
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження та заплановані результати
- 3. Огляд досліджень та розробок
- 3.1 Огляд міжнародних джерел
- 3.2 Огляд національних джерел
- 3.3 Огляд локальних джерел
- 4. Етапи аналізу тональності тексту
- 5. Методи класифікації текстів
- 5.1 Наївний Баєсовський класифікатор
- 5.2 Метод дерев рішень
- 5.3 Метод опорних векторів
- 5.4 Методи зi штучними нейронними мережами
- Висновки
- Перелік посилань
Вступ
Завдяки сучасним технологіям користувачі отримали можливість ділитися інформацією один з одним, у тому числі висловлювати свою думку щодо всього, що його оточує, чи то книга, фільм, висловлювання відомого діяча чи скарга на службу доставки. Обсяги тексту в Мережі з кожною секундою стають все більшими, тому обробка їх людиною вручну фізично неможлива. Так сформувалася потреба у напрямі, як інтелектуальний аналіз тексту.
Інтелектуальний аналіз тексту (з англ. Text Mining) – автоматизація отримання відомостей з текстових даних. Його особливість (на відміну від аналізу інших даних) полягає у неформалізованості вихідної інформації: її не описати простою математичною функцією [1].
Різним компаніям та корпораціям для проведення успішних дій важливо швидко визначати реакцію користувачів, і ця потреба є однією з ключових для аналізу тональності.
Аналіз тональності (з англ. Sentiment Analysis) – клас методів аналізу вмісту, призначений для автоматизованого виявлення в текстах емоційно забарвленої лексики та емоційної оцінки авторів стосовно об'єктів, про які йдеться в тексті [2]. Основною метою аналізу тональності є знаходження думок у тексті та виявлення їх властивостей. Які саме властивості будуть досліджуватися, залежить від поставленого завдання: метою аналізу може бути автор, тобто особа, якій належить думка.
Завдання визначення тональності тексту завдання класифікації текстів у сенсі. Класифікація документів – одне із завдань інформаційного пошуку (розділ машинного навчання), полягає у віднесенні документа до однієї з кількох категорій виходячи з змісту документа [3]. У разі класами будуть розбиті на підмножини думки, висловлені користувачами.
1. Актуальність теми
В останні роки виникла потреба в інструментах, що дозволяють відстежувати реакцію користувачів інтернету на події, товари та навіть пісні. Позитивні та негативні думки сильні, адже за допомогою них можна здобути довіру покупця або суттєво зіпсувати репутацію серед фанатів. Так, відомо, що 40% покупців формують думку про бізнес після прочитання 1-3 оглядів. Ще можна сказати, що люди набагато частіше вибирають товар серед інших, якщо його рекомендує людина, якій вони довіряють. Процес відстеження думок користувачів можна спробувати автоматизувати, зібравши відгуки, впорядкувавши та обробивши їх відповідним чином, та застосувавши методики аналізу тональності текстів.
Основною метою аналізу тональності є знаходження думок у тексті та виявлення їх властивостей. Досліджувані властивості залежать від поставленого завдання: комусь важлива реакція спільноти на книгу (загалом позитивно/негативно), а для когось, скажімо, косметичної компанії, потрібно проводити детальніший аналіз: наприклад, визначити, до якої цільової аудиторії належить автор тексту та на чому він акцентував увагу. У якості основних інструментальних засобів для вирішення цього завдання використовується мова програмування Python, а також різні бібліотеки для обробки тексту.
Цю мову програмування зазвичай вибирають за універсальність, а також наявність безлічі інструментів (тобто бібліотек), покликаних полегшити роботу.
2. Мета та завдання дослідження, плановані результати
Об'єкт дослідження – визначення тональності тексту.
Предмет дослідження – способи визначення тональності тексту.
Метою дослідження є вивчення підходів до аналізу тональності тексту, а також розробка інструменту для аналізу тональності завантаженого корпусу текстів та генерації статистики на їх основі.
