
Реферат
Вступ
Кількість графічної інформації, особливо, тієї що створюється користувачами інтернету безперервно росте. Це пов'язано з широким розповсюдженням мобільних пристроїв, оснащених високоякісними цифровими камерами, і зростанням популярності сервісів публікації і розповсюдження фотографій. За період з 2013 по 2017 роки кількість створюваних щорічно фотографій зросла приблизно в два рази і склала 1.2 трильйони [1]. Загальна кількість цифрових фотографій, збережених людством, станом на 2017 р. оцінюється в 4.7 трильйона. Не виникає сумнівів що це число буде рости.
Пошук в такому великому масиві інформації — складне завдання, що вимагає розробки ефективних алгоритмів індексування і пошуку, разом зі створенням продуктивних програмних систем, що реалізують ці алгоритми. На сьогодні, в комерційних системах пошуку графічних файлів ключову роль відіграє метаінформація (опис, геотегінг, контекст використання та ін.), яка може бути відсутня або мати недостатню якість. З цієї причини актуальним є розробка систем, що здійснюють пошук графічних файлів за інформацією, що міститься безпосередньо в них.
Цілі і задачі дослідження, плановані результати
Метою дослідження є розробка алгоритму пошуку зображень за змістом, що враховує переваги і недоліки існуючих підходів, а також розробка його програмної моделі.
Програмна модель, що розробляється в рамках написання магістерської дисертації, являє собою інформаційну пошукову систему, яка здійснює пошук за зразком, тобто в якості запиту користувача виступає зображення, а результатом пошуку є графічні файли, схожих із запитом.
Основними задачами дослідження є:
- дослідження існуючих підходів до здійснення пошуку, особливостей цього процесу для графічної інформації;
- аналіз існуючих методів і алгоритмів побудови індексу і пошуку графічної інформації, визначення переваг та недоліків цих методів і алгоритмів;
- розробка архітектури інформаційної пошукової системи;
- реалізація програмної моделі інформаційної пошукової системи згідно з розробленою архітектурою;
- розробка графічної бази даних тестових прикладів для подальшої оцінки якості пошуку;
- розробка алгоритму пошуку зображень в графічній БД, його реалізація і порівняння ефективності з існуючими алгоритмами;
- оптимізація і тестування архітектури, алгоритму, його параметрів і програмної моделі.
В якості предметної області для вирішення задачі пошуку був обран пошук зображень архітектурних об'єктів.
З метою апробації результатів дослідження планується участь в науково-технічних конференціях.
Стаття Квантування колірного простору в контексті вирішення завдання пошуку зображень за змістом
[2] була представлена на II науково-практичній конференції Програмна інженерія: методи і технології інформаційно-вичислювальних систем
(ПІІВС-2018). У ній описуються існуючі методи і алгоритми пошуку зображень в графічних БД.
Огляд досліджень і розробок
Методи функціонування систем пошуку зображень у вмісті (CBIR-систем) активно досліджуются як з теоретичної точки зору (розробка і оцінка ефективності методів виділення ознак, побудови індексу, здійснення пошуку), так і з практичної (розробка програмних моделей, вибір структури і алгоритмів функціонування баз даних, виділення підзадач алгоритмів для їх реалізації з використанням паралельних і розподілених обчислювальних систем).
Огляд міжнародних джерел
Першою комерційною системою, що використовує методи пошуку зображень є QBIC, опис якої представлено в [3]. У цій публікації описується загальна структура CBIR-системи, пропонуються три види ознак, за якими будується індекс: ознаки, засновані на кольорах пікселів; ознаки, засновані на текстурних характеристиках, і ознаки, для побудови яких використовується інформація про форми зображених об'єктів.
