Manika Sharma, A Survey and Classification on Recommendation Systems / Manika Sharma, Raman Mittal, Ambuj Bharati, Deepika Saxena, Ashutosh Kumar Singh // 7th International Conference on Smart Computing & Communications, National Institute of Technology, Kurukshetra, Jan 2022 [Ссылка]
Обзор и классификация рекомендательных систем
Manika Sharma, Raman Mittal, Ambuj Bharati, Deepika Saxena, Ashutosh Kumar Singh
Department of Computer Application, National Institute of Technology, Kurukshetra
136119, Kurukshetra, Haryana, India
Аннотация: В современном мире объем данных растет в геометрической прогрессии, и традиционные системы не в состоянии удовлетворить требования пользователей. Для удовлетворения потребностей пользователей различные компании, такие как Amazon, Netflix и т.д. используют рекомендательные системы, которые рекомендуют контент или различные типы данных на основе предыдущих действий пользователя и взаимодействий с системой. В рекомендательной системе представлены в основном три подхода: контент-ориентированный, коллаборативная фильтрация и подходы, основанные на знаниях. Благодаря их широкой применимости рекомендательные системы стали областью активных исследований, и в этом контексте в данной статье представлен обзор и сравнительная характеристика существующих подходов. В исследовании делается вывод о том, как различные методы рекомендаций взаимодействуют с современными растущими технологическими тенденциями, а также обсуждаются проблемы, с которыми они сталкиваются.
Ключевые слова: коллаборативная фильтрация, фильтрация на основе контента, гибридные методы, фильтрация на основе знаний, рекомендательная система
1. Введение
С ростом технологических достижений в настоящее время в Интернете доступно огромное количество данных, что делает просмотр продуктов по своему выбору для пользователя довольно утомительным. Кроме того, для поставщиков цифровых услуг стало сложной задачей привлекать множество пользователей на макисмально длительное время в свои приложения. Вот тут-то и появляется система рекомендаций. Рекомендательные системы рекомендуют контент или различные типы данных на основе предыдущих действий пользователя и взаимодействия с системой. Различные приложения для поиска фильмов, музыки, книг, новостей и т.д., внедряют рекомендательные системы. Наглядными примерами систем рекомендаций являются рекомендации по продуктам на Amazon, рекомендации Netflix по фильмам и телешоу, рекомендации по видео на YouTube, музыке на Spotify и многое другое. Большинство рекомендательных систем показывают рекомендации пользователю, чтобы обеспечить лучший пользовательский опыт. Система предлагает пользователям материалы по их выбору и вкусу на основе обширного набора товаров и описания их потребностей. Такие системы помогают пользователям лучше взаимодействовать с приложением и, таким образом, увеличивают количество времени, проводимое пользователем в этом приложении.
Какой мобильный телефон мне купить? Какое место отдыха лучше всего подходит для меня и
моей семьи? Какие фильмы мне следует смотреть? Какую книгу мне следует взять напрокат или купить? Какую
песню мне следует послушать? Этот список можно легко расширить множеством подобных вопросов, по которым необходимо принять какое-то решение. Неправильные решения могут привести к пустой трате
времени и денег. Традиционно люди использовали различные стратегии для решения таких
проблем, как серфинг в Интернете, принятие предложений от друга или просто наблюдение за другими людьми. Однако все мы сталкивались с ситуациями, в которых эти методы
плохо работают. Хороший совет трудно получить, в большинстве случаев на это уходит много времени
и даже тогда он часто бывает сомнительного качества. Теперь представьте себе систему, которая действительно
дает отличные качественные советы и, самое главное, ей можно доверять.
Большинство из нас уже так или иначе сталкивались с рекомендательными системами.
Представьте, например, что вы идете в интернет-магазин, чтобы что-то купить. После совершения
покупки вы оцениваете купленный товар как 9/10. Итак, в следующий раз, когда вы посетите
магазин, вы увидите, что вам рекомендуют похожие товары в разделе похожие
товары
, или вы увидите раздел под названием люди, которые купили это, также
купили
. Эти разделы состоят из продуктов, похожих
на недавно купленный продукт, или продуктов, которые покупают пользователи, имеющие схожий интерес.
Программная система, которая определяет, какие продукты должны быть показаны пользователю, является системой рекомендаций. Большинство поставщиков услуг стремятся повысить качество обслуживания клиентов в своих приложениях. Но с огромным количеством данных, доступных в Интернете, пользователям
трудно не только искать то, что они хотят, но даже выяснить
чего они хотят в первую очередь. Таким образом, система рекомендаций улучшает опыт пользователя, что, в свою очередь, укрепляет отношения между пользователем и
поставщиком услуг, это иллюстрирует рис. 1. Рекомендательные системы могут быть как персонализированными, так и обезличенными. Приведенный выше пример относится к персонализированной
системе рекомендаций. Другими словами, каждый посетитель видит разный список товаров в зависимости от
своих интересов.
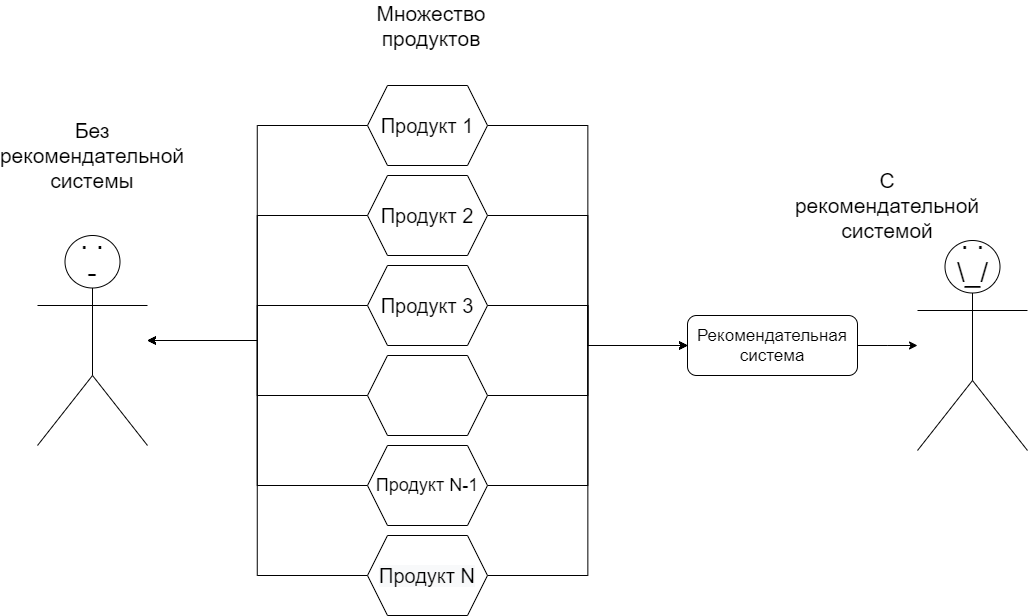
Рис. 1. Рекомендательная система
Напротив, многие магазины или веб-порталы показывают свои самые продаваемые товары или наиболее просматриваемые или покупаемые товары, теоретически это можно интерпретировать как пример обезличенной рекомендации. Предоставление персонализированных рекомендаций, однако, требует, чтобы система знала что-то о каждом пользователе, и каждая система рекомендаций разрабатывает и поддерживает пользовательскую модель для предоставления рекомендаций. Хотя существование пользовательской модели зависит от способа получения информации с использованием какой-либо конкретной техники.
