Краткий обзор больших данных: технологии, терминология и приложения, интенсивно использующие данные
Хемн Барзан Абдалла
Журнал Big Data
habdalla@kean.edu
Хемн Барзан Абдалла. Краткий обзор больших данных: технологии, терминология и приложения, интенсивно использующие данные. В исследовании анализируются термины и методы больших данных в соответствии с несколькими факторами, такими как год публикации, показатели производительности, достижения существующих моделей и используемые методы.
Ключевые слова: Internet of Things (IoT), Big data, Application, Challenges, Techniques.
Реферат
Технические достижения и доступность огромных объемов данных в Интернете привлекают огромное внимание исследователей в области принятия решений, наук о данных, бизнес-приложений и правительства. Эти огромные объемы данных, известные как большие данные, имеют много преимуществ и приложений для исследователей. Однако использование больших данных отнимает много времени и требует огромной вычислительной сложности. В этом обзоре описывается значение больших данных и их таксономия, а также подробно излагаются основные термины, используемые в больших данных. В нем также обсуждаются технологии, используемые в приложениях для работы с большими данными, а также их различные сложности и проблемы. В обзоре основное внимание уделяется различным методам, представленным в литературе, для ограничения проблем, связанных с большими данными. В частности, обзор концентрируется на методах работы с большими данными в соответствии с их обработкой, безопасностью и хранением. Также обсуждаются различные параметры, связанные с большими данными, такие как доступность и скорость. В исследовании анализируются термины и методы больших данных в соответствии с несколькими факторами, такими как год публикации, показатели производительности, достижения существующих моделей и используемые методы. Наконец, в этой обзорной статье описывается будущее направление исследований и освещаются возможности работы с большими данными и предложения с подробным описанием сред обработки больших данных.
Введение
Большие данные стали последней и важной темой исследований из-за их широкого применения и использования в различных областях. Согласно отчету, представленному Gartner в 2013 году, большие данные занимают видное место среди инновационных технологий и входят в число ведущих трендовых технологий с 2013 по 2018 год» [88]. Большие данные характеризуются как совокупность огромных баз данных, что создает трудности при определении наилучшего класса информации для обработки сроков или обычных этапов подготовки информации. В 2012 году компания Gartner дала более подробное определение больших данных: «Большие данные описываются как высокоскоростные или потенциально объемные ресурсы данных с большим ассортиментом, которые требуют новых типов мер по обработке для улучшения динамики, знание-откровение и цикл продвижения». По большей части информационный набор, который может эффективно выполнять улов, объединение, изучение и восприятие при текущих достижениях, можно назвать «большими данными» [2]. По данным International Data Corporation (IDC) [1], в 2017 году рынок инноваций в области больших данных принес около 32,4 млрд долларов США. - исходные этапы и аппараты, большие наборы данных были созданы и доступны для тех, кто в них нуждается. Доступность этих больших наборов данных или «больших данных» для использования в приложениях для работы с большими данными, которые рекомендуют эффективную обработку информации и администрирование приложений, значительно расширила возможности удовлетворения потребностей бизнеса и запросов в повседневной жизни людей [3].
В современном мире большие данные используются почти во всех средах приложений, таких как рамки предложений, прогнозы, предполагаемые закономерности и приложения для создания фактических отчетов. Появляющиеся огромные средства обработки и администрирования данных могут использоваться в различных областях и приложениях, включая организационное управление, медиацентр, состояние окружающей среды, образовательные организации, биомедицинские услуги, медицинские услуги и науки о жизни, онлайн-медиа и системное администрирование, интеллектуальный городской транспорт и передачу данных. [2, 7]. Более того, огромные информационные приложения обычно используются в качестве предложения, предсказания [9] или схемы выбора [10]. Таким образом, выражение «информационная динамика» появляется для описания стратегий сбора и оценки информации для направления или дальнейшего улучшения выбора [9]. Динамическая структура принятия решений помогает маркетологам сосредоточиться на отслеживании рекламы, поставщикам средств защиты сосредоточиться на предоставлении индивидуальных средств защиты своим клиентам, а поставщикам медицинских услуг сосредоточиться на предоставлении пациентам высококачественной недорогой терапии [7, 8]. Это включает в себя оценку безусловной и неопределенной информации, такой как описания продуктов или аудиты клиентов. Например, эксперты по информации изучают обширную информацию, собранную из сетевых СМИ, чтобы проверить конкретную теорию.
В результате можно определить ценность, легитимность и достижимость этих гипотез, а также разработать схемы их реализации [11]. Несмотря на достижения в хранении, подборке, оценке и расчетах информации, связанных с предсказанием поведения человека, крайне важно понимать скрытые движущие силы и управляющие факторы, такие как социальные нормы, рамки, закон, принятые рынком практики и инженерии, которые помогают создавать мощные модели, способные работать с обширной информацией и, таким образом, повышать точность прогнозов [13]. Однако из-за огромного объема производимой информации, быстрой скорости, с которой эта информация становится доступной, и огромного количества разнородной информации большие информационные приложения создают новые трудности и проблемы для инженеров по обеспечению качества (QA).
Например, из-за огромного объема информации и элемента практичности признать правильность основных основанных на информации рамок ожиданий является сложной задачей. В связи с этим крупные утверждения качества информации и крупные подтверждения качества информационно-ориентированных приложений становятся серьезной проблемой, требующей дальнейшего изучения. Несмотря на то, что в нескольких предыдущих статьях изучалось качество информации и подтверждение качества информации [15, 16, 17, 18, 19, 20], очень немногие статьи посвящены одобрению огромного качества информационных приложений. Растет потребность в исследовательской работе по вопросам исследования качества и ответам на подтверждение качества для больших информационных приложений [1, 31, 42]. Следующей важной темой исследований в этой области является запрограммированный возраст метаданных, который изображает записанную информацию и описывает, как она записывается и оценивается. Безопасность [3, 21, 23] вызывает серьезную озабоченность, особенно в отношении больших данных. Например, сейчас во многих регионах действуют законы, защищающие частную жизнь пациентов. Растет опасение ненадлежащего использования индивидуальной информации, особенно когда она объединяется из различных источников. Кроме того, получение больших данных имеет свои уникальные трудности, которые сильно отличаются от тех, которые связаны с обычной информацией [2]. В этой статье приводится обзор терминологии больших данных, связанных с ними технологий и приложений.
В этой исследовательской статье описываются методы больших данных, касающиеся хранения, обработки и безопасности. Кроме того, в статье обсуждаются различные параметры, связанные с большими данными, такие как доступность и скорость. В исследовании анализируются термины и методы больших данных по нескольким факторам, таким как год публикации, показатели производительности, достижения существующих моделей и используемые методы. Наконец, в этом обзорном документе описывается будущее направление исследований, подчеркиваются возможности и приложения для работы с большими данными, а также подробно описывается структура обработки больших данных.
Структура обзорного документа выглядит следующим образом: Раздел «Введение» определяет большие данные и их различные аспекты. «Обзорный документ преследует несколько целей» В разделе представлен анализ, основанный на инструментах для работы с большими данными и архитектуре Hadoop. В разделе «Анализ на основе инструментов для работы с большими данными и архитектуры Hadoop» описывается основанное на обзоре приложение для работы с большими данными в различных областях. В разделе «Обзор и анализ технологий больших данных» освещаются проблемы, связанные с технологиями больших данных. В разделе «Анализ и обсуждение» описываются проблемы и проблемы, связанные с аналитикой больших данных, а в разделе «Проблемы, связанные с приложениями для больших данных» приводится сравнительное обсуждение с существующими статьями. Наконец, статьи завершает раздел «Аналитика больших данных: проблемы и вызовы».
Обзорная статья преследует несколько целей:
- обзор методов обработки больших данных в областях приложений, основанных на машинном обучении, глубоком обучении, облачных вычислениях, туманных вычислениях, граничных вычислениях, концентрических вычислениях, Интернете вещей (IoT), аналитике больших данных и Hadoop;
- для анализа больших данных с помощью таких инструментов, как NoSQL, Cassandra, Hadoop, Strom, Spark, Hive и OpenRefine;
- для оценки больших данных с точки зрения анализа производительности на основе точности, использования ресурсов, RMSE, SD, масштабируемости, скорости, безопасности, времени обработки, TPR, FPR, пропускной способности, скорости обнаружения, энергопотребления, среднего значения, загрузки элемента, задержки, стабильности, и ОСШ.