Ці три підходи до формування вектора ознак довгий час поліпшувалися і удосконалювалися. Наприклад, в [4] описується використання багатовимірних гістограм ознак (кольорів, щільності границь, текстурних характеристик, величина градієнта і ін.), що призвело до збільшення продуктивності пошуку. Методи, що використовують гістограми, засновані на побудові гістограми ознак (наприклад кольору) по усім точкам графічного файлу або по їх підмножині. Схожість зображень, в цьому разі, визначається як відстань між ними в просторі гістограм. Для обчислення схожості може застосовуватися ряд метрик, наприклад евклидов або хі-квадрат, або ж більш спеціалізовані метрики, орієнтовані на роботу саме з гістограмами [5].
У той час як колірні характеристики використовують інформацію про колір в кожній точці зображення, для побудови текстурних ознак розглядаються околі точок [6].
Інший підхід до виділення вектора ознак з'явився з появою алгоритмів обчислення локальних дескрипторів. Першим з таких дескрипторів став SIFT, запропонований в [7]. Ідеєю цього класу методів є обчислення деякого вектора ознак для кожної з ключових точок. Елементом цього вектора можуть бути дійсні числа або булеві значення (у цому випадку дескриптор називають бінарним). Визначення ключових точок здійснюється по їх окілах. Передбачається, що при спотворенні зображення (перспективні спотворення, Афінні перетворення, зміни освітлення та ін.) будуть виділено та саме, або близька до тієї же, множина ключових точок.
SIFT функціонує в декілька етапів. Спочатку обчислюється функція різниці зображень зі застосуванням фільтра Гаусса. Цей етап проводиться для зображень різного розміру з метою досягнення інваріантності до масштабу. Потім знаходяться екстремуми цієї функції, які і є ключовими точками. З кожної з ключових точок асоціюється її орієнтація, за значеннями пікселів в її околі будується вектор ознак. Асоціювання орієнтації з точкою дозволяє досягти інваріантності SIFT до повороту.
SIFT та інші локальні дескриптори використовуються для багатьох задач, таких як зіставлення зображень, розпізнавання образів і, в тому числі, пошук зображень за вмісті. В роботі [8] описується використання SIFT для побудови CBIR-системи. У цій статті пропонується використання функції Earth Mover's Distance для обчислення відстані між векторами ознак.
Незабаром після появи SIFT були розроблені і інші локальні дескриптори, що відрізняються алгоритмом виділення ключових точок і генерації вектора по їх околах. До них відносяться SURF, KAZE, AKAZE, ORB, BRISK та ін. В роботі [9] представлено короткий опис їх функціонування і наводиться кількісна оцінка їх продуктивності для завдання зіставлення зображень. Згідно з представленими результатами, найбільшу ефективність, серед розглянутих, має ORB [10] — бінарний дескриптор, який використовує алгоритм виділення ключових точок FAST і модифікацію дескриптора BRIEF, що обчислює інваріантні до повороту бінарні дескриптори (рисунок 1).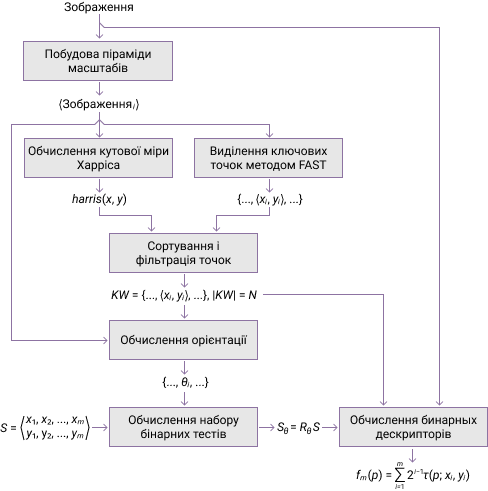
ORB може застосовиватися для вирішення задачі пошуку, про що свідчать результати, отримані в [11]. У цій роботі використовується підхід мішок слів
, поширений в системах пошуку тексту, для генерації вектора — опису всього зображення. У зв'язку з великою розмірністю дескриптора ORB (256 біт) і великою кількістю ключових точок, зображення неможливо описати в формі множини дескрипторів. Замість цього будується модель мішок слів
(bag of words) [12] (в контексті пошуку графічної інформації її іноді називають мішок візуальних слів
(bag of visual words) або мішок ознак
(bag of features)). Проводиться кластеризация всіх дескрипторів і будується гістограма кількості дескрипторів в кожному кластері. Ця гістограма потім може бути порівняна з іншими гістограмами будь-яким методом.
