Анотация
Серёженко А. А., Коломойцева И. А. Анализ методов классификации при определении тональности. В данной статье приведён краткий обзор методов Bag-of-Words и TF-IDF. Также было описано и сравнение методов с помощью моделей XGBoost и логической регрессии.
Введение
Классификация текста и анализ настроений - очень распространённая проблема машинного обучения, которая используется во многих действиях, таких как прогнозы продуктов, рекомендации фильмов и многие другие. В настоящее время для каждого нового специалиста по машинному обучению изучение этой области стало очень важным. Особенно важным вопросом является понимаю того, как мы можем извлекать функции из нашего текстового набора данных и какие методы для этого будут быстродействующими. Целью данной статьи является краткий обзор и сравнение методов Bag-of-Words и TF-IDF с помощью моделей XGBoost и логической регрессии.
Особенности Bag-of-Words
ДBag-of-Words является методом функций выписки из текстовых документов. Эти функции можно использовать для обучения алгоритмов машинного обучения [1]. Он создает словарь всех уникальных слов, встречающихся во всех документах обучающего набора, преобразовывая документы в векторы, где каждому слову в документе присваивается оценка.
Рассмотрим корпус (набор текстов) документов D {d1, d2… ..dD}, и N уникальных токенов, извлеченных из корпуса C. N токенов (слов) сформируют список, а размер матрица M мешка слов будет задана DX N. Каждая строка в матрице M содержит частоту токенов в документе D (i).
Например, если у вас есть 2 строчки из песни:
- D1: All my loving I will send to you.
- D2: All my loving, darling I will be true.
Он создает словарь, используя уникальные слова из всех документов («my», «loving», «I», «send», «you», «true», «darling»). Как видно из приведенного выше списка, мы не рассматриваем «all», «will», «be» в этом наборе, потому что они не передают необходимую информацию, необходимую для модели.
Матрица M размера 2x6(D = 2 – количество документов, N = 6 – количество слов в словаре) представлена в таблице 1.
Таблица 1 — Матрица M размера 2x6
| My | loving | I | Send | You | True | Darling | |
| D1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| D2 | 1 | 1 | 1 | 0 | 0 | 1 | 1 |
В приведенной выше таблице показаны функции обучения, содержащие частоту терминов каждого слова в каждом документе. Это называется подходом «мешка слов», поскольку в этом подходе имеет значение количество вхождений, а не последовательность или порядок слов.
Возможности TF-IDF
TF-IDF расшифровывается как Term Frequency-Inverse Document Frequency, а вес TF-IDF – это вес, часто используемый при поиске информации и интеллектуальном анализе текста. Этот вес – статистическая мера, используемая для оценки того, насколько важно слово для документа в коллекции или корпусе [3]. Идея заключается в том, что словам, которые чаще встречаются в одном документе и реже в других документах, следует придавать большее значение, поскольку они более полезны для классификации. Важность увеличивается пропорционально тому, сколько раз слово появляется в документе, но компенсируется частотой появления слова в корпусе.
Обычно вес TF-IDF состоит из двух членов :
- частота термина (TF);
- обратная частота документов (IDF).
Первый вычисляет нормализованную частоту термина (TF).
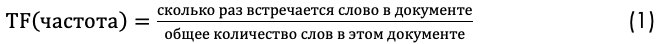
Рассмотрим текст тесни The Beatles Yesterday, содержащий 84 слова, в котором слово Yesterday встречается 6 раза. Тогда термин частоты (TF), для слова Yesterday равняется 0,07.
Второй член – это обратная частота документов (IDF).
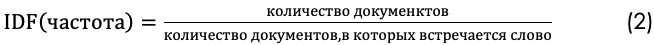
Предположим, у нас текст 200 песен The Beatles, и слово Yesterday встречается в одной четырёх из них. Затем обратная частота документов (IDF) рассчитывается как log〖(200/4)=1,69〗.
Формула для определения веса TF-IDF:
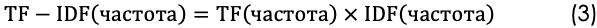
В приведенных выше примерах частота термина равна 0,07, а частота обратного документа – 1,69.