Основні завдання дослідження:
- вивчення існуючих алгоритмів та методів передобробки тексту;
- вивчення алгоритмів визначення тональності тексту;
- створення власного корпусу текстів новин із галузі культури;
- розробка власного алгоритму визначення тональності тексту на прикладі створеного корпусу текстів новин;
- розробка програмної моделі для визначення тональності завантажених текстів та складання статистичних даних на їх основі для демонстрації відношення суспільства (в особі авторів завантажених статей) до різних новин.
Планується, що розроблена програмна модель матиме інтуїтивно зрозумілий інтерфейс користувача, можливість збереження результатів аналізу, а також їх експорту для подальшої роботи в інших програмах.
3. Огляд досліджень та розробок
Розглянемо дослідження з цієї теми.
3.1 Огляд міжнародних джерел
У статті Bing Liu “Sentiment Analysis and Subjectivity” розглядаються взаємозв'язки та відмінності фактів та думок. Думки зазвичай є суб'єктивні висловлювання, які описують почуття, оцінки чи почуття людей стосовно об'єктам, подій та його властивостям.
У статті Bo Pang, Lillian Lee “A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts” вивчається аналіз тональності спрямовано виявлення точки зору (точок), що у основі діапазону тексту. Щоб визначити полярність настроїв, пропонується новий метод машинного навчання, який застосовує методи категоризації тексту лише суб'єктивним частинам документа.
3.2 Огляд національних джерел
У статті Метод визначення емоцій у текстах російською мовою
розглядаються методи автоматичного визначення емоційної складової (тональності) у тексті та описується досвід практичної реалізації системи для текстів ЗМІ російською мовою, в основі якої лежать словники лексичної тональності та набір комбінаторних правил об'єднання окремих слів та словосполучень. У роботі запропоновано метод визначення тональності, що ґрунтується на предикаційних відносинах у пропозиції.
У статті Аналіз тональності російськомовного тексту
як класифікатор використовується наївний байесовський класифікатор. Використовуються різні методи відбору ознак, виробляється порівняння отриманих результатів із результатами класифікації англомовного тексту.
3.3 Огляд локальних джерел
У роботах магістрів не було знайдено такої самої постановки завдання (аналіз тональності тексту з метою характеристики сприйняття суспільством новин), проте подібна тема вже висвітлювалася в магістерських дисертаціях.
Так, Прокапович А.А. у своїй магістерській дисертації на тему Розробка алгоритмічного забезпечення інтелектуального модуля аналізу емоційного змісту мовних повідомлень блогів та форумів
ставив собі за мету аналізувати емоційний
зміст повідомлень з різних блогів та форумів, розробивши при цьому відповідне алгоритмічне забезпечення інтелектуального модуля аналізу; у своїй роботі він розглянув вже існуючі алгоритми, наукову новизну даного підходу,
а також зазначив, що алгоритми, що використовують лінгвістичний підхід, є популярнішими та точнішими.
Пилипенко О.С. теж стосувався цієї теми у своїй роботі з дослідження методів та алгоритмів визначення тональності природно-мовного тексту: він навів порівняння популярних засобів, що визначають унікальність тексту, а також зазначив, що ці засоби (сервіси Text.ru, Antiplagiat.ru, Advego Plagiatus, Etxt Антиплагіат), хоч і виділяють деякі характеристики завантаженого тексту, але не визначають його тональність у вигляді, в якому це передбачається в рамках поставленого завдання.
4. Етапи аналізу тональності тексту
Перш ніж розпочати роботу над визначенням тональності того чи іншого документа, його необхідно опрацювати. Попередня обробка тексту включає приведення всіх слів до нижнього регістру, видалення стоп-слів, токенізацію, лематизацію або стематизацію [4] Всі ці кроки служать для зменшення шуму, властивого будь-якому звичайному тексту, і підвищення точності результатів класифікатора: після виконаних дій як ознак будуть всі значущі слова, що зустрічаються в документі.
Токенізація та видалення стоп-слів
Токенізація – це процес розбиття тексту більш дрібні частини. Слід звернути увагу, що захоплені токени включають розділові знаки та інші рядки, що не відносяться до слів [5]. Стоп-слова – це слова, які можуть мати важливе значення у людському спілкуванні, але не мають сенсу для машин. Фільтрування тексту прибирає займенники та службові слова: артиклі, спілки, прийменники та післялоги [3].
