Обнаружение обмана по видео
Введение
Обман распространен в нашей повседневной жизни. Некоторая ложь безобидна, в то время как другая может иметь серьезные последствия и стать реальной угрозой для общества. Например, ложь в суде может повлиять на справедливость и освободить виновного подсудимого. Исходя их этого точное обнаружение обмана в ситуации с высокими ставками имеет решающее значение для личной и общественной безопасности
Способность людей обнаружить обман очень ограничена. В (Bond Jr and DePaulo 2006) сообщалось, что средняя точность обнаружения лжи без специальных приспособлений составляет 54%, что лишь немного лучше, чем вероятность. Для более точного выявления обмана были разработаны физиологические методы. Однако физиологические методы, такие как полиграф или более поздние функциональные методы, основанные на магнитно-резонансной томографии (МРТ), не всегда коррелируют с обманом (Farah et al. 2014). Кроме того, стоимость оборудования и открытый характер метода делают использование этих устройств ограниченным для реального обнаружения обмана.

В следующей работе осуществляется попытка нахождения поведенческих сигналов для обнаружения обмана (DePaulo et al. 2003). Эти сигналы представляют собой слабые следы поведения, которые трудно обнаружить неподготовленным людям. Например, согласно (Ekman et al. 1969; Ekman 2009), микро-выражения лица отражают эмоции, которые субъекты могут захотеть скрыть. Однако из-за различий между разными субъектами эти микровыражения чрезвычайно трудно обнаружить с помощью компьютерного зрения, особенно в естественных условиях.
Мотивированные этими наблюдениями, мы предлагаем использовать динамику движения для распознавания микро-выражений лица. Данная методика совпадает с психологическим пониманием (Duran et al. 2013), в котором авторы предлагают сосредоточиться на динамических сигнатурах движения, которые указывают на обман. Для этого мы разрабатываем двухуровневое представление объектов для захвата динамических сигнатур движения. Для представления объектов низкого уровня мы используем плотные траектории, которые представляют движение и изменения движения. Для представления на высоком уровне мы обучаем детекторы микроэкспрессии лица, используя функции низкого уровня, и используем их показатель достоверности в качестве функций высокого уровня. Эксперименты на 104 судебных видео в зале суда показывают эффективность и взаимодополняемость наших функций низкого и высокого уровня.
Обман — это сложное человеческое поведение, когда субъекты пытаются подавить свои ложные факты, от выражения лица до жестов, от того, как они разговаривают, к тому, что именно они говорят. Таким образом, надежный метод обнаружения обмана должен включать информацию из более чем одного способа. Исходя из мотивации предыдущей работы (Perez-Rosas et al. 2015; Jaiswal, Tabibu и Bajpai 2016), мы также включили функции из других модальностей, в частности, аудио и текста. Эти дополнительные условия улучшают AUC (площадь под кривой точности отлика, от англ. – Area under the precisionrecall curve) нашей автоматизированной системы на 5% до 0,877. При использовании естественных микро-выражения лица система дает 0,922 AUC, что на 9% лучше, чем в педыдущем случае. Мы также проводим исследования с целью анализа людей, насколько хорошо последние выполнят данную задачу: какие методы они используют и как они ведут себя, если доступна только одна из них.
Сопутствующие работы
Физиологические меры считаются полезными для обнаружения обмана в течение длительного времени. Полиграф измеряет физиологические показатели, такие как кровяное давление, частоту сердечных сокращений, проводимость кожи человека, которого допрашивают, но их достоверность сомнительна. Тепловидение может записывать тепловые диаграммы (Pavlidis, Eberhardt, and Levine 2002) и измерять кровоток тела (Buddharaju et al. 2005), но для этой технологии требуются дорогие тепловые камеры. Детекторы мозга, такие как функциональный МРТ, недавно были предложены для обнаружения обмана путем сканирования его активности и выявления областей, которые коррелируют с обманом. Хотя он достигает высокой точности (Kozel et al. 2005; Langleben и Moriarty 2013; Farah et al. 2014), важные вопросы, связанные с рабочим механизмом, надежностью и экспериментальными настройками, остаются открытыми исследовательскими проблемами (Langleben and Moriarty 2013; Farah et al. др. 2014). Кроме того, вышеупомянутые методы, основанные на физиологических мерах, являются открытыми и могут быть нарушены контр-подготовкой и поведением субъекта (Ganis et al. 2011).