Останнім часом широкого поширення набуло використання штучних нейронних мереж при вирішенні задачі обробки та класифікації зображень. Про їх ефективність можна судити за результатами проведеного компанією Google весною 2019 року конкурсу, присвяченого пошуку зображень в графічних базах даних [13]. Згідно публікацій команд-учасників, які посіли призові місця [14; 15], ними застосовувалися комбінації з декількох моделей згорткових нейронних мереж для обчислення вектора ознак. Недоліком нейросетевого підходу є необхідність в наявності великої навчальної бази даних і великих витрат обчислювальних ресурсів.
При вирішенні задачі пошуку, дослідники часто використовують методи попередньої обробки зображень, зокрема, їх сегментації. В роботі [16] продемонстрована ефективність етапу розбиття зображення на фіксовані області з нечіткими границями при вирішенні завдання пошуку. У більш пізній публікації [17] пропонується алгоритм генерації вектора ознак, елементами якого є статистичні моменти значень кольорів областей зображення. Області, при цьому, виділяються динамічно, алгоритмом k-середніх.
Крім k-середніх існують і інші алгоритми сегментації: алгоритм водорозділу [18], Felzenszwalb [19], SLIC [20] та інші. Ці алгоритми використовуються для сегментації довільних зображень. Також існують і спеціалізовані алгоритми. Приклад такого алгоритму наведено в публікації [21]. У цій статті автори описують свій алгоритм сегментації фасадів будівель. Він відновлює перспективні спотворення, присутні на фотографії, а затім, аналізує значення сум градієнтів кольорів в точках кожного з стовпців пікселів, що дозволяє виділити вертикальні лінії зміни будівель, тобто відокремити зображення фасаду одного будинку від іншого.
Огляд національних джерел
Алгоритми і методи пошуку зображень за змістом також розглядаються дослідниками з України і Росії, проте публікацій на цю тему значно менше ніж публікацій англійською мовою.
Однією з таких публікацій є робота [22], що описує процес пошуку зображень серед пов'язаних графічних об'єктів. Замість традиційного підходу — сегментації всіх зображень на множину непересічних кластерів, в цій публікації пропонується формування гіперграфу, вузлами якого є зображення. Під гіперграфом розуміється особливий вид графа, ребра якого можуть з'єднувати відразу декілька елементів — кожне гіперребро задається деякою непустою підмножиною множини вершин графа. Всі вершини, що належать одному гіперребру вважаються релевантними для пошукової системи.
Також варто відзначити публікацію [23], в якій пропонується використання попереднього етапу сегментації зображення на прямокутні ділянки з урахуванням обсягу поверхні в просторі інтенсивності. Після цього ділянки об'єднуються в кластери які і додаються в індекс.
Огляд локальних джерел
Тема пошуку зображень за змістом також розглянута в роботах магістрів і працівників Донецького національного технічного університету.
Серед робот магістров ДонНТУ, що були опубліковані на їх особистих сайтах, можно виділити роботи Похиля М.Ю. (випуск 2008 р.), хто розглядає традиційні підходи до розробки CBIR-систем; Тележкіна Д.В. (випуск 2007 р.), хто здійснює постановку задачі пошуку, процес виявлення ознак зображення. Лук'янов С.В. (випуск 2005 р.) розглядає проблему оцінки якості функціонування інформаційної пошукової системи, яка працює в графічній БД.