Приведення до нормальної форми: стемінг та лематизація
У процесі нормалізації усі форми слова наводяться до єдиної думки. Є два основні підходи: стемінг та лематизація. Стеммінг (з англ. stemming) – процес знаходження основи слова для заданого вихідного слова, доповнивши яку можна отримати слова-нащадки. Наприклад, лісовий – ліс, похідний – похід [6]. Основа слова може збігатися з морфологічним коренем слова. Такий підхід простий, але і певною мірою наївний – стеммінг просто обрізає рядок, відкидаючи закінчення. Лематизація (з англ. lemmatization) – процес приведення словоформи до леми, тобто базового слова, шляхом відсікання або перетворення флективних закінчень [7]. У російській мові лемами прийнято вважати:
- іменники – в називному відмінку однини;
- прикметники – в називному відмінку однини і чоловічого роду;
- дієслова, причастя та дієприслівника – дієслова у вихідній формі (в інфінітиві).
Можна навести такі приклади: іграшок – іграшка, позитивні – позитивний, бігали – бігати. Таким чином, стеммінг – це спільна операція, а лематизація – інтелектуальна операція, у якій правильна форма виглядатиме у словнику. Отже, лематизація допомагає у формуванні найкращих можливостей машинного навчання. Наступним кроком є представлення кожного токена способом, зрозумілим машині. Цей процес називається векторизацією.
Векторизація за допомогою Word2Vec та bag-of-words
Word2vec – це методика обробки природної мови, опублікована у 2013 році. Word2vec бере на вхід великий корпус текстів і створює векторний простір, що складається з кількох сотень вимірювань, причому кожному унікальному слову в корпусі присвоюється відповідний вектор у цьому просторі. Вектори слів розташовуються у векторному просторі таким чином, що слова, що мають загальні контексти в корпусі, розташовані близько один до одного у просторі [8].
Іншим методом є bag-of-words: для документа формується вектор розмірності словника, кожного слова виділяється своя розмірність, для документа записується ознака (наскільки часто слово зустрічається у ньому), отримуємо вектор. Найбільш поширеним методом для обчислення ознаки є TF-IDF [9] та його варіації (TF – частота слова (з англ. term frequency), IDF – зворотна частота документа (з англ. inverse document frequency)). Плюсом мішка слів є проста реалізація, але варто пам'ятати, що цей метод втрачає частину інформації (наприклад, порядок слів).
5. Методи класифікації текстів
Існує кілька груп методів класифікації тексту. Аналіз з допомогою методів, заснованих на правилах і словниках, полягає у роботі із заздалегідь складеними тональними словниками. Процес складання цих словників дуже трудомісткий і проблемний, оскільки одне слово в різних контекстах може мати різну тональність (наприклад, слово «складний» по відношенню до системи захисту є позитивною характеристикою, але негативною – до процедури реєстрації або авторизації користувача). Для коректного використання у такому разі потрібно скласти велику кількість правил. Існує ряд підходів, що дозволяють автоматизувати складання словників конкретної предметної області. У методах, заснованих на теоретико-графових моделях, текст зображується у вигляді графа на підставі припущення, що деякі слова мають більшу вагу, отже, сильніше впливають на тональність тексту. Тут аналіз тексту починається з побудови графа та ранжування його вершин. Після ранжування слова класифікуються відповідно до словника, де у кожного проаналізованого слова з'являється характеристика (негативний, нейтральний, позитивний). Результат визначається як співвідношення кількості слів із позитивною оцінкою до кількості слів із негативною оцінкою: якщо отримана оцінка близька до 1, то текст нейтральний, більше – позитивний, менше – негативний. Ключовим моментом у методах на основі машинного навчання з учителем є машинний класифікатор, алгоритм роботи з яким виглядає так:
- збір інформації (документів), на основі якої відбуватиметься навчання;
- розкладання кожного документа у вигляді вектора ознак, за якими відбуватиметься аналіз;
- вказівки правильного типу тональності для кожного документа;
- вибір алгоритму класифікації та методу для навчання класифікатора;
- використання отриманої моделі визначення тональності нового набору інформації.
