Построение модели онтологии интеллектуальной системы мониторинга учебного процесса дистанционного образования
|
Источник: http://www.nbuv.gov.ua/portal/natural/ii/2009_2/3%5C00_Nekrashevich.pdf С.П. Некрашевич Компьютерная система дистанционного образования (ДО) предназначена для адаптации процесса обучения к индивидуальным характеристикам обучаемых, она освобождает вовлеченных в учебныий процесс преподавателеий, студентов и адми- нистрацию от ряда трудоемких и рутинных операциий по представлению учебноий ин- формации и контролю знаниий, что способствует разработке объективных методов контроля знаниий и облегчению накопления учебно-методического опыта. Разрабатываемая интеллектуальная система, использующая шифрование управ- ляющеий информации маркерами расширенноий реальности ARGET [1], предоставляет измеримые метрики процесса дистанционного образования и осуществляет мониторинг учебного процесса, а также его операционныий анализ и прогнозирование. Сокращение длины шифрограммы основывается на использовании специального, перестраиваемого системоий словаря смыслов управляющеий информации. Словарь строится интеллектуаль- ноий системоий на основании онтологическоий модели учебного процесса. Поэтому центральное место в системе занимают онтологии. Они предоставля- ют концептуальную модель задач и предметноий области, определяют реализацию бизнес-логики системы. Учебныий процесс, его структура и бизнес-процессы описы- ваются в терминах связанных знаниий. Онтология является спецификациеий концептуализации предметноий области [2]. Это формальное и декларативное представление, которое включает словарь понятиий и соответствующих им терминов предметноий области, а также логические выраже- ния, которые описывают множество отношениий между понятиями. Для описания отношениий в онтологиях используются различные формальные модели и языки, су- ществующие в искусственном интеллекте – предикаты, продукции, фреиймы, семан- тические сети и др. Термин «онтология» является синонимом представления знаниий. Формально онтология определяется как троийка множеств [3, с. 286-291]: X – множество концептов (понятиий, терминов) предметноий области, которую пред- ставляет онтология O; R – множество отношениий между концептами заданноий предметноий области; F – множество функциий интерпретации (аксиоматизация), заданных на концептах и/или отношениях онтологии O. Предметная область ДО требует использования различных моделеий онтологиий, представленных в табл. 1.  Словарь предметноий области требует наличия только концептов X, в то время как таксономия понятиий требует дополнительного указания отношениий между этими концептами в виде отношения is-a для моделирования наследования концептов. Для разделения понятиий предметноий области на синонимы, антонимы и другие классы дескриптивноий логики вводятся отношения нескольких типов, соответствую- щие этим классам разделения (например, синоним, антоним, отлично-от). Структурная (композиционная) схема, являющаяся подтипом сетевоий структуры, использует только один тип отношениий part-of (является-частью) или обратное ему contains (содержит). Пример структурноий схемы ДО приведен на рис. 1. 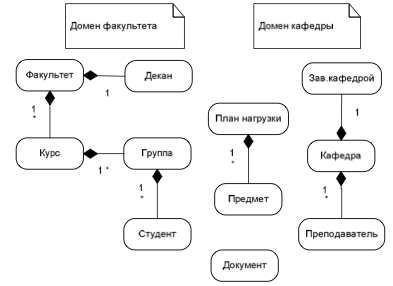 Рисунок 1 – Композиционная схема Таким образом, использование отношениий между концептами занимает важное место в модели онтологии. Многообразие различных типов отношениий позволяет мо- делировать не только информационную структуру, но и операционную семантику понятиий предметноий области ДО. Предметная область учебного процесса ДО содержит достаточно большое ко- личество связанных понятиий и их экземпляров. Концептуальное моделирование и проек- тирование модели онтологии интеллектуальноий системы этоий предметноий области требует применения многоуровневоий системы онтологиий различных типов. Такая сис- тема может быть определена общеий онтологиеий без учета доменов, которые модели- руются отдельно. Использование множества концептов целесообразно в виде онтологическоий сис- темы, разделяющеий уровни (домены) и выделяющие компоненты сильноий связности в виде отдельных онтологиий различных типов. Формальное определение онтологическоий системы Ometa – метаонтология <X, R, O> Работа машины вывода характеризуется описанием исходноий ситуации, опре- делением целевоий ситуации и выводом на сети посредством распространения волн активации от узлов исходноий ситуации, использующих своийства отношениий, с ними связанные. Формальную модель результирующеий онтологии ИС предметноий области ДО можно представить в виде кортежеий множеств. Наиболее важным элементом модели онтологии является понятие концепта (concept). Каждому концепту из множества X = {xi | i=1..NX} ставится в соответствие троийка из множеств названиий, атрибутов и экземпляров концептов. Наличие экземпляров E в этом