Введение
Технологии баз данных (БД) в настоящее время используются практически во всех организациях. Все большую значимость приобретают процессы децентрализации, требующие создания приложений, доступ к которым осуществляется из различных географических мест. Увеличиваются требования к оперативности и достоверности информации. Задачи информационной интеграции БД и проектирования географически распределенных БД (РБД) являются наиболее актуальными для разработчиков программного обеспечения в течение почти трех десятилетий.
Большинство авторов под проектированием РБД понимают фрагментацию и размещение, т.е. разбиение БД на фрагменты и принятие решения о том, где будут храниться эти фрагменты. Однако проектирование схем фрагментации и размещения отношений реляционной базы данных основывается на информации о способах и методах использования РБД. Эти методы зависят от стратегии исполнения запросов, которая, в свою очередь, должна учитывать схемы фрагментации и размещения. Следовательно, проектирование схем фрагментации и размещения, а также определение стратегии исполнения запросов должны производиться одновременно. Таким образом, задачу проектирования РБД следует формулировать так: для заданной логической схемы БД, множества запросов и конфигурации вычислительной сети (ВС) описать схему фрагментации, схему размещения фрагментов и сформировать стратегии исполнения каждого запроса таким образом, чтобы оптимизировать целевую функцию.
Обзор генетических алгоритмов
Все три задачи, входящие в процесс проектирования РБД, NP-полные [1-2], т.е. с ростом размерности задач их вычислительная сложность растет экспоненциально. Во многих работах (например, [3-5]) отмечается, что для решения задач кластеризации и компоновки наиболее успешно применяются генетические алгоритмы.
В основу генетических алгоритмов положены идеи естественного отбора в биологических популяциях. В таких алгоритмах любое решение задачи синтеза представляется особями, которые характеризуются хромосомами. Хромосомы состоят из генов, значениями генов являются значения проектных параметров. Направленный перебор решений осуществляется с помощью генетических операторов выбора родителей, скрещивания, мутации, селекции, переупорядочения. Особи оцениваются с использованием функции приспособленности, определяющей, насколько хорошо особь подходит для решения данной задачи.
Помимо NP-полноты, задачи проектирования РБД обладают свойством взаимозависимости, т.е. входными данными для следующей задачи является решение предыдущей. Таким образом, для получения проекта РБД, близкого к оптимальному, целесообразно применять вложенные генетические алгоритмы.
Обзор разработанного генетического алгоритма
В соответствии с разработанным автором настоящей статьи методом для каждой хромосомы из внешнего алгоритма, который сформирован схемами фрагментации и размещения, запускается вложенный генетический алгоритм, предназначенный для формирования оптимальной стратегии исполнения запросов. Хромосомы вложенного алгоритма представляют собой решения, принимаемые при исполнении запроса. Комбинация хромосом из внешнего и вложенного алгоритмов полностью определяет решение поставленной задачи.
Сначала необходимо сформировать пространство поиска схем фрагментации, размещения и стратегии исполнения запросов, затем схемы должны быть представлены в виде хромосом. Пространство поиска схемы фрагментации формируется разбиением отношений на минимальные, не делимые далее, фрагменты. Для получения такого набора фрагментов для каждого отношения R на основании транзакций определяются набор минтермов предикатов и группы атрибутов. Разбиение на предикаты характеризует горизонтальную фрагментацию, а группы атрибутов – вертикальную.
Схема размещения кодируется бинарной матрицей D, строками которой являются узлы ВС, а столбцами – сформированный набор фрагментов. Единица в ячейке матрицы означает наличие определенного фрагмента в узле ВС. Для обеспечения полноты схемы размещения каждый фрагмент должен находиться хотя бы в одном узле (в каждом столбце должна быть хотя бы одна единица).
При исполнении реляционного запроса необходимо принять следующие решения.
- В какой последовательности производить операции соединения отношений.
- В каком узле производить операцию соединения.
- Применять ли технику semi-join (неполное соединение) [6] при соединении. Эта техника используется при соединении отношений, находящихся в разных узлах: пусть отношение A находится в узле 1 и отношение B находится в узле 2; принцип semi-join заключается в отправке на узел 2 столбцов отношения A, по которым осуществляется соединение, нахождение и отправка на узел 1 только тех записей из B, которые удовлетворяют условию соединения.
- Применять ли технику double-pipelined hash-join (двойное конвейерное хэш-соединение) [7] при соединении. Идея double-pipelined hash-join состоит в формировании двух хэш-таблиц Ha и Hb, после чего записи из A и B обрабатываются по одной в каждый момент времени. Для записи из A в таблице Hb ищутся соответствующие ей вложения, после чего запись из A и найденные записи из B возвращаются как результаты соединения, и запись из A помещается в хэш-таблицу Ha. Далее, берется запись из B и обрабатывается аналогичным образом.
