Быстрый поиск изображений — результатов дистанционного зондирования Земли, основанный на признаках ORB
Системы поиска изображений по содержанию в контексте обработки изображений, полученных средствами дистанционного зондирования Земли, являются областью активного исследования. При поиске таких изображений используются локальные признаки, такие как SIFT. В этой работе мы рассматриваем признаки ORB в качестве альтернативы для SIFT с целью улучшения гибкости и производительности модели BoW в задаче обучения словаря, многомерного поиска признаков и квантования. Применением нашего метода достигнуто уменьшение количества вычислительных операций на примерно один порядок, и, при этом, увеличение точности. Производительность дескриптора ORB оценивается на наборе изображений UC Merced Land Use-Land Cover.
Ключевые слова: поиск изображений, локальные инвариантные признаки, признак BRIEF, признак ORB, Bag of visual words
Введение
С появлением и бурным развитием дистанционных датчиков началась технологическая революция в области удалённого зондирования. Поиск интересующей информации усложнился с увеличением числа коммерческих спутников с датчиками высокого разрешения.
Для создания крупномасштабных репозиториев изображений, с возможностью поиска по ним, требуется разработка и улучшение автоматизированных процессов, исключающих необходимость во вмешательстве человека в процесс обработки информации. Поиск изображений по содержанию (CBIR) — это растущий в популярности метод поиска в больших графических базах данных. Для выполнения CBIR-запросов не применяются традиционные реляционные системы управления базами данных, хранящие метаданные изображения.
CBIR — наиболее важный и эффективный метод поиска изображений; он исследуется как в академической, так и промышленной сферах. Поиск изображений по содержанию, по всей вероятности впервые, был рассмотрен в работе [1], посвящённой автоматическому поиску изображений в базе данных. Такой вид поиска отличается от поиска по ключевым словам, тегам или дескрипторам, ассоциированным с изображением. CBIR анализирует содержимое изображений: цвет, формы, текстуры и любую другую информацию, которая может быть извлечена непосредственно из изображения.
В [2] применяется несколько текстурных дескрипторов, круговая ковариационная гистограмма и инвариантные к повороту тройки точек для представления содержания изображений. Эта работа оценивается с помощью набора данных LULC. Поскольку визуальные знания связанны с формами изображённых объектов, для описания изображений часто применяются дескрипторы формы. В [3] описывается создание системы поиска и индексирования геопространственной информации (GetIRIS) и предлагается новая структура индекса и новый дескриптор форм.
С другой стороны, локальным признакам могут быть не свойственны ограничения глобальных признаков: зависимость от перекрытий, геометрических трансформаций и изменений освещения. Локальные признаки строятся по множеству ключевых точек, окрестность которых описывается в виде вектора, который и используется в качества дескриптора. Впервые, локальные признаки применяются для поиска геопространственной информации в работе [4].
На данный момент предлагается два класса локальных признаков: бинарные и небинарные дескрипторы. Наиболее популярными небинарными дескрипторами являются SIFT, SURF, HOG, PCA-SIFT и др. Инвариантное к масштабу преобразование признаков (SIFT), предложенное в [5] можно считать ключевой вехой в исследовании применения локальных признаков.
К другому классу локальных признаков относятся бинарные дескрипторы, такие как BRIEF, BRISK, ORB и др. Для их построения осуществляется сравнение интенсивности цвета пикселей в различных позициях и формируется двоичный вектор. В [6] предлагается дескриптор BRIEF, использующийся для высокопроизводительного вычисления дескрипторов и их сопоставления. BRIEF представляется в виде двоичной строки, вычисленной в результате простого сравления интенсивности в случайных, заранее-определённых пикселях окрестности контрольной точки. Несмотря на очевидные преимущества этого подхода в виде высокой скорости и эффективности, его недостатками являются низкая надёжность и робастность, связанная с влиянием поворота изображения и изменения масштаба. BRISK, описанный в [7], сначала находит контрольные точки в непрерывном масштаб-пространстве основываясь на детекторе, в основу которого легли FAST и GFAST. Затем, вычисляется BRIEF путём конкатенации результатов простых сравнений яркости пикселей. Дескриптор BRISK, в отличии от BRIEF, учитывает местоположение, масштаб и ориентацию, тем самым достигается его инвариантность к ориентации и масштабу. Дескриптор ORB [8] основыван на BRIEF, но использует новый алгоритм o-FAST для извлечения ключевых точек, тем самым достигается инвариантность к повороту. Несмотря на ограничения робастности и отчётливости по сравнению с SIFT, ORB очевидно быстрее SIFT.
Наш подход вдохновлён работой [4], представленной ранее, в которой были использованы локальные признаки для поиска географических изображений.
Метод
В этой статье описывается несколько основных процедур процесса поиска изображений. Во-первых, происходит выделение множества ключевых точек, для окрестностей которых вычисляется дескриптор ORB. Во вторых, применяется модель «Мешок слов» (Bag of words, BoW) для квантования локальных дескрипторов и получения «визуальных слов», использующихся для составления описания изображения в виде вектора слов и для составления словаря. На последнем этапе, изображение-поисковый запрос представляется в виде вектора и его поиск осуществляется в векторном пространстве признаков с использованием меры схожести.
