Анотация
Серёженко А. А., Коломойцева И. А. Исследование методов анализа тональности на примере текстов песен. В статье представлен краткий обзор анализа текстов сообщений из современных информационных потоков, в частности оценка тональности. Также рассмотрены и описаны алгоритмы классификации, а также проблематика с точки зрения обработки текстов песен.
Введение
Эмоции — это часть человеческого общения. Настроение, чувства и личность любого человека можно узнать по его эмоциям. Люди всегда считали музыку значимой в своей жизни. Музыка — это язык эмоций. Она часто выражает эмоциональные качества и качества человеческой личности, такие как счастье, печаль, агрессивность, нежность и т. д. Она играет центральную роль в человеческом обществе, потому что сильно пробуждает чувства и влияет на социальную активность и взаимодействие.
информацию, как жанр, тональность и тема песни. Однако автоматизировать эту задачу очень сложно. Системы автоматической классификации музыки обычно ориентированы на классификацию по звуковым характеристикам или совместную фильтрацию. Ссылка на лит. Однако у этих методов есть множество недостатков. Бывает достаточно трудно по одной лишь мелодии получить эмоциональную окраску всего трека. Следовательно, мы автоматизируем классификацию песен и выступлений, используя их тексты.
Данная работа посвящена анализу методов и моделей исследования тональности текстов песен. Результаты данной работы будут использоваться в реализации собственного метода анализа текстов на естественном языке.
Актуальность темы
Для данной работы решено провести анализ теста песен. Тексты песен — это неструктурированная информация, обрабатывать которую вручную чересчур трудозатратно. Но собирать и обрабатывать информацию необходимо хотя бы потому, что это даёт возможность получать новую информацию из уже имеющихся данных, с помощью которой можно повысить разнообразие принятых решений. В связи с этим задача автоматического анализа данных является актуальной, и для её решения разработано множество методов и моделей. Одним из методов является Data Mining.
Data Mining — процесс автоматического обнаружения в исходных данных скрытой информации, которая ранее не была известна, нетривиальна, практически полезна и доступна для интерпретации человеком [1].
Отдельной областью обработки знаний является анализ неструктурированной текстовой информации. Под неструктурированной текстовой информацией подразумевают набор документов, представляющих собой логически объединенный текст, не ограниченный структурными компонентами [2].
Анализ тональности
Один из аспектов анализа текстов сообщений из современных информационных потоков — это оценка так называемой тональности или эмоциональной окраски.
Основной задачей анализа тональности текста является определение его эмоциональной окраски. Это необходимо, в том числе, для:
- анализа отзывов о товарах и услугах;
- определение языка вражды [3].
В общем случае, задача анализа тональности текста эквивалентна задаче классификации текста, где категориями текстов могут быть тональные оценки. Примеры тональных оценок:.
- позитивная;
- негативная;
- нейтральная (текст не содержит эмоциональной окраски) [3].
Этапы анализа тональности приведена рисунке 1 [3].

Рисунок 1 — Методология анализа тональности
Рассмотрим процесс сбора информации. Потребители обычно выражают свои чувства на публичных форумах, таких как блоги, форумы, обзоры продуктов, а также в социальных сетях Мнения и чувства выражаются по-разному, с разным словарным запасом, контекстом написания, использованием кратких форм и сленга, что делает данные огромными и дезорганизованными. Ручной анализ данных о настроениях практически невозможен. Поэтому для обработки и анализа данных используются специальные языки программирования.
Подготовка текста — это не что иное, как фильтрация извлеченных данных перед анализом. Он включает в себя выявление и удаление нетекстового контента и контента, который не имеет отношения к области исследования из данных.
На этапе обнаружения оценки каждое предложение отзыва и мнения проверяется на субъективность. Предложения с субъективными выражениями сохраняются, а предложения с объективными выражениями отбрасываются. Анализ тональности выполняется на разных уровнях с использованием обычных вычислительных методов, таких как униграммы, леммы, отрицание и т. д.