Також, магістри ДонНТУ Савченко Д.А. (випуск 2010 р.), Комаричев М.Е. (випуск 2012 р.) и Михайлць В.В. (випуск 2007 р.) працювали над магістерськими дисертаціями на теми, які пов'язані з сегментацією зображень, що є кроком деяких методів пошуку.
Окрім работ магістрів, в ДонНТУ публиковалися і роботи працівників университету на тему пошуку зображень. Зокрема, в публікації [24] для пошуку зображень здйснюється побудова гісограмних ознак, що використовують кольори пікселів, і здійснюється кластерізація. В публікації [25] описується метод зменьшення кількості результатів пошуку шляхом використання математичного апарату мультимножин.
Варто відзначити цілий ряд публікацій авторів Башкова Е.А., Вовк О.Л. і Костюкової Н.С., присвячених питанням пошуку зображень в графічних базах даних. У число цих робіт входить монографія Пошук зображень за змістом в графічних базах даних
[26].
Архітектура системи пошуку зображень за змістом
Робота більшості сучасних систем пошуку зображень за змістом складає дві стадії обчислень. Перша стадія проходить в режимі офлайн
, тобто до того моменту, коли система зможе відповідати на запити користувачів. На цьому етапі відбувається обробка бази даних зображень, побудова індексу. На другій стадії система відповідає на запити користувача. Вона обробляє зображення-зразок, знаходить відповідні запиту зображення в базі даних і формує пошукову видачу сортуючи результати пошуку по релевантності.
Схема роботи типової системи пошуку зображень [27] показана на рисунке 2.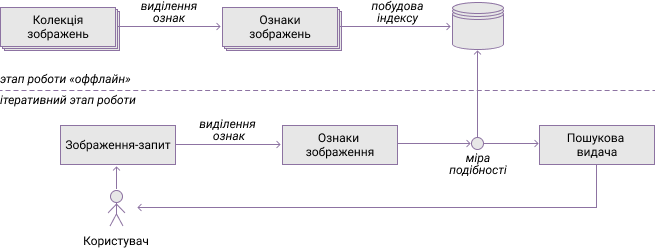
На етапі роботи оффлайн
відбувається виділення ознак кожного зображення колекції. Ці ознаки мають значно менший розмір у порівнянні з вихідним зображенням, що спрощує пошук. За допомогою векторів ознак виконується побудова індексу. Для цього може бути використані k-мірні дерева [28], хеш-функції [29], особливі форми інвертованого індексу [30] або інші методи.
Аналогічний процес здійснюється і на етапі обробки користувальницького запиту: відбувається виділення ознак з запиту і виконується пошук схожих зображень в індексі. Для визначення схожості використовується деяка функція відстані — міра подібності.
Для реалізації програмної моделі описаної вище архітектури пошукової системи при написанні магістерської дисертації буде використана мікросервісная архітектура [31]. Відповідно до цього підходу, програмна система розбивається на множину компонентів обмеженого функціонального призначення і з точно визначеним інтерфейсом. Кожен з цих компонентів може виконуватися як в межах однієї обчислювальної системи, так і на різних системах, об'єднаних комп'ютерною мережею.
Компоненти в мікросервісній архітектурі взаємодіють між собою засобами IPC стека TCP/IP безпосередньо, наприклад по HTTP, або за допомогою брокера повідомлень.
Перевагами мікросервісной архітектури є проста горизонтальна масштабованість (кількість запущених екземплярів компонентів може динамічно змінюватися в залежності від необхідного навантаження) і відмовостійкість (в разі критичної несправності компонента він може бути зупинений і перезапущений автоматично; необроблені повідомлення будуть повторно відправлені на обробку). Мікросервісная архітектура була успішно застосована при створенні високонавантажених систем обробки відеоінформації та зображень [32].