Таким образом, вес TF-IDF является произведением этих величин: 0,07 * 1,69 = 0,11.
Применение моделей машинного обучения
Большая часть практического машинного обучения использует обучение с учителем.
Контролируемое обучение – это когда у вас есть входные переменные (x) и выходная переменная (Y), и вы используете алгоритм для изучения функции сопоставления от входа к выходу [3].
Цель состоит в том, чтобы аппроксимировать функцию сопоставления настолько хорошо, чтобы, когда у вас есть новые входные данные (Х), вы могли предсказать выходные переменные (Y) для этих данных.
Это называется обучением с учителем, потому что процесс обучения алгоритму на основе набора обучающих данных можно рассматривать как учителя, контролирующего процесс обучения. Мы знаем правильные ответы, алгоритм итеративно делает прогнозы на основе данных обучения и корректируется учителем. Обучение прекращается, когда алгоритм достигает приемлемого уровня производительности.
Задачи контролируемого обучения можно далее сгруппировать в задачи регрессии и классификации [3].
Классификация: проблема возникает, когда выходной переменной является категория, например «красный» или «синий», или в нашем случае «положительный» или «отрицательный».
Регрессия: проблема возникает, когда выходной переменной является реальное значение, такое как «доллары» или «вес».
Наша проблема попадает в категорию классификации, потому что мы должны классифицировать наши результаты либо на положительные, либо на отрицательные.
Существует еще одна категория алгоритмов машинного обучения, называемая неконтролируемым машинным обучением, где у вас есть входные данные, но нет соответствующих выходных переменных. Цель обучения без учителя - смоделировать базовую структуру или распределение данных, чтобы узнать о них больше. Но это не касается нас в данной постановке проблемы.
Для лучшего результата, используем разные модели, чтобы увидеть, какая из них лучше всего подходит для нашего набора данных. Мы будем использовать 2 разные модели:
- XGBoost.
- Логистическая регрессия.
Затем сравним их производительность и выберем наилучшую возможную модель с наилучшей возможной техникой извлечения признаков для прогнозирования результатов на наших тестовых данных.
Также используем F1 Score для оценки производительности нашей модели. F1 Score обычно используется для оценки систем поиска информации, таких как поисковые системы, а также для многих типов моделей машинного обучения, в частности, при обработке естественного языка [4].
XGBoost
XGBoost — алгоритм машинного обучения, основанный на дереве поиска решений и использующий фреймворк градиентного бустинга.
Библиотека ориентирована на скорость вычислений и производительность модели, поэтому в ней мало излишеств. Тем не менее, он предлагает ряд дополнительных функций [5].
Реализация алгоритма была спроектирована с учетом эффективности вычислительного времени и ресурсов памяти. Целью проектирования было наилучшее использование доступных ресурсов для обучения модели. Некоторые ключевые особенности реализации алгоритма включают:
- Реализация Sparse Aware с автоматической обработкой отсутствующих значений данных.
- Структура блоков для поддержки распараллеливания построения дерева.
- Продолжение обучения, чтобы вы могли дополнительно улучшить уже подогнанную модель на новых данных.
На рисунке 1 продемонстрированно прогнозирование вероятности попадания в положительный или отрицательный класс и расчёт F1 Score для методов Bag-of-Words и TF-IDF соответственно.