Среди скрытых систем важную роль играют методы, основанные на компьютерном зрении. В ранних работах (Lu et al. 2005; Tsechpenakis et al. 2005) использовался анализ блобов для отслеживания движений головы и рук, которые использовались для классификации поведения человека на видео в трех различных поведенческих состояниях. Однако в этих методах использовались отдельные образцы изображений для обучения детекторов блобов, и поскольку база данных была небольшой, методы были склонны к переобучению и не распространялись на новых субъектов. Основываясь на исследованиях психологии Экманом (Ekman et al. 1969; Ekman 2009), что некоторые лицевые формы поведения являются непроизвольными и могут служить доказательством для обнаружения обмана, было разработано несколько автоматических систем, основанных на компьютерном зрении. Zhang et al. (Zhang et al. 2007) пытался выявить различия между симулированными выражениями лица и непроизвольными выражениями лица, идентифицируя индикаторы обмана, которые были определены группой конкретных единиц действия лица (Ekman and Friesen 1977). Однако этот метод требует, чтобы люди вручную маркировали лицевые ориентиры и вводили основные компоненты FAU, поэтому он не полностью автоматизирован. Кроме того, данный метод был протестирован только на статических изображениях, поэтому основные выражения мимики лица не были зафиксированы. (Michael et al. 2010) предложили новую функцию, называемую профилями движения, для расширения анализа головных и кистевых пятен с помощью микро-выражений лица. Хоть данный метод полностью автоматический, он в значительной степени зависит от характеристик локализации лицевых ориентиров, и экспериментальные условия очень ограничены. Для видео в естественных условиях этот метод локализации лицевого ориентира может быть ненадежным.
Эти ранние работы были в основном в медленных ситуациях. В последнее время исследователи стали уделять больше внимания обнаружению обмана с высокой долей, чтобы эксперименты стали ближе к реальной жизни. В (Perez-Rosas et al. 2015) был представлен новый набор данных, содержащий реальные пробные видео. В этой работе представлен мультимодальный подход к проблеме обнаружения обмана с высокой ставкой, но метод требует ручной маркировки человеческих микро-выражений. Кроме того, в наборе данных количество видео для разных испытаний сильно различается, что приводит к смещению результатов в сторону более длительных испытаний. В (Su и Levine 2016) авторы также собрали видео базу данных ситуаций с высокими ставками и вручную разработали множество признаков для различных частей лица. Опять же, вручную разработанные признаки требуют точного определения лицевых ориентиров. Кроме того, метод сегментировал каждое видео на несколько временных томов и предполагает, что все метки этих томов будут одинаковыми при обучении классификатора. Это может быть неправильно для случаев обмана, потому что доказательства обмана могут быть потеряны где-нибудь в видео.
Обманчивое поведение очень субъективное и варьируется у разных людей. Таким образом, обнаружение этих тонких микроподвижностей, например, микро-выражений лица само по себе является сложной проблемой. Кроме того, Duran et al. (Duran et al. 2013) предположил, что исследования должны сосредоточиться больше на динамике движения и структуре поведения. Замотивированные этим, мы напрямую описываем поведенческую динамику, не обнаруживая лицевые ориентиры, затем используем динамику поведения, чтобы выучить микро-выражения и обманчивое поведение. Мы также включаем простые словесные и звуковые признаки, как и другие мультимодальные подходы (Perez-Rosas et al. 2015; Jaiswal, Tabibu и Ba-jpai 2016), в общую скрытую автоматизированную систему.
Методы
Наша система автоматического обнаружения обмана состоит из 3 этапов: 1 - мультимодальное извлечение признаков; 2 - кодирование призакнов; 3 - классификация признаков (рис. 2).
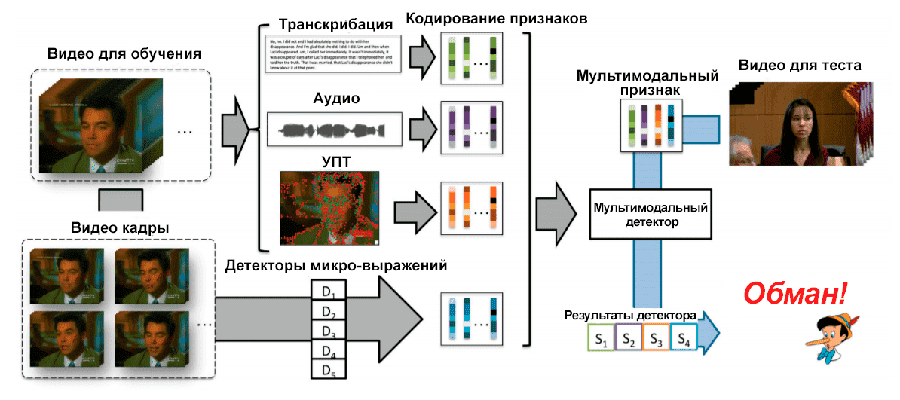
Мультимодальное извлечение признаков
Движение
Наш источник информации - видео, где человек делает правдивые или обманчивые заявления. Условия захвата видео не ограничены, поэтому лицо субъекта не всегда можно посмотреть спереди или по центру. Здесь мы используем призаки УПТ (Улучшенная плотная траектория) (Wang et al. 2016) благодаря их отличным характеристикам распознавания действий, особенно в естественных условиях.
