
Abstract
Содержание
- Introduction
- 1. Theme urgency
- 2. Goal and tasks of the research
- 3. Analysis of the main methods of embedding information for placing a digital watermark in order to protect copyright for audio files
- Conclusion
- References
Introduction
Every day hundreds of different songs are created in the world, radio broadcasts and TV programs are recorded. When they take the form of an audio file, the question of copyright protection for these objects arises.
1. Theme urgency
Since the copyright protection mechanism is not perfect from a legal point of view, they need to be protected from a technical point of view. vision by affixing digital watermarks and hiding information directly inside the audio file.
This approach allows you to indicate the author or copyright holder directly on the multimedia product, which unambiguously fixes exclusive rights to it.
2. Goal and tasks of the research
The purpose of the work is to develop an author's method of embedding information into audio files in order to protect copyright.
The following research tasks are highlighted:
- Analysis of existing methods of copyright protection for audio files.
- Justification of the feasibility of developing an author's model for embedding information in audio files.
- Determine the key requirements that an authoring model for protecting audio copyright must meet.
- Development of the author's model for embedding information into audio files in order to protect copyright.
Research object : models and methods of copyright protection for audio files.
Subject of research : development of an author's model of copyright protection for audio files.
3. Analysis of the main methods of embedding information for placing a digital watermark in order to protect copyright for audio files
Steganography is a messaging method that actually hides the very existence of a connection. Unlike cryptography, where the interested a person can accurately determine whether the transmitted message is cipher text, steganography methods allow embedding secret messages into harmless messages so that it was impossible to suspect the existence of an embedded secret message. Steganographic process diagram shown in Figure 1.

Figure 1 - Scheme of the steganographic process
(animation: 6 frames, 7 repetition cycles, 71.8 kilobytes)
(1 - container
2 - embed message
3 - embedding
4 - container with inline message
5 - extract
6 - empty container
7 - message)
The main task of steganographic hiding information inside an audio file is to embed data in such a way as to minimize distortion container object. In this regard, new algorithms and methods for embedding information in audio files are constantly emerging.
Currently, in connection with the rapid development of computer technology, a new direction of steganography has appeared - computer (or digital) steganography, which is aimed at embedding messages in various types of files (text, image, audio, video, etc.). In connection with With the growing role of global computer networks, digital steganography is gaining great importance. Analysis of Internet sources allows conclude that digital steganography is currently being used for the following:
- Covert messaging used for various purposes;
- Protection of confidential information from unauthorized access;
- Overcoming monitoring and management systems for network resources;
- Software camouflage;
- Copyright protection for certain types of intellectual property
Currently, new methods of computer steganography are being developed based on the peculiarities of presenting information in digital form. Some of these methods use palette modification, inaccuracy of digitizing devices, redundancy of audio and video files, and other approaches.
Despite the rapid development of steganographic methods, there is not enough free access software for steganography in audio files. Problem due to the fact that the methods of embedding information into audio files of different bitness are somewhat different. There are currently no universal software solutions for working with audio files of different bitness.
The simplest steganographic method is Least Significant Bits (LSB) replacement. Its idea is as follows: the least the significant bits of the amplitude of the audio signal are replaced by a binary sequence, in which a significant amount of information can be encrypted. The NZB method is a method that exploits the redundancy of audio files. The LSB algorithm is shown in Figure 2.