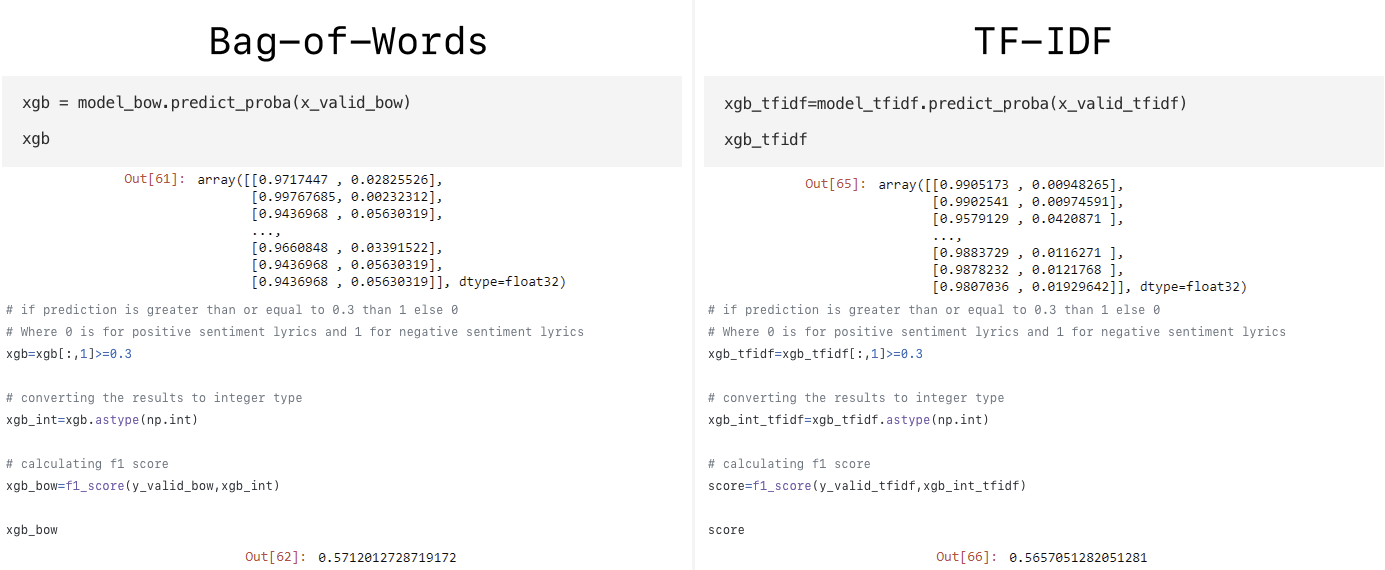
Рисунок 1 — Прогнозирование вероятности и расчёт F1 для методов Bag-of-Words и TF-IDF моделью XGBoost
Логистическая регрессия
Логистическая регрессия названа в честь функции, используемой в основе метода, логистической функции.
Логистическая функция, называемая также сигмовидная функцией была разработана статистиками для описания свойств роста населения в области экологии, растет быстро на несущей способности окружающей среды [6].. Это S-образная кривая, которая может принимать любое действительное число и преобразовывать его в значение от 0 до 1, но никогда точно не в этих пределах.
Логистическая регрессия использует уравнение в качестве представления, что очень похоже на линейную регрессию.
На рисунке 2 продемонстрированно прогнозирование вероятности попадания в положительный или отрицательный класс и расчёт F1 Score для методов Bag-of-Words и TF-IDF соответственно.
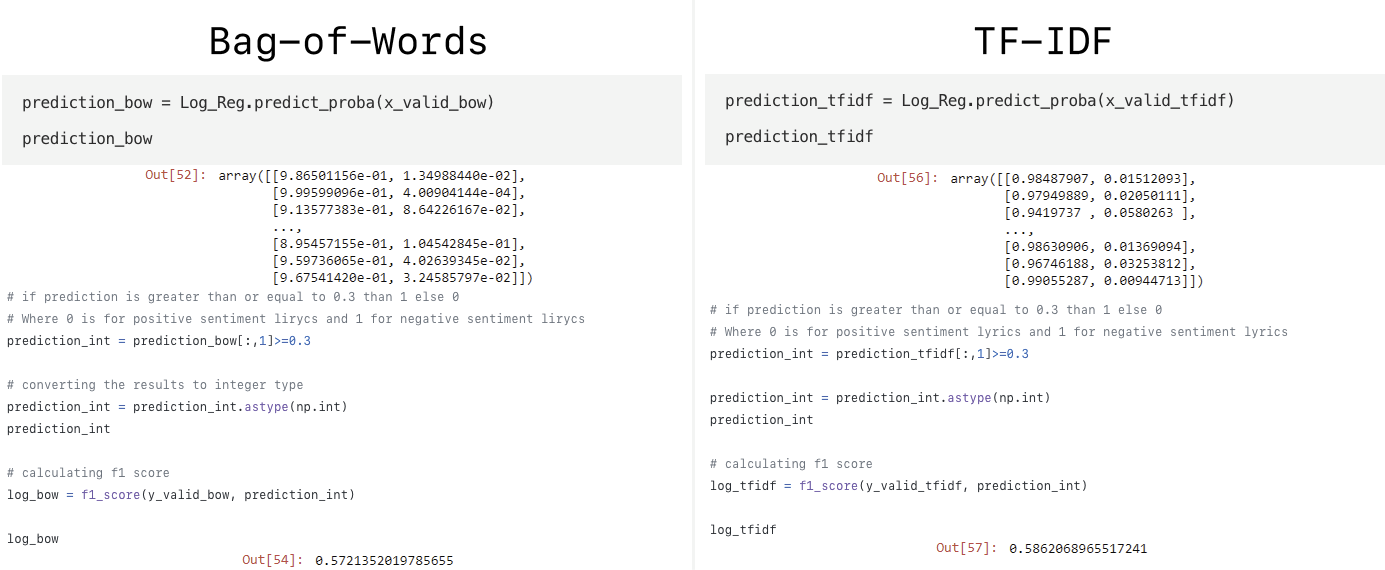
Рисунок 2 - Прогнозирование вероятности и расчёт F1 для методов Bag-of-Words и TF-IDF моделью логической регрессии
Сравнение моделей
Теперь давайте сравним разные модели, которые мы применили к нашему набору данных, с различными методами встраивания слов (см. рис. 3).
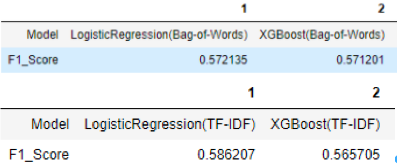
