ОБЗОР СРЕДСТВ РАЗРАБОТКИ ОНТОЛОГИЧЕСКИХ МОДЕЛЕЙ
Автор: Чайка В.А., Землянская С.Ю., Андриевская Н.К.
Источник: В сборнике: Информатика, управляющие системы, математическое и компьютерное моделирование (ИУСМКМ-2020). Сборник материалов XI Международной научно-технической конференции в рамках VI Международного Научного форума Донецкой Народной Республики. Редколлегия: Ю.К. Орлов [и др.]. 2020. С. 233-237. [Ссылка]
УДК 004.048
ОБЗОР СРЕДСТВ РАЗРАБОТКИ ОНТОЛОГИЧЕСКИХ МОДЕЛЕЙ
Чайка В.А., Землянская С.Ю., Андриевская Н.К.
Донецкий национальный технический университет
кафедра автоматизированных систем управления
E-mail: valera_chaika@mail.ru
Аннотация:
Чайка В.А., Землянская С.Ю., Андриевская Н.К. Обзор средств разработки онтологий. В данной статье была поставлена проблема извлечения и использования полезной информации из документов, связанных с научно-исследовательской деятельностью. Подробно рассмотрен этап составления онтологии. Проведен анализ и выбран язык спецификации, средство разработки и машины логического вывода онтологии.
Annotation:
Chaika V.A., Zemlyanskaya S.Y., Andrievskaya N.K. Ontology development tools overview. The article identified the problem of useful information from research-related documents extracting. The concept of a specialized information system was proposed. The stage of ontology compilation was considered in detail. A study of tools for working with ontological models was carried out. As a result of the study, the specification language, development tool and ontology logic output machines were chosen.
Проблематика
Процесс и результаты научной деятельности сотрудников организаций, занимающихся исследовательской и научно-педагогической деятельностью, сопровождается большим количеством различной отчетной документации, включающей публикации, тезисы докладов, патенты, диссертационные исследования и многие другие. Разнородность и неоднозначные способы форматирования этих материалов превращают учет и анализ результатов научных исследований в сложную задачу. Для решения этой задачи необходимо обеспечить формирование стандартизованного информационного каркаса, позволяющего ориентироваться на общие концепции научно-изыскательской предметной области, который может быть использован для извлечения научной и системной информации, а также для проверки, увязки и согласования данных. Для повышения эффективности управления данными о научных исследованиях и проектах необходима разработка и внедрение стандартов данных и применение лучших практик по управлению данными.
Один из способов создания такого стандартизованного каркаса – это использование онтологических моделей предметной области. Онтологии – попытка детальной формализации некоторой области знаний при помощи концептуальных схем. Онтологии описывают понятия предметной области, а также отношения, которые существуют между этими понятиями. Такое представление информации позволяет компьютеру и человеку использовать ее эффективнее. [1]
Понятие онтологии
Существует множество определений онтологий, большинство которых сводится к тому, что онтология некоторым образом описывает понятия предметной области., на базе которых можно реализовать понятия и отношения между ними, а также правила, аксиомы и др.
Чаще всего упрощенно математически онтологию можно представить, как упорядоченную тройку вида [2]:
О = ⟨ T, R, F ⟩
где:
T – конечное множество терминов (концептов, понятий, классов) предметной области, которую представляет онтология O; (помимо конечности также есть ограничение непустоты);
R – конечное множество отношений между понятиями заданной предметной области;
F – конечное множество функций интерпретации (аксиоматизация) заданных на концептах и/или отношениях онтологии O.
В зависимости от степени детализации онтологии могут быть представлены в следующих видах:
- простой каталог id-значение;
- словарь терминов или глоссарий- хранит список терминов и их значения;
- тезаурус-используют связи между понятиями (синонимы, иерархия, ассоциация);
- формальные таксономии-дополнительно включают отношения класс-подкласс и класс-экземпляр;
- фреймы- подразумевают возможность дополнительного хранения свойств.
По цели создания онтологии делят на 4 класса:
- онтологии представления, целью которых является описание области представления знаний;
- онтологии верхнего уровня, обобщающие знания для многократного и широкого использования;
- онтологии предметных областей, продолжающих описание онтологии представления, но ограниченные конкретной предметной областью;
- прикладные онтологии, описывающие концептуальную модель конкретной прикладной задачи.
Путей формирования онтологий известно два. Первый, формальный, основывается на логике предикатов. Второй, лингвистический, основан на обработке корпусов текстовых документов и использовании семантических методов.