УПТ вычисляет локальные соответствия признаков в последовательных кадрах и оценивает движение камеры, используя RANSAC. После отмены эффекта движения камеры выборки метода плотно показывают точки в нескольких пространственных масштабах, а затем отслеживают их через ограниченное количество кадров, чтобы предотвратить смещение. В пространственно-временном объеме вокруг траектории метод вычисляет HOG (гистограмма ориентированных градиентов), HOF (гистограмма оптического потока) (Laptev et al. 2008), MBH (гистограмма путевого движения) (Dalal, Triggs и Schmid 2006 ) и дескрипторы траектории. Мы обнаружили, что дескриптор MBH работает лучше, чем другие дескрипторы (например, HOG / HOF) для нашей задачи, потому что MBH вычисляет производные оптического потока и захватывает производные движения, а не информацию движения первого порядка. Поскольку мы хотим обнаруживать микро-выражения, дескриптор должен представлять изменения в движении, а не постоянное движение, которое фиксируется в MBH.
Аудио
Мы используем признаки MFCC (Mel-частоты Cepstral Coefficients) (Davis and Mermelstein 1980) в качестве наших аудио призаков. MFCC более 30 лет широко используется для задач автоматического распознавания речи. Мы используем следующую процедуру извлечения MFCC: сначала оцениваем периодограмму спектра мощности для каждого короткого кадра, затем преобразуем в шкалу частот Mel и, наконец, вычисляем DCT лог-спектра Mel. Затем для каждого видео у нас есть ряд признаков MFCC, соответствующих коротким интервалам. После того, как признаки MFCC извлечены, мы используем GMM (Gaussian Mixture Model), чтобы создать словарь аудио признаков для всех обучающих видео. Мы одинаково рассматриваем все аудио признаки и используем наш метод кодирования объектов для всей последовательности, аналогично (Campbell, Sturim и Reynolds 2006), потому что нас интересует не речевой контент (произнесенные слова), а скрытые сигналы обмана в области звука.
Транскрибация
Для каждого видео мы используем Glove (глобальные векторы для представления слов) (Pennington, Socher и Manning 2014) для кодирования всего набора слов в транскриптах видео в один вектор фиксированной длины. Glove — это бесконтрольный алгоритм обучения для представления слов с помощью векторов. Он обучается с использованием статистики совпадений слов. В результате представления вектора слова захватывают значимую семантическую структуру. По сравнению с другими текстовыми методами обнаружения обмана (Porter and Brinke 2010), Glove более широко применяется в естественных условиях.
Мы используем предварительно обученный корпус Wikipedia 2014+ Gigaword5, который содержит в общей сложности 6 миллиардов токенов. Каждое слово вложено в 300-мерное векторное пространство. Опять же, мы используем GMM для изучения словаря для векторов слов и используем кодировку вектора Фишера, описанную ниже, чтобы объединить все векторы слов в представление фиксированной длины для всего транскрипта.
Кодирование признаков
Так как количество признаков различно для каждого видео, мы используем векторную кодировку Фишера для агрегирования переменного числа объектов в вектор фиксированной длины. Векторы Фишера впервые были представлены в (Jaakkola and Haussler 1999) для объединения преимуществ порождающих и дискриминационных моделей и широко используются в других задачах компьютерного зрения, таких как классификация изображений (Perronnin and Dance 2007), распознавание действий (Wang et al. 2016) и поиск видео (Хан и др. 2017).
Векторное кодирование Фишера сначала строит K-компонентную модель GMM (μ, σ, w: i = 1, 2, ..., K) из обучающих данных, где μ, σ, w — среднее значение, диагональная ковариация и смешанные веса для i-го компонента соответственно. Учитывая набор функций {x, x, ..., x}, его вектор Фишера вычисляется как:
$$ \zeta_{\mu_{i}}=\frac{1}{T\sqrt{\omega_{i}}}\sum_{t=1}^{T} \gamma_{t}\left(i\right) \left(\frac{x_{t}-\mu_{i}}{\sigma_{i}}\right) $$
$$ \zeta_{\sigma_{i}}=\frac{1}{T\sqrt{\omega_{i}}}\sum_{t=1}^{T} \gamma_{t}\left(i\right) \left(\frac{\left(x_{t}-\mu_{i}\right)^{2}}{\sigma_{i}^{2}}-1\right) $$
где γ(i) - апостериорная вероятность. Затем всеРезультаты поиска ζμi и ζσi суммируются, чтобы сформировать вектор Фишера в 2DK-измерении, где D - размерность локального признака x.

Предсказание микро-выражений лица
Мультимодальные признаки, описанные выше, являются признаками низкого уровня. Здесь мы представляем высокоуровневые признаки, используемые для представления микро-выражений лица. Согласно (Ekman et al. 1969; Ekman 2009), микро-выражения лица играют важную роль в предсказании обманного поведения. Чтобы исследовать их эффективность, (Perez-Rosas et al. 2015) вручную аннотировали выражения лица и использовали двоичные особенности, полученные из основополагающих аннотаций истинности, для предсказания обмана. Они показали пять самых предсказательных микро-выражений: Нахмурившись, Брови поднимаются, Углы губ вверх, Губы выпуклые и Поворот головы в сторону. Образцы этих лицевых микровыражений показаны на рисунке 3.