Несмотря на популярность рекомендательных алгоритмов, некоторые исследовательские вопросы остаются без ответа. Каково современное состояние рекомендательных систем? Каковы наиболее распространенные подходы, используемые для внедрения и оценки систем рекомендаций? Каковы исследовательские проблемы при разработке системы рекомендаций?
Остальная часть статьи структурирована следующим образом. В разделе 1.1 мы обсуждаем классификацию различных основных методов, используемых в системах рекомендаций. Вклад этого документа объясняется в разделе 1.2. Далее, в разделе 2, мы представили обзор литературы по различным традиционным и передовым подходам, которые помогут в будущих исследованиях в этой области. В том же разделе этой статьи также представлена хорошо структурированная сравнительная таблица, в которой сравниваются различные существующие методы. В разделе 3 мы обсуждаем возникающие тенденции и будущие возможности в области систем рекомендаций. Наконец, раздел 4 завершает нашу статью.
1.1 Классификация
Рекомендательные системы можно разделить на основанные на содержании, основанные на коллаборативной фильтрации, основанные на знаниях и гибридные. Рисунок 2 показывает классификацию различных основных методов, используемых в системах рекомендаций. Эти методы очень популярны для создания рекомендательных систем и успешно используются во многих приложениях.
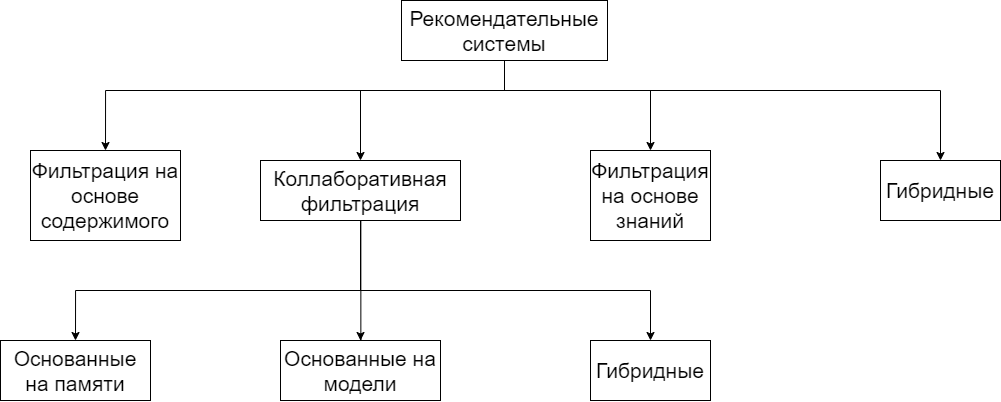
Рис. 2. Классификация рекомендательных систем
Метод фильтрации на основе содержимого
Методы, основанные на содержимом, проиллюстрированные на рис. 3, должны анализировать только элементы и профиль пользователя для получения рекомендаций. Он рекомендует контент на основе истории посещений пользователя, количества кликов и просмотренных продуктов. Этот подход может предлагать товары без рейтинга и полностью основан на рейтинге пользователя; однако он не работает для новых пользователей, которые еще ничего не оценили. В подходе, основанном на содержании, нет рекомендаций по элементам, которые являются неожиданными для пользователя (случайные элементы), и это не будет работать, если система не сможет распознать контент, который не нравится пользователю.
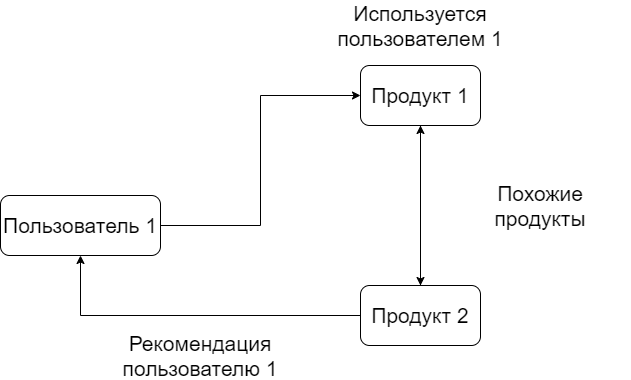
Рис. 3. Фильтрация на основе содержимого
Метод коллаборативной фильтрации
С другой стороны, методы коллаборативной фильтрации, проиллюстрированные на рис. 4 работают, находя сходство между разными пользователями и рекомендуя используемые ими продукты. Две основные классификации методов коллаборативной фильтрации – это подход, основанный на памяти, и подход, основанный на модели. Подход, основанный на памяти, работает в основном в три этапа: Измерение сходства между пользователями обучения и целевым пользователем, определение ближайших соседей целевого пользователя (т.е. пользователей, которые очень похожи на целевого пользователя) и составление окончательного списка рекомендаций. Подход, основанный на модели, учитывает поведение пользователей при оценке вместо непосредственного использования данных рейтинга. Данные рейтинга используются для извлечения параметров модели, что приводит к повышению точности и производительности.
Рекомендация коллаборативной фильтрации зависит от поведения пользователя и не зависит от контента. Потому что предложения основаны на сходстве пользователей вместо сходства предметов. Этот метод также дает случайные рекомендации. Но проблема с этим подходом заключается в том, что он не может рекомендовать товары новым пользователям (проблема холодного старта). Этот метод также затрудняет рекомендацию товаров тем пользователям, которые имеют особые интересы и отличаются от большинства людей. Это происходит потому, что они
могут не соглашаться или не соглашаться с остальными пользователями, создавая трудности в получении
соответствующих результатов (Проблема белой вороны
).