Все этапы формирования онтологии вместе с ее оценкой можно свести к схеме, представленной на рисунке 1. [3]
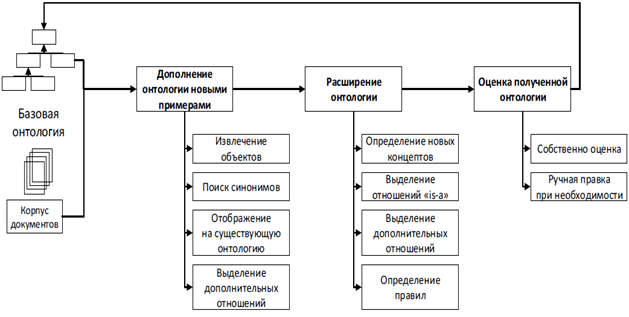
Рис. 1. Этапы формирования онтологии
Процесс генерации онтологии на основе множества документов, состоит из следующих этапов:
- идентификация и извлечение объектов;
- кластеризация объектов на группы синонимичных объектов;
- поиск соответствия кластеров существующим концептам или генерации нового концепта;
- выделение отношений наследования между концептами;
- вспомогательных отношений;
- определение правил на получившейся онтологии.
При составлении онтологии в автоматическом или полуавтоматическом режиме очень важен процесс оценки результатов работы алгоритмов.
Следует отметить, что алгоритм цикличен: исходная, возможно, пустая онтология дополняется новыми объектами, концептами и отношениями, оценивается и затем уже используется как база для дальнейшего расширения.
Обзор языков онтологий
Ключевым моментом в проектировании онтологии является выбор соответствующего языка спецификации онтологий. Цель таких языков – дать возможность указывать дополнительную машинно-интерпретируемую семантику ресурсов, сделать машинное представление данных более похожим на положение вещей в реальном мире, существенно повысить выразительные возможности концептуального моделирования слабо структурированных Web-данных [4]. Рассмотрим некоторые из них.
Язык RDF. В рамках проекта семантической интерпретации информационных ресурсов Интернет (Semantic Web) был предложен стандарт описания метаданных о документе Resource Description Framework, использующий XML-синтаксис. RDF использует базовую модель данных «объект – атрибут – значение» и способен сыграть роль универсального языка описания семантики ресурсов и взаимосвязей между ними. Ресурсы описываются в виде ориентированного размеченного графа — каждый ресурс может иметь свойства, которые в свою очередь также могут быть ресурсами или их коллекциями. Все словари RDF используют базовую структуру, описывающую классы ресурсов и типы связей между ними. Это позволяет использовать разнородные децентрализованные словари, созданные для машинной обработки по разным принципам и методам. Важной особенностью стандарта является расширяемость: можно задать структуру описания источника, используя и расширяя такие встроенные понятия RDF-схем, как классы, свойства, типы, коллекции. Модель схемы RDF включает наследование классов и свойств.
DAML+OIL – семантический язык разметки Web-ресурсов, расширяющий стандарты RDF и RDF Schema за счет более полных примитивов моделирования. Последняя версия DAML+OIL обеспечивает богатый набор конструкций для создания онтологии и разметки информации таким образом, чтобы их могла читать и понимать машина.
OWL (Web Ontology Language) – язык представления онтологий, расширяющий возможности XML, RDF, RDF Schema и DAML+OIL. Этот проект предусматривает создание мощного механизма семантического анализа. Планируется, что в нем будут устранены ограничения конструкций DAML+OIL. Онтологии OWL – это последовательности аксиом и фактов, а также ссылок на другие онтологии. Они содержат компоненту для записи авторства и другой подробной информации, являются документами Web, на них можно ссылаться через URI.
Описание и сравнение средств разработки онтологий
При создании онтологий (как и при проектировании программного обеспечения или написании электронного документа) целесообразно пользоваться подходящими инструментами. Будем называть инструментальные программные средства, созданные специально для проектирования, редактирования и анализа онтологий, редакторами онтологий.
В приведенной ниже таблице 1 перечислены основные характеристики наиболее популярных редакторов онтологий.
