Аннотация
Бердюкова С.С., Коломойцева И.А. Исследование применения сверточных нейронных сетей для анализа тональности текста. В данной статье приведены основные определения, касающиеся сверточных сетей, их преимущества и недостатки, а также области их использования при работе с текстами. Также были описаны меры, примененные к текстам перед анализом. Приведены результаты работы сети по определению тональности предложенных текстов.
Введение
В последние годы возникла потребность в инструментах, позволяющих отслеживать реакцию пользователей интернета на события, товары и даже песни. Положительные и отрицательные мнения сильны, ведь с помощью них можно завоевать доверие покупателя или существенно испортить репутацию среди фанатов. Так, известно, что 40% покупателей формируют мнение о бизнесе после прочтения 1-3 обзоров. Еще можно сказать, что люди гораздо чаще выбирают товар среду прочих других, если его рекомендует человек, которому они доверяют.
Процесс отслеживания мнений пользователей можно попытаться автоматизировать, собрав отзывы, упорядочив и обработав их соответствующим образом, и применив методики анализа тональности текстов.
Анализ тональности (с англ. Sentiment Analysis) – класс методов анализа содержимого, предназначенный для автоматизированного выявления в текстах эмоционально окрашенной лексики и эмоциональной оценки авторов по отношению к объектам, речь о которых идёт в тексте [1].
Основной целью анализа тональности является нахождение мнений в тексте и выявление их свойств. Исследуемые свойства зависят от поставленной задачи: кому-то важна реакция сообщества на книгу (в целом положительно/негативно), а для кого-то, скажем, косметической компании, потребуется проводить более детальный анализ: например, определить, к какой целевой аудитории принадлежит автор текста и на чем он акцентировал внимание.
Предварительная обработка и индексация документов
Прежде чем начать работу над определением тональности того или иного документа, его необходимо обработать. Предварительная обработка текста включает в себя приведение всех слов к нижнему регистру, удаление стоп-слов, токенизацию, лемматизацию или стемматизацию [2].
Все эти шаги служат для уменьшения шума, присущего любому обычному тексту, и повышения точности результатов классификатора: после проделанных действий в качестве признаков будут выступать все значимые слова, встречающиеся в документе.
Токенизация и удаление стоп-слов
Токенизация – это процесс разбиения текста на более мелкие части. Следует обратить внимание, что захваченные токены включают знаки препинания и другие строки, не относящиеся к словам [3].
Стоп-слова – это слова, которые могут иметь важное значение в человеческом общении, но не имеют смысла для машин. Фильтрация текста убирает местоимения и служебные слова: артикли, союзы, предлоги и послелоги [4].
Приведение к нормальной форме: стемминг и лемматизация
В процессе нормализации все формы слова приводятся к единому представлению. Есть два основных подхода: стемминг и лемматизация.
Стемминг (с англ. stemming) – процесс нахождения основы слова для заданного исходного слова, дополнив которую можно получить слова-потомки. Например, лесной – лес, походный – поход, столовый – стол [5].
Основа слова может не совпадать с морфологическим корнем слова. Такой подход прост, но и в какой-то мере наивен – стемминг просто обрезает строку, отбрасывая окончание.
Лемматизация (с англ. lemmatization) – процесс приведения словоформы к лемме, то есть базовому слову, путем отсечения или преобразования флективных окончаний [6].
В русском языке леммами принято считать:
- имена существительные – в именительном падеже единственного числа;
- имена прилагательные – в именительном падеже единственного числа и мужского рода;
- глаголы, причастия и деепричастия – глаголы в исходной форме (в инфинитиве).
Можно привести такие примеры: игрушек – игрушка, позитивные – позитивный, бегали – бегать.
Таким образом, стемминг – это общая операция, а лемматизация – интеллектуальная операция, в которой правильная форма будет выглядеть в словаре. Следовательно, лемматизация помогает в формировании лучших возможностей машинного обучения.
Следующим шагом является представление каждого токена способом, понятным машине. Этот процесс называется векторизацией.
Векторизация с помощью Word2Vec
Word2vec – это методика обработки естественного языка, опубликованная в 2013 году.