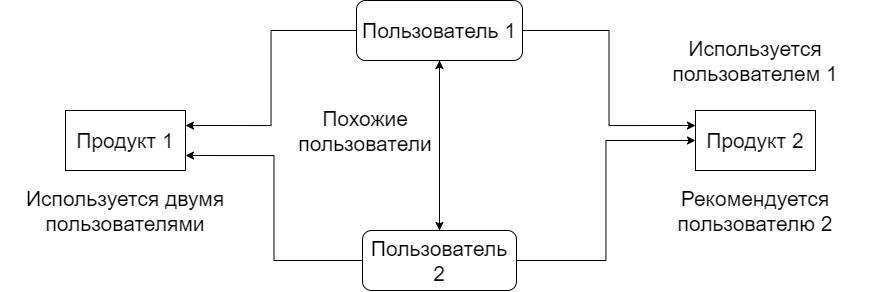
Рис. 4. Коллаборативная фильтрация
Проблема разреженности, которая относится к обстоятельствам, при которых данные разрежены и недостаточны для поиска параллелей в интересах потребителей, является еще одним фундаментальным недостатком этой стратегии. Скудные данные означают, что потребители оценили небольшое количество товаров, что затрудняет рекомендацию достаточного количества товаров.
Метод фильтрации, основанный на знаниях
Как коллаборативные, так и основанные на содержимом рекомендательные методы имеют свои преимущества и сильные стороны. Однако существует много ситуаций, когда эти подходы не являются хорошим выбором. Недвижимость, автомобили, финансовые услуги и другие предметы роскоши являются примерами подобных ситуаций. Как правило, люди не очень часто покупают эти товары. Таким образом, в этом сценарии коллаборатинвая фильтрация и метод на основе содержимого не будут работать корректно из-за малого количества доступных оценок или низкого взаимодействия пользователя с системой. Наконец, в более сложных областях продуктов, таких как недвижимость, клиенты часто желают четко указать свои требования, такие как местоположение или цвет объекта, и системы рекомендаций, основанные на знаниях, могут помочь нам решить все эти проблемы. Иными словами, подходы, основанные на знаниях, показанные на рис. 5, не требуют какой-либо оценки для рекомендации продуктов; вместо этого процесс рекомендации основан на сходстве между требованиями заказчика и описаниями товаров или на использовании ограничений, устанавливающих требования к использованию.
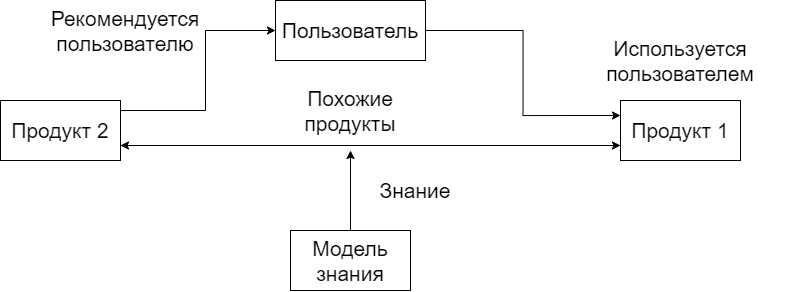
Рис. 5. Фильтрация, основанная на знаниях
Гибридный подход
Поскольку каждый из вышеупомянутых подходов имеет свой собственный набор преимуществ и недостатков, гибридные методы, как показано на рис. 6, используются для объединения преимуществ различных подходов для создания системы, которая хорошо работает в широком диапазоне применений. Современные системы используют различные передовые алгоритмы для решения существующих проблем. Например, для решения проблемы разреженности, большинством использует подходы методов кластеризации и нормализации. Метод анализа демографических и ассоциативных правил используются для решения проблемы холодного старта, и они были признаны довольно эффективными. K-ближайшие соседи (KNN) и Дерево частых шаблонов (FP) объединены для получения качественных предложений, преодолевающих многие недостатки существующих подходов.
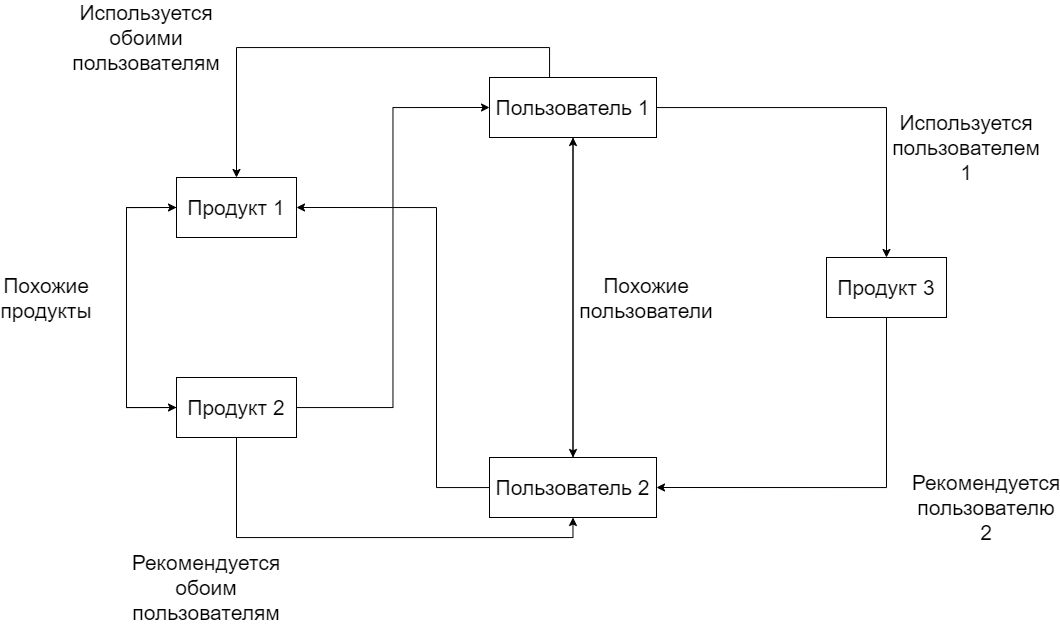
Рис. 6. Гибридный подход
Единственная проблема с традиционными гибридными системами заключается в том, что они используют прошлую информацию о пользователях для рекомендации контента. Допустим, пользователь, который долгое время использует приложение на основе гибридной системы, внезапно прекращает использовать приложение. Через несколько дней, когда пользователь повторно посетит веб-сайт, система порекомендует товары, основанные на интересе, проявленном ранее, которые могут быть неактуальны сейчас.
