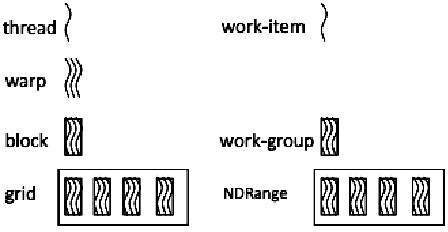
Рис. 1. Архитектура нитей в CUDA и OpenCL
Авторы: Бондарев А.В., Киселёв Ю.И.
Источник:// Достижения науки и образования. 2017. №6 (19). – С. 22-23.
CUDA – одна из самых зрелых и широко используемах структур в программировании GPGPU. OpenCL – молодая и перспективная технология параллельного программирования, которая нацелена на одновременные вычисления как на GPU так и на CPU. Программисты CUDA смогли легко заметить, что у OpenCL есть много общих черт с CUDA.
К сегодняшнему дню стали очень популярны различные разработки беспилотных транспортных средств (ТС). Сейчас существует огромная практика в этой области. Множество известных компаний взялись за разработку таких автомобилей.
Рис. 1 показывает различия архитектуры нитей в CUDA и OpenCL. Левая часть на рис. 1 демонстрирует архитектуру CUDA, а правая часть OpenCL. В CUDA сетка относится к набору всех нитей, которые выполняют ту же самую ядерную функцию. Сетка организована как множество блоков того же самого размера. Блок назначен на текущий мультипроцессор, и далее разделен на единицы с 32 нитями, названные деформациями. Размер деформаций может измениться от одного внедрения до другого. Например, На графических картах серии Nvidia GTX, каждая деформация состоит из 32 нитей. В OpenCL NDRange - N-мерное пространство индекса, где N обозначает один, два или три измерения. Рабочая группа – крупномодульное разложение пространства индекса, которое подобно сетке в CUDA. Взаимодействие с ядром выполнения называют пунктом работы. Это подобно нити в CUDA. Архитектура нити и CUDA и OpenCL одинакова за исключением того, что понятие деформации менее значима в OpenCL. Однако на самом деле деформация - все еще основная единица в создании, управлении, планировании и выполнении нитей мультипроцессорами в OpenCL. Отдельные нити, составляющие деформацию, начинают обращаться вместе в той же самой программе, но в других отношениях свободны ветвиться и выполнить независимо. Когда мультипроцессору дают один или несколько блоков нити, чтобы выполнить, он разделяет их на деформации, которые намечены единицей SIMT [1].
Рис. 1. Архитектура нитей в CUDA и OpenCL

Рис. 2. Сравнение моделей памяти между CUDA и OpenCL в виде таблицы
Рис. 2 показывает различия моделей памяти между CUDA и OpenCL [2]. В CUDA локальная память частная у каждой нити. У каждого блока нити есть общая память, видимая всеми нитями в блоке и с таким же временем «жизни», как и сам блок. Все нити получают доступ к глобальной памяти. К постоянным пространствам памяти и пространствам памяти структуры могут также получить доступ все нити. У памяти структуры есть некоторые свойства, которые делают ее чрезвычайно полезной для вычисления. Например, структура память «прячется», оставляется про запас на чипе, таким образом, в некоторых ситуациях это обеспечивает более высокую эффективную пропускную способность, уменьшая запросы памяти к памяти вне чипа. Определенно, тайники структуры разработаны для графических приложений, где образцы доступа к памяти показывают много пространственной местности. У OpenCL есть почти та же самая модель памяти как CUDA, кроме памяти структуры. Однако у ImageBuffer в OpenCL есть подобные особенности с памятью структуры аналогично CUDA. Кроме того, CUDA использует статический компилятор, чтобы собрать ядро и host код прежде, чем начать программу на GPU. В то время как OpenCL использует ahead-of-time (AOT) или just-in-time (JIT) компилятор, который имеет хорошую мобильность, но будет всегда включать время компиляции в полное время выполнения.