Дескриптор признаков
Локальные дескрипторы признаков играют ключевую роль в решении задачи поиска изображений. В нашем методе используется дескриптор ORB. ORB является улучшением бинарного дескриптора BRIEF, поэтому в этом разделе приводится введение в BRIEF.
BRIEF (Binary Robust Independent Elementary Feature) [9] — это дескриптор, использующий относительно малое число сравнений интенсивности для представления фрагмента изображения в виде бинарной строки.
Для того, чтобы уменьшить чувствительность к шуму, применяется этап предварительного сглаживания. Используется размытие по гауссу с ядром размера 9×9. После чего определяется тест τ на участке p размера S×S:
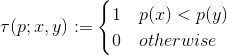
Множество бинарных тестов определяется выбором множества местоположений nd(x,y). Таким образом, дескриптор BRIEF может быть представлен nd-мерной битовой строкой:
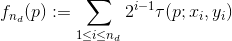
Признаки ORB (Oriented FAST and Rotated BRIEF)
ORB — это новый дескриптор признаков, основанный на широко извеснтом детекторе ключевых точек FAST и недавно разработанном дескрипторе BRIEF. Он, примерно на порядок, быстрее SIFT. Вычисление ORB начинается с обнаружения ключевых точек алгоритмом FAST. Оригинальная работа по FAST реализует множество бинарных тестов на участке путём варьирования порога интенсивности между центральным пикселем и пикселями на окружности вокруг центра. Для определения интенсивности угла используется угловая мера Хариса.
Признаки FAST не учитывают ориентацию, что важно для извлечения дескрипторов. ORB применяет центроид интенсивности, который предполагает что интенсивность пикселей окрестности смещена относительно центра. Информация об ориентации в FAST вычисляется с методом, предложенным Rosin. В частности, момент mpq фрагмента может быть вычислен как
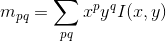
И с учётом моментов, центроид может быть вычислен как
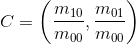
Вектор OC может быть найден по центру угла О и центроиду С. Ориентация, тогда, вычисляется как
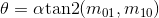
Двоичный тест и признак fn(p) определён аналогично. В связи с тем, что BRIEF не является инвариантным к повороту в плоскости, применяется модификация (steer) BRIEF по ориентации ключевой точки. Для каждого множества признаков из n двоичных тестов в позиции (xi, yi) составляется матрица 2×n
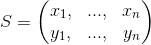
Модифицированная версия Sθ, полученная от S может быть построена с использованием матрицы поворота Rθ:
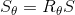
Модифицированный оператор BRIEF определяется следующим образом:
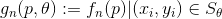
В конце вычисления ORB, осуществляется поиск среди всех возможных двоичных тестов множества некоррелирующих тестов интенсивности с большой дисперсией. Как показано на рисунке 1 ORB даёт лучший результат сопоставления нежели SIFT и SURF.

Квантование и индексация дескрипторов
В связи с переменным количеством ключевых точек в каждом изображении, требуется квантование большого количества локальных признаков. Мы используем квантование локальных дескрипторов для формирования визуальных слов. Применяется стандартная кластеризация методом k-средних для генерации словаря визуальных слов (codebook) по множеству дескрипторов ORB. В ходе работы итеративной кластеризации методом k-средних, расстояние между дескрипторами SIFT или SURF и центроидами кластеров вычисляется с использованием расстояния Махаланобиса или евклидово расстояния. Дескрипторам ORB, являющимся бинарными дескрипторами, извлечённым из изображения, назначаются метки, соответствующие ближайшему центроиду кластера по расстоянию Хэмминга. Таким образом достигается повышение производительности. На основании словаря, изображения-запросы представляются как вектор визуальных слов. Мы можем получить множество похожих изображений путём вычисления схожести вектора-запроса с каждым из векторов-кандидатов.
Эксперименты и результаты
В наших экспериментах производится тестирование метода на наборе данных UC Merced LULC, состоящем из изображений 21 категории. В каждую категорию входит по 100 изображений в цветовом пространстве RGB (256×256 пикселей). Изображения были выбраны вручную из большей коллекции USGS National Map Urban Area Imagery. Были отобраны различные изображения городских областей. Разрешение пикселей этих изображений, находящихся в общественном достоянии, — 1 фут.

Качество поиска оценивается с использованием ANMRR (средний нормализованный модифицированный рейтинг поиска), принятым CBIR-сообществом как метод оценки эффективности поиска MPEG-7. ANMRR рассматривает не только количество действительно релевантных изображений в первых результатах поиска но и их порядок.
Обозначим запрос как q, количество действительно релевантных результатов как NG(q), позицию k-го релевантного изображения в списке результатов поиска как Rank(k). Мы произвели несколько сравнительных экспериментов для демонстрации эффективности предложенного алгоритма.