1.2 Материалы статьи
Хотя методы, используемые в современных рекомендательных системах, были созданы более десяти лет назад, в настоящее время в этой области проводятся активные исследования, поскольку Интернет стал жизненно важной частью жизни каждого человека, в то время как новые технологии появляются ежедневно. Основная цель этой статьи состоит в том, чтобы собрать все различные существующие технологии в одном месте и сравнить их на основе различных параметров. В документе делается вывод о том, как различные методы рекомендаций взаимодействуют с современными растущими технологическими тенденциями, а также обсуждаются проблемы, с которыми они сталкиваются. В конце этой статьи также был предложен новый гибридный метод, который может устранить некоторые ограничения, с которыми сталкиваются существующие методы.
2. Обзор литературы
Большая работа была проделана в области систем рекомендаций с использованием различных издательских форумов. Здесь, в этом разделе, мы провели обширное исследование различных традиционных и передовых подходов и предоставили для них опрос, который поможет в будущих исследованиях в этой области. Кроме того, в таблице 1 показано сравнение многих подходов, которые были предложены.
2.1 Метод фильтрации на основе содержимого
Система рекомендаций товаров, основанная на фильтрации на основе содержимого, предложенная в [1], использует алгоритм машинного обучения XGBoost для рекомендации товаров пользователям на основе их предыдущих действий и информации о кликах, собранной из профиля пользователя. Подход фильтрации на основе содержимого был использован Редди и др. в [2] для создания системы рекомендаций фильмов, которая рекомендует товары пользователям на основе прошлого поведения. Он также дает рекомендации, основанные на сходстве жанров. Если фильм высоко оценен пользователем, то фильмы, аналогичного жанра, также могут быть рекомендованы.
2.2 Метод коллаборативной фильтрации
В [3] была предложена система рекомендаций интеллектуальной библиотеки, которая рекомендует книги и другие ресурсы пользователям и улучшает образовательную систему. Представлена модель, которая собирает данные из различных источников, после сбора данных проводится обработка и анализ данных. После анализа модель затем выполнит коллаборативную фильтрацию, и по завершении процесса пользователь получит список рекомендаций с элементами, представляющими больший интерес. Основываясь на модели TrustSVD и методах факторизации матриц, Ан Нгуен Тхи Дье и др. предоставил новую методологию для анализа рейтингового элемента и ввода неявного эффекта рейтинга элемента в систему рекомендаций в [4]. Результаты эксперимента показали, что эта модель превзошла стандартный подход к факторизации матриц на 18% и метод многореляционной факторизации матриц на 15%.
[5] предлагает обзорную статью о системах социальных рекомендаций на основе совместной фильтрации. Авторы дали краткое объяснение задач рекомендательных систем и стандартных способов, которые не используют информацию о социальных сетях в этом исследовании, и затем показал, как информация о социальных сетях может быть использована в качестве дополнительного ввода системами рекомендаций для повышения точности. [6] предлагает обзорное исследование модели матричной факторизации в методах совместной фильтрации. Матричная факторизация с использованием векторы факторов, выведенные из шаблонов оценки товаров, характеризуют как товары, так и пользователей, а высокая связь между пользовательскими факторами и факторами товаров приводит к рекомендации. Матричные операции более масштабируемы и экономичны, а также решают проблему высокой разреженности. Тхэ Ен Ким и др. в [7] предложена модель системы рекомендаций, которая фактически распознает шесть человеческих эмоций. Эта модель разработана путем объединения коллаборативной фильтрации со статическим распознаванием эмоциональной информации речи, полученной в режиме реального времени от пользователей. В этой модели в качестве эмоциональной модели выбрана расширенная 2-мерная модель эмоций Тейера. Классификатор SVM также использовался для распознавания закономерностей в информации об эмоциях, содержащейся в оптимизированных признаковых векторах. Эта модель дает более точные рекомендации пользователям благодаря добавлению информации об эмоциях.
Харуна и др. [8] предложили стратегию сотрудничества для системы рекомендаций по исследовательским статьям, которая использует общедоступные контекстуальные данные для выявления скрытых связей между исследовательскими работами с целью персонализации рекомендаций. Независимо от области исследований или опыта пользователя, эта система дает индивидуальные рекомендации. Форасим и др. [9] использовали коллаборативную фильтрацию для создания системы рекомендаций фильмов, которая использует метод кластеризации K-средних для классификации пользователей основываясь на их интересах, а затем обнаруживает сходство между пользователями, чтобы подготовить рекомендацию для активного пользователя. Предлагаемая модель пытается сократить время, затрачиваемое на рекомендацию товара пользователю. Слияние рекомендаций, использующих явные социальные отношения (друзья и соавторы), с рекомендациями, использующими неявные социальные отношения (сходство между пользователями), было использовано в [10] для увеличения охвата пользователей с минимальной потерей точности рекомендаций. Этот подход пытается устранить некоторые недостатки коллаборативной фильтрации, например, холодный старт и повысить точность рекомендаций. Джамал и др. в [11] описан другой метод рекомендаций, основанный на совместном подходе в сочетании с правилами анализа ассоциаций для выявления закономерностей. Он работает, предоставляя рекомендации в соответствии с другими людьми, представляющими аналогичный интерес. Система требует заявленной минимальной поддержки, определенной минимальной достоверности и набора данных в качестве входных данных. В результате своей работы система разрабатывает правила ассоциации. Затем система использует эти правила для создания списка рекомендаций. Для достижения лучшего выбрана производительность, высокая надежность.
[12] разработали гибридную технику совместной работы, которая сочетает модель KNN и модель XGBoost и использует оценки, предсказанные алгоритмом персональных рекомендаций на основе модели, в качестве функций для преодоления разреженности данных и проблем с холодным стартом в персонализированных рекомендательных системах. Алгоритмический принцип, лежащий в основе XGBoost состоит в том, чтобы выбрать несколько образцов и функций для построения элементарной модели классификации. Цель состоит в том, чтобы извлечь уроки из предыдущих данных и создать новый алгоритм.