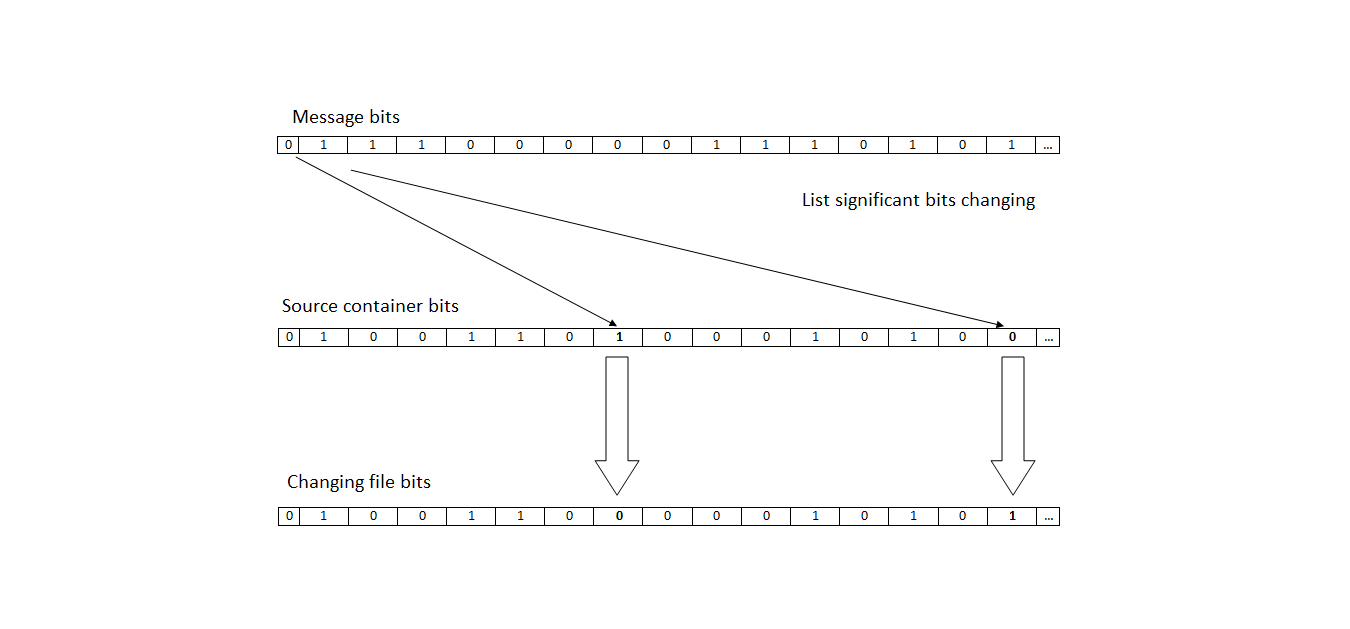
Figure 2 - diagram of the LSB (LSB) algorithm
This group of methods has a number of distinctive features. Among the negative ones, the following can be distinguished: with a change in information, they are distorted statistical characteristics of digital streams. In view of this, correction of statistical characteristics is required to reduce compromising features. The advantages include: the possibility of hidden transmission of a large amount of information, the ability to protect copyright, hidden image, trademark, registration numbers, etc. [1]
Spread spectrum coding is more advanced and robust against noise. The algorithm proposed in [2], satisfies most of the requirements outlined above. DVZ is embedded into audio signals (sequence of 8- or 16-bit samples) by slightly changing the amplitude of each sample. The original audio signal is not required to detect the digital water center.
Let the audio signal consist of N samples x (i), i = 1, ..., N, where the value of N is not less than 88200 (correspondingly 1 second for a stereo audio signal, sampled at 44.1 kHz). In order to embed the digital watermark, the function f (x (i), w (i)) is used, where w (i) is the digital watermark count, within [- ?; ?],? - some constant. The function f must take into account the characteristics of the human hearing system to avoid perceptible distortion. original signal. The counting of the resulting signal is obtained by the formula 1:
y (i) = x (i) + f (x (i), w (i)) (1)
The method proposing to use the weak sensitivity of the human hearing system to minor changes in the signal phase was proposed by V. Bender, N. Morimoto et al. [3]
Audio phase modification information injection is a technique in which the phase of the initial segment of the audio signal is modified depending on embedded data. The phase of the subsequent segments is matched with it to maintain the phase difference. This is necessary because the human phase difference the ear is more sensitive. Phase encoding, when applicable, is one of the most efficient criteria-based encoding techniques. signal-to-noise ratio.
The phase encoding procedure is as follows:
- The audio signal is split into a series of N short segments
- A k-point discrete Fourier transform is applied to the nth signal segment, where K = I / N, and phase and amplitude matrices are created.
- The phase difference between every two adjacent segments is remembered
- A binary data sequence is presented as a new phase
- Taking into account the phase difference, a new phase matrix is ??created for n> 0
- The stego-coded signal is obtained by applying the inverse discrete Fourier transform to the original amplitude matrix and modified phase matrix
The recipient must know the segment length and DFT points. The sequence must be synchronized before decoding.
The disadvantage of this scheme is its low bandwidth. In the experiments of V. Bender and N. Morimoto, the channel capacity was varied from 8 to 32 bits per second.
There is also a method for embedding information by changing the echo delay time. It was suggested by the same authors as the previous algorithm.
This method allows data to be embedded in the cover signal by modifying the echo parameters. The echo parameters carrying the embedded information include: initial amplitude, fall time and offset (the time delay between the original signal and its echo). By decreasing the offset, the two signals are mixed. At a certain point, human the ear ceases to distinguish between the two signals, and the echo is perceived as an additional resonance. This point is difficult to pinpoint as it depends on the original record, such as sound and listener. In general, according to the studies of V. Bender and N. Morimoto, for most types of signals and for most listeners, the merging of two signals occurs when the distance between them is about 0.001 seconds
The encoder uses two delay times, one for encoding a zero and one for encoding a one. Both the delay time is less than that at which the human the ear can recognize the echo. In addition to reducing the delay time, it is necessary to achieve the establishment of the initial amplitude and decay time so that the embedded information does not could be perceived by the human hearing system.