В основі машинного навчання без вчителя лежить ідея, що терміни, які найчастіше зустрічаються у цьому тексті і водночас присутні у невеликій кількості текстів всього набору текстів (колекції), мають найбільшу вагу. Висновок про тональність тексту ґрунтується на виділенні таких термінів та визначенні їх тональності.
5.1 Наївний Байєсовський класифікатор
Один із методів машинного навчання з учителем – наївний Байєсовський класифікатор (з англ. Naive Bayes Classifier) [10], який є приватним варіантом байєсовського класифікатора і заснований на застосуванні теореми Байєса з істотним припущенням, що зміна однієї величини не впливає на зміну іншої величини.
Для цієї моделі теорема Байєса виглядає так:
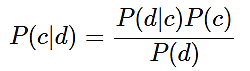 (1)
(1)
де P(c|d) – ймовірність, що документ належить класу c;
P(d|c) – можливість зустріти документ d серед усіх документів класу c;
P(c) – безумовна ймовірність зустріти документ класу c у корпусі документів;
P(d) – безумовна ймовірність документа d у корпусі документів.
Знаменник P(d) у формулі (1) може бути опущений, тому що ймовірність для одного і того ж документа d буде однаковою.
Для визначення найімовірнішого класу використовується оцінка апостериорного максимуму:
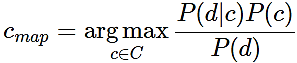 (2)
(2)
Оскільки документ d моделі – це вектор d = {w1, w2, …, wn}, де wi – вага i-ого терміну, а n – розмір словника вибірки, то умовну ймовірність P(d|c) можна виразити як P (w1…wn | c) или же P (w1 | c) * (w2 | c) *...* ( wn | c) = Пi P(wi | cj).
Таким чином, для знаходження найбільш ймовірного класу c потрібно порахувати умовні ймовірності для кожного можливого класу та вибрати той, у якого найбільша ймовірність:
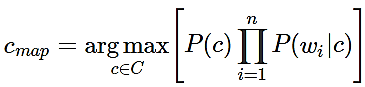 (3)
(3)
Преимущества данного метода:
- висока швидкість роботи;
- щодо проста програмна реалізація алгоритму;
- легка інтерпретність результатів роботи алгоритму.
Недостатки метода:
- відносно низька якість класифікації;
- нездатність враховувати залежність результату класифікації від поєднання ознак [11].
5.2 Метод дерев рішень
Деревом рішень називають ациклічний граф, яким проводиться класифікація об'єктів (у разі документів), описаних набором ознак. Кожен вузол дерева містить умову розгалуження за однією з ознак. У кожного вузла стільки розгалужень, скільки значень має обрану ознаку. У процесі класифікації здійснюються послідовні переходи від одного вузла до іншого відповідно до значень ознак об'єкта. Класифікація вважається завершеною, коли досягнуто одного з листя (кінцевих вузлів) дерева. Значення цього листа визначить клас, якому належить об'єкт, що розглядається. Насправді зазвичай використовують бінарні дерева рішень, у яких прийняття рішення переходу по ребрах здійснюється простою перевіркою наявності ознаки у документі. Якщо значення ознаки менше певного значення, вибирається одна гілка, якщо більше чи одно, інша. Приклад дерева рішень представлений малюнку 2 [12].

Рисунок 1 – Приклад дерева рішень (анімація: 10 кадрів, 10 циклів повторення, 66,1 кілобайт)
Алгоритм побудови дерева рішень складається з наступних кроків:
- створюється перший вузол дерева, куди входять усі документи, представлені всіма наявними ознаками; розмір вектора ознак кожного документа дорівнює n, оскільки d = (t1, …, tn);
- для поточного вузла дерева вибираються найбільш підходяща ознака tk та його найкраще прикордонне значення vk;
- на основі прикордонного значення обраної ознаки проводиться поділ навчальної вибірки на дві частини, обраний ознака не включається до опису фрагментів у цих частинах;
- підмножини, що утворилися, обробляються аналогічно доти, поки в кожному з них не залишаться документи тільки одного класу або ознаки для розрізнення документів.