Рисунок 3 – F1 Оценка различных моделей с использованием функций из Bag-of-Words и TF-IDF
Как можно увидеть, лучшая возможная модель из Bag-of-Words и TF-IDF – это логистическая регрессия.
Сравним оценку модели логистической регрессии с двумя методами извлечения признаков, такими как Bag-of-Words и TF-IDF (см. рис. 4).
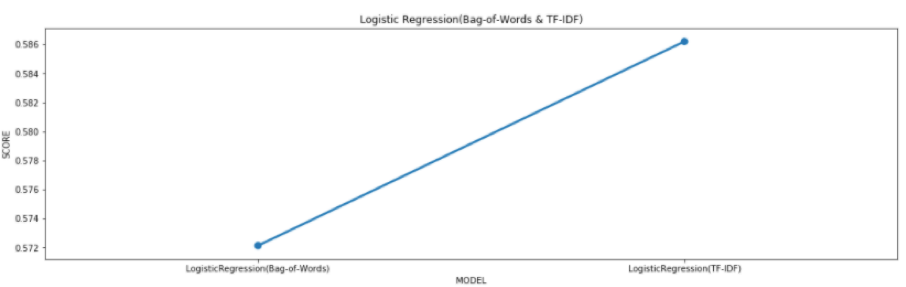
Рисунок 4 – График оценок модели логистической регрессии
Вывод
Из приведенного выше исследований, мы можем ясно видеть, что наилучший возможный показатель F1 достигается с помощью модели логистической регрессии с использованием функций TF-IDF.
Литература
1. Батура Т.В. Методы автоматической классификации текстов / Т.В. Батура // Программные продукты и системы. 2017. Т. 30. № 1. С. 85–99; DOI: 10.15827/0236-235X.030.1.085-099.
2. Sentiment Analysis on Amazon Reviews using TF-IDF Approach [Электронный ресурс], - Режим доступа:[Ссылка]
3. Ландэ Д. В. Интернетика Навигация в сложных сетях Модели и алгоритмы. — М.: Книжный дом «ЛИБРОКОМ», 2009. — с. 87-88.
4. What is the F-score? [Электронный ресурс], - Режим доступа:[Ссылка]
5. XGBoost [Электронный ресурс], - Режим доступа:[Ссылка]
6. Logistic Regression for Machine Learning [Электронный ресурс], - Режим доступа:[Ссылка]