Определение больших данных
В отличие от обычных данных, термин «большие данные» относится к разработке огромных информационных индексов, которые включают в себя разнородные конфигурации, то есть организованную, неорганизованную и полуорганизованную информацию. Обширные данные имеют ошеломляющую природу, которая требует невероятных достижений и прогрессивных вычислений. Следовательно, традиционная технология последовательной бизнес-аналитики (BI) не может использоваться для приложений с большими данными. Большие данные производятся из разных источников и в различных конфигурациях (например, записи, отчеты, примечания и журналы). Огромные массивы данных содержат информацию организованную и неорганизованную, частную и публичную, соседнюю и удаленную, разрозненную и секретную, а также полную и неадекватную [4, 18]. Большинство исследователей и специалистов характеризуют большие данные пятью сопутствующими основными атрибутами, называемыми 5 V: объем, скорость, разнообразие, достоверность и ценность. Пять V в больших данных кратко описаны ниже.
Объем
Объем представляет величие информации. Большие объемы информации составляют разные терабайты и петабайты. Обзор, проведенный международной организацией International Business Machines Corporation (IBM) в 2012 году, показал, что более части из 1144 респондентов считают наборы данных объемом более одного терабайта колоссальной информацией. В одном терабайте хранится столько информации, сколько уместилось бы на 220 DVD-дисках или 1500 компакт-дисках, что достаточно для резервирования до 16 миллионов изображений Facebook, а один петабайт эквивалентен 1024 терабайтам. В отчете говорится, что Facebook создает миллиарды изображений в секунду, что эквивалентно одному петабайту. По предварительной оценке, Facebook хранит более 260 миллиардов изображений, занимая около 20 петабайт. Описание больших объемов данных является случайным и различается в зависимости от таких факторов, как способ сортировки данных и время получения информации. В будущем может стать трудным поддерживать огромные объемы данных, потому что пределы емкости могут быть увеличены, что позволит зафиксировать значительно больший объем информационных индексов. Кроме того, вид информации, обсуждаемой в разделе «ассортимент», характеризует то, что подразумевается под «крупным». Для двух наборов данных одинакового размера может потребоваться разная информация, а исполнительные инновации зависят от того, как сортируются базы данных. Кроме того, значение огромной информации зависит от бизнеса. Следовательно, эти факторы делают нецелесообразным определение определенного предела для больших объемов информации [8].
Разнообразие
Разнообразие определяется как конструктивная диверсификация в наборе данных. Современные технические достижения позволяют фирмам использовать различные типы организованной, неорганизованной и неструктурированной информации. Организованная информация, которая составляет 5% всех текущих данных, ссылается на простую информацию, найденную в наборах социальных данных или электронных таблицах. Текст, изображения, звук и видео — это экземпляры неструктурированной информации, в которой иногда отсутствуют первичные ассоциации, необходимые машинам для исследования. Организация полуорганизованной информации не соответствует строгим правилам, разделяя пополам взаимосвязь между все более неорганизованной и организованной информацией. Расширяемый язык разметки (XML), текстовый язык для торговли информацией в Интернете, является обычной иллюстрацией полуорганизованной информации. Записи XML содержат информационные метки, характеризуемые клиентом, что делает их машинно-значимыми. Они обладают неоспоримой степенью разнообразия, характеристикой, нормальной для огромного объема информации. Ассоциации долгое время хранили неструктурированную информацию из внутренних источников (например, информацию с датчиков) и внешних источников (например, онлайн-СМИ). Тем не менее, современная творческая точка зрения поощряет разработку новой информации, исполнительных достижений и исследований, которые позволяют ассоциациям использовать информацию в своих деловых мероприятиях. Например, инновации распознавания лиц позволяют физическим ритейлерам получать информацию о загруженности магазинов, поле или возрасте их клиентов, а также о планах их развития в магазине. Эти жизненно важные данные используются при продвижении предметов, ситуациях и выборе персонала. Информация о посещениях предоставляет онлайн-продавцам множество данных и примеров поведения клиентов, что дает им информацию об обстоятельствах и группировке страниц, просматриваемых клиентом. Используя массовые исследования информации, даже малые и средние предприятия (SME) могут добывать чудовищные объемы полуорганизованной информации для дальнейшей разработки веб-архитектуры и внедрения жизнеспособных стратегических питчей и индивидуальных сред предложения товаров.
Скорость
Скорость определяется как скорость, с которой создается информация, и скорость, с которой она должна оцениваться и отслеживаться. Расширение передового оборудования, например, персональных цифровых помощников (КПК) и датчиков, привело к феноменальным темпам производства данных и вызывает растущую потребность в непрерывных исследованиях и организации, основанной на доказательствах. Даже традиционные ритейлеры создают информацию с высокой повторяемостью. Например, Wal-Mart измеряет более 1 000 000 обменов в час. Информация, исходящая от сотовых телефонов и перемещающаяся через универсальные приложения, создает потоки данных, которые можно использовать для создания текущих индивидуальных предложений для постоянных клиентов. Эта информация предоставляет подробные данные о клиентах, такие как геопространственная территория, социально-экономические показатели и прошлое покупательское поведение, которые можно постоянно исследовать для повышения подлинного уважения клиентов [10].
Правдивость
Достоверность указывает на точность и достоверность данных, которые собираются из различных источников. Есть некоторые возможности смешивания неточных и необработанных данных. Следовательно, достоверность данных указывает на надежность и уровень неопределенности данных [7].
Ценность
Значение представляет собой определяющий атрибут больших данных. Оценка больших объемов данных обеспечивает высокую ценность, что, в свою очередь, увеличивает знания, полученные из данных [10].
Визуальная аналитика в больших данных
Визуальная аналитика (VA) концентрируется на содействии взаимодействию и исследованию при анализе больших сложных данных. Визуальная аналитика больших данных зависит от трех основных уровней: уровня визуализации, уровня аналитики и уровня управления данными. Краткое описание каждого уровня дано в следующем подразделе.
Визуализация
Термин визуализация определяется как использование коллективного визуального представления концептуальных данных для улучшения восприятия. Функциональность и эстетическая форма необходимы для легкой передачи информации. Такая информация, как переменные и атрибуты, абстрагируется от данных в семантической форме. Одна из платформ онлайн-маркетинга, известная как eBay, использует инструмент визуализации данных, чтобы понять все данные, созданные их клиентами. Следовательно, сотрудники eBay используют инструмент визуализации для отслеживания последних отзывов клиентов, чтобы обеспечить более высокое качество услуг. Проведение визуализации больших данных — сложный процесс из-за их высокой размерности и большого размера. Визуализация требует рассмотрения, поскольку она должна управлять набором данных с большим объемом и скоростью [87, 89].
Аналитика
Аналитика определяется как процесс получения выводов из больших данных посредством оценки данных. Исследователи применяют несколько методов обработки в процессе оценки для достижения предпочтительного результата. Если данных мало, обзор можно выполнить быстро, и данные визуализируются с помощью средства построения диаграмм. Следовательно, интеграция аналитической среды с визуальной средой широко используется в промышленности и исследованиях. Если данных много, интеграция визуализации и аналитики может не сработать и вызвать проблемы с масштабируемостью [89].
Управление данными
Управление данными является важным аспектом приложений VA, поскольку оно помогает управлять жизненным циклом данных. Управление данными способствует обеспечению качества, поиску и сохранению данных с течением времени. Обычные инструменты управления данными не справляются с большими данными, которые являются сложными и большими [89].
В разделе «Обзорный документ преследует несколько целей» представлено краткое описание существующих инструментов для обработки больших данных, а также их преимуществ и недостатков.