Переваги дерев рішень:
- щодо проста програмна реалізація алгоритму;
- легка інтерпретність результатів роботи алгоритму.
Недоліки:
- нестійкість алгоритму щодо викидів у вихідних даних;
- великий обсяг даних для отримання точних результатів.
5.3 Метод опорних векторів
Метод належить до сімейства лінійних класифікаторів. У цьому поході кожен об'єкт представляється як вектор (точка) в p-мірному просторі. Кожна з точок належить одному із двох класів. Завдання методу – перетворити простір за допомогою оператора ядра так, щоб знайшлися такі гіперплощини, які поділяють приклади різних класів навчальної вибірки. Якщо така гіперплощина існує, вона називається оптимальною розділюючою гіперплощиною, а відповідний їй лінійний класифікатор називається оптимально розділяючим класифікатором [13]. Насправді структура даних буває невідома і дуже рідко вдається побудувати роздільну гіперплощину, отже, неможливо гарантувати лінійну роздільність вибірки. Можуть існувати такі документи, які алгоритм зарахує до одного класу, а насправді вони мають належати до протилежного. Такі дані називаються викидами. Вони створюють похибку методу, тому краще їх ігнорувати [4]. На рисунку 2 показано графічну інтерпретацію методу.
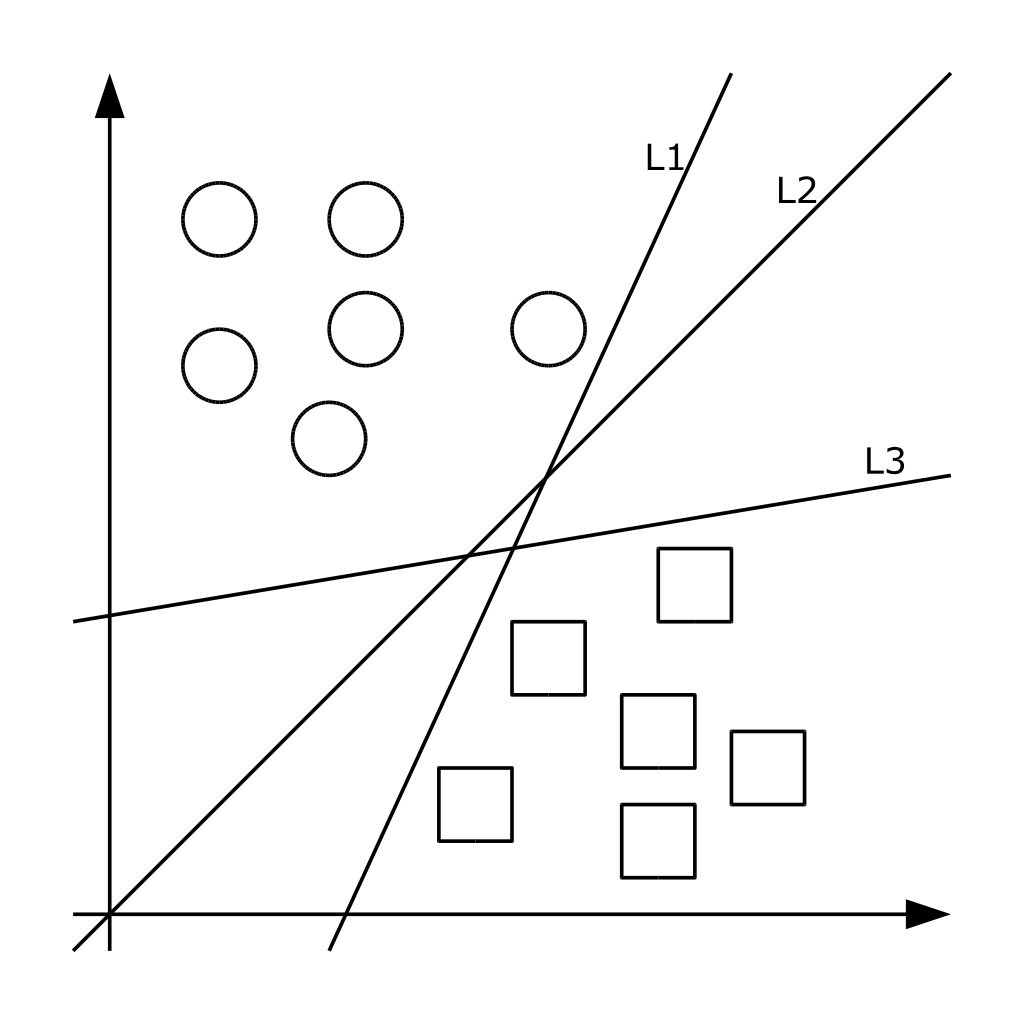
Рисунок 2 – Графічна інтерпретація методу опорних векторів
Переваги методу:
- один із найбільш якісних методів;
- можливість роботи з невеликим набором даних для навчання;
- зведення до завдання опуклої оптимізації, що має єдине рішення.