На рисунке 3 показані компоненти запропонованої архітектури і їх взаємодія. Анімація демонструє процес обробки пошукового запиту та інформацію, що передається між компонентами. Передбачається, що запит раніше системою не оброблявся і його результати не були збережені в кеш.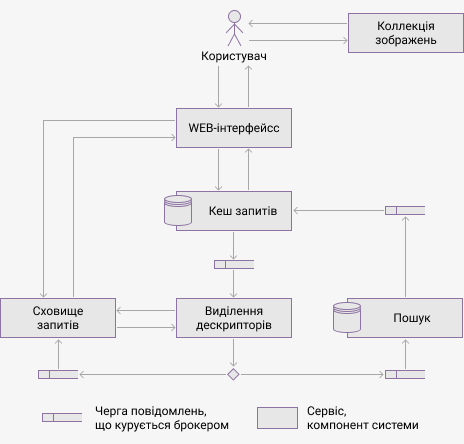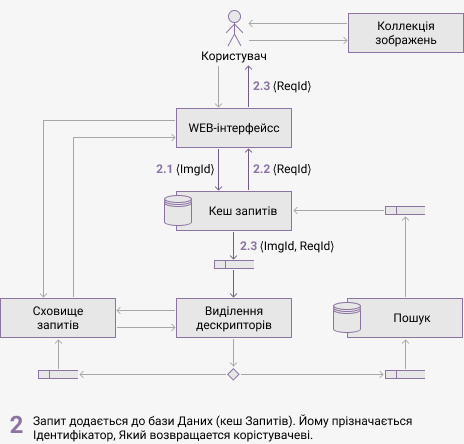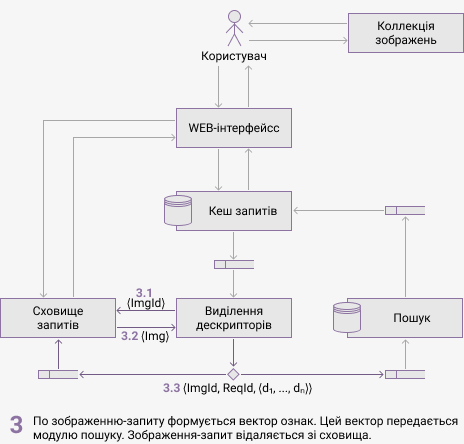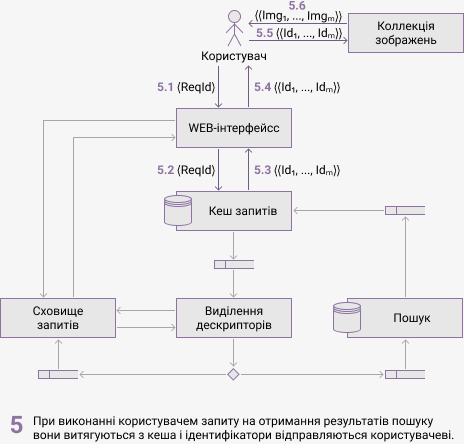
(анимація, затримка 3 с., 6 кадрів, 5 повторень, 81,6 КБ)
Компонентами системи являються:
- сховище зображень — база даних графічних файлів, які можна отримати за їх ідентифікаторами по протоколу HTTP;
- Web-інтерфейс — графічний користувальницький інтерфейс системи, який дозволяє користувачеві виконувати запити і переглядати результати пошуку;
- кеш запросів — база даних і інтерфейс до неї, яка зберігає ідентифікатори запитів і результати пошуку, в разі якщо вони були отримані;
- сховище зображень — база даних, яка тимчасово зберігає зображення, відправлені користувачем для пошуку;
- виділення дескріпторів — підсистема, що віконує виділення вектору ознаків;
- пошук — підсистема, що виконує запити до бази даних векторів ознак, організовані за принципом MapReduce.
Для реалізації описаної архітектури були обрані таке програмне забеспечення: Docker для контейнеризації компонентів, керування їх життєвим циклом і організації взаємодії; RabbitMQ в якості брокера повідомлень; MongoDB як нереляційна база даних для зображень, кеша і векторів ознак.