Как мы уже говорили ранее, оценку можно условно классифицировать на три группы: положительные, отрицательные и нейтральные. На этом этапе методологии анализа настроений каждое обнаруженное субъективное предложение классифицируется на группы: положительное, отрицательное, хорошее, плохое, нравится, не нравится.
Основная идея анализа — преобразовать неструктурированный текст в значимую информацию. После завершения анализа текстовые результаты отображаются на диаграммах.
Алгоритмы анализа тональности
Анализ тональности использует различные методы и алгоритмы обработки естественного языка, которые мы рассмотрим более подробно в этом разделе.
Основной задачей анализа тональности текста является определение его эмоциональной окраски. Это необходимо, в том числе, для:
- на основе правил: эти системы выполняют анализ настроений на основе набора правил, созданных вручную;
- автоматически: системы полагаются на методы машинного обучения, чтобы учиться на данных;
- гибридные системы сочетают в себе подходы, основанные на правилах и автоматические.
Рассмотрим подходы, основанные на правилах. Обычно система, основанная на правилах, использует набор правил, созданных человеком, чтобы помочь идентифицировать субъективность, полярность или предмет мнения.
Эти правила могут включать в себя различные методы, разработанные в компьютерной лингвистике, такие как:
- Создание стеммингов, токенизация, теги и синтаксический анализ частей речи.
- Лексиконы (т.е. списки слов и выражений).
Рассмотрим базовый пример того, как работает система, основанная на правилах.
- Определяются два списка поляризованных слов (например, отрицательные слова, такие как «плохой», «худший», «уродливый» и т.д., а также положительные слова, такие как «хорошие», «лучшие», «красивые» и т.д.).
- Система подсчитывает количество положительных и отрицательных слов, которые встречаются в заданном тексте.
- Если количество появлений положительных слов больше, чем количество появлений отрицательных слов, система возвращает положительное настроение, и наоборот. Если числа четные, система вернет нейтральное мнение.
Системы, основанные на правилах, очень наивны, поскольку не принимают во внимание, как слова объединяются в последовательности. Конечно, можно использовать более продвинутые методы обработки и добавлять новые правила для поддержки новых выражений и словаря. Однако добавление новых правил может повлиять на предыдущие результаты, и вся система может стать очень сложной. Поскольку системы, основанные на правилах, часто требуют тонкой настройки и обслуживания, они также потребуют регулярных инвестиций.
Автоматические методы, в отличие от систем, основанных на правилах, полагаются не на правила, созданные вручную, а на методы машинного обучения. Задача анализа настроений обычно моделируется как проблема классификации, при которой классификатор получает текст и возвращает категорию, например положительную, отрицательную или нейтральную.
Реализация классификатора машинного обучения приведена на рисунке 2 [5].
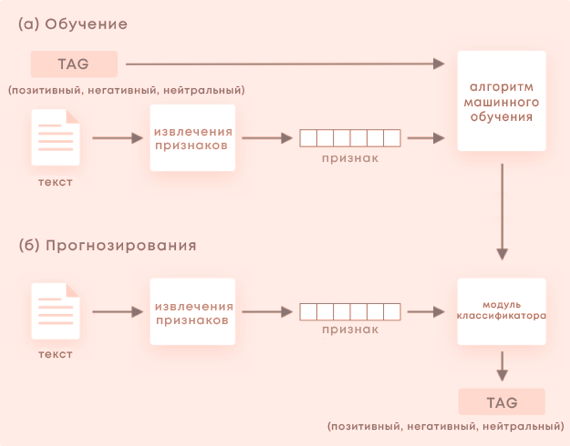
Рисунок 2 — Реализация классификатора машинного обучения
В процессе обучения (а) наша модель учится связывать конкретный ввод (т.е. текст) с соответствующим выводом (тегом) на основе тестовых выборок, используемых для обучения. Средство извлечения признаков преобразует введенный текст в вектор признаков. Пары векторов признаков и тегов (например, «положительные», «отрицательные» или «нейтральные») вводятся в алгоритм машинного обучения для создания модели.