Мы используем визуальные признаки низкого уровня для обучения детекторов микро-выражений, а затем используем прогнозируемые оценки детекторов микро-выражения в качестве признаков высокого уровня для прогнозирования обмана. Мы разделяем каждое видео в базе данных на короткие видеоклипы фиксированной длительности и помечаем эти клипы метками микро-выражения. Формально, учитывая обучающий набор видео V = {υ, υ, ..., υ}, разделив каждое видео на клипы, мы получаем обучающий набор C = {υij}. Набор аннотаций: L = {lij}, i ∈ [1, N] обозначает идентификатор видео, верхний индекс j ∈ [1, n] обозначает идентификатор клипа, n - количество клипов для видео i и продолжительность υij постоянная (4 секунды в нашей реализации). Размерность lij - количество микро-выражений. Затем мы обучаем набор классификаторов микро-выражений, используя клипы C, и применяем классификаторы к тестовым видеоклипам Č, чтобы сгенерировать прогнозируемый счет Ĺ = {ĺij}. Эти векторы оценки объединяются путем их усреднения по всем клипам в видео, чтобы получить вектор оценки видео.
Обнаружение обмана
Затем векторное кодирование Фишера низкоуровневых объектов и вектор оценки уровня видео используются для обучения четырех двоичных классификаторов обмана. Три из этих классификаторов основаны на визуальных, слуховых и текстовых каналах, для которых были построены GMM, а четвертый использует объединенные векторы оценок для детекторов микроэкспрессии. Обозначим оценку предсказания мультимодального вектора Фишера и функции микровыражения высокого уровня как {Smi}, i ∈ [1, 3] и S. Окончательный результат обмана S получается путем позднего слияния, определяемого как:
$$ S = \sum_{i} \alpha_{i}S_{m_{i}}+\alpha_{high}S_{high} ,$$
где α, α > 0 и Σi=14 α + α = 1. Значения α и α получены путем перекрестной проверки.

Эксперименты и результаты
Набор данных
Мы оцениваем наш подход автоматического обнаружения обмана на реальной базе данных (Perez-Rosas et al. 2015). Эта база данных содержит 121 видеоклип судебного заседания. Видео в этой пробной базе данных являются неограниченными видео из Интернета. Таким образом, нам необходимо обрабатывать различия в углах обзора человека, колебаниях качества видео и фоновых шумов, как показано на рисунке 4.
Мы используем подмножество 104 видео из пробной базы из 121 видео, в том числе 50 правдивых и 54 обманных видео. В экспериментах, показанных ниже, мы не сообщаем результаты, как описано в (Perez-Rosas et al. 2015). Вместо этого мы повторно реализуем метод (относящийся к естественным микро-выражениям) в наших обучаемых и тестовых выборках, чтобы избежать переобучения на личности, а не на обманных подсказках.
Набор данных содержит только 58 идентификаторов, что меньше количества видеороликов, и часто одна и та же идентификация либо обманчива, либо правдива. Это означает, что метод обнаружения обмана может просто переродиться в переоценку личности, если видео одного и того же человека были включены в разделение на тренинг и тестирование. Чтобы избежать этой проблемы, мы проводим 10-кратную перекрестную проверку с использованием идентификаторов вместо образцов видео для всех следующих экспериментов, т. Е. Никакие идентификаторы в тестовом наборе не принадлежат обучающему набору.
| Микро-выражения | IDT+FV |
|---|---|
| Брови нахмурены | 0.6437 |
| Брови подняты | 0.6633 |
| Уголки губ вверх | 0.4791 |
| Губы прикусаны | 0.7512 |
| Голова наклонена в бок | 0.7180 |
| Среднее | 0.6511 |
Предсказание микро-выражений
Сначала мы проанализируем производительность нашего модуля прогнозирования микро-выражений. Мы выбираем кадры для каждого видеоклипа, используя частоту кадров 15 кадров в секунду. Движущимися элементами являются улучшенные плотные траектории, которые представлены векторной кодировкой Fisher. Детекторы микроэкспрессии обучаются с использованием линейного ядра SVM с использованием LibSVM (Chang and Lin 2011). Результаты приведены в табл. 1, и мы сообщаем AUC (Площадь под кривой точного возврата). В следующих экспериментах мы покажем, что, хотя AUC 0,6511 не является высоким для обнаружения микро-выражений, высокоуровневые функции, представляющие вероятность микро-выражений, все же обеспечивают хорошую производительность при окончательной задаче обнаружения обмана. Мы считаем, что подходы, основанные на глубоком обучении, могли бы лучше прогнозировать микро-выражения; однако из-за ограниченного количества обучающих данных, доступных в этом наборе данных, обучение таким методам проблематично. Мы провели эксперимент с готовыми функциями CNN для классификации микровыражений, но их производительность была значительно хуже, чем у IDT.