Анализ на основе инструментов больших данных и архитектуры Hadoop
В первой части этого раздела дается краткое описание инструментов для работы с большими данными, а во второй части раздела объясняются технологии работы с большими данными на основе инструмента Apache. В третьей части раздела рассказывается об экосистеме Hadoop в больших данных. В этой части анализируются инструменты и технологии с их плюсами и минусами, что помогает исследователям выбрать лучшие инструменты для обработки больших данных.
Инструменты больших данных
Дальнейшее развитие бизнеса чрезмерно зависит от интенсивной оценки больших данных. Анализ больших данных играет важную роль в процессе принятия решений, направленных на продвижение и процветание ассоциации [9]. В любом случае чисто вычислительные измерения информации с помощью обычных информационных вычислительных устройств не дают продуктивных результатов, и устройство недостижимо. Поэтому за последние годы было разработано несколько инструментов для работы с большими данными, которые помогают ассоциациям и исследователям данных продуктивно и с минимальными затратами делать выводы о выборе, основанном на информации. Ассортимент аналитики больших данных [4,5,6,7, 13, 25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41 ] устройства используются специалистами для работы с хранением информации, управлением информацией, очисткой информации, добычей информации, прогнозированием данных и подтверждением данных. В этом разделе кратко описаны инструменты, используемые для анализа BD [33, 50].
noSQL
Как правило, SQL (язык структурированных запросов) широко используется для ограничения и анализа структурированных данных. Однако стремительное развитие неопределенных данных вызвало появление неструктурированных информационно-аналитических аппаратов. В конце концов появился SQL (NoSQL) для продуктивной работы с неорганизованными моделями данных. Информационные базы NoSQL в основном не придерживаются архитектуры, храня неопределенные данные. В последующем значения сегмента таблицы сдвигаются по каждой информационной записи (строке). Из-за этой неархитектурной природы система уравновешивает согласованность с импульсом, адаптацию к внутренним сбоям и доступность. Хотя за последние несколько лет NoSQL приобрел огромное распространение, проблемы возникают из-за низкоуровневых диалектов запросов, а отсутствие нормализованных интерфейсов еще предстоит рассмотреть [12].
Cassandra
Cassandra — это тип NoSQL, непатентованный и распространяемый набор данных, который управляет исключительно огромными наборами данных от различных поставщиков. Великолепие Cassandra заключается в низкой отказоустойчивости, гарантирующей высокую доступность при любых условиях. Таким образом, группа экспертов предпочитает Cassandra, когда универсальность и доступность имеют решающее значение, не влияя на производительность исполнения. Кроме того, Cassandra обеспечивает репликацию информации в различных облаках [19] или фермах серверов, чтобы гарантировать более низкий уровень бездействия и адаптацию к внутренним сбоям.
Hadoop
Hadoop — это система, включающая набор библиотек программирования, которые объединяют различные модели программирования, чтобы обеспечить распределенные вычисления огромных наборов данных. Универсальность является значительным преимуществом, связанным с системой Hadoop, где рассредоточенный репозиторий независимо называется распределенной файловой системой Hadoop (HDFS). Эта структура Hadoop представляет собой высокодоступный аналитический инструмент, независимый от аппаратного оборудования. Вместо этого он объединяет библиотеки программирования, чтобы различать, распознавать и ограничивать недостатки на уровне реализации. Система Hadoop включает обычные библиотеки, архивные библиотеки, Hadoop YARN и Hadoop MapReduce для вычисления обширных наборов данных.
Strom
Storm — это бесплатная непатентованная платформа распределенной обработки непрерывного действия, которая управляет огромным объемом потоковой информации, напоминающей кластерные вычисления Hadoop. Великолепие шторма обрабатывается с помощью языка программирования, и для обеспечения законного непрерывного опыта расследования шторм координирует текущие компоненты очередей в дополнение к инновациям в наборах данных. Процедура потоковой передачи штормов требует сложных и субъективных пакетов на каждом алгоритмическом этапе. Расследование в режиме реального времени, непрерывное выполнение и онлайн-обучение (машинное обучение) — это часть ключевых администраций, рекомендованных Storm.
Spark
Spark — широко распространенная распределенная система кластерной обработки данных с открытым исходным кодом. Spark обеспечивает лучшую производительность как при потоковых информационных вычислениях, так и при кластерных вычислениях. Spark координирует свои действия с GraphX, SQL, сегментами потоковой передачи Spark и MLib. Spark проверяет информацию из разных источников данных и выполняет ее на разных этапах, таких как Mesos, Yarn и Hadoop. Поскольку одно и то же регулирование кода может применяться как к постоянным вычислениям, так и к кластерным вычислениям, искра считается продуктивной при оценке шторма. Тем не менее, шторм приобрел преобладание с точки зрения бездействия с меньшим количеством ограничений.
Hive
Hive — это межэтапный центр программирования распространения информации, работающий на Hadoop, который позволяет оценивать информацию и запрашивать информацию в многочисленных областях хранения и структурах документов, координируемых с Hadoop. Чтобы запрашивать передаваемые структуры документов, Hive обеспечивает отражение SQL с помощью HiveQL, языка запросов, подобного SQL. Впоследствии ходатайства не требуют обработки вопросов, используя API-интерфейсы Java более низкого уровня. HiveQL напрямую переходит на вопросы в Apache Tez, MapReduce и Spark. Кроме того, Hive предлагает списки для дальнейшего увеличения скорости обработки запросов.
OpenRefine
OpenRefine — это непатентованное независимое предложение, недавно известное как Google Refine. Эта структура широко используется в современном информационном мире для очистки зашумленной и грубой информации и изменения информации, начиная с одной структуры, а затем с другой. OpenRefine связан с обычными таблицами систем управления реляционными базами данных (RDBMS), которые хранят строки информации в разделах. Тем не менее, это отступление от традиционной ситуации, поскольку никакие уравнения не накапливают ячейки под разделами. Кроме того, уравнения, используемые в OpenRefine, изменяют информацию, и изменения разрешены только один раз [6].
Версия инструментов апача
В этом разделе подробно перечисляются различные технологии, используемые в больших данных на основе инструмента apache, и мы даем возможность глубже понять эти технологии.
Apache flume
Apache Flume [20, 43, 44] — это рассредоточенная, надежная и доступная среда для эффективного сбора, понимания и передачи большого количества журнальной информации из широкого круга источников во встроенное хранилище информации. Основное преимущество apache flume заключается в том, что он устойчив к ложным срабатываниям, надежен, масштабируем и доступен для различных приемников и источников. Кроме того, Apache Flume помогает хранить данные в централизованных хранилищах, таких как HDFS и HBase [10, 47]. Основное ограничение заключается в том, что нет никаких гарантий упорядочения любого из событий. Следовательно, в будущем исследования должны преодолеть гарантии нулевого порядка, чтобы обеспечить правильную доставку пакетов данных.
Apache sqoop
Apache Sqoop — это устройство с интерфейсом командной строки (CLI), предназначенное для перемещения информации между наборами данных Hadoop и социальных сетей. Sqoop может использовать неявную информацию из СУБД [17], например, из набора данных Oracle или MySQL, хранящихся в HDFS, а затем распространять информацию обратно после того, как MapReduce изменил информацию. Sqoop дополнительно переносит информацию в Hive и HBase и связан с РСУБД через коннектор подключения к базе данных Java (JDBC) и зависит от РСУБД для отображения архитектуры набора данных для импортируемой информации. Apache Sqoop обеспечивает более быстрые, эффективные и недорогие процессы разгрузки, такие как ETL (извлечение, загрузка и преобразование). В будущем необходимо уделять больше внимания уменьшению ошибок импорта и экспорта, которые снижают производительность системы Apache Sqoop.