- Какие узлы сети, содержащие необходимые фрагменты, использовать при внутриопе-раторном параллелизме.
Функцией приспособленности вложенного алгоритма является критерий оптимальности РБД. Для всех запросов производится расчет сокращения времени исполнения за счет применения внутриоператорного параллелизма и расчет коэффициентов использования ресурсов.
После останова вложенного алгоритма значение функции приспособленности лучшей хромосомы используется как оценка функции приспособленности внешнего алгоритма. Критерием останова алгоритмов является cхождение популяции.
Для оценки качества предложенного генетического алгоритма был проведен эксперимент, в котором решения, найденные с помощью этого алгоритма, сравнивались с оптимальными. Использовался следующий критерий эффективности БД (рис. 1).
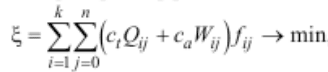
Рисунок 1 – Формула для подсчёта критерия эффективности БД
Где: k — количество узлов ВС; п — количество запросов; fij — частота возникновения i-го запроса в j-м узле; Qij — временной коэффициенту j-го запроса, порожденного в i-м узле; Wij — коэффициент использования ресурсов при обработке j-го запроса, порожденного в i-м узле; с и са — коэффициенты, определяющие приоритеты времени ответа и готовности транзакции, значения ct и са находятся в интервале [0...1] и определяются проектировщиком.
Временной коэффициент j-го запроса определяется как Qij=Tif/TiJ, т.е. равен отношению времени ответа на запрос, исполненный в РБД, к расчетному времени ответа на запрос, исполненный локально в узле i, при условии наличия в узле всех необходимых фрагментов. Коэффициент использования ресурсов Wij равен сумме коэффициентов использования центрального процессора и внешнего запоминающего устройства узлов, вовлеченных в операцию, и коэффициента использования сетевых ресурсов.
Эксперимент проводился для следующей вычислительной системы: ВС состоит из трех узлов, равноудаленных друг от друга; логическая схема БД имеет 2 отношения; производится 3 запроса на выборку и 2 запроса на обновление данных, которые формируют 4 группы атрибутов и 5 предикатов.
Выводы
По результатам измерений были определены оптимальные значения параметров генетических алгоритмов, приведенные на рисунке 2. Запуск алгоритма с другими значениями параметров ухудшает результат или увеличивает время работы.
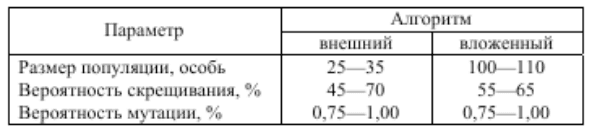
Рисунок 2 – Оптимальные значения параметров генетических алгоритмов
Схождение популяций, при котором 90 % лучших особей имеют расхождение по значению функции приспособленности не более, чем на 10 %, наблюдалось примерно спустя 500—700 поколений внешнего генетического алгоритма и 2500—3000 поколений вложенного алгоритма. Отметим, что для различных значений ct и ca удалось найти оптимальное решение, полученное полным перебором. Кроме этого, с увеличением пространства возможных решений (количества фрагментов и узлов ВС) время работы генетического алгоритма увеличивается квадратично, тогда как поиск оптимального решения путем полного перебора растет экспоненциально.
В дальнейшем необходимо исследовать зависимость скорости схождения популяций от параметров генетического алгоритма.
Разработанная прикладная программа, реализующая предложенный алгоритм, может быть положена в основу создания САПР распределенной базы данных.
Список использованной литературы
1. Ahmad I., Karlapalem K., Kwok Y.K. et al. Evolutionary algorithms for allocating data in distributed database systems // Distributed and Parallel Databases. 2002. Vol. 11, N 1. P. 5—32. 2. Apers P. M. G. Data allocation in distributed database systems // ACM Trans. on Database Systems. 1988. Vol. 13, N 3. P. 263—304. 3. Rho S., March S. T. Optimizing distributed join queries: A genetic algorithm approach // Annals of Operations Research. 1997. Vol. 71. P. 199—228. 4. Wang J.-C., Horng J.-T., Hsu Y.-M. et al. A genetic algorithm for set query optimization in distributed database systems // Proc. of the IEEE Intern. Conf. on Systems, Man and Cybernetics. Beijing, China. 1996. P. 1977—1982. 5. Норенков И. П. Эвристики и их комбинации в генетических методах дискретной оптимизации // Информационные технологии. 1999. № 1. С. 2—7. 6. Bernstein P. A., Goodman N., Wong E. et al. Query processing in a system for distributed databases (SDD-1) // ACM Trans. on Database Systems. 1981. Vol. 6, N 4. P. 602—625. 7. Wilschut A. N., Apers P. M. G. Dataflow query execution in a parallel main-memory environment // Distributed and Parallel Databases. 1993. Vol. 1, N 1. P. 103—128.