Обнаружение обмана
Сейчас мы оцениваем нашу автоматизированную систему обнаружения обмана. Сначала мы протестируем четыре отдельные функции: IDT (улучшенная траектория Debse), высокоуровневые оценки микро-экспрессии, словесные функции и аудиофункции MFCC. Затем мы тестируем различные комбинации мультимодальных функций. Чтобы проверить надежность и надежность функций, в наших экспериментах мы используем несколько широко используемых двоичных классификаторов: линейный SVM, ядро SVM, наивный байесовский механизм, деревья решений, случайные леса, логистическая регрессия и Adaboost. Мы используем ядро с полиномами для ядра SVM, потому что оно работает лучше всего. Для наивного байесовского классификатора мы используем нормальные распределения и удаляем размеры объектов, которые имеют нулевую дисперсию перед подгонкой. Для логистической регрессии мы используем биномиальное распределение. В Случайном Лесу количество деревьев равно 50. В Adaboost мы используем деревья решений в качестве слабых учеников. Все эксперименты проводятся с использованием 10-кратной перекрестной проверки разных наборов признаков и классификаторов.Результаты, измеренные AUC, приведены в табл. 2. Первые 4 строки являются результатами одной модальности, а последние 4 строки - после позднего слияния мультимодальных функций. Каждый столбец соответствует одному типу классификатора. Мы видим, что самый высокий AUC (0,8773) после позднего слияния, который использует все модальные функции и линейный классификатор SVM. Эта производительность намного лучше, чем использование функций микровыражения Ground Truth (0.8325).
Производительность разных классификаторов
SVM и Random Forest работают лучше по сравнению с другими классификаторами, такими как Наивный Байес и Логистическая регрессия, потому что они являются дискриминационными. Один интересный вывод заключается в том, что разные классификаторы хороши в использовании разных модальностей. Например, мы видим, что линейный SVM лучше всего работает с функциями IDT, Random Forest лучше всего работает с высокоуровневыми функциями микровыражений, а Kernel SVM лучше всего работает с функциями MFCC. Однако когда мы объединяем мультимодальные функции с использованием позднего слияния, производительность разных классификаторов сходится.
Выполнение различных модальностей
Мы видим, что функции IDT получают AUC 0,7731. Хотя предлагаемые функции микроэкспрессии высокого уровня не могут точно предсказать микроэкспрессию, они помогают улучшить обнаружение обмана. Функции MFCC получают наивысший AUC с использованием единой модальности, показывая важность звуковых функций в задаче обнаружения обмана. Функция транскрипции получает наименьшую производительность, главным образом потому, что предварительно обученное представление вектора слов не охватывает основные сложные словесные сигналы обмана. Тем не менее, вся система по-прежнему извлекает выгоду из функций расшифровки после позднего слияния.
Анализ позднего слияния
Хотя производительность разных модальностей различна для каждого классификатора, общая производительность улучшается, когда мы комбинируем разные модальности. Объединение баллов классификатора, обученного по функциям IDT, с классификатором, обученным прогнозированию микроэкспрессии, помогает нам получить AUC 0,8347, который является характеристикой визуальной модальности. Таким образом, даже несмотря на то, что детекторы микровыражений обучаются с использованием функций IDT, низкоуровневые и высокоуровневые классификаторы дополняют друг друга. Другие методы, такие как текст и аудио, улучшают производительность системы на 4%.
Обнаружение обмана с помощью естественных микро-выражений
Поскольку высокоуровневой характеристикой является оценка предсказания обученных детекторов микро-экспрессии, один интересный вопрос заключается в том, как повлияет на производительность, если мы будем использовать функции микро-экспрессии Ground Truth, как в (Perez-Rosas et al. ´ 2015) , В следующем эксперименте мы используем функцию микровыражения GT в качестве базовой линии и тестируем, как производительность изменяется с другими модальностями функций. Таблица. 3 показывает результаты, измеренные AUC. Обратите внимание, что мы повторно запустили это исследование, потому что мы не используем одну и ту же личность в разделениях обучения и тестирования.
Из таблицы 2, мы видим, что производительность GTMicroExpression (Perez-Rosas et al. 2015) лучше, чем характеристики микроэкспрессии высокого уровня (что является доверительной оценкой классификатора микроэкспрессии). С добавлением функций ЧПТ наша система зрения улучшается более чем на 5% (0,8988 AUC). Это доказывает эффективность функций, основанных на движении. После позднего слияния с результатами функций стенограммы и MFCC производительность всей системы составляет 0,9221 AUC, что лучше, чем в предлагаемой полностью автоматизированной системе. Это говорит о том, что разработка более точных методов обнаружения микро-выражений является потенциальным направлением для улучшения обнаружения обмана в будущем.