2.3 Метод фильтрации, основанный на знаниях
В [13] Сара Бурага и др. разработал классификационный подход для систем рекомендаций, основанных на знаниях, который действительно отличает такие системы на основе их характеристик. Структура пытается упростить идентификацию существующих
систем рекомендаций, основанных на знаниях, а подход, изложенный в документе, направлен
на то, чтобы упростить разработку новых, более совершенных систем рекомендаций, основанных на знаниях. Авторы
предложили три классификационных измерения, составляющих основу, первое из которых
Проблема рекомендации и решение
, описывает, что такая
система, основанная на знаниях, должна решать. Второй – это Профиль пользователя
, в котором
указываются характеристики, которые должны присутствовать для формирования индивидуальной рекомендации. Последним фактором является Степень автоматизации
, которая решает, требуется ли вмешательство человека или нет, и если да, то в какой степени. После проведения
опроса авторы выяснили, что, используя системы, основанные на знаниях, мы можем избежать
проблем с холодным стартом, новыми товарами и белыми воронами, а также отсутствием большого набора исторических данных. Однако работа по приобретению знаний сложна, а разработка и обслуживание системы обходятся дорого.
2.4 Гибридный подход
Цзюнь Сяо и др. в [14] разработана модель, которая рекомендует различные онлайн-курсы для учащихся из разных стран. Эта модель использует комбинацию подходов к фильтрации на основе контента и коллаборативной фильтрации. Модель в этой статье включает в себя три модуля: модуль поддержки данных, модуль механизма рекомендаций и модуль рекомендаций. Используя эти модули, модель преодолевает некоторые ограничения, такие как проблемы с холодным стартом. Система рекомендаций по новостям предложена в [15]. В этой статье была предпринята попытка перечислить проблемы в системах рекомендаций новостей. Авторы кратко рассмотрели литературу и использовали обзоры в качестве основного метода сбора данных. Они включали рукописи с различных стандартных платформ в период с 2006 по 2019 год. Изучив все статьи, авторы обнаружили, что только 13% применяли подход коллаборативной фильтрации для рекомендации новостей в течение предыдущего десятилетия. Чтобы избежать ограничений, используется гибридный подход.
Обзор использования алгоритмов машинного обучения в рекомендательных системах был предложен в [16]. Основная цель этой статьи – определить различные алгоритмы ML, используемые в рекомендательных системах, и помочь новым исследователям провести исследование надлежащим образом. Результат подтверждает, что были предприняты минимальные исследовательские усилия, направленные на гибридные подходы. Гитой и др. в [17] была предложена система рекомендаций для фильмов, которая преодолевает проблемы с холодным стартом. Это главным образом направлено на коллаборативную фильтрацию, фильтрацию на основе контента, фильтрацию на основе демографии и гибридные подходы. Эта система пытается преодолеть недостатки каждого индивидуального подхода.
Система рекомендаций для библиотек, основанная на гибридном подходе, была предложена в [18]. В этой статье проводятся сравнительные эксперименты, чтобы продемонстрировать, что гибридный подход обеспечивает более точные рекомендации по сравнению с любыми индивидуальными подходами к фильтрации. Осадчим и др. в [19] предложен алгоритм, который может строить модель коллективных предпочтений независимо от личных интересов пользователя. Используя правила попарной ассоциации, этот новый подход устраняет необходимость в сложной системе рейтингов. Используя этот подход, были устранены некоторые проблемы, с которыми сталкиваются подходы к фильтрации на основе контента и коллаборативной фильтрации. Междоменный подход к рекомендациям использовался в [20], где он использует знания из других доменов, которые включают дополнительные данные о предпочтениях пользователей для подтверждения рекомендации в целевом домене приложения. Система использует измерения семантического сходства общей информации для определения того, как связаны домены. Джеймил и др. в [21] предложена гибридная модель, представляющая собой комбинацию контента и коллаборативной фильтрации в сочетании с технологией анализа ассоциаций для повышения эффективности рекомендательных систем. В исследовании рассматриваются другие стратегии гибридизации, такие как взвешенный метод, который используется для частичного преодоления ограничений предыдущих методов. Кроме того, в нем также рассматриваются возможные решения таких проблем, как проблемы с холодным стартом. Персонализированная гибридная система в [22] было предложено привлекать пользователей в течение более длительного периода времени, рекомендуя продукты по их выбору. В статье представлена модель туризма, разработанная путем объединения классификации и ассоциации, известная как метод ассоциативной классификации. Он также использует нечеткую логику для повышения качества рекомендаций. Нечеткая логика дополнительно помогает свести к минимуму проблему разреженности. Бо Кай Йе в [23] представил обзорную статью, в которой описываются различные методы рекомендаций. В целом рекомендательные системы подразделяются на три категории: Контентные, Коллаборативные и Гибридные. Коллаборативная фильтрация работает путем поиска сходства между разными пользователями и рекомендации используемых ими продуктов. Методы, основанные на содержании, должны анализировать только элементы и профиль пользователя для получения рекомендаций. Затем гибридные системы используются для объединения преимуществ обоих этих подходов для создания системы, которая способна хорошо работать в широком спектре применений. Гибридная система рекомендаций, представленная в [24], фокусируется на дальнейшем расширении гибридной модели путем выполнения анализа настроений. Понимая чувства, лежащие в основе отзывов пользователей, система, таким образом, может принимать обоснованные решения о том, какой конкретный продукт рекомендовать. Модель реализована на платформе spark для удовлетворения потребностей мобильных сервисов. Этот метод обеспечивает высокую эффективность полученной модели по сравнению с существующими гибридными моделями. Одно из ограничений этого метода заключается в том, что отсутствие достаточного количества отзывов действительно затрудняет рекомендацию того или иного фильма любому пользователю. [25] представили персонализированный подход к рекомендациям. В отличие от существующих методов, в этой статье не полностью используются методы контента или совместной работы, но учитываются их преимущества для построения гибридной модели. Эта работа сочетает в себе K-ближайших соседей (KNN) и дерево частых шаблонов (FPT).