пространство, обычно состоящее из нескольких сотен измерений, причем каждому уникальному слову в корпусе присваивается соответствующий вектор в этом пространстве. Векторы слов располагаются в векторном пространстве таким образом, что слова, имеющие общие контексты в корпусе, располагаются близко друг к другу в пространстве [7].
Сверточные нейронные сети
Сверточная нейронная сеть (англ. convolutional neural network, CNN) – специальная архитектура искусственных нейронных сетей, предложенная Яном Лекуном в 1988 году и нацеленная на эффективное распознавание образов, входит в состав технологий глубокого обучения (deep-learning) [8].
Сверточные нейронные сети обеспечивают частичную устойчивость к изменениям масштаба, смещениям, поворотам, смене ракурса и прочим искажениям. Сверточная нейронная сеть и ее модификации считаются лучшими по точности и скорости алгоритмами нахождения объектов на сцене. Именно поэтому их использование наиболее распространено в задачах, связанных с распознаванием изображений.
Преимущества:
- один из лучших алгоритмов по распознаванию и классификации изображений;
- гораздо меньшее количество настраиваемых весов, так как одно ядро весов используется целиком для всего объекта, вместо того, чтобы делать для каждой ее составляющей свои персональные весовые коэффициенты. Это подталкивает нейросеть при обучении к обобщению демонстрируемой информации;
- удобное распараллеливание вычислений, а, следовательно, возможность реализации алгоритмов работы и обучения сети на графических процессорах;
- обучение при помощи классического метода обратного распространения ошибки.
Недостатки:
- слишком много варьируемых параметров сети; непонятно, для какой задачи и вычислительной мощности какие нужны настройки.
Входными данными сверточной нейронной сети является матрица с фиксированной высотой n, где каждая строка представляет собой векторное отображение слова в признаковое пространство размерности k [8].
Применение сверточной нейронной сети для анализа
Для работы был выбран набор коротких текстов, сформированный на основе русскоязычных сообщений из социальной сети Twitter. RuTweetCorp содержит 114 911 «заведомо положительных», 111 923 «заведомо отрицательных» твитов, а также базу неразмеченных твитов объемом 17 639 674 текстов [9].
Распределение длины твитов показано на рисунке 1. Можно увидеть, что максимальная длина твита – 33 символа. Для векторизации текстов можно выбрать размерность в 28 – так можно покрыть почти все тексты в корпусе.
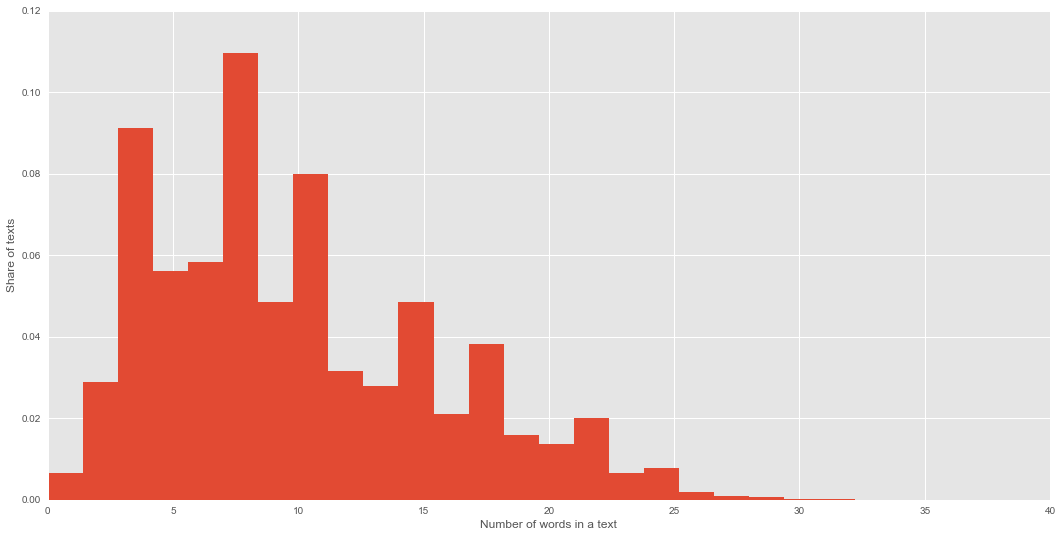
Рисунок 1 – Распределение длины текстов
Перед началом работы твиты прошли процедуру предварительной обработки: все символы были приведены к нижнему регистру, буква «ё» заменена на «е», удалены знаки пунктуации.