In order to encode more than one bit, the original signal is split into small sections. Each site is considered as a separate signal, and it is embedded one bit of information. The resulting encoded signal (containing several bits of embedded information) is a combination of individual sections.
To achieve minimum visibility, two signals are first generated: one containing only “ones” and the other containing only zeros. Then two switches are created signal - zero and one. Each of them is a binary sequence, the state of which depends on which bit should be inserted into a given section. beep.
Next, the sum of the products of a zero mixing signal and an audio signal with a "zero" delay, as well as a single mixing signal and an audio signal with a delay is calculated "unit". In other words, when it is necessary to embed a “one” in the audio signal, a signal with a “one” delay is applied to the output, otherwise - a signal with a “zero” delay. Since the sum of the two mixing signals is always equal to one, a smooth transition is ensured between the portions of the audio signal in which different bits are embedded. Block diagram stegocoder is shown in Figure 3.

Figure 3 - block diagram of the stegocoder
Decoding embedded information is the determination of the time interval between the signal and the echo. To do this, you need to consider the amplitude (at two points) autocorrelation function of the discrete cosine transform of the logarithm of the power spectrum (cepstrum). As a result of calculating the cepstrum, you get a sequence of pulses (echo duplicated every seconds).
Methods based on the use of format features are no less popular. For example, algorithms for adding information to service fields are in great demand, such as ID3 tags in MP3 files, which contain information about artists, album and comments. You can embed information into the same field, but this is undesirable, since the ID3 field read by each player before playing the audio file.
At the same time, in addition to tags, the audio files may contain Info fields that are no longer decoded by audio players, and, therefore, are potentially suitable for introducing useful information.
The data area of ??WAVE audio files stores uncompressed and in no way altered data received directly from the analog-to-digital converter, so implement steganographic algorithms for files of this type are somewhat simpler and clearer.
Since WAVE files are large enough, they are not used for sharing on the Internet and for storing music on portable devices (players, mobile phones). WAVE files are used where it is necessary to preserve the original appearance of the file of high quality, where there is no limit on the size of free disk space. For example, they are used in recording studios in audio editing programs, where they save time on compression and decompression of data. Due to their large size, these files can store in itself unnecessary or repeated information. Thus, steganographic data hiding can also be performed in them. However, it should not be placed randomly, but pseudo-random. Such a sequence is called a footpath [4].
The choice of the optimal steganographic information hiding method depends on the container object, the required level of resistance to noise and any influences. The most common of the above algorithms is the LSB algorithm, but it is bad in that there are already programs for destroying the steg message, so you cannot be sure that the information will not be destroyed or distorted.
From the point of view of the complexity of the implementation of the system, the greatest difficulties are caused by the spectrum spreading method, since it has the most serious mathematical apparatus among the considered methods. Its advantages also include the fact that only this algorithm is resistant to information destruction when using a filter of medium and low frequencies.
Methods based on the use of format features have the greatest resistance to the impact on the file by increasing the size, since the data is not distorted, being placed in a fixed memory area.
Among the main requirements for information embedding methods are the following:
- Keep the integrity of the container
- Indistinguishable by ear of files with and without a message
- The file should not be suspicious
- Ability to work with files of any bitness
- Ability to determine the volume of the container
- Multi-volume container
Conclusion
From the above features, we can conclude that the choice of the most optimal method for hiding information in audio files depends on the format of the selected container audio file, the required level of resistance to a certain kind of noise and impact, as well as the necessary resistance to compression (since the MP3 format, in contrast to WAV, is used just for storing compressed audio). Steganographic techniques work most effectively on WAV files.
When writing this essay, the master's work has not yet been completed. Final completion: May 2021. Full text of the work and materials on the topic can be obtained from the author or his manager after that date.
References
- Dryuchenko M.A. Algorithms for detecting steganographic information hiding in jpeg files. - Voronezh State University, 2007 .-- 7 p.
- Gribunin V.G. Digital steganography. / V.G. Gribunin, I.N. Okov, I.V. Turintsev - M .: SOLON-PRESS, 2009 - 272 p.
- Bender W., Gruhl B., Morimoto N., Lu A. Techniques for data hiding // IBM Syst. J., 1996. Vol. 35. No. 3.
- Kalintsev, Yu.K. Speech intelligibility in digital vocoders / Yu.K. Kalintsev - M .: Radio and communication, 1991 .-- 320 p.