Недоліки методу:
- складна інтерпретованість параметрів алгоритму;
- нестійкість по відношенню до викидів у вихідних даних [4].
5.4 Методи зi штучними нейронними мережами
Методів, заснованих на нейронних мережах, досить багато. Основними з них є мережі прямого поширення, рекурентні мережі, радіально базисні функції та карти, що самоорганізуються. Налаштування ваг у методах може бути фіксованим або динамічним.
У класичних нейронних мережах прямого розповсюдження (Feed Forward Back Propagation, FFBP) присутні вхідний шар, вихідний шар та проміжні шари: сигнал йде послідовно від вхідного шару нейронів проміжними шарами до вихідного. Прикладом такої структури є багатошаровий перцептрон.
Для класифікації документа з допомогою нейронної мережі прямого поширення ваги ознак документа подаються відповідні входи мережі. Активація поширюється через мережу; значення, що вийшли на виходах, і є результатом класифікації. Стандартний метод навчання такої мережі – метод зворотного розповсюдження помилки. Суть його в наступному: якщо на одному з виходів для одного з навчальних документів отримано неправильну відповідь, то помилка поширюється назад по мережі та ваги ребер змінюються так, щоб зменшити помилку.
Кількість проміжних шарів нейронної мережі може бути не заздалегідь, таку архітектуру називають динамічною. В цьому випадку шари послідовно динамічно генеруються доти, доки не буде досягнутий потрібний рівень точності.
Згорткова нейронна мережа – односпрямована багатошарова мережа із застосуванням операції згортки, коли кожен фрагмент вхідних даних множиться на матрицю (ядро) згортки поэлементно, а результат підсумовується і записується в аналогічну позицію вихідних даних. Рекурентна нейронна мережа виходить із багатошарового перцептрону запровадженням зворотних зв'язків. Один з найпоширеніших різновидів рекурентних нейронних мереж – мережа Елмана. У ній зворотні зв'язки йдуть немає від виходу мережі, як від виходів внутрішніх нейронів. Це дозволяє врахувати передісторію процесів і накопичити інформацію для вироблення правильної стратегії навчання. Головною особливістю рекурентних нейронних мереж є запам'ятовування послідовностей.
Переваги методу:
- має дуже високу якість алгоритму при вдалому доборі параметрів;
- є універсальним апроксиматором безперервних функцій;
- підтримує інкрементне навчання.
Недоліки методу:
- можливість можливої розбіжності або повільної збіжності, оскільки для налаштування мережі використовуються градієнтні методи;
- необхідність дуже великого обсягу даних для навчання, щоб досягти високої точності;
- низька швидкість навчання;
- складна інтерпретованість параметрів алгоритму [4].
Згорткові нейронні мережі
Згорткова нейронна мережа (англ. convolutional neural network, CNN) – спеціальна архітектура штучних нейронних мереж, запропонована Яном Лекуном в 1988 році і націлена на ефективне розпізнавання образів, входить до складу технологій глибокого навчання (deep-learning) [14].