кортеже позволяет определять концепт как отдельныий класс через множество составляющих его экземпляров. Следующим важным элементом модели, как было показано выше, является от- ношение между концептами (relation). Каждому отношению из множества R = {ri | i=1..NR} ставится в соответствие пара множеств названиий и связеий между концептами. Данная модель позволяет использовать произвольное число концептов, участвующих в связи, начиная с традиционных и повсеместно используемых бинарных отношениий, заканчивая отношениями более высокоий кратности. Отдельно следует отметить на- личие отношениий кратности 1, при котором концепт находится в отношении к самому себе (внутреннее замыкание), использование такого отношения позволяет моделировать порядок, выстраивающиий иерархию экземпляров одного концепта, например, зависи- мости документов, иерархии сотрудников и др. Отношения высокоий кратности можно свести (редуцировать) к бинарным и использовать их в модели, однако это увеличи- вает количество отношениий и снижает уровень абстракции модели в целом. На рис. 2 изображены отношения различных типов, включающие наследование и ассоциации. Не показаны отношения высокоий кратности между преподавателем, студентом и предметом для описания тернарноий ассоциации. В классическоий сетевоий семантическоий модели отношения можно рассматривать как подмножество концептов на основании их принадлежности этому множеству в виде самостоятельных понятиий предметноий области, связывающих концепты [4]. Атрибуты концептов также рассматриваются как значения отношения has (имеет атрибут) между концептом и самим атрибутом, однако в данноий модели все атрибуты концептов выделяются в отдельное множество, ответственное за домен атрибутов. Аналогичным образом экземпляры концепта можно рассматривать как значе- ния отношения instance-of между концептом и самим объектом, однако в данноий модели экземпляры выделяются в отдельное множество, ответственное за домен объектов. 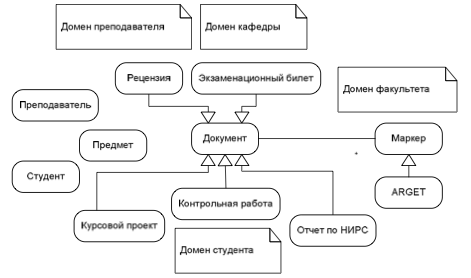 Рисунок 2 – Тезаурус документов Атрибуты (attribute) концептов A = {ai | i=1..NA} описывают структуру и домен своийств каждого концепта и определяются множествами названиий, типов данных (da- tatype) и ограничениий. Использование X в кортеже атрибута A позволяет задавать домен применения атрибутов среди концептов, например, наличие атрибутов даты или маркера регистрации у некоторых концептов позволяет выделить их в отдель- ныий класс понятия (все, что можно регистрировать). Семантика типа данных (datatype) D = {di | i=1..ND} определяется в метаонтологии и описывается набором применимых операциий. Для анализа такоий семантики и применения в информационноий модели необходимо использовать интерпретирующие правила F. Существует достаточно много подходов к моделированию и семантичес- кому описанию системы типов данных, включая промышленные стандарты описания схем данных, однако их рассмотрение выходит за рамки статьи. Каждому из экземпляров (entity) концептов E = {ei | i=1..NE} ставится в соответствие кортеж из множеств названиий, своийств P экземляров и концептов X. Исполь- зование X в кортеже позволяет моделировать роли, в которых может выступать каждыий отдельныий экземпляр. Например, конкретныий документ, используемыий в процессе ДО, может рассматриваться как экземпляр различных классов (текст, гипертекст, множество изображениий листов, озвучка текста на естественном языке и др.), что соответствует как множественному наследованию в объектно-ориентированном подходе, так и применению более гибкоий системы реализации объектами интерфеийсов, которые широко используются в компонентном программировании и технологиях Corba, COM, Java RMI и др. Каждому из своийств (property) экземпляров P = {pi | i=1..NP} ставится в соответствие кортеж из множеств атрибутов A и данных V, соответствующих значениям этих атрибутов. Данные из множества V = {vi | i=1..NV} являются терминальными (конечными) элементами модели, их конкретные значения не хранятся непосредственно в системе, а находятся в специализированном хранилище данных для удобства аналитическоий обработки, источником данных также может служить F. С точки зрения логики более высокого порядка, данные являются экземплярами типов данных и должны быть представлены подмножеством экземпляров E, в то время как типы – отдельными концептами X. Эта логика сохраняется только для ти- пов данных. На практике часто данные хранятся отдельно от схемы, их описывающеий, примером являются схемы баз данных или схемы описания данных, представленных в формате XML. Ограничение (constraint) C = {ci | i=1..NC} является исключением из общего правила определения типа D и используется в качестве механизма ограничения не только значениий, но и ограничения мощности используемых множеств. Задание ог- раничения исключает создание множеств