Таблица 1 – Характеристики редакторов онтологий
| № | Название | Краткое описание | Формализмы, языки, форматы |
|---|---|---|---|
| 1 | Ontolingua | Совместная разработка онтологий | OKBC, KIF |
| 2 | Protege | Создание, просмотр онтологий | JDBC, UML, XML, XOL, SHOE, RDF / RDFS, DAML+OIL, OWL |
| 3 | OntoSaurus | Web-браузер баз знаний на языке LOOM | LOOM |
| 4 | OntoEdit | Разработка и поддержка онтологий | F-Logic, RDFS, OIL, OXML |
| 5 | OilEd | Разработка онтологий, поддержка логического вывода | DAML+OIL |
| 6 | WebOnto | Многопользовательская разработка онтологий | OCML |
| 7 | WebODE | Создание онтологий с помощью методологии Methontology | F-Logic, LOOM, Ontolingua |
Таблица 2 – Сравнительная характеристика резонеров
| Наименование | Pellet | RacerPro | Fact++ | Hermit |
|---|---|---|---|---|
| Версия | 1.x, 2.x |
1.1.10 | - | 1.3.6, 1.3.5, 1.2.2 |
| Методология | Tableau based | Tableaux based | Tableau based | Hypertableauх based |
| Родной профиль | DL, DL.EL(2.x) | DL | DL | DL |
| Платформа | All | All | All | All(1.3.6) |
| OWL API | Yes | Yes | Yes | Yes |
| Язык программирования | Java | LISP | C++ | Java |
| Доступность | Open source | Commercial | Open source | Open source |
| Выразит. | SROIQ(D) | SROIQ(D-) | SROIQ(D) | SHOIQ+ |
| v. protege | +3.x (1.х), +4.x (1.х), -(2.x) |
4.1,4.2(1.1.1.0) | 4.Х | 4.2 (1.3.6), 4.2 (1.3.5), 4.1 (1.2.2) |
Основная функция любого редактора онтологий состоит в поддержке процесса формализации знаний и представлении онтологии как спецификации (точного и полного описания).
В большинстве своем современные редакторы онтологий предоставляют средства кодирования
(в смысле описания
) формальной модели в том или ином виде. Некоторые дают дополнительные возможности по анализу онтологии, используют механизм логического вывода.
В последнее время количество общедоступных редакторов онтологий превысило 100 единиц. Но редко можно встретить универсальное и в то же время полезное средство. [5]
Характеристики, которые будут сравниваться [6]:
Методология. У каждого существующего резонера есть определенный алгоритм или методология, по которому он выстраивает взаимосвязей в иерархических структурах. К таким методологиям относятся Tableau-based, Tableaux-based, Completion rules, SWRL rules, Hypertableau-based, Consequence based методики.
Родной профиль. Эта характеристика показывает, к какому типу OWL относится данный резонер. OWL DL или OWL EL, OWL QL, OWL RL.
Платформа. Характеристика поддержки различных платформ, а именно: Windows, Linux.
OWL API. Булевая характеристика, обозначающая наличие или отсутствие поддержки OWL API у резонера.
Язык программирования. Одна из ключевых характеристик – на каком языке программирования был написан резонер, например: Java, C++, Prolog, LISP, и др.
Доступность. Данная характеристика показывает, является ли резонер платным или бесплатным.
Поддержка выразительности резонера. Характеристика, которая введена для определения методики выразительности резонерa.
v. protege. Показывает, с какими версиями Protege совместима данная версия резонера.
Выводы
Использование специального языка правил и классификаций для стандартизации контента, и семантики данных внутри научно-образовательной организации позволит организовать оперативный анализ персональных и обобщенных данных, облегчит поиск необходимой для научных исследований и учебных разработок информации за счет жестких, прозрачных, неизменных правил. Рассмотренные в статье средства могут быть использованы для создания информационной модели автоматизированной системы учета и анализа результатов научных исследований.
Литература
- Морозов И., Белокопытова Е. Анализ и сравнение работы различных Reasoner’ов в Protege. URL: https://www.academia.edu/9280798/Анализ_и_сравнение_работы_различнх_Reasonerов_в_Protege (дата обращения: 04.05.20)
- Романов С. В., Сытник А. А., Шульга Т. Э. О возможностях использования коммуникативных грамматик и LSPL-шаблонов для автоматического построения онтологий // Известия Самарского научного центра Российской академии наук. — 2015. — Т. 17
- Платонов А. В., Полещук Е. А. Методы автоматического построения онтологий. URL: https://cyberleninka.ru/article/n/metody-avtomaticheskogo-postroeniya-ontologiy/viewer (дата обращения: 07.05.20)
- Языки представления онтологических знаний. Кратко [Электронный ресурс]. — Режим доступа: http://fevt.ru/load/jazyki_predstavlenija_ontologicheskikh_znanij/124-1-0-1739 (дата обращения: 09.05.20)
- Лекция 7: Инструментальные средства проектирования онтологий. [Электронный ресурс]. — Режим доступа: https://www.intuit.ru/studies/courses/1078/270/lecture/6857?page=2 (дата обращения: 10.05.20)
- Горшков С. Введение в онтологическое моделирование // ООО ”ТриниДата