Apache pig
Pig от Apache — это важное предприятие, которое наследует лидирующие позиции Hadoop и позволяет языкам программирования более высокого уровня использовать библиотеку MapReduce от Hadoop. Pig дает язык предварительной подготовки для описания задач, таких как просмотр, разделение и изменение, консолидация и компоновка информации, которые точно выполняют аналогичные действия, для которых MapReduce изначально предназначался. Вместо того, чтобы сообщать об этих задачах в огромном количестве строк кода Java, MapReduce используется напрямую, а Apache Pig позволяет клиентам общаться на другом языке, который отличается от обычных программ, таких как Perl или сценарий slam. В отличие от других SQL, Pig не требует архитектуры данных, поэтому уместно ограничить неструктурированную информацию. Тем не менее, Pig в любом случае может использовать ценность архитектуры, предполагая, что клиенты должны внести свой вклад. PigLatin сравнительно совершенен, как и SQL, и кульминация поворота требует ограничительной формулировки, неограниченных фреймворков памяти [18] и всеобъемлющего фреймворка. Отсутствие интегрированной среды разработки (IDE) — главный недостаток свинской системы Apache. Будущие исследования свиньи Apache состоят в разработке среды IDE, которая предлагает функции для компиляции сценариев свиньи.
Apache hive
Hive — это инновация, созданная Facebook, которая превращает Hadoop в центр распределения информации, заканчивающийся вызовом SQL для запросов. HIVEQL — решающий язык в SQL. В PigLatin поток информации определяют клиенты. Однако в Hive клиенты изображают результат, требуемый для клиента, а куст выбирает способ собрать информационный поток для достижения требуемого результата. В отличие от Pig, Hive требует сборки, но клиенты не ограничены только одной композицией. Подобно SQL и PigLatin, HiveQL сам по себе является сравнительно терминальным языком. Высокая задержка — главный недостаток Apache Hive, который следует учитывать в будущих исследованиях.
Apache ZooKeeper
Apache Zoo Keeper — это попытка создать и поддерживать поставщиков с открытым исходным кодом, которые обеспечивают надежную распределенную координацию. Он обеспечивает администрирование распределенного дизайна, управление синхронизацией и хранилище имен для передаваемых платформ. Распространяемые приложения используют ZooKeeper для хранения и передачи обновлений, чтобы неявно отображать данные. Смотритель зоопарка особенно быстро справляется с обязанностями, когда просмотр информации скорее нормальный, чем собранный. Установлено, что наилучшее соотношение чтения/составления составляет 10:1, и Zoo Keeper воссоздается по группе хостов, известной как труппа, и провайдеры знают друг о друге, и нет узлов сбоя. Существует вероятность случайной потери данных, поскольку он не поддерживает избыточное количество модулей. Следовательно, будущим направлением исследований является разработка платформы для поддержки избыточного количества модулей, чтобы избежать случайной потери данных.
Apache Cassandra
Apache Cassandra — это другой непатентованный исходный набор данных NoSQL, в котором реализованы современные инновации, способные справиться с огромными информационными потребностями. Это чрезвычайно универсальная и элитная структура администрирования информационной базы, которая может работать с огромным количеством текущих приложений, которые управляют ключевыми структурами для современных и эффективных организаций. Компания разработала масштабируемую структуру, которая может обрабатывать петабайты данных и миллионы клиентов/действий каждую секунду так же эффективно, как поддерживать скромные объемы информации и клиентского трафика. Apache Cassandra также оснащен адаптируемым/мощным планом проектирования, который поддерживает все механизмы больших информационных приложений, включая организованную, полуорганизованную и неструктурированную информацию. Cassandra обращается к информации через семейства динамических сегментов, которые обязывают все изменения в сети. Задержка Apache Cassandra из-за чрезмерных запросов и данных, как правило, будет сведена к минимуму в будущих направлениях исследований.
Apache Hadoop
Медиацентр обработки Apache Hadoop — это структура, которая позволяет распространять обработку огромных информационных индексов между группами компьютеров. Он предназначен для увеличения от отдельных рабочих до огромного количества машин, с каждой соответствующей оценкой и пропорциями района. Основная идея состоит в том, чтобы позволить одиночному вопросу обнаруживать и собирать результаты от всех индивидуумов кластера. Эта модель точно соответствует структуре поддержки поиска Google. Одной из самых серьезных механических трудностей в исследованиях фреймворков программирования сегодня является предоставление системам возможности контролировать и восстанавливать данные на огромном количестве информации. MapReduce — это чрезвычайно адаптируемая структура параллельных вычислений, обычно используемая с Hadoop и другими частями, такими как YARN и HDFS. YARN можно представить как широкомасштабную, распределенную рабочую среду для выполнения огромных объемов информации. С развитием Hadoop кластеризованные и сосредоточенные на дисках препятствия MapReduce получили более четкое представление, поскольку анализ больших данных все чаще переходит к своевременному приложению, обработке потоков и поэтапному выполнению. MapReduce включает самый быстрый, самый экономичный и самый универсальный компонент для получения результатов. Сегодня подавляющее большинство основных нововведений для надзора за «большой информацией» создано на MapReduce. MapReduce имеет несколько ограничений по адаптивности. Однако его прямое использование требует составления и хранения большого количества кода. Следовательно, направление будущих исследований состоит в том, чтобы уменьшить количество кодов, чтобы свести к минимуму вычислительную задержку.
Apache Splunk
Apache Splunk — это широко используемый инструмент для изучения, исследования и детализации текстовой информации о временных рядах, полученной из машинной информации. Программирование Splunk используется, по крайней мере, для решения одной центральной ИТ-задачи: руководителей приложений, безопасности, согласованности, управления ИТ-задачами и изучения бизнес-запросов. Мотор Splunk был улучшен для быстрой организации и обслуживания неструктурированной информации, размещенной в фреймворке. В частности, Splunk использует незначительную конструкцию для непрерывной информации, а события включают только грубый текст события, предполагаемую метку времени, источник (имя файла для источников данных на основе документов), тип источника (признак общего вида информации), и хост (откуда началась информация). Инфраструктура Apache помогает создавать приложения для работы с данными в реальном времени. Когда информация поступает в структуру Splunk, она быстро обрабатывается, сохраняется в своей грубой структуре и регистрируется в вышеуказанных полях рядом с каждым из ключевых слов в исходном тексте события. Планирование является фундаментальным компонентом стандартного варианта использования «super-grep» для Splunk, но оно также ускоряет большинство процессов восстановления. В этих грубых случаях любые более современные вычисления разрешены до конца поиска. Это служит четырем важным целям: скорость выполнения увеличивается, так как выполняется незначительная подготовка, внесение новой информации в структуру — это, как правило, практика с небольшими усилиями, поскольку не требуется систематизация шаблонов, первая информация сохраняется для простого изучения, и структура универсальна для изменения. поскольку синтаксический анализ информации не требует перезагрузки или изменения порядка информации [2]. В будущем инструменты мониторинга должны быть усовершенствованы для поддержки больших объемов данных.
Большие данные и экосистема Hadoop
Возможности Hadoop
Фреймворк Hadoop — это заметная инновация для работы с большими данными, которая существенно поддерживает локальные области. Он был разработан, чтобы избежать низкой демонстрации и сложности, возникающих при ограничении и анализе больших данных с использованием традиционных инноваций. Одним из основных преимуществ Hadoop является его способность быстро справляться с огромными информационными коллекциями благодаря равным группам и структуре передаваемых документов. В отличие от традиционных достижений, Hadoop не копирует всю удаленную информацию для выполнения вычислений в памяти. Скорее, Hadoop выполняет поручения, где хранится информация. Таким образом, Hadoop снижает нагрузку на организации и провайдеров по переписке. Еще одним преимуществом Hadoop является его способность запускать программы, гарантируя адаптацию к некритическим сбоям, обычно возникающим в условиях рассредоточенного климата. Это предотвращает потерю информации, имитируя информацию рабочих, чтобы гарантировать это. Сила этапа Hadoop зависит от двух фундаментальных подсегментов: распределенной файловой системы Hadoop (HDFS) и структуры MapReduce (поясняется в сопутствующих сегментах). Точно так же клиенты могут добавлять модули поверх Hadoop в зависимости от ситуации, указанной их целями, и предварительными условиями их приложений (например, ограничениями, выставками, надежностью, адаптивностью и безопасностью). Как правило, организация Hadoop добавила для улучшения своей биологической системы несколько непатентованных модулей. Точно так же ИТ-продавцы прилагают невероятные усилия, чтобы укрепить преимущества, переданные в ассигнованиях Hadoop [86].