Згорткові нейронні мережі забезпечують часткову стійкість до змін масштабу, зсувів, поворотів, зміни ракурсу та інших спотворень. Згорткова нейронна мережа та її модифікації вважаються найкращими за точністю та швидкістю алгоритмами знаходження об'єктів на сцені. Саме тому їх використання найбільш поширене у завданнях, пов'язаних із розпізнаванням зображень.
Переваги:
- набагато менша кількість ваг, що настроюються, так як одне ядро ваг використовується цілком для всього об'єкта, замість того, щоб робити для кожної її складової свої персональні вагові коефіцієнти. Це підштовхує нейромережу при навчанні до узагальнення інформації, що демонструється;
- зручне розпаралелювання обчислень, а, отже, можливість реалізації алгоритмів роботи та навчання мережі на графічних процесорах;
- навчання за допомогою класичного методу зворотного розповсюдження помилки.
Недоліки методу:
- занадто багато параметрів мережі, що варіюються; незрозуміло, для якого завдання та обчислювальної потужності які потрібні налаштування.
Вхідними даними згорткової нейронної мережі є матриця з фіксованою висотою n, де кожен рядок являє собою векторне відображення слова ознаковий простір розмірності k [14].
Висновки
Переважними для подальшого дослідження можна назвати метод опорних векторів (за якісні результати аналізу та можливість навчання невеликого масиву даних), наївний байесовський класифікатор (за високу швидкість роботи та просту інтерпретованість результатів) та методи, пов'язані з нейронними мережами.
Перелік посилань
- Интеллектуальный анализ текста, или Text Mining [Электронный ресурс]. – Режим доступа: интеллектуальный-анализ-текста-что-это-и-зачем-он-нужен.aspx . – Заглавие с экрана.
- Анализ тональности текста [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Анализ_тональности_текста. – Заглавие с экрана.
- Классификация документов методом опорных векторов [Электронный ресурс]. – Режим доступа: – Режим доступа: https://habr.com/ru/post/130278/. – Заглавие с экрана.
- Батура Т.В. Методы автоматической классификации текстов / Т.В. Батура // Программные продукты и системы. 2017. Т. 30. № 1. С. 85–99; DOI: 10.15827/0236-235X.030.1.085-099.
- Анализ данных и процессов: учеб. пособие / А. А. Барсегян, М. С. Куприянов, И. И. Холод, М. Д. Тесс, С. И. Елизаров. – 3-е изд., перераб. и доп. – СПб.: БХВ-Петербург, 2009. – 512 с.
- Что такое стемминг [Электронный ресурс]. – Режим доступа: https://habr.com/ru/post/130278/ https://textis.ru/stemming/. – Заглавие с экрана.
- Лемматизация [Электронный ресурс]. – Режим доступа: https://cropas.by/seo-slovar/lemmatizatsiya/. – Заглавие с экрана.
- Word2Vec [Электронный ресурс]. – Режим доступа: https://en.wikipedia.org/wiki/Word2vec. – Заглавие с экрана.
- TF-IDF [Электронный ресурс]. – Режим доступа: https://seonomad.net/slovar/tf-idf. – Заглавие с экрана.
- Наивный байесовский классификатор [Электронный ресурс]. – Режим доступа: http://bazhenov.me/blog/2012/06/11/naive-bayes.html. – Заглавие с экрана.
- Классификация текстов и анализ тональности [Электронный ресурс]. – Режим доступа: http://neerc.ifmo.ru/wiki/index.php?title=Классификация_текстов_и_анализ_тональности – Заглавие с экрана.
- Decision Trees – scikit-learn [Электронный ресурс]. – Режим доступа: – Режим доступа: https://scikit-learn.org/stable/modules/tree.html. – Заглавие с экрана.
- Метод опорных векторов [Электронный ресурс]. – Режим доступа: – Режим доступа: https://ru.wikipedia.org/wiki/Метод_опорных_векторов. – Заглавие с экрана.
- Сверточные нейронные сети [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Свёрточная_нейронная_сеть. – Заглавие с экрана.