В соответствии с требованиями к интеллектуальным рекомендациям в области интеллектуального образования [26] использовался разреженный линейный метод (SLIM). Этот подход работает путем извлечения внутренней структуры и содержания доступных курсов. Исходная матрица студент / курс извлекается из учебного плана колледжа. Окончательный результат рекомендации для последнего курса каждого студента завершается путем упорядочения не пройденных курсов в порядке убывания, при этом первые несколько курсов в списке являются окончательным результатом рекомендации. MovieMender – рекомендательная система фильмов, предложенная автором в [27] с целью помочь пользователям без каких-либо трудностей находить фильмы в соответствии с их интересами. Он использует веб-сканер для получения базы данных. Набор данных предварительно обрабатывается и выводится матрица оценок пользователей. Для создания матрицы к каждой паре оценок пользователей применяется фильтрация на основе данных. Коллаборативная фильтрация использует матричную факторизацию для определения взаимосвязи между элементами и пользовательскими сущностями, чтобы предоставить рекомендации для активного пользователя. Кванхи-эль-аль. в [28] предложена персонализированная система рекомендаций для исследовательских работ путем извлечения ключевых слов, приведенных в статьях. Затем эти слова рассматриваются во всем документе. Любое слово, количество повторений которого превышает среднее, считается ключевым словом для статьи. Этот подход компенсирует недостатки существующих систем, которые не могут реагировать на информацию профиля пользователя конфиденциальным и безопасным способом.
2.5 Рекомендательная система, основанная на эмоциях
Дж. Умамахесвари и др. в [29] представлена модель распознавания эмоций с помощью распознавания речи. Эта модель была создана с использованием комбинированного нейронного распознавания образов. Авторы классифицировали и оценили ранее созданные системы в этом исследовании и обнаружили, что предлагаемая система обладает более высокой точностью, чем ранее использовавшиеся. В [30] Павел Тарновский и др. описывают парадигму распознавания семи основных эмоциональных состояний, основанных на выражениях лица: нейтральный, радость, удивление, гнев, печаль, страх и отвращение. Авторы этой статьи решили включить коэффициенты, описывающие элементы выражения лица, в качестве признака или переменной для модели. Для дальнейшей классификации объектов были использованы классификатор K-ближайшего соседа и нейронная сеть MLP. Для случайного разделения данных эта модель показывает хорошие результаты классификации с точностью 96 процентов (KNN) и 90 процентов (MLP). С. Иниян и др. в [31] предложена модель системы рекомендаций, которая будет предлагать информацию пользователям в зависимости от их текущего настроения или эмоций. Техника распознавания выражения лица в этой модели использует сверточную нейронную сеть (CNN) для извлечения черт из изображения лица. Извлеченные признаки затем передаются в классификатор, который предсказывает полученное выражение в качестве выходного сигнала. Добавляя в систему еще одну переменную реального времени, эта модель исправляет недостаток старого подхода и повышает его точность. В своей статье [32] Джеймс и др. сосредоточились на выявлении человеческих эмоций, чтобы создать систему музыкальных рекомендаций, основанную на эмоциях. Этот метод позволяет избежать трудоемких и утомительных усилий по ручной классификации или разделению музыки на различные списки и помогает создать идеальный список воспроизведения, основанный на эмоциональных характеристиках человека.
Таблица 1. Сравнительная таблица
| Существующая работа | Год | Подход | Сильные стороны | Слабые стороны |
|---|---|---|---|---|
| [3] | 2018 | Коллаборативная фильтрация | Знание предметной области не требуется | Проблема белой вороны, Проблема разреженности данных, Проблема холодного старта |
| [4] | 2020 | Модель TrustSVD, Методы факторизации матриц | Высокая точность | Требуется больше времени для оптимизации целевой функции |
| [14] | 2017 | Основанная на содержимом и коллаборативная фильтрация | Контроль над проблемой холодного старта, в некоторой степени | Разреженность данных, Масштабируемость |
| [5] | 2013 | Коллаборативная фильтрация, матричная факторизация на основе социальной информации | Более высокая точность, в некоторой степени контроль над проблемой холодного старта | Разреженность данных, Масштабируемость |
| [29] | 2019 | KNN, Нейронная сеть для распознавания образов | Знание предметной области не требуется | Повышенная сложность |
| [30] | 2017 | К-Ближайший Сосед, Многослойная Нейронная Сеть | Более высокая точность | KNN плохо работает с большим набором данных |
| [31] | 2020 | Сверточная нейронная сеть; Подход, основанный на содержании | Более высокая точность, устраняет проблему холодного запуска | Увеличивает угрозу конфиденциальности и безопасности пользователей |
| [6] | 2015 | Коллаборативная фильтрация с использованием матричных моделей факторизации | Снижает уровень разреженности, обрабатывает большую базу данных, решает проблемы холодного старта | Низкая точность, сложность модели увеличивается с увеличением набора данных |
| [7] | 2021 | Коллаборативная фильтрация, классификатор машин с опорными векторами | Увеличение точности (средняя точность составляет 87.2%) | Разреженность данных увеличивает угрозу конфиденциальности и безопасности пользователей |
| [15] | 2020 | Систематический обзор литературы 2020 года в качестве основного метода сбора данных | Эта статья помогает исследователям идентифицировать и классифицировать некоторые хорошие подходы. | В этой статье не показана какая-либо новая модель для рекомендации новостей |
| [16] | 2017 | Основным подходом к сбору данных является систематический обзор литературы. | Эта статья поможет исследователям определить и классифицировать некоторые хорошие алгоритмы ML для системы рекомендаций | Отсутствуют исследования требований и дизайна, а также поздних стадий, таких как техническое обслуживание. |
| [17] | 2018 | Фильтрация на основе содержимого и коллаборативная фильтрация, корреляция Пирсона, средневзвешенное значение | Более высокая точность, может быть дополнительно распространена на другие области, в некоторой степени решает проблемы холодного старта. | Разреженность данных, масштабируемость |
| [1] | 2020 | Фильтрация на основе содержимого, Классификатор XGBoost | Решает проблему белой вороны, нет проблемы с разреженностью данных | Проблема с холодным стартом, не удается расширить интерес пользователей |
| [8] | 2017 | Коллаборативная фильтрация | Не требует предварительного профиля пользователя, персонализированной рекомендации, расширяет область интересов пользователя | Проблема белой вороны, проблема холодного старта, проблема разреженности данных |
| [2] | 2019 | Фильтрация на основе содержимого | Решает проблему белой вороны, дает индивидуальные рекомендации | Проблема с холодным стартом, никаких случайных рекомендаций |