Висновки
Пошук зображень за вмісом є складною і актуальною задачею. Її складність пов'язана з труднощами формалізації вимог для системи, що забезпечує мінімізацію семантичного розриву
- різниці в тому, як схожість двох зображень сприймає людина і автоматизована система.
При написанні магістерської дисертації буде розроблена і реалізована інформаційна пошукова система, що здійснює пошук зображень в графічній базі даних за зразком. Будуть розглянуті питання компактного представлення інформації, що міститься в зображеннях колекції і в призначеному для користувача запиті, питання побудови індексу, що забезпечує продуктивний пошук у великій колекції.
Література
- Erric Perret. Here’s How Many Digital Photos Will Be Taken in 2017 [Электронный ресурс]. — URL: https://focus.mylio.com/tech-today/heres-how-many-digital-photos-will-be-taken-in-2017-repost-oct (дата обращения: 04.11.2019).
- Полетаев В. А. Квантование цветового пространства в контексте решения задачи поиска изображений по содержанию / В. А. Полетаев, И. А. Коломойцева // Программная инженерия: методы и технологии разработки информационно-вычислительных систем (ПИИВС-2018): сборник научных трудов II научно-практической конференции (студенческая секция), Том 2 / Донец. национал. техн. ун-т; — Донецк, 2017. — С. 96–101.
- The QBIC Project: Querying Images by Content Using Color, Texture, and Shape. The QBIC Project / T.J.W.I.R. Center [et al.]. — IBM Thomas J. Watson Research Division, 1993. — 20 p.
- Pass G. Comparing images using joint histograms / G. Pass, R. Zabih // Multimedia Systems. — 1999. — Vol. 7. — № 3. — P.—234–240.
- A Comparison on Histogram Based Image Matching Methods / W. Jia [и др.] // 2006 IEEE International Conference on Video and Signal Based Surveillance. — Sydney, Australia, 2006.
- A comparative study of texture measures with classification based on feature distributions / M. Pietikainen [и др.] // Pattern Recognition. — 1996. — Т. 29. — С. 51–59.
- Lowe D. G. Distinctive Image Features from Scale-Invariant Keypoints / D. G. Lowe // International Journal of Computer Vision. — 2004. — Vol. 60. — № 2. — P.—91–110.
- Jurandy Almeida. SIFT applied to CBIR / Jurandy Almeida, Ricardo da S Torres, Siome Goldenstein // Revista de Sistemas de Informacao. — 2009. — P.—41–48.
- Tareen S.A.K. A comparative analysis of SIFT, SURF, KAZE, AKAZE, ORB, and BRISK / S.A.K. Tareen, Z. Saleem. — 2018.
- ORB: An efficient alternative to SIFT or SURF / E. Rublee [et al.] // 2011 International Conference on Computer Vision 2011 IEEE International Conference on Computer Vision (ICCV). — Barcelona, Spain: IEEE, 2011. — ORB.
- Ma L. Fast Retrieval on Remote Sensing Imagery Based On ORB Feature / L. Ma, B. Jiang, Z. Xu // International Journal of Management and Applied Science. — 2018. — Vol. 4. — № 1. — P.—4.
- O’Hara S. Introduction to the Bag of Features Paradigm for Image Classification and Retrieval / S. O’Hara, B. Draper. — 2011.
- Google Landmark Recognition 2019 // Kaggle [Электронный ресурс]. — URL: https://kaggle.com/c/landmark-recognition-2019 (дата обращения: 04.11.2019).
- Ozaki K. Large-scale Landmark Retrieval/Recognition under a Noisy and Diverse Dataset / K. Ozaki, S. Yokoo // arXiv:1906.04087 [cs]. — 2019.
- 2nd Place and 2nd Place Solution to Kaggle Landmark Recognition andRetrieval Competition 2019 / K. Chen [и др.] // arXiv:1906.03990 [cs]. — 2019.