Уровень хранения информации
Hadoop зависит от фреймворка, такого как HBase и HDFS, для накопления информации, его фреймворка документов HDFS и самодостаточного набора данных под названием Apache HBase.
HDFS — это система накопления информации, которая поддерживает до нескольких узлов в связке и обеспечивает практичную и надежную возможность накопления. Он может работать как с организованной, так и с неструктурированной информацией и хранить огромные объемы (т. е. хранящиеся документы могут превышать терабайт). Тем не менее, клиенты должны знать, что HDFS не устанавливает структуру общего назначения, поскольку она была разработана для кластерных вычислений с высокой степенью простоя. Кроме того, он не дает быстрых запросов записи в документах. Основным преимуществом HDFS является ее универсальность для разнородного оборудования и этапов программирования. Кроме того, HDFS помогает уменьшить засорение организации и увеличить производительность инфраструктуры, перемещая вычисления ближе к накоплению информации. Это гарантирует дублирование дополнительной информации для адаптации к внутреннему сбою. Эти основные моменты объясняют его широкий прием. HDFS зависит от схемы ведущий-ведомый. Он выделяет огромное количество информации в группу. Действительно, в группе есть новый эксперт (NameNode), который контролирует деятельность структуры документа, и множество ведомых устройств (DataNodes), которые контролируют и организуют накопление информации на отдельных узлах реестра. Чтобы обеспечить доступность информации, Hadoop расположен на репликации информации.
>HBase — это присвоенный независимый набор данных и непатентованный проект, разработанный на основе производительности HDFS и предназначенный для операций с малой задержкой. Hbase зависит от раздела, упорядоченного по ключу/почитай информационную модель. Он может поддерживать высокие скорости обработки стола и работать на ровной поверхности в передаваемых группах. HBase обеспечивает гибкую и организованную поддержку огромных таблиц в организации, подобной BigTable. Таблицы хранят информацию связно в строках и разделах. Преимущество таких таблиц в том, что они могут работать с миллиардами строк и огромным количеством сегментов. С помощью HBase несколько атрибутов могут быть собраны в семейства разделов, что позволяет хранить компоненты семейства сегментов вместе. Эта методология отличается от линейного набора социальных данных, где все разделы строки хранятся вместе. Следовательно, HBase более адаптируется, чем базы социальной информации. При прочих равных условиях HBase имеет то преимущество, что позволяет клиентам получать обновления с лучшей обработкой изменяющихся требований приложений. Каждая таблица должна иметь охарактеризованный шаблон с первичным ключом, который используется для доступа к таблице. Строка распознается по имени таблицы и ключу запуска, в то время как разделы могут иметь несколько адаптаций для аналогичного ключа строки. Hbase предоставляет множество возможностей, таких как текущие запросы, поиск на обычном языке, предсказуемый доступ к источникам больших данных, прямая и взвешенная адаптивность, а также запрограммированные и настраиваемые фрагменты таблиц. Он известен некоторыми соглашениями о больших данных и информационными сайтами, такими как информационная платформа Facebook. HBase включает Zookeeper, чтобы координировать администрирование и выполнять функции Zookeeper естественным образом. В дополнение к HBase в HDFS есть MasterNode, который управляет группой, и подчиненные устройства, которые резервируют части таблиц и выполняют процедуры с информацией [74].
Уровень обработки данных
YARN и MapReduce устанавливают две альтернативы полной обработки информации в Hadoop. Они предназначены для наблюдения за резервированием работ, активами и группой. Стоит отметить, что YARN более традиционен, чем MapReduce.
- во-первых, работа с картой разделяет информацию, такую как длинные записи контента, на пакеты свободной информации, которые составляют наборы ключевых значений;
- затем, в этот момент, система MapReduce отправила все наборы ключевых значений в Mapper, который измеряет каждый из них независимо, всего в нескольких одинаковых направляющих назначениях в группе. Каждая информационная посылка назначается одному из узлов обработки. Mapper дает по крайней мере один средний набор ключевых значений. На этом этапе структура собирает все переходные наборы ключевых значений и классифицирует их по ключевому признаку. Таким образом, результатом являются многочисленные ключи со списком связанных качеств;
- затем работа по сокращению используется для работы с информацией о среднем доходе. Для каждого экстраординарного ключа работа Сокращения сочетает качества, связанные с ключом, как указано в предопределенной программе (т. е. просеивание, суммирование, упорядочивание, хеширование, принятие нормальных значений или отслеживание самых крайних). С этого момента он создает по крайней мере один набор ключевого значения доходности;
- наконец, структура MapReduce сохраняет все результаты набора значений Key-value в выходном документе. Внутри мировоззрения MapReduce NameNode работает как событие JobTracker для планирования различных позиций и передачи задач через подчиненный узел. JobTracker отслеживает ситуацию с ведомыми концентраторами и переназначает назначения, когда они терпят неудачу, чтобы защитить надежность реализации. Каждый из подчиненных узлов запускает представителей системы отслеживания заданий для выделенного назначения. Событие TaskTracker выполняет назначения, указанные JobTracker, и контролирует их выполнение. Каждый TaskTracker будет использовать несколько виртуальных машин Java (JVM) для выполнения нескольких инструкций или уменьшения сбоев в сети. Как правило, коллекция Hadoop состоит из поставщиков клиентов, разных узлов данных и двух узлов имен (обязательных и необязательных). Работа клиентских провайдеров заключается в том, чтобы сначала собрать информацию в стек, а затем отправить оккупации MapReduce в NameNode. Важнейший Master NameNode стремится облегчить и контролировать производительность и расчеты. Затем снова вспомогательный эксперт NameNode занимается репликацией и доступностью информации. Настоящий новый работник может выполнять три задания: клиент, эксперт и ведомые в небольшом кластере в пределах 40 узлов. Тем не менее, каждая работа должна быть назначена отдельному рабочему станку в средних и огромных группах.
Фреймворк YARN более традиционен, чем MapReduce. Это обеспечивает превосходную универсальность, равенство и прогрессивное управление активами по сравнению с MapReduce. Он предоставляет возможности рабочей среды для научного сбора больших данных. Исполнительный директор YARN Resource интегрирован в модифицированную структуру Hadoop. В частности, реализация YARN происходит на пике HDFS. Эта позиция обеспечивает параллельное выполнение нескольких приложений. Это позволяет обрабатывать как пакетную обработку, так и интерактивную обработку в реальном времени. YARN совместим с интерфейсом прикладного программирования (API) MapReduce. Пользователям нужно просто перекомпилировать задания MapReduce, чтобы запустить их в YARN. В отличие от MapReduce, YARN повышает эффективность, разделяя две основные функции JobTracker на два отдельных домена:
- диспетчер ресурсов (RM) распределяет ресурсы в кластере и управляет ими;
- Application Master (AM) — это система, состоящая из огромных архивов, выделяющих определенные задачи, которые уравниваются с помощью TaskTrackers для отслеживания их улучшения. AM расширяет возможности таких задач, как накопление книг, увековечивание счетчиков, сбой самоограничения или задержка.