| [9] | 2017 | Коллаборативная фильтрация, кластеризация k-средних | Обеспечивает точные рекомендации, высокую точность и скорость | Проблема с холодным стартом, проблема белой вороны и разреженность данных |
| [18] | 2019 | K-кластеризация, коллаборативная фильтрация и фильтрация на основе контента. | В некоторой степени уменьшает проблему разреженности данных, дает полезные рекомендации | Проблема с холодного старта |
| [19] | 2018 | Правила попарной ассоциации | Нет проблем с холодным стартом или разреженностью данных. | Проблема белой вороны, требуется большой набор данных |
| [20] | 2016 | Тензорная декомпозиция, семантическое сходство, k-кластеризация | Использует несколько сетей, уменьшает проблему разреженности данных | Проблема холодного старта, неоьходимость полностью полагаться на вспомогательный домен |
| [10] | 2016 | Коллаборативная фильтрация, четкие социальные сети | В некоторой степени устраняет проблему холодного старта, повышает точность | Проблема белой вороны, динамическое поведение пользователя |
| [32] | 2019 | Распознавание лиц, распознавание эмоций, классификация | Отсутствие проблем с холодным стартом, возможность адаптации к динамическому поведению пользователя, решение проблемы белой вороны | Никаких случайных рекомендаций, необходимость полагаться на эмоции пользователя |
| [21] | 2015 | Технология data-mining, Ассоциации | Лучшая точность | Проблема белой вороны |
| [22] | 2013 | Кластерный анализ, ассоциативный майнинг, нечеткий алгоритм CBA | Нечеткая логика помогает свести к минимуму проблему разреженности. | Можно было бы предложить новые методы для дальнейшего повышения точности и производительности системы |
| [23] | 2019 | FPT, K-ближайшие соседи (KNN) | Устраняет проблему холодного старта | Отзывы, созданные пользователями рейтинги могут быть недоступны для профилирования пользователей. |
| [25] | 2014 | Фильтрация, основанная на содержимом, коллаборативная фильтрация, гибридный подход | Более высокая производительность | Надежная интеграция, эффективный расчет |
| [24] | 2018 | Коллаборативная фильтрация, фильтрация на основе содержимого, чувствительный анализ | Высокая вовлеченность пользователей в приложение, высокая эффективность | Ограниченная вовлеченость пользователей |
| [11] | 2016 | Кластеризация, KNN, анализ ассоциаций | Лучше подходит для прогнозирования поведения клиентов | Слишком сложный |
| [26] | 2018 | Разреженный линейный метод (SLIM), регуляризация | Высокая производительность | Точность может быть улучшена |
| [27] | 2016 | Коллаборативная фильтрация, фильтрация на основе содержимого, матричная факторизация | Повышенная эффективность и общая производительность системы. | Для повышения производительности может быть создана гибридная система рекомендаций, основанная на кластеризации и сходстве |
| [28] | 2014 | Извлечение ключевых слов | Устраняет проблему холодного старта | Группировка научных работ по конкретным темам |
| [12] | 2019 | Коллаборативная фильтрация | Точные и эффективные результаты. | Разнородные и неоднородные данные, разреженность данных |
| [13] | 2014 | Фльтрация, освнованная на знаниях | Устраняет проблему холодного старта, проблему белой вороны, отсутствие необходимости большого набора данных; более надеждная рекомендация | Задача приобретения знаний является сложной, разработка и техническое обслуживание являются дорогостоящими |
Возникающие тенденции и будущий охват
Развитие области рекомендательных систем носит постоянный характер, поскольку экспоненциальное расширение Интернета затрудняет получение необходимой информации за достаточно короткое время. Будущее рекомендательных систем будет гораздо шире, чем простое использование для бизнеса, они окажут гораздо большее влияние на нашу повседневную жизнь. Идеальной системой рекомендаций была бы та, которая знает нас лучше, чем мы сами и принимает решения, необходимые на каждом этапе нашей жизни без усилий и быстро, чтобы мы могли потратить наше драгоценное время на более продуктивные занятия. Несколько подходов и методов уже используются, как обсуждается в статье, но у них есть свои проблемы, такие как проблема холодного старта. Проблема связана с новыми пользователями, у которых еще нет истории посещенных страниц. Таким образом, предполагается, что система будет предоставлять рекомендации пользователю, не полагаясь на какие-либо предыдущие действия. Рекомендательные системы предполагают использование всего профиля пользователя, ваших симпатий и антипатий. Это может создать угрозу конфиденциальности пользователя. Предоставление точных рекомендаций на основе большого объема данных могут привести к некоторой задержке во времени отклика. Кроме того, в любой рекомендательной системе прогнозирование интереса пользователя может быть сложной задачей, поскольку интерес может меняться со временем. Для решения этих проблем исследователи предлагают некоторые модификации, такие как объединение K-ближайших соседей (KNN) и дерева частых шаблонов (FP) для обеспечения качественных рекомендации пользователям или гибридную систему, основанную на настроениях, которая работает за счет применения анализа настроений к списку рекомендаций, сгенерированному для повышения точности и производительности существующих систем.
В продолжение этого мы пытаемся еще больше повысить точность этих моделей, введя новую переменную – эмоциональную информацию. Эмоциональные данные могут эффективно использоваться в рекомендательных системах, поскольку они отражают текущее эмоциональное состояние пользователя. Чтобы повысить удовлетворенность пользователей, система рекомендаций должна распознавать и отражать уникальные черты и обстоятельства, в которых находится пользователь, личные предпочтения и чувства. Как правило, эмоциональная информация может быть собрана двумя способами: распознаванием речи и распознаванием выражения лица. Этот метод помогает не только устранить проблему холодного старта, но и сможет рекомендовать пользователям новые и полезные товары, чтобы расширить область их интересов. Любая традиционная система использует прошлые данные пользователей для рекомендации контента, которые иногда становятся неактуальными для пользователей и предлагаемый метод также устраняет эту проблему традиционных систем.
Заключение
Из-за огромного количества неструктурированных данных в Интернете рекомендательные системы по-прежнему являются интересной областью для исследований. Такие системы позволяют пользователям получать доступ к предпочитаемому ими контенту без необходимости проходить через все доступные сервисы. Таким образом, качественная система рекомендаций может устранить информационные барьеры для пользователя наряду с повышением бизнес-результатов. Виды рекомендательных систем, таких как основанные на содержании, коллаборативные, основанные на знаниях и гибридные системы классифицируются в этой статье, опистывается их работа, достоинства и ограничениями. В настоящее время наболее популярны гибридные методы, которые объединяют два или более метода для предоставления точных рекомендаций пользователям. Ожидается, что в ближайшем будущем можно будет внедрить больше инноваций, чтобы создать системы лучше, чем существуют сейчас.