Наш метод, основанный на признаках ORB, сравнивается с классическими признаками SIFT и SURF. На шаге BoW формируется словарь путём кластеризации методом k-средних используя локальные признаки. Для измерения схожести между двумя признаками применяется эвклидово расстояние для SIFT и SURF, расстояние Хэмминга — для ORB. Для каждой из 21 категории в базе данных шесть раз выполняется запрос и рассматриваются 100 изображений — результатов запроса. После чего вычисляется среднее ANMRR по шести запросам. На рисунке 3 показана производительность различных локальных признаков в каждой из 21 категории и среднее значение.
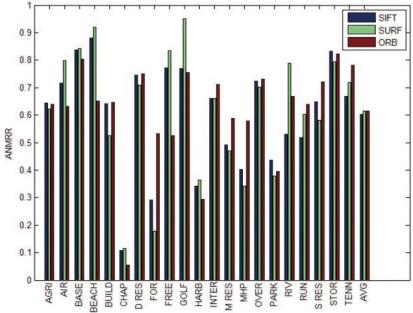
Средние значения ANMRR для SIFT, SURF и ORB — 0.602787, 0.614163 и 0.615101 соответственно. По значению ANMRR видно, что качество результатов по трем дескрипторам схожа.
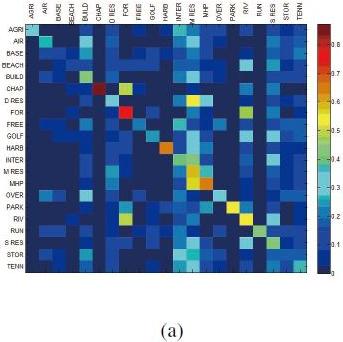
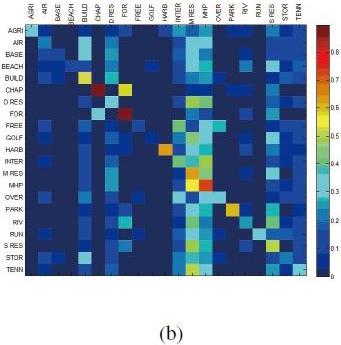
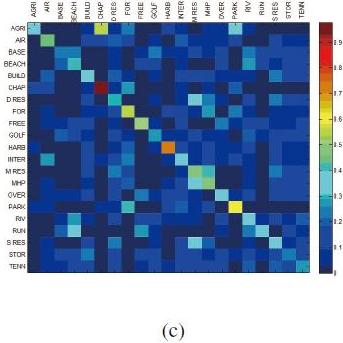
Мы можем применить матрицу ошибок (Confusion matrix) для сравнения точности поиска. Строки определяют класс запроса, а колонки — классы результата. Как показано на рисунке 4, у ORB наиболее точное предсказание, о чем свидетельствует наибольшие значения на главной диагонали матрицы. В наших экспериментах проверка дескрипторов признаков осуществлялась на процессоре 2.80GHz Intel Core2 и 4 ГБ оперативной памяти.
Выводы
В этой статье мы применили новые локальные признаки ORB, как альтернативу SIFT для описания изображений, полученных средствами дистанционного зондирования Земли с целью реализации поиска. Наш метод достигает уменьшения количества вычислительных операций на примерно один порядок при повышении качества. Были проведены эксперименты на наборе данных UC Merced LULC, показавшие эффективность нашего метода.
Литература
- T. Kato, “Database architecture for content-based image retrieval,” in SPIE/IS&T 1992 Symposium on Electronic Imaging: Science and Technology. International Society for Optics and Photonics, 1992, pp. 112–123.
- E. Aptoula, “Remote sensing image retrieval with global morphological texture descriptors,” 2014.
- G. J. Scott, M. N. Klaric, C. H. Davis, and C.-R. Shyu, “Entropy-balanced bitmap tree for shape-based object retrieval from large-scale satellite imagery databases,” Geoscience and Remote Sensing, IEEE Transactions on, vol. 49, no. 5, pp. EEE Transactions on, vol. 49, no. 5, pp.
- Y. Yang and S. Newsam, “Geographic image retrieval using local invariant features,” Geoscience and Remote Sensing, IEEE Transactions on, vol. 51, no. 2, pp. 818–832, 2013.
- D. G. Lowe, “Distinctive image features from scaleinvariant keypoints,” International Journal of Computer Vision, vol. 60, no. 2, pp. 91–110, 2004. [Online]. Available: http://dx.doi.org/10.1023/B:VISI.0000029664.99615.94
- M. Calonder, V. Lepetit, C. Strecha, and P. Fua, “Brief: Binary robust independent elementary features,” in Computer Vision–ECCV 2010. Springer, 2010, pp. 778–792.
- S. Leutenegger, M. Chli, and R. Y. Siegwart, “Brisk: Binary robust invariant scalable keypoints,” in Computer Vision (ICCV), 2011 IEEE
- International Conference on. IEEE, 2011, pp. 2548–2555. E. Rublee, V. Rabaud, K. Konolige, and G. Bradski, “Orb: an efficient alternative to sift or surf,” in Computer Vision (ICCV), 2011 IEEE
- International Conference on. IEEE, 2011, pp. 2564–2571. M. Calonder, V. Lepetit, C. Strecha, and P. Fua, “BRIEF: binary robust independent elementary features,” in Computer Vision - ECCV 2010, 11th