Аннотация
Сидорчук В.И., Губенко Н.Е., Сипаков Д.С. Метод сокрытия сообщений на основе жаргонов. В статье было рассмотрено понятие стеганографии. Была поднята тема о защите информации от несанкционированного доступа. Был проведен сравнительный анализ методов сокрытия сообщения. На основе одного из методов, был разработан авторский метод сокрытия информации
Введение
Стеганография часто определяется как наука и искусство сокрытия информации в так называемом контейнере, передача которого от одного лица другому не вызывает подозрений. В отличие от криптографии, в задачи которой входит защита собственно сообщения, основной целью стенографии является защита самого факта наличия скрытого сообщения.
Современные стенографические средства в основном работают в информационных средах, которые имеют большую избыточность. Если брать во внимание информацию, содержащую большое количество шумовых данных (таких как звуки или изображения), письменный текст содержит малое количество избыточной информации, которую можно использовать для сокрытия тех или иных данных.
Методы лингвистической стенографии – скрытое внедрение кодированной произвольной информации в текстах, опираясь на лингвистические ресурсы – известны еще со времен средневековья. С развитием компьютерных и информационных технологий средневековые методы лингвистической стенографии возродились на новом уровне и дают возможность, в некоторых случаях, скрыть факт тайной переписки не только от атематического цензора
, который осуществляет мониторинг сетей телекоммуникаций, но и от самого человека.
Постановка проблемы
Проблема защиты информации от несанкционированного доступа возникла еще в древние времена, и с тех пор выделилось направление решения этой проблемы, которое существуют и сегодня, стеганография. Главная задача стеганографии стоит в том, чтобы человек не подозревал, что внутри передаваемой информации, внешне не представляющей абсолютно никакой ценности, содержится секретная информация. Тем самым стеганография позволяет передавать важную информацию через открытые каналы, скрывая сам факт её передачи. Целью статьи является проведение сравнительного анализа методов в лингвистической стеганографии для разработки авторского метода сокрытия сообщения.
Сравнительный анализ методов
Первым методом является – метод жаргонов. Использование жаргона в тексте может озадачить постороннего читателя. В процессе реализации данного метода создается база данных, в которую заносятся слова и соответствующие жаргоны, которые будут заменять слова.
Данный метод несложен в реализации, и используя его, отсутствует подозрение о наличии скрытой информации, в случае сохранения текста в читаемом виде. Однако данный метод имеет и недостатки: база данных слов ограничена перечнем слов, которые используют участники переписки; получатель сообщения также должен знать используемые жаргоны; в случае неудачного употребления жаргона, злоумышленник может понять скрытый смысл сообщения.
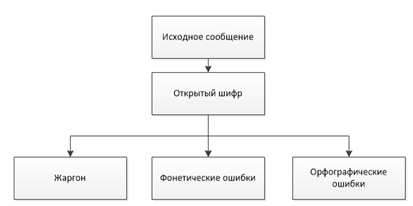
Рисунок 1 – Схема метода жаргонов
Вторым методом является – семаграмма. Семаграмма – это способ сокрыть информацию благодаря знакам или символам. Например, размещение предметов на столе в определенной последовательности, определенная последовательность чисел и т.п. Для стороннего человека, данные знаки не заметны.
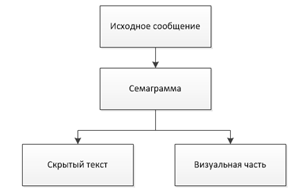
Рисунок 2 – Схема метода семаграмм
Также, существуют текстовые семаграммы. Текстовыми семаграммами являются послания, которые скрыты внутри текста. Для передачи какого-либо сообщения, могут быть использованы: заглавные буквы, пробелы между буквами или словами, особенности подчёркивания и т.п.
Среди достоинств данного метода стоит отметить, что он прост в реализации и незаметен для сторонних лиц.
Недостатком данного метода является тот факт, что из-за простоты реализации метода, злоумышленник достаточно легко может заполучить скрытую информацию.