Литература
- Z. Shahbazi and Y.-C. Byun,
Product recommendation based on content-based filtering using XGBoost classifier,
Int. J. Adv. Sci. Technol, no. 29, pp. 6979-6988, 2019 - S. Reddy, S. Nalluri, S. Kunisetti, S. Ashok and B. Venkatesh,
Content-based movie recommendation system using,
Smart Intelligent Computing and Applications, pp. 391-397, 2019. - A. Simovic,
A big data smart library recommender system,
Library Hi Tech, 2018 - A. N. T. Dieu, T. N. Vu and T. D. Le,
A New Approach Item Rating Data Mining on the Recommendation System,
SN Computer Science, pp. 1-6, 2021. - X. Yang, Y. Guo, Y. Liu and H. Steck,
A survey of collaborative filtering based social recommender systems,
Computer communications, no. 41, pp. 1-10, 2014. - D. Bokde, S. Girase and D. Mukhopadhyay,
Matrix factorization model in collaborative filtering algorithms: A survey,
Procedia Computer Science, no. 49, pp. 136-146, 2015 - T.-Y. Kim, H. Ko, S.-H. Kim and H.-D. Kim,
Modeling of Recommendation System Based on Emotional Information and Collaborative Filtering,
Sensors, no. 21(6), p. 1997, 2021. - K. Haruna, M. A. Ismail, D. Damiasih, J. Sutopo and T. Herawan,
A collaborative approach for research paper recommender system,
PloS one, no. 12(10), 2017. - P. Phorasim and L. Yu,
Movies recommendation system using collaborative filtering and k-means,
International Journal of Advanced Computer Research, vol. 7, no. 29, p. 52, 2017. - S. Alotaibi and J. Vassileva,
Personalized Recommendation of Research Papers by Fusing Recommendations from Explicit and Implicit Social Network,
UMAP (Extended Proceedings), 2016. - A. A. Badarneh and J. Alsakran,
An automated recommender system for course selection,
International Journal of Advanced Computer Science and Applications, vol. 7, no. 3, pp. 166-175, 2016 - W. Juan, L. Y. Xin and W. C. Ying,
Survey of recommendation based on collaborative filtering,
Journal of Physics: Conference Series, vol. 1314, no. 1, 2019. - S. Bouraga, I. Jureta, S. Faulkner and C. Herssens,
Knowledge-based recommendation systems: A survey,
International Journal of Intelligent Information Technologies (IJIIT), vol. 10, no. 2, pp. 1-19, 2014. - J. Xiao, M. Wang, B. Jiang and J. Li,
A personalized recommendation system with combinational algorithm for online learning,
Journal of ambient intelligence and humanized computing, vol. 9, no. 3, pp. 667-677, 2018 - C. Feng, M. Khan, A. U. Rahman and A. Ahmad,
News recommendation systems accomplishments, challenges & future directions,
IEEE Access, vol. 8, pp. 16702-16725, 2020. - I. Portugal, P. Alencar and D. Cowan,
The use of machine learning algorithms in recommender systems: A systematic review,
Expert Systems with Applications, vol. 97, pp. 205-227, 2018. - G. G., S. M., F. C. and S. D.,
A hybrid approach using collaborative filtering and content based filtering for recommender system,
Journal of Physics: Conference Series, vol. 1000, no. 1, p. 012101, 2018. - Y. Tian, B. Zheng, Y. Wang, Y. Zhang and Q. Wu,
College library personalized recommendation system based on hybrid recommendation algorithm,
Procedia CIRP, vol. 83, pp. 490-494, 2019 - T. Osadchiy, I. Poliakov, P. Olivier, M. Rowland and E. Foster,
Recommender system based on pairwise association rules,
Expert Systems with Applications, vol. 115, pp. 535- 542, 2019. - V. kumar, K. M. P. Shrivastva and S. Singh,
Cross domain recommendation using semantic similarity and tensor decomposition,
Procedia Computer Science, vol. 85, pp. 317-324, 2016. - J. M. Shah and L. Sahu,
A hybrid based recommendation system based on clustering and association,
Binary Journal of Data Mining & Networking, vol. 5, no. 1, pp. 36-40, 2015 - J. P. Lucas, N. Luz, M. N. Moreno, R. Anacleto, A. A. Figueiredo and C. Martins,
A hybrid recommendation approach for a tourism system,
Expert systems with applications, vol. 40, no. 9, pp. 3532-3550, 2013. - B. K. Ye, Y. J. Tu and T. P. Liang,
A hybrid system for personalized content recommendation,
Journal of Electronic Commerce Research, vol. 20, no. 2, pp. 91-104, 2019 - Y. Wang, M. Wang and W. Xu,
A sentiment-enhanced hybrid recommender system for movie recommendation: a big data analytics framework,
Wireless Communications and Mobile Computing, vol. 2018, pp. 1-9, 2018. - B. B. Bhatt, P. P. J. Patel and P. H. Gaudani,
A Review Paper on Machine Learning Based Recommendation System,
Development, vol. 2, pp. 3955-3961, 2014. - J. Lin, H. Puc, Y. Li and J. Lian,
Intelligent recommendation system for course selection in smart education,
Procedia Computer Science, vol. 129, pp. 449-453, 2018 - R. Hande, A. Gutti, K. Shah, J. Gandhi and V. Kamtikar,
Moviemender - a movie recommendation system,
International Journal of Engineering Science & Research Technology, 2016. - K. Hong, H. Jeon and C. Jeon,
Personalized research paper recommendation system using keyword extraction based on userprofile,
Journal of Convergence Information Technology, vol. 8, no. 16, p. 106, 2013. - J. Umamaheswari and A. Akila,
An enhanced human speech emotion recognition using hybrid of PRNN and KNN,
International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), pp. 177-183, 2019. - P. Tarnowski, M. Kolodziej, A. Majkowski and R. J. Rak,
Emotion recognition using facial expressions,
Procedia Computer Science, vol. 108, pp. 1175-1184, 2017. - S. Iniyan, V. Gupta and S. Gupta,
Facial Expression Recognition Based Recommendation System,
International Journal of Advanced Science and Technology, vol. 29, no. 3, pp. 5669 - 5678, 2020 - H. I. James, J. J. A. Arnold, J. M. M. Ruban, M. Tamilarasan and R. Saranya,
Emotion based music recommender system,
International Research Journal of Engineering and Technology (IRJET), vol. 6, no. 3, pp. 2096-2101, 2019.