В процессе прогнозирования (б) средство извлечения признаков используется для преобразования невидимого ввода текста в векторы признаков. Эти векторы признаков затем вводятся в модель, которая генерирует предсказанные теги (опять же, «положительные», «отрицательные» или «нейтральные»).
На этапе классификации обычно используются статистические модели, такие как байесовский метод и метод опорных векторов.
Байесовская классификация является одним из самых простых, но не значит, что неэффективных, методов в классификации текстов. Данный алгоритм основан на принципе максимума апостериорной вероятности. Для классифицируемого объекта вычисляются функции правдоподобия каждого из классов, по ним вычисляются апостериорные вероятности классов. Объект относится к тому классу, для которого апостериорная вероятность максимальна [6].
Пусть P(ci|d)— вероятность того, что документ, представленный вектором d=(t1,…,tn), соответствует категории ci для i=1,…,|C|. Задача классификатора заключается в том, чтобы подобрать такие значения ci и d, при которых значение вероятности P(ci|d) будет максимальным:
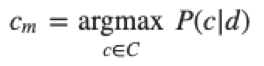
Рисунок 3 — Конечный результат вероятности
Машина опорных векторов (SVM) — это еще одна управляемая модель машинного обучения, похожая на линейную регрессию, но более продвинутая. SVM использует алгоритмы для обучения и классификации текста в рамках нашей модели полярности настроений, делая шаг дальше предсказания X / Y [7].
Для простого визуального объяснения, мы будем использовать две метки: красные и синие, с особенностями двух данных: X и Y. Мы научим наш классификатор выводить координаты X / Y как красные или синие.
Затем SVM назначает гиперплоскость, которая лучше всего разделяет теги. В двух измерениях это просто линия (как в линейной регрессии). Все, что на одной стороне линии, красное, а все, что на другой стороне, синее. Для анализа настроений это может быть как положительным, так и отрицательным.
Чтобы максимизировать машинное обучение, лучшая гиперплоскость — это та, у которой наибольшее расстояние между каждым тегом (см. рис. 4).
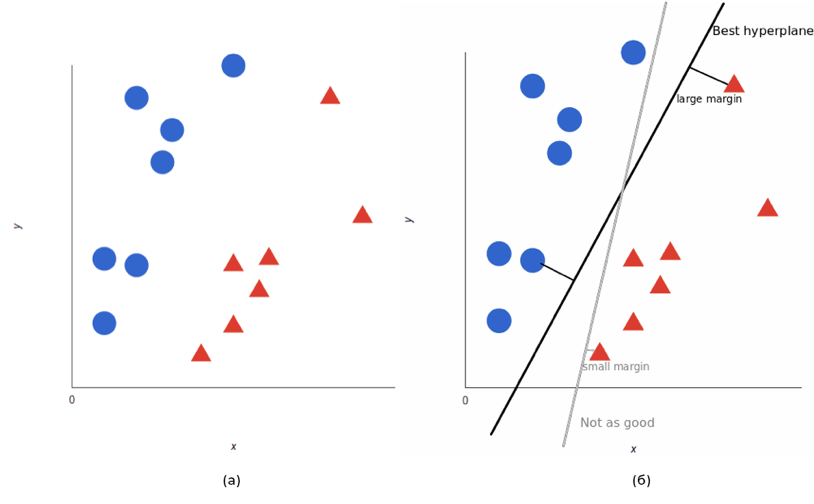
Рисунок 4 — Пример применения метода опорных векторов:
а — начальные данные;
б — назначение гиперплоскости.
Однако по мере того, как наборы данных становятся более сложными, может оказаться невозможным провести одну линию, чтобы разделить данные на два лагеря.
При использовании SVM, чем сложнее данные, тем точнее становится предсказатель. Представьте себе это в трех измерениях с добавленной осью Z, так что она становится кругом.
Два измерения с помощью лучшей гиперплоскости представлена на рисунке 5.