Третьим методом является – скрытое кодирование. Скрытое кодирование считается частным случаем лингвистической стеганографии, его же наиболее сложно реализовать, однако он обеспечивает высокую скрытность информации. Данный метод использует специальную функцию, которая шифрует и дешифрует сообщение для передачи. В методе используется контейнер
, в который помещается скрываемое сообщение (см. рис.3). После получения сообщения, определенным алгоритмом, скрываемое сообщение достается из контейнера
.
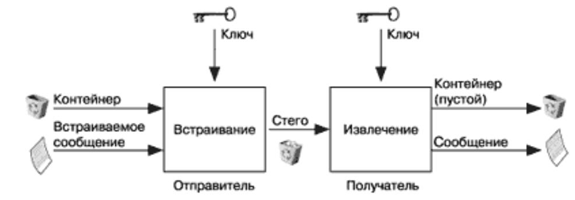
Рисунок 3 – Классическая схема метода скрытого кодирования
Данный метод имеет крепкую стойкость к дешифрованию, но высокую сложность реализации.
Четвертым метод является открытое кодирование. В данном случае имеется в виду следующее: скрытое сообщение размещают в тексте таким образом, чтобы оно не бросалось в глаза стороннему лицу. Когда доходит до анализа, компьютеры и люди демонстрируют разные методы распознавания и по-разному воспринимают стенографические сообщения. Данный метод прост в реализации, но легок в получении скрытой информации сторонним лицом.
Последним методом является – фонетика. Данный метод можно применять, если точно знать, на какой язык запрограммирован фильтр, который ищет слова на том языке, который преимущественно используется жителями в стране. Конечно, нельзя с уверенностью сказать, как в точности запрограммирован фильтр. Но чтобы приблизиться к пониманию, можно использовать фонетически схожие слова. Этот способ наиболее подходит, если вы используете алфавит, отличный от принятого в вашей стране (например, латинский вместо русского).
Данный метод прост в реализации, но информация фактически не скрывается и сторонний человек сможет легко заполучить скрытую информацию и воспользоваться ею.
Разобрав каждый метод, была составлена таблица сравнения, которая учитывает следующие критерии анализа методов: сложность реализации, сложность дешифрования, сложность определения наличия скрываемого сообщения. Каждый метод оценивается баллами от 1 до 3.
Таблица 1 – Сравнительная таблица методов стеганографии
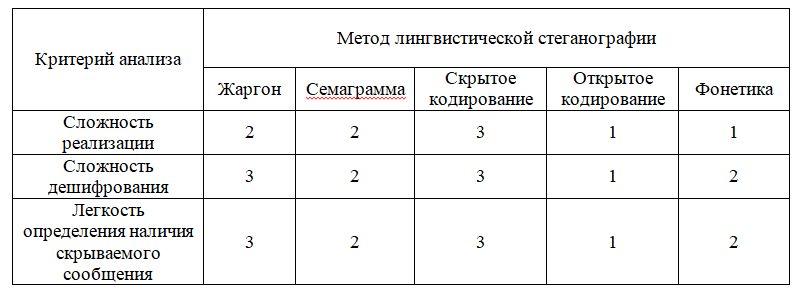
В ходе проведения исследований были проанализированы различные методы лингвистической стеганографии, а также была построена сравнительная таблица с вышеуказанными методами. Они сравнивались по сложности реализации, сложности дешифрования и сложности обнаружения сообщения. Анализируя таблицу 1 выяснилось, что метод скрытого кодирования и метод семаграмм наиболее эффекты в применении.
Разработка авторского метода
Разобрав выше каждый метод, было решено взять за основу для авторского алгоритма, метод жаргона (он же метод синонимических замен). В отличие от других исследуемых методов, данный способ может работать без источника данных слов, то есть для работы потребуется только стеготекст.
Также, при разработке, за основу был взят механизм замены кодов в соответствии с последовательностью бит сообщения, но в данном случае кодироваться будут не пробелы, а буквы согласно их ASCII кодам. Часть букв русского и английского алфавита имеют одинаковую форму написания, но различные коды (см. рис. 4). Таким образом, появляется возможность использовать данную особенность для кодирования какой-либо последовательности бит.
