна.
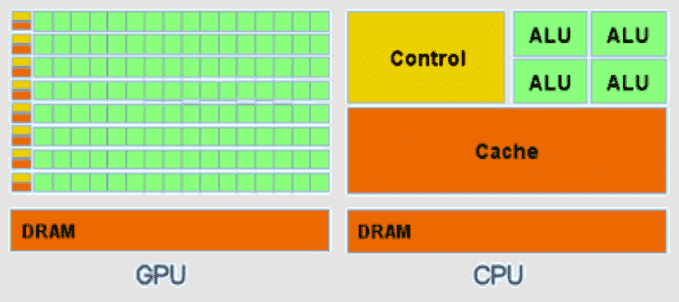
Рисунок 1 — Структура CPU и GPU
Простой способ понять разницу между GPU и CPU - сравнить то, как они выполняют задачи. CPU состоит из нескольких ядер, оптимизированных для последовательной обработки данных, в то время как GPU имеет тысячи более мелких ядер, созданных для выполнения нескольких задач одновременно [4].
Применение технологии CUDA
Для программирования GPU необходима определенная программно- аппаратная платформа. Компания NVIDIA предоставляет удобную платформу CUDA. Главным преимуществом которой, является ее бесплатность и простота использования (программирование производится на расширенном языке С). Технология CUDA позволяет задействовать любое АЛУ микросхемы [1].
Поскольку GPU ориентированы на обработку графики, то вычисление на данных процессорах необходимо выполнять, загружая данные в 128-битные структуры, которые будут выполняться на графическом конвейере. Технология CUDA скрывает работу графического конвейера и предоставляет более удобную работу программисту. Для выполнения на GPU нужно всего лишь перед участком кода на С указывать некоторую служебную информацию, которая указывает, что данный код необходимо выполнить на GPU. Обработка данных в приложения идет таким образом, что GPU обрабатывает части приложения, требующие большой вычислительной мощности, при этом остальная часть приложения выполняется на CPU. С точки зрения пользователя, приложение просто работает значительно быстрее [4].
Описание работы
Анализ направления движения транспортного средства (ТС) подразумевает наличие данных о местонахождении и окружающей обстановке (что впереди, сзади, по бокам). ТС имеет четко фиксированный набор вариантов продолжения движения: продолжить движение, уменьшить скорость, увеличить скорость, задний ход, повернуть вправо/влево.
Анализ можно разделить на два этапа:
1. Проверка, можно ли продолжить движение в данном направлении (нет ли впереди препятствия или неудовлетворяющей движению местности).
2. Выбор оптимального маршрута, если движение в том же направлении невозможно
Как первый, так и второй этап могут дать лишь относительный ответ, поскольку в действительности можно выполнить просчет на ограниченное число шагов, так как на каждом шаге анализа количество вычислений возрастает по геометрической прогрессии (рис. 2), а время на ответ ограничено допустимым порогом 100 мс [3].
Необходимо так же учитывать тот факт, что ТС не может мгновенно изменить курс. Скорость «реакции» на изменение положения рулевого механизма будет зависеть от массы ТС, его сцепления с поверхностью. Если отбросить второй этап и определять только, можно ли продолжать движение в том же направлении, то время ответа будет гораздо меньше. На каждом шаге будет анализироваться лишь одно состоянии (можно или нельзя перейти в эту позицию). Таким образом, нагрузка на вычисления уменьшиться в разы, что позволит производить вычисления для нескольких ТС одновременно.
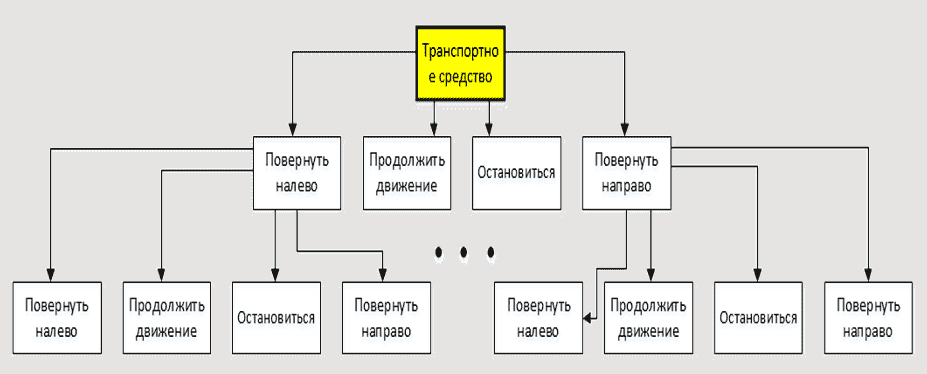
Рисунок 2 — Пример определения движения на два шага
Выводы
Определение направление дальнейшего движения транспортного средства требует значительных вычислительных мощностей. Использование параллельных вычислительных систем позволит выполнить расчет на большее количество шагов, что обеспечит более точные и правильный анализ дальнейшего движения.
Список литературы
1. Технология CUDA в примерах: введение в программирование графических процессоров; Пер. с англ. Слинкина А. А., научный редактор Боресков А. В. – М.: ДМК Пресс, 2013. – С. 17-21.
2. Кривошеев С.В. Исследование эффективности параллельных архитектур вычислительных систем для расчета параметров движения транспортного средства // Научные труды Донецкого национального технического университета. Выпуск № 1(10)-2(11). Серия «Проблемы моделирования и автоматизации проектирования». – Донецк, ДонНТУ, 2012. С. 207-214.
3. Eric Hansen, Terry Huntsberger and Les Elkins, Autonomous maritime navigation: developing autonomy skill sets for USVs, Proc. SPIE 6230, 62300U (2006).
4. Вычисления с ускорением на GPU [электронный ресурс] // NVIDIA Corporation: [сайт]. [2017]. URL: http://www.nvidia.com.ua/object/gpu-computing- ru.htm