Рисунок 4 — Пример применения метода опорных векторов:
а — переход на декартовую систему координат;
б — конечный результат.
SVM позволяет для более точного машинного обучения, потому что это многомерное.
Проблемы анализа тональности
Анализ тональности — одна из самых сложных задач при обработке естественного языка, потому что даже людям сложно точно анализировать настроения.
Анализируя текст песен можно столкнуться с неточностью классификации эмоции. Основные проблем анализа тональности текста песен:
- субъективность и тон;
- контекст и полярность;
- ирония и сарказм;
- сравнения.
Есть два типа текста: субъективный и объективный. Объективные тексты не содержат явных сантиментов, в то время как субъективные тексты содержат. Скажем, например, вы собираетесь проанализировать тональность следующих двух текстов:
«Пакет хороший.»
«Пакет красный.»
Большинство людей сказали бы, что настроение положительное для первого и нейтральное для второго, верно? Ко всем сказуемым (прилагательным, глаголам и некоторым существительным) не следует относиться одинаково с точки зрения того, как они создают настроение. В приведенных выше примерах приятный цвет более субъективен, чем красный.
Все высказывания произносятся в определенный момент времени, в определенном месте, некоторыми людьми и для некоторых людей, вы понимаете. Все высказывания произносятся в контексте. Очень сложно анализировать настроения без контекста. Однако машины не могут узнать о контекстах, если они не упомянуты явно. Одна из проблем, возникающих из контекста, — это изменение полярности.
Когда дело доходит до иронии и сарказма, люди выражают свои негативные чувства с помощью положительных слов, которые может быть трудно обнаружить машинам, не имея полного понимания контекста ситуации, в которой было выражено чувство.
Например, рассмотрите некоторые возможные ответы на вопрос: Вам понравились покупки у нас?
Да, конечно. Так гладко!
Не один, а много!
Какое настроение вы бы назвали приведенным выше ответам? Первый ответ с восклицательным знаком может быть отрицательным, верно? Проблема в том, что нет текстовой подсказки, которая поможет машине научиться или, по крайней мере, подвергнуть сомнению это мнение, поскольку «да» и «конечно же» часто относятся к положительным или нейтральным текстам.
Как насчет второго ответа? В этом контексте настроение является положительным, но мы уверены, что вы можете придумать множество разных контекстов, в которых один и тот же ответ может выражать отрицательные настроения.
Как относиться к сравнениям в анализе настроений — еще одна проблема, которую стоит решить. Посмотрите на тексты ниже:
Этот продукт не имеет себе равных.
Это лучше, чем ничего.
Первое сравнение не требует контекстных подсказок для правильной классификации. Понятно, что положительно.
Однако второй и третий тексты немного сложнее классифицировать. Вы бы классифицировали их как нейтральные, положительные или даже отрицательные? Еще раз, контекст может иметь значение. Например, если «старые инструменты» во втором тексте были сочтены бесполезными, то второй текст очень похож на третий.
Список использованной литературы
1. Батура Т. В. Методы автоматической классификации текстов. — Новосибирск : Институт систем информатики им. А.П. Ершова СО РАН, 2017. — с. 87-93.
2. Принципы работы рекомендательных механизмов Интернета [Электронный ресурс], - Режим доступа:[Ссылка]
3. Классификация текстов и анализа тональности [Электронный ресурс], - Режим доступа:[Ссылка]
4. Methods of Sentiment Analysis [Электронный ресурс], - Режим доступа:[Ссылка]
5. Sentiment Analysis: A Definitive Guide [Электронный ресурс], - Режим доступа:[Ссылка]
6. Ландэ Д. В. Интернетика Навигация в сложных сетях Модели и алгоритмы. — М.: Книжный дом «ЛИБРОКОМ», 2009. —с. 87-88.
7. Ландэ Д. В. Интернетика Навигация в сложных сетях Модели и алгоритмы. — М.: Книжный дом «ЛИБРОКОМ», 2009. —с. 87-88.