| Признаки | L-SVM | K-SVM | NB | DT | RF | LR | Adaboost |
|---|---|---|---|---|---|---|---|
| УПТ | 0.7731 | 0.6374 | 0.5984 | 0.5895 | 0.5567 | 0.6425 | 0.6591 |
| Микро-выражение | 0.7502 | 0.7540 | 0.7629 | 0.7269 | 0.8064 | 0.7398 | 0.7507 |
| Транскрипции | 0.6457 | 0.4667 | 0.6625 | 00.5251 | 0.6172 | 0.5643 | 0.6416 |
| MFCC | 0.7694 | 0.8171 | 0.6726 | 0.4369 | 0.7393 | 0.6683 | 0.6900 |
| ЧПТ+Микро-выражения | 0.8347 | 0.7540 | 0.7629 | 0.7687 | 0.8184 | 0.7419 | 0.7507 |
| ЧПТ+Микро-выражения+Транскрипции | 0.8347 | 0.7540 | 0.7776 | 0.7777 | 0.8184 | 0.7419 | 0.7507 |
| ЧПТ+микро-выражения+MFCC | 0.8596 | 0.8233 | 0.7629 | 0.7687 | 0.8477 | 0.7894 | 0.7899 |
| Все модальности | 0.8773 | 0.8233 | 0.7776 | 0.7777 | 0.8477 | 0.7894 | 0.7899 |
| Признаки | L-SVM | K-SVM | NB | DT | RF | LR | Adaboost |
|---|---|---|---|---|---|---|---|
| GTMicroExpression | 0.7964 | 0.8102 | 0.8325 | 0.7731 | 0.8151 | 0.8275 | 0.8270 |
| GTMicroExpression+ЧПТ | 0.8456 | 0.8137 | 0.8468 | 0.7834 | 0.8205 | 0.8988 | 0.8270 |
| GTMicroExpression+ЧПТ+Транскрипция | 0.8594 | 0.8137 | 0.8923 | 0.8074 | 0.8205 | 0.8988 | 0.8270 |
| GTMicroExpression+ЧПТ+MFCC | 0.8969 | 0.9002 | 0.8668 | 0.7834 | 0.8319 | 0.9221 | 0.8320 |
| GTMicroExpression+Все модальности | 0.9065 | 0.9002 | 0.8905 | 0.8074 | 0.8731 | 0.9221 | 0.8321 |
Анализ микро-выражений
Мы исследуем эффективность каждого отдельного микро-выражения.
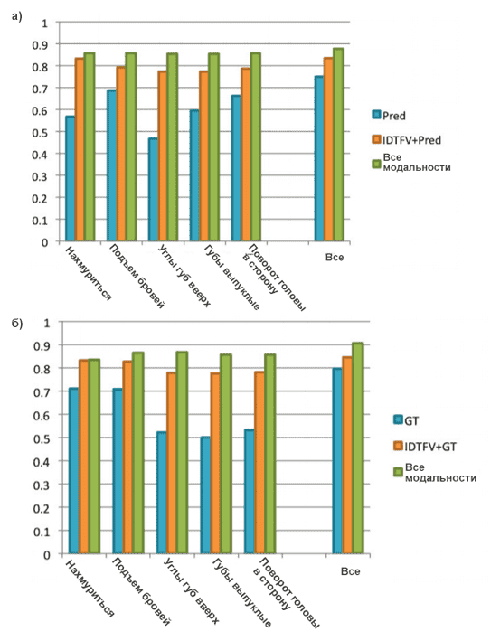
Для каждого микро-выражения мы тестируем производительность с помощью функции оценки высокого уровня с признаками движения низкого уровня и другими способами, показанными на рисунке 5. Производительность использования всех микро-выражений показана для сравнения. Мы используем линейный классификатор SVM в данном исследовании т.к. это был лучший индивидуальный классификатор. Из рисунка 5 мы видим, что Повышение бровей более эффективно, чем другие микро-выражения, как в предсказанных микровыражениях, так и в естественных микро-выражениях. Поворот головы также полезен при использовании предсказанных микровыражений, см. Рисунок 5а. Это отличается от результатов, полученных из естественных микро-выражений. С другой стороны, Нахмуриться работает лучше, если использовать признаки истинности относительно естественных, чем прогнозируемый признак, возможно, из-за того, что детектор Нахмуриться не является достаточно точным, как также предлагается в таблице 1.
Исследование пользователей
Чтобы проверить работоспособность человека при выполнении этой задачи, мы проводим исследования пользователей с использованием AMT (Amazon Mechanical Turk). Сначала мы просим 10 разных людей посмотреть каждое видео и решить, считают ли они информацию из него правдивой или нет. Каждому аннотатору назначается 5 видеороликов с 5 различными идентификаторами, чтобы гарантировать, что для прогнозирования обмана не будет смещения, характерного для идентификатора. Мы также записываем, были ли изображения, аудио или транскрипторы полезны для их решения. Обратите внимание, что здесь решение принимается с использованием всех модальностей. Процент голосов за видео используется как оценка для обмана. AUC для человеческого прогноза составляет 0,8102. Это показывает, что этот набор данных относительно проще, чем предыдущие исследования, где прогнозы людей по этой задаче были почти случайными. Тем не менее, даже в этом наборе данных не очевидно, является ли объект обманчивым или нет.