Структура MapReduce — это многофункциональный Java API, который предоставляет большое количество возможностей для быстрого и экономичного продвижения, тестирования и согласования приложений для работы с большими данными. Каскадирование обладает интригующими преимуществами, позволяет контролировать прогрессирующие вопросы и заботится о сложных рабочих процессах в группах Hadoop. Он поддерживает адаптируемость, компактность, включение и управляемый тестированием поворот событий. Этот API добавляет уровень обсуждения на высшей точке Hadoop, чтобы улучшить сложные запросы с помощью падающей идеи. Стекированная информация обрабатывается и разделяется последовательностью мощностей для получения многочисленных потоков, называемых потоками. Эти потоки формируют нециклические согласованные графики и могут быть объединены в зависимости от ситуации. Сбор строк характеризует поток, который должен проходить между источниками информации (Source Taps) и выходной информацией (Sink Taps), которые связаны с линией. Сбор строк может содержать как минимум один кортеж заданного размера. Каскадный поток компилируется в Java и во время выполнения преобразуется в образцовый MapReduce. Потоки выполняются в группах Hadoop и зависят от сопутствующего цикла. Пример потока — это рабочий процесс, который сначала просматривает информацию от одного или нескольких источников, прежде чем измерять их, выполняя набор одинаковых или последовательных действий, характерных для группы линий. Затем, в этот момент, он объединяет информацию об доходе в один или несколько кранов раковины. Кортеж обращается к набору свойств (например, к записи набора данных таблицы SQL), которые можно упорядочить с помощью полей и можно напрямую поместить в любой дизайн файла Hadoop в виде пары ключ/оценка. Кортеж должен иметь эквивалентные сортировки для работы с корреляцией кортежей. Огромное количество было добавлено в каскадную структуру для повышения ее мощности, в том числе:
- шаблон используется для создания предвидящих огромных информационных приложений. Он выполняет множество вычислений ИИ и позволяет расшифровывать архивы Predictive Model Markup Language (PMML) в запросах на Hadoop;
- Scalding используется как уникальный язык программирования для решения практических задач. Это зависит от языка Scala с простыми механизмами. Это расширение создано и поддерживается Twitter;
- Cascalog позволяет расширять возможности приложения с помощью Clojure (мощный язык программирования, основанный на жаргоне Lisp) или java. Он поддерживает специальные запросы, выполняя ряд многочисленных функций MapReduce для изучения различных источников (локальные данные, HDFS и информационные базы). Это дает более значительный уровень отражения, чем Hive или Pig;
- Lingual обеспечивает связь ANSI-SQL с Apache Hadoop и поддерживает быстрое перемещение информации и заданий в и из Hadoop. С помощью Lingual проще координировать текущие инструменты Business Intelligence и различные приложения [47].
Уровень запроса информации
Усовершенствованный язык сценариев Pig Latin был разработан непатентованной системой, известной как Hive, Pig и JAQL. Он уменьшает сложность MapReduce, поддерживая параллельные вычисления задач MapReduce и рабочих процессов в Hadoop. Похожий на свинью Hive упрощает исследование и вычисления в таких же огромных информационных индексах с использованием HDFS (например, сложный информационный поток для ETL, другой анализ информации) благодаря интуитивно понятному интерфейсу. Pig допускает дополнительные ассоциации с внешними проектами, такие как содержимое оболочки, пары и другие диалекты программирования. Pig имеет свою информационную структуру, известную как Map Data, которая представляет собой набор наборов ключевых значений. Свиная латынь имеет множество преимуществ. Это зависит от структуры естественного языка, чтобы помочь простым задачам MapReduce и рабочим процессам (базовым или установленным потокам). Это уменьшает время продвижения, сохраняя при этом сходство. Таким образом, клиенты могут полагаться на язык Pig Latin и нескольких администраторов для передачи и обработки информации. Как правило, администраторы, которые циклически перемещают информацию, создают узлы в таком DAC, а ребра вводят информационные потоки. Несмотря на SQL, Pig не нуждается в композиции и может обрабатывать полуорганизованную и неструктурированную информацию. Он поддерживает большее количество информационных дизайнов, чем Hive. Свинья может работать как на ближайшей среде в одиночной JVM, так и на переданной среде в группе Hadoop. JAQL — это решающий язык поверх Hadoop, который предоставляет язык вопросов и поддерживает BDA [14, 24, 28, 45, 46]. Он заменяет запросы значительного уровня на задачи MapReduce. Он был разработан для запроса полуорганизованной информации, зависящей от дизайна JSON (нотация объектов JavaScript). Чаще всего он используется для опроса различной информации, организованной так же, как и многочисленные типы информации (например, XML, информация о качествах, изолированных запятыми (CSV), документы уровня). В этом смысле JAQL, как и Pig, не нуждается в отображении информации. JAQL предоставляет несколько готовых мощностей, центральных администраторов и соединителей ввода-вывода. Такие компоненты гарантируют подготовку, накопление, интерпретацию и преобразование информации в формат JSON. Apache Hive — это структура хранилища информации, предназначенная для улучшения использования Apache Hadoop. Вместо MapReduce, который управляет информацией в записях через HDFS.
Hive позволяет обращаться к информации в организованном наборе данных, который в основном предназначен для клиентов. Как правило, информационная модель Hive основана на таблицах. Такие таблицы адресованы каталогам HDFS и разделены на части. Затем каждый сегмент делится на ведра, известные как ведра. Кроме того, Hive предоставляет SQL-подобный язык под названием HiveQL, который позволяет клиентам получать и контролировать информацию на основе Hadoop, хранящуюся в HDFS или HBase. Таким образом, Hive подходит для некоторых бизнес-приложений. Hive не подходит для постоянного обмена. Действительно, это зависит от деятельности с низким уровнем покоя. Как и Hadoop, Hive предназначен для вычислений в огромных масштабах, поэтому даже для небольших позиций могут потребоваться минуты. На самом деле HiveQL напрямую изменяет запросы (например, импровизированные вопросы, соединения и краткое изложение) в занятия MapReduce, которые подготовлены как сбои кластера. Hive также позволяет подключать обычные преобразователи и редьюсеры, когда невозможно или расточительно передавать их в HiveQL. В отличие от SQL, который имеет подсветку схемы при составлении, Hive имеет шаблон при чтении и поддерживает различные композиции, что допускает использование схемы до тех пор, пока вы не попытаетесь просмотреть информацию. Однако преимущество заключается в более быстрых стеках, а недостаток в том, что вопросы задаются несколько медленнее. Куст нуждается в полной поддержке SQL и не обеспечивает встроенных обновлений или стираний на уровне столбцов. Таким образом, в этом случае HBase является лучшим вложением [74].
Уровень доступа к данным
В этом разделе описывается уровень доступа к данным, процесс приема данных и процесс управления хранилищем.
Apache Sqoop при приеме данных
Apache scoop включает интерфейс командной строки (CLI), который гарантирует эффективный обмен массовыми данными между Apache Hadoop и организованными хранилищами данных (такими как наборы социальных данных, центры распространения информации об усилиях и наборы данных NoSQL). Sqoop предлагает множество преимуществ, таких как быстрое выполнение, адаптация к внутренним сбоям и идеальное использование фреймворка для уменьшения накладных расходов на вычисления для внешних фреймворков. Импортированная информация изменяется с помощью MapReduce или другого языка важного уровня, такого как Hive, Pig Pig и JAQL. Он обеспечивает простое согласование с HBase, Hive и Oozie. В тот момент, когда Sqoop импортирует информацию из HDFS, доход предоставляется в разных документах. Эти записи могут быть документами содержимого с разделителями, параллельными Avro или SequenceFiles, содержащими сериализованную информацию. Взаимодействие Sqoop Export просматривает множество документов с разделителями из HDFS в одном месте, анализирует их в записи и дополняет их новыми строками в наборе объективных данных.
Flume в приеме данных
Flume имеет базовую адаптируемую конструкцию и управляет потоком информационных потоков. Flume опирается на базовую расширяемую информационную модель для работы с огромными выделенными источниками информации и предлагает различные компоненты, включая адаптацию к внутреннему сбою, настраиваемую систему надежности и управление восстановлением после сбоев. Однако Flume хорошо дополняет Hadoop; свободный сегмент может откалываться на разных этапах. Это необходимо для его способности запускать разные циклы на одной машине. Используя Flume, клиенты могут передавать информацию из различных источников большого объема для текущего расследования. Более того, Flume дает запрос, подготавливающий двигатель, который может менять каждый новый информационный пакет до того, как он будет направлен на заданный приемник.
Chukwa при приеме данных
Это информационный фреймворк, основанный на высшей точке Hadoop. Chukwa, вероятно, просматривает огромное количество распределенных фреймворков и использует HDFS для сбора информации от разных поставщиков информации, а также MapReduce для анализа собранной информации. Он приобретает адаптируемость и жизнеспособность Hadoop и устанавливает интерфейс для отображения экрана и анализа результатов. Chukwa предоставляет адаптируемую и удивительную платформу для больших данных, которая позволяет исследователям собирать и анализировать большие наборы данных только для просмотра и отображения результатов. Chukwa организован как ассортиментный конвейер, чтобы гарантировать адаптивность, подготавливая этапы так же, как и связь между этапами. Структура зависит от четырех основных сегментов: во-первых, она зависит от специалистов по информации на каждой машине для передачи информации. Затем власти используются для сбора информации от специалистов и составления ее постоянного запаса. Занятия MapReduce используются для анализа и хранения информации. Клиенты могут полагаться на удобный интерфейс (HICC) для отображения результатов и информации. Он имеет стиль онлайн-интерфейса.