- Stricker M. Spectral covariance and fuzzy regions for image indexing / M. Stricker, A. Dimai // Machine Vision and Applications. — 1997. — Vol. 10. — № 2. — P.—66–73.
- Using Image Segmentation in Content Based Image Retrieval Method / M. Ouhda [и др.] // Lecture Notes in Networks and Systems. — 2018. — С. 179–195.
- Kaur A. Image Segmentation Using Watershed Transform / A. Kaur // International Journal of Soft Computing and Engineerin. — 2014. — Vol. 4. — № 1. — P.—4.
- Felzenszwalb P. F. Efficient Graph-Based Image Segmentation / P. F. Felzenszwalb, D. P. Huttenlocher // International Journal of Computer Vision. — 2004. — Vol. 59. — № 2. — P.—167–181.
- SLIC Superpixels Compared to State-of-the-Art Superpixel Methods / R. Achanta [et al.] // IEEE Transactions on Pattern Analysis and Machine Intelligence. — 2012. — Vol. 34. — № 11. — P.—2274–2282.
- Hernandez J. Morphological segmentation of building façade images / J. Hernandez, B. Marcotegui // 2009 16th IEEE International Conference on Image Processing (ICIP) 2009 16th IEEE International Conference on Image Processing (ICIP 2009). — Cairo: IEEE, 2009. — P.—4029–4032.
- Воробжанский Н. Н. Алгоритмы поиска изображений по содержанию с использованием нечеткого гиперграфа: Системный анализ и информационные технологии / Н. Н. Воробжанский // Вестник ВГУ. — 2016. — № 2. — С. 85–91.
- Р. Мельник. Пошук образів за індексами кластерів фрагментів зображень / Р. Мельник, Ю. Каличак // Вісник Національного університету
Львівська політехніка
. — 2011. — № 719: Комп’ютерні науки та інформаційні технології. — С. 262–269. - Пошук кольорових зображень з використанням методів гістограмних ознак і кластеризації / О. Л. Вовк [и др.]. — 2008.
- Башков Е. А. Исследование возможностей использования математического аппарата мультимножеств при контекстном поиске изображений в базах данных / Е. А. Башков, О. Л. Вовк, Н. С. Костюкова // Донбас—2020: перспективи розвитку очима молодих вчених: Матеріали V науково-практичної конференції. м. Донецьк, 25–27 травня 2010 р. — Донецьк, ДонНТУ Міністерства освіти і науки, 2010. — С. 973.
- Башков Е. А. Поиск изображений по содержимому в графических базах данных [Текст] : монография / Е. А. Башков, О. Л. Вовк, Н. С. Костюкова. — Донецк : ГВУЗ
ДонНТУ
, 2014. — 120 с. - Aber Esa A M Alomairi. An overview of content-based image retrieval techniques / Aber Esa A M Alomairi, G. Sulong // Journal of Theoretical and Applied Information Technology. — 2016. — Т. 84. — № 2. — С. 215–223.
- Beis J. S. Shape indexing using approximate nearest-neighbour search in high-dimensional spaces / J. S. Beis, D. G. Lowe // Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition IEEE Computer Society Conference on Computer Vision and Pattern Recognition. — San Juan, Puerto Rico: IEEE Comput. Soc, 1997. — P.—1000–1006.
- Lamdan Y. Geometric Hashing: A General and Effective Model-Based Recognition Scheme / Y. Lamdan, H. Wolfson // Proceedings ICCV ’88. — Tampa, Florida, USA, 1988. — С. 238–249.
- Поиск изображений по визуальному подобию с применением инвертированных индексов цветовых гистограмм / И. В. Соченков [и др.] // Информационные технологии и вычислительные системы. — 2015. — С. 86–94.
- Microservices: How To Make Your Application Scale. Microservices / N. Dragoni [и др.]. — 2017.
- M. Sc. Michel Krämer. A Microservice Architecture for the Processing of Large Geospatial Data in the Cloud / M. Sc. Michel Krämer. — 2017.