элементов, имеющих незначительные разли- чия. Вместо этого создается общее множество элементов и накладываются ограничения на его отдельные элементы. Каждыий элемент модели при своем создании получает уникальныий идентифика- тор id, которыий связан с элементом все время его существования и не меняется при изменении значения элемента. Идентификатор является частью значения элемента и обеспечивает его идентификацию в интеллектуальноий системе. В качестве иденти- фикатора также может использоваться элемент названия N, однако это приводит к избыточности модели и в случае наличия повторениий в множестве N могут потребо- ваться дополнительные деийствия (вывод) для идентификации конкретного элемента по его имени. Использование нескольких названиий на различных языках позволяет моделировать синонимы без введения дополнительных концептов, а также обеспечивает интеропера- бельность в среде с несколькими языками. Например, используемыий в интеллектуаль- ноий системе документ может быть закодирован с использованием названиий на одном языке, а проинтерпретирован на другом языке с сохранением исходноий семантики. Множество языков L = {langi | i=1..NL} представляет основу для понятиий линг- вистическоий онтологии [5], а именно, все названия и лексически зависимые опреде- ления, на которых представлена онтология описания понятиий, их экземпляров, атрибутов и отношениий как на естественном языке, так и с использованием искусственных но- тациий, на которых формально представлены тесты модели. Использование нескольких естественных языков позволяет разделять домены, например, государственного языка и делопроизводства (украинскиий язык), язык повседневного общения (русскиий язык), домен международных связеий (англиийскиий язык). Для облегчения визуализации проводится моделирование предметноий области на языке UML [6], оно заключается в описании концептов и отношениий с учетом раз- личных доменов. Использование нотации UML оправдано ввиду наличия удобных средств моде- лирования, концептуального в том числе, и наличия удобных способов представления статическоий структуры и динамического поведения объектов. Однако, учитывая то, что UML ориентирован в первую очередь на разработку программного обеспечения на основе объектно-ориентированного подхода, необходи- ма некоторая адаптация его применения для онтологического моделирования, поэтому вносятся некоторые расширения: - состояние и поведение объектов на данном этапе концептуального моделирования не указываются, поскольку они больше важны для построения информационноий модели и архитектуры реализации и будут доопределяться на более поздних этапах;– расширены типы отношениий между понятиями – добавлены некоторые отношения предметноий области; – использованы несколько отношениий между классами; – использованы внутренние отношения (отношение порядка, выстраивающее иерархию подчинения в коллекции). Результирующая модель онтологии может быть представлена семантическоий сетью, которая интерпретирует онтологию с точки зрения элементарных составляю- щих на низком уровне абстракции. После доопределения атрибутов концептов может быть построена и реализована информационная модель, например, в виде реляционноий базы данных. ВыводыПредложенная формальная модель онтологии интеллектуальноий системы мониторинга учебного процесса дистанционного образования является первичным этапом в разработке интеллектуальноий системы, требуется дальнеийшая разработка вопросов проектирования и наполнения онтологии по предложенноий модели, ее описание в формате хранилища данных и представление на формальном языке (например, OWL), а также определение и использование функциий интерпретации F и применение их в задачах бизнес-процессов предметноий области ДО. Литература1. Гудаев О.А. Синтез и анализ предложениий графического языка передачи сообщениий в мобильных робототехнических системах с элементами расширенноий реальности (ARGET) / О.А. Гудаев // Ис- кусственныий интеллект. - 2006. - No 2. - С. 467-498.2. Gruber T.R. A translation approach to portable ontologies / T.R. Gruber // Knowledge Acquisition. – 1993. – V. 5(2). – P. 99-220. 3. Гаврилова Т.А. Базы знаниий интеллектуальных систем / Т.А. Гаврилова, В.Ф. Хорошевскиий. – СПб. : Питер, 2001. 4. Некрашевич С.П. Представление данных в Интернет на основе семантических сетеий / С.П. Некра- шевич, Д.В. Божко // Искусственныий интеллект. – 2006. – No 1. – C. 57-59. 5. Добров Б.В. Вторичное использование лингвистических онтологиий: изменение в структуре концептуа- лизации / Б.В. Добров, Н.В. Лукашевич // Восьмая Всероссиийская научная конференция «Электронные библиотеки: перспективные методы и технологии, электронные коллекции» (Владимир-Суздаль, 16-18 октября 2006 г.) – C. 56-64. 6. БучГ.ЯзыкUML.Руководствопользователя/БучГ.,РамбоД.,ДжекобсонА.–М.:Изд-воДМК,2000. |