Слои нейронной сети обучались в течение 10 эпох, размер партии – 32.
Качество работы классификатора оценивалось по таким критериям, как точность, полнота и f-мера.
Точность (с англ. precision) – доля документов, являющихся положительными от общего числа примеров, классифицированных как положительные.
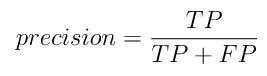 (1)
(1)
Полнота (с англ. recall) – доля правильно классифицированных положительных примеров от общего числа положительных примеров.
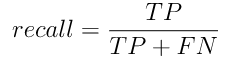 (2)
(2)
F-мера – мера, комбинирующая точность и полноту. F-мера достигает максимума при полноте и точности, равными единице, и близка к нулю, если один из аргументов близок к нулю. [10].
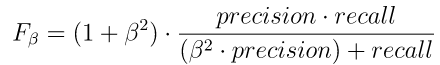 (3)
(3)
Полученные результаты оценивания приведены в таблице 1.
| Метка класса | Точность | Полнота | F-мера | Количество объектов |
|---|---|---|---|---|
| 0 (отрицательные) | 0.77503 | 0.77272 | 0.77388 | 22457 |
| 1 (положительные) | 0.77194 | 0.77426 | 0.77310 | 22313 |
| Среднее | 0.77349 | 0.77349 | 0.77349 | 44770 |
Выводы
В данной статье были рассмотрены меры, применимые к исследуемым текстам перед анализом. Рассмотрен принцип работы свреточных нейронных сетей. Приведены результаты работы сети по определению тональности предложенных текстов (твитов).
Сверточная нейронная сеть показала себя достаточно хорошо в определении тональности предложенных текстов (F-мера = 77,35%). Тем не менее, стоит продолжить исследование работы данной модели (в частности, взять другой корпус текстов, провести более тщательную предварительную обработку текстов, провести эксперименты с разным количеством эпох обучения или слоев сети).
Литература
1. Анализ тональности текста – Режим доступа: https://ru.wikipedia.org/wiki/Анализ_тональности_текста. – Заглавие с экрана.
2. Батура Т.В. Методы автоматической классификации текстов / Т.В. Батура // Программные продукты и системы. 2017. Т. 30. № 1. С. 85–99;
DOI: 10.15827/0236-235X.030.1.085-099.
3. Анализ данных и процессов: учеб. пособие / А. А. Барсегян, М. С. Куприянов, И. И. Холод, М. Д. Тесс, С. И. Елизаров. – 3-е изд., перераб. и доп. – СПб.: БХВ-Петербург, 2009. – 512 с.
4. Классификация документов методом опорных векторов – Режим доступа: https://habr.com/ru/post/130278/. – Заглавие с экрана.
5. Что такое стемминг – Режим доступа: https://textis.ru/stemming/. – Заглавие с экрана.
6. Лемматизация – Режим доступа: https://en.wikipedia.org/wiki/Word2vec. – Заглавие с экрана.
7. Word2Vec – https://en.wikipedia.org/wiki/Word2vec. – Заглавие с экрана.
8. Сверточные нейронные сети – Режим доступа: https://ru.wikipedia.org/wiki/Свёрточная_нейронная_сеть. – Заглавие с экрана.
9. Рубцова Ю. Автоматическое построение и анализ корпуса коротких текстов (постов микроблогов) для задачи разработки и тренировки тонового классификатора // Инженерия знаний и технологии семантического веба. – 2012. – Т. 1. – С. 109-116.
10. Метрики в задачах машинного обучения – Режим доступа: https://habr.com/ru/company/ods/blog/328372/. – Заглавие с экрана.