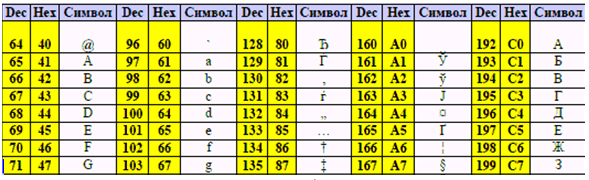
Рисунок 4 – Пример таблицы ASCII кодов
Для того чтобы запутать стегоаналитика, необходимо добавить шум в стеготекст. Если при цифровой стеганографии в качестве шума изображения или аудио файлам применялись геометрические преобразования, то в случаи с текстовым форматом нужно провести другие действия. Таким образом, можно выбрать массив букв, которые будут нести закодированное сообщение, а изменение других букв будет осуществляться случайно.
Чтобы повысить степень защиты, следует использовать какой-либо ключ. В качестве ключа будет выступать какое-либо слово или словосочетание, длина которого будет равна длине скрываемого сообщения. При внедрении, в стеготексте будет сделан отступ на длину ключа, с того места и будет осуществляться сокрытие сообщения.
Так как, используется зашумление, даже пропущенные слова будут подвержены изменениям, однако никакой информации о сообщении они не будут нести. При извлечении, получатель согласно ключу, будет знать, откуда начинать извлечение и сколько слов в сообщении.
Таким образом, методы сокрытия сообщения в текстовый файл содержит следующие шаги:
- проверка соответствия длины сообщения и ключа;
- шифрование сообщения с помощью ключа;
- перевод зашифрованного сообщения в последовательность бит (каждая буква занимает 8 бит, то есть 1 байт);
- перевод стеготекста в массив байт;
- отступ на длину ключа;
- кодирование зашифрованного сообщения;
- перевод полученных байтов стего-текста обратно в строку.
- не используется большие источники или хранилища данных;
- быстрое выполнение внедрения и извлечения информации;
- низкая вероятность обнаружения передаваемого сообщения;
- алгоритм может быть использован для текста любого стиля;
- отсутствие возможности извлечения сообщения, в случае обнаружения.
Таким образом, получатель сообщения не сможет извлечь сообщение из стеготекста без определенного ключа. При стегоанализе текста, в котором сокрыто сообщение, невозможно точно определить место, где хранится скрываемая информация и какие буквы являются существенными, при наличии в тексте предложений на русском и английском языках задача для стороннего лица еще больше усложняется.
Вывод
В статье представлены результаты анализа 5 методов лингвистической стеганографии, а также построена их сравнительная таблица. Таблица позволяет сравнивать методы по сложности реализации, сложности дешифрования и сложности обнаружения сообщения. В результате анализа был выбран метод жаргонов для разработки авторского алгоритма сокрытия сообщения в текстовом файле, который обеспечивает защиту передачи данных. Авторский метод имеет ряд преимуществ:
Литература
1. Большаков И.А., А.Ф. Гельбух. Раздельное представление словосочетаний для существительных единствен-ного и множественного числа. // Труды Международного Семинара по вычислительной лингвистике и ее приложениям. Диалог’96. Пущино, 1996.– с. 42–44.
2. FrontLine International foundation for the protection of human rights defenders [Электронный ресурс] / L.Trappeniers [et al.] // Computer. – Электрон. дан. - 2013. - Vol.46, No 2. – P. 24-25. – Режим доступа: https://equalit.ie/esecman/russian/chapter2_7.html
3. Мельчук, И. А. Опыт теории лингвистических моделей Смысл U Текст
. Семантика, синтаксис. М.: Наука. – 1974. – 314 с.
4. Стеганография [Электронный ресурс] //Академик, 2018: [сайт] – URL: https://dic.academic.ru/... – Загл. с экрана.
5. Электронная библиотека студента [Электронный ресурс.] // Библиофонд, 2018: [сайт] – URL: https://www.bibliofond.ru/...