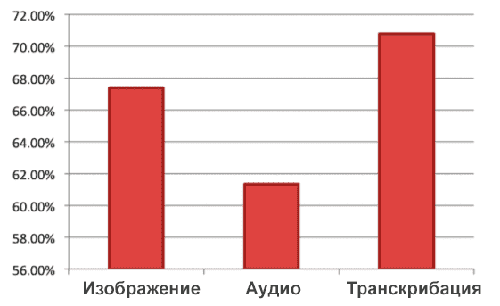
При принятии решения 67,4% времени пользователи полагаются на визуальные подсказки, 61,3% времени на звук и 70,7% времени на транскрипторы, как показано на рисунке 6. Обратите внимание, что для каждого видео люди могут выбрать несколько модальностей. Исходя из этих данных, мы замечаем, что люди склонны принимать решения на основе голосового контента, поскольку это признак семантического уровня. Только половина людей считает, что аудио помогает им принимать решения, в то время как в нашей системе признаки аудио очень эффективны. Поэтому мы провели еще одно исследование, в котором мы показываем только одну модальность за раз каждому отдельному испытуемому, потому что, когда несколько источников информации доступны одновременно, нелегко определить, какой источник был полезен для принятия окончательного решения.
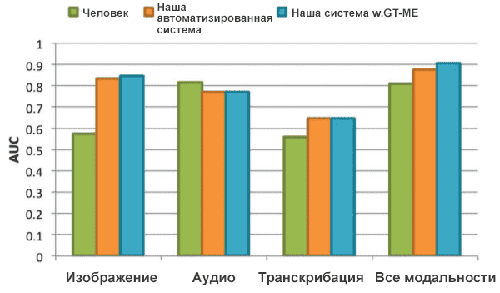
Чтобы проверить работоспособность каждого человека, мы просим 5 человек смотреть каждое видео без звука, 5 человек слушать аудио и 5 человек читать транскрипторы видео. Поэтому в каждом исследовании испытуемый имеет доступ только к одной модальности. Обратите внимание, что одному и тому же человеку снова не показывают никакой другой модальности из того же видео после показа одной модальности. Результаты показаны на рисунке 7 из нашей системы с использованием линейного классификатора SVM (Метод опорных векторов) в качестве классификатора наряду с человеческими характеристиками. Мы можем видеть, что с помощью только визуальной модальности существует огромный разрыв в производительности между человеческой деятельностью и нашей системой. Это показывает, что людям хоть и не хватает способности предсказать обманчивое поведение только с помощью визуальных сигналов, наша система, основанная на компьютерном зрении, значительно лучше. С другой стороны, при использовании только звука производительность человека так же высока, как и при доступности всех модальностей. Но когда предоставляются только транскрипторы видео, производительность значительно снижается как для людей, так и для нашей системы. Это говорит о том, что аудиоинформация играет важную роль для человека для предсказания обманного поведения, в то время как расшифровка не так полезна. При всех модальностях наша автоматизированная система примерно на 7% лучше по сравнению со средним человеком, в то время как наша система с истинными микро-выражениями лучше примерно на 11%.
Для будущей работы мы считаем, что лучшие модели для представления аудио будут перспективным направлением для повышения производительности нашей системы. Кроме того, проектирование гибридных компьютерных систем может быть очень важным для разработки надежной и точной системы обнаружения обмана.
Заключение
Была представлена система скрытого автоматического обнаружения обмана с использованием мультимодальной информации в видео. Мы показали, что обман может быть предсказан независимо от личности человека. Наша система зрения, которая использует визуальные признаки как высокого, так и низкого уровня, значительно лучше предсказывает обман по сравнению с людьми. Когда предоставляется дополнительная информация из аудио и транскриптов, предсказание обмана может быть дополнительно улучшено. Эти утверждения верны в отношении множества классификаторов, проверяющих надежность нашей системы. Чтобы понять, как люди предсказывают обман с использованием индивидуальных модальностей, были также представлены результаты такого исследования. Как часть будущей работы, мы полагаем, что сбор большего количества данных для этой задачи будет плодотворным, поскольку могут быть использованы более мощные методы глубокого обучения. Прогнозирование обмана в настройке с несколькими субъектами с использованием информации из видео было бы перспективным будущим направлением, т.к. система в будущем сможет понимать диалог между субъектами анализа, а затем прийти к логическому выводу.
Литература
- Bond Jr, C. F., and DePaulo, B. M. 2006. Accuracy of deception judgments. Personality and social psychology Review 10(3):214–234.
- Buddharaju, P.; Dowdall, J.; Tsiamyrtzis, P.; Shastri, D.; Pavlidis, I.; and Frank, M. 2005. Automatic thermal monitoring system (athemos) for deception detection. In Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on, volume 2, 1179– vol. IEEE
- Campbell, W. M.; Sturim, D. E.; and Reynolds, D. A. 2006. Support vector machines using gmm supervectors for speaker verification. IEEE signal processing letters 13(5):308–311.
- Chang, C.-C., and Lin, C.-J. 2011. Libsvm: a library for support vector machines. ACM transactions on intelligent systems and technology (TIST) 2(3):27.
- Dalal, N.; Triggs, B.; and Schmid, C. 2006. Human detection using oriented histograms of flow and appearance. In European conference on computer vision, 428–441. Springer.
- Davis, S., and Mermelstein, P. 1980. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE transactions on acoustics, speech, and signal processing 28(4):357–366
- DePaulo, B. M.; Lindsay, J. J.; Malone, B. E.; Muhlenbruck, L.; Charlton, K.; and Cooper, H. 2003. Cues to deception. Psychological bulletin 129(1):74.
- Duran, N. D.; Dale, R.; Kello, C. T.; Street, C. N.; and Richardson, D. C. 2013. Exploring the movement dynamics of deception. Frontiers in psychology 4.
- Ekman, P., and Friesen, W. V. 1977. Facial action coding system.
- Ekman, P.; Sorenson, E. R.; Friesen, W. V.; et al. 1969. Pan-cultural elements in facial displays of emotion. Science 164(3875):86–88.
- Ekman, P. 2009. Telling lies: Clues to deceit in the marketplace, politics, and marriage (revised edition). WW Norton & Company
- Farah, M. J.; Hutchinson, J. B.; Phelps, E. A.; and Wagner, A. D. 2014. Functional mri-based lie detection: scientific and societal challenges. Nature reviews. Neuroscience 15(2):123.
- Ganis, G.; Rosenfeld, J. P.; Meixner, J.; Kievit, R. A.; and Schendan, H. E. 2011. Lying in the scanner: covert countermeasures disrupt deception detection by functional magnetic resonance imaging. Neuroimage 55(1):312–319.
- Grill-Spector, K.; Kushnir, T.; Edelman, S.; Itzchak, Y.; and Malach, R. 1998. Cue-invariant activation in object-related areas of the human occipital lobe. Neuron 21(1):191–202.
- Han, X.; Singh, B.; Morariu, V.; and Davis, L. S. 2017. Vrfp: On-the-fly video retrieval using web images and fast fisher vector products. IEEE Transactions on Multimedia.
- Jaakkola, T., and Haussler, D. 1999. Exploiting generative models in discriminative classifiers. In Advances in neural information processing systems, 487–493.
- Jaiswal, M.; Tabibu, S.; and Bajpai, R. 2016. The truth and nothing but the truth: Multimodal analysis for deception detection. In Data Mining Workshops (ICDMW), 2016 IEEE 16th International Conference on, 938–943. IEEE.
- Kozel, F. A.; Johnson, K. A.; Mu, Q.; Grenesko, E. L.; Laken, S. J.; and George, M. S. 2005. Detecting deception using functional magnetic resonance imaging. Biological psychiatry 58(8):605–613.
- Langleben, D. D., and Moriarty, J. C. 2013. Using brain imaging for lie detection: Where science, law, and policy collide. Psychology, Public Policy, and Law 19(2):222.
- Laptev, I.; Marszalek, M.; Schmid, C.; and Rozenfeld, B. 2008. Learning realistic human actions from movies. In Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on, 1–8. IEEE.
- Lu, S.; Tsechpenakis, G.; Metaxas, D. N.; Jensen, M. L.; and Kruse, J. 2005. Blob analysis of the head and hands: A method for deception detection. In System Sciences, 2005. HICSS’05. Proceedings of the 38th Annual Hawaii International Conference on, 20c–20c. IEEE.
- Michael, N.; Dilsizian, M.; Metaxas, D.; and Burgoon, J. K. 2010. Motion profiles for deception detection using visual cues. In European Conference on Computer Vision, 462– 475. Springer.
- Pavlidis, I.; Eberhardt, N. L.; and Levine, J. A. 2002. Human behaviour: Seeing through the face of deception. Nature 415(6867):35–35.
- Pennington, J.; Socher, R.; and Manning, C. D. 2014. Glove: Global vectors for word representation. In EMNLP, volume 14, 1532–1543.
- Perez-Rosas, V.; Abouelenien, M.; Mihalcea, R.; and Burzo, ´ M. 2015. Deception detection using real-life trial data. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, 59–66. ACM.
- Perronnin, F., and Dance, C. 2007. Fisher kernels on visual vocabularies for image categorization. In Computer Vision and Pattern Recognition, 2007. CVPR’07. IEEE Conference on, 1–8. IEEE.
- Porter, S., and Brinke, L. 2010. The truth about lies: What works in detecting high-stakes deception? Legal and criminological Psychology 15(1):57–75.
- Su, L., and Levine, M. 2016. Does lie to me lie to you? an evaluation of facial clues to high-stakes deception. Computer Vision and Image Understanding 147:52–68.
- Tsechpenakis, G.; Metaxas, D.; Adkins, M.; Kruse, J.; Burgoon, J. K.; Jensen, M. L.; Meservy, T.; Twitchell, D. P.; Deokar, A.; and Nunamaker, J. F. 2005. Hmm-based deception recognition from visual cues. In Multimedia and Expo, 2005. ICME 2005. IEEE International Conference on, 824– 827. IEEE.
- Wang, H.; Oneata, D.; Verbeek, J.; and Schmid, C. 2016. A robust and efficient video representation for action recognition. International Journal of Computer Vision 119(3):219– 238.
- Zhang, Z.; Singh, V.; Slowe, T. E.; Tulyakov, S.; and Govindaraju, V. 2007. Real-time automatic deceit detection from involuntary facial expressions. In Computer Vision and Pattern Recognition, 2007. CVPR’07. IEEE Conference on, 1– 6. IEEE.