Storm и spark storm
Это непатентованная рассредоточенная структура, которая обеспечивает непрерывную обработку информации, в отличие от Hadoop, предназначенного для кластерных вычислений. В отличие от фреймворка flume, storm демонстрирует более высокую производительность при выполнении сложных предварительных вычислений в зависимости от Trident API. Strom зависит от топологии сети, состоящей из общей организации потоков, болтов и носиков. Носик — это собрание потоков, а болт обрабатывает входные потоки для создания выходных потоков. Отныне шторм подходит для изменения потока с помощью «носиков» и «болтов». Интерфейс ISpout шторма может поддерживать любую поступающую информацию. Действительно, используя Storm, клиенты могут получать информацию из различных постоянно скоординированных и нестандартных сред. С помощью Bolts Storm позволяет создавать данные для любой платформы доходности. Storms предоставляет вложение IBolt, которое поддерживает любую структуру доходности, такую как JDBC (для хранения информации в любом наборе социальных данных), файлы последовательности, сегменты Hadoop, такие как HDFS, HBase и другие информационные среды. Группа tempest и группа Hadoop сопоставимы.
Тем не менее, в Storm можно запускать различные географические регионы для различных сбоев шторма. Тем не менее, на этапе Hadoop единственная альтернатива включает выполнение задач Map-Reduce для соответствующих приложений. Одно фундаментальное различие между оккупациями MapReduce и топологиями заключается в том, что когда MapReduce перестает работать, топология продолжает вычислять сообщения либо постоянно, либо до завершения работы клиента. Storm — это простая в использовании, быстрая, адаптируемая и гибкая структура; если хотя бы один цикл закончится, Storm перезапустит его. Шторм изменит маршрут, если цикл провалится более одного раза. Его можно использовать в некоторых случаях, таких как текущее обследование, онлайн-ИИ, постоянные вычисления и соответствующий RPC. Шторм используется для планирования результатов, которые затем могут быть разбиты на другие устройства Hadoop. Он может обрабатывать миллионы кортежей каждую секунду. Storm предлагает улучшенную модель программирования, такую как MapReduce, которая скрывает сложность создания передаваемых приложений. Flash похож на Hadoop, но для дальнейшего развития выполнения он зависит от среды в памяти. Это воспринимаемый этап исследования, который гарантирует быструю, простую и адаптируемую обработку. Flash справляется со сложными исследованиями огромных коллекций информации. Конечно, Spark запускает программы до 100 xs быстрее, чем Hive и Apache Hadoop, через инфраструктуру MapReduce в памяти. Sparkle зависит от кодовой базы Apache Hive. Для дальнейшего развития выполнения фреймворка Spark уступила фактический исполнительный двигатель Hive.
Кроме того, Spark предлагает API-интерфейсы, помогающие быстро продвигать приложения на разных диалектах, включая Java, Python и Scala. Sparkle может работать со всеми платформами хранения документов, поддерживаемыми Hadoop. Информационная модель Sparkle зависит от решения Resilient Distributed Dataset (RDD). RDD создают доступный для чтения набор элементов, хранящихся в памяти фреймворка на разных машинах. Доступ к таким элементам не требуется.
Более того, их можно воссоздать в случае утери посылки. Проект Spark включает в себя различные части для планирования задач, памяти на плате, восстановления дефицита и взаимодействия с инфраструктурами емкости. Партии записываются следующим образом:
Spark SQL
Одним из важных компонентов Spark SQL является то, что он сочетает в себе две функции: социальные таблицы и RDD. Таким образом, разработчики могут принимать данные без особых усилий и смешивать SQL-запросы, чтобы подвергать сомнению внешние информационные наборы со сложным исследованием. Надежно, клиенты могут задавать вопросы как по импортированной информации из внешних источников, так и по информации, хранящейся в существующих RDD. Более того, Spark SQL позволяет работать с RDD или документами Parquet. По этой причине он работает с быстрой одинаковой обработкой информационных вопросов по огромным распространяемым информационным коллекциям. Он использует диалекты запросов, называемые HiveQL. Для быстрого продвижения приложений Spark внедрил систему Catalyst, которая позволяет клиентам через Spark SQL быстро добавлять новые улучшения.
Spark streaming
Искровой поток — это дополнительная часть, которая обеспечивает запрограммированную сравнимую, адаптируемую и беспристрастную потоковую обработку. Он позволяет клиентам выполнять задания в потоковом режиме, составляя похожие на группы циклы в Scala и Java. Можно включить кучу профессий и интеллектуальных вопросов. Он реализует каждое вычисление потока как последовательность коротких групповых операций над памятной информацией, хранящейся в RDD.
MLlib
MLlib — это передаточная система искусственного интеллекта, основанная на Spark. MLlib предоставляет различные обновленные вычисления ИИ для выполнения, такие как группировка, рецидив, группировка и совместное разделение. Как и MLlib и Mahout, MLlib полезен для классификации ИИ. Они предлагают оценки для отображения темы и последовательного извлечения примеров. MLlib поддерживает дополнительные модели рецидивов. Как бы то ни было, Mahout не помогает с такой структурой. MLlib в целом моложе, чем Mahout.
GraphX
GraphX содержит библиотеку для управления диаграммами и выполнения вычислений, эквивалентных диаграммам. Подобно Spark SQL, GraphX и Spark, потоки расширяют элементы Spark. Следовательно, клиенты могут составить согласованную диаграмму с уверенными активами, присоединенными к каждому ребру и вершине. GraphX предлагает различных администраторов, которые помогают управлять диаграммами. Он также предоставляет библиотеку расчетов диаграмм (подсчет треугольников).
Администрирование хранилища
HCatalog apache
HCatalog предоставляет администрирование таблицы и платы репозитория для клиентов Hadoop, что расширяет возможности взаимодействия между устройствами обработки информации. HCatalog выполняет это с помощью общего шаблона и инструментов типа информации, которые предоставляют интерфейс для улучшения действий по просмотру и составлению информации для любого информационного дизайна, для которого может быть составлен Hive SerDe (сериализатор-десериализатор). Администрирование платформы передает SerDe, OutputFormat и InputFormat. Независимая таблица HCatalog дает социальный взгляд на информацию в HDFS и позволяет нам видеть разнородные информационные структуры в равномерном расположении. Поэтому от клиентов не требуется знать место или способ хранения информации. Кроме того, HCatalog поддерживает клиентов с различными администрациями и сообщает о доступе к информации, что дает интерфейс REST для доступа к задачам языка определения данных Hive (DDL). Кроме того, он предоставляет службы предупреждения, которые сообщают устройствам рабочего процесса (таким как Oozie), когда на складе появляется новая информация [74].
Обзор и анализ технологий больших данных
В этом разделе рассматриваются и анализируются 37 статей, посвященных технологиям больших данных. На основе этих статей в этом разделе рассматривается применение больших данных в различных областях. Большие данные применяются практически во всех областях, таких как умные города, сетевые коммуникации, управление бизнесом, умный дом, транспорт, анализ настроений, поддержка принятия решений или сбор мнений, умный дом, конфиденциальность, здравоохранение, промышленное применение и сельское хозяйство. Приложение больших данных использует различные методы, такие как машинное обучение, глубокое обучение, методы облачных вычислений, методы граничных вычислений, концентрические вычисления и Интернет вещей. Краткое описание применения больших данных представлено ниже. На рис. 1 схематично представлено приложение для работы с большими данными. В этом разделе кратко анализируются некоторые из существующих статей, связанных с приложениями для работы с большими данными, с их методами, преимуществами и недостатками.
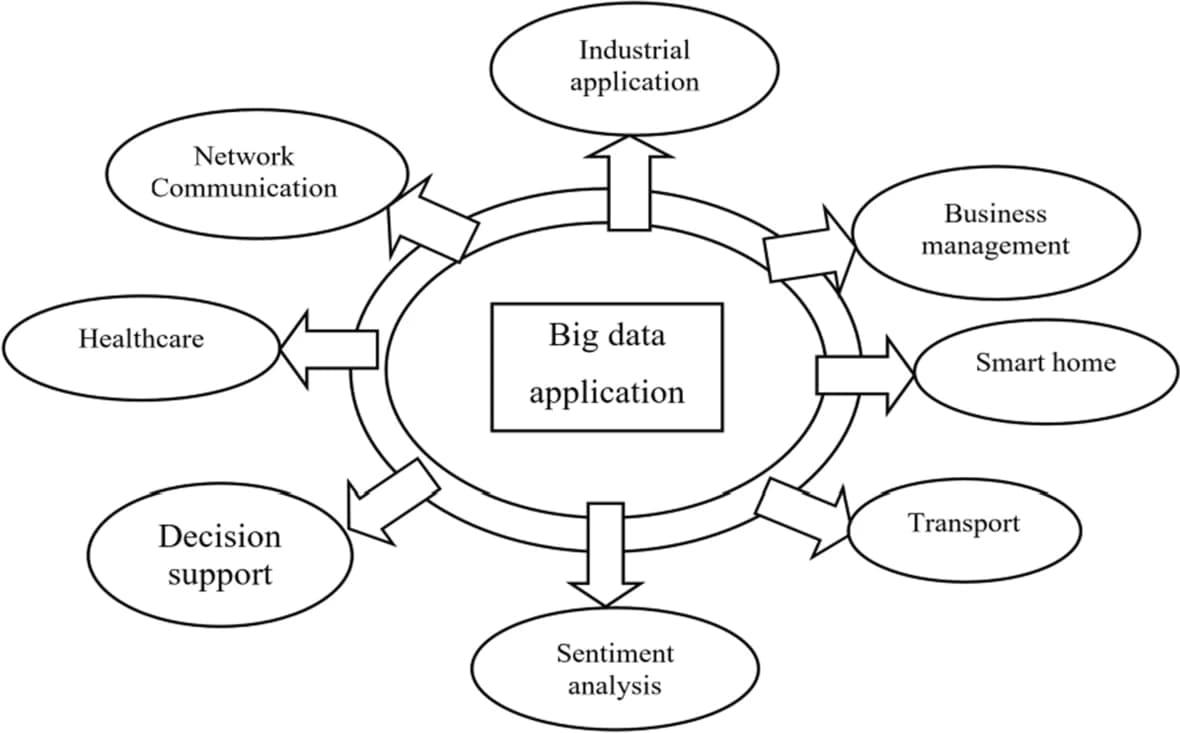
Рис.1. Приложения для работы с большими данными
Обзор на основе приложений для работы с большими данными
Этот раздел иллюстрирует обзор применения больших данных в различных областях. Использование больших данных распространено почти во всех отраслях, таких как умные города, сетевые коммуникации, управление бизнесом, умный дом, транспорт, анализ настроений, поддержка принятия решений или сбор мнений, умный дом, конфиденциальность, здравоохранение, промышленное применение и сельское хозяйство. . Краткое описание применения больших данных проиллюстрировано ниже. На рис. 1 схематично представлено приложение для работы с большими данными.
Методы машинного обучения
Кибрия и др. [52] предложили передовые удаленные организации, ориентированные на информацию, где администраторы организации используют прогрессивные подходы к исследованию информации, искусственному интеллекту и машинному обучению. Этот метод оценивает источники информации и надежные движущие силы для создания анализа информации и работы ML, искусственного сознания в создании умной структуры в отношении действий естественно осознанных, самостоятельных, инициативных и предписывающих. В отношении проверки информации было введено несколько организационных планов и планов оптимизации.
Рагиния и др. [58] представили огромную информационную методологию и описали различные этапы, связанные с порядком оценки. Основное обязательство — это точечное исследование стратегии обучения и организации, чтобы упорядочить потребности людей в часы катастрофы. Изучить предположения о различных потребностях людей, на которые повлияло фиаско, и предложить технику представления мнения. Сочетание абстрактного выражения и алгоритма ИИ обеспечивает лучшую точность группировки информации о бедствии. Большое информационное исследование также анализирует различные трудности, связанные с использованием Twitter для реагирования на бедствия и восстановления сил. Из тщательного изучения ясно, что словарный запас, доступный для изучения текста, должен быть расширен для размещения информации, связанной с катастрофой. Точно так же построение метафизики для информации о чрезвычайных ситуациях может помочь сгруппировать потребности людей во время бедствия.
Методы глубокого обучения
Раут и др. [53] представили гибридное моделирование структурных уравнений, основанное на модели ANN, используемой для оценки 316 реакций индийских специалистов-экспертов. Результаты анализа факторов показывают, что стиль администрирования и инициативы, государственная и правительственная стратегия, интеграция поставщиков, внутренний бизнес-цикл и интеграция клиентов влияют на изучение огромного количества информации и репетиции поддержки. Кроме того, результаты продемонстрированных основных условий были включены в модель организации искусственной нейронной сети. Открытия расследования показывают, что администрация и власть формируют стратегию государства и местного самоуправления как два наиболее важных индикатора изучения огромного количества информации и репетиций управляемости. Результаты дают единственные в своем роде знания о сборочных фирмах для дальнейшего развития их поддерживаемого ведения бизнеса с точки зрения руководителя задачи.
Облачные вычисления
Лу и Сюй [54] представили обычную структуру для облачной сборки оборудования для сред цифрового производства. Предоставляется обширный информационный обзор, позволяющий связать производство оборудования с облаком и сделать его доступным для организации управления производством по запросу. Отраслевое исполнение мирового поставщика оборудования для управления автомобилем подтверждает, что представленная структура платформы для облачной сборки оборудования может эффективно расширять возможности производственных систем по запросу, предоставляемых через Интернет, и может быть расширена для организаций, которые планируют преобразовать системы создания наследства в облачные цифровые платформы.
Ясин и др. [61] представили сцену для исследования огромной информации интеллектуального домашнего IoT с помощью громких и распределенных вычислений. Этот метод обеспечивает предварительную оценку и представление сегментов сцены и устанавливает путь к воспроизведению оценки в туманном узле. Результаты показывают потенциальное использование фреймворка с разных точек зрения. Например, использование полученной информации может включать в себя подтверждение движения, чтобы распознавать заболевания, различать примеры использования энергии и меры по энергосбережению, а также гарантировать выполнение задач в соответствии с точки зрения использования энергии.
Шорфуззаман и др. [62] разработали интеллектуальную облачную систему обработки, которая может успешно анализировать огромную информацию разносторонних студентов и постоянно предлагать эту информацию для работы с убедительной динамикой в передовых образовательных организациях. Зависимая от облака структура превосходит ограниченную пропускную способность мобильных телефонов, перенося некоторые здоровенные вычислительные части в облако, которое может предоставить достаточные ресурсы для вычислений и мощности. В частности, этот метод фокусируется на конкретном использовании огромных процедур исследования информации в универсальной структуре обучения для работы с выбором плана. В заключение, этот метод решает проблему подготовки студентов к разностороннему обучению в высших учебных заведениях, исследуя переменные, побуждающие принять эту возникающую инновацию, используя расширенную предполагаемую модель признания инновации.
Раджесвари и др. [73] предложили усовершенствованную модель для сельскохозяйственного сектора, основанную на методах облачных вычислений, чтобы предвидеть урожайность и выбирать лучшую последовательность сбора урожая в зависимости от прошлого расположения урожая на аналогичных сельскохозяйственных угодьях с текущими данными, дополняющими грязь. Постоянно исследуя почву, владелец ранчо захочет получать компост, необходимый для урожая. Это основная предпосылка для сельскохозяйственных угодий в Индии, чтобы получить более развитое производство урожая с уменьшением затрат на навоз, сохраняя почву безупречной. Поскольку информация о тонкостях выращивания и состоянии почвы собирается в течение многих лет, эта модель исследует большие данные, чтобы найти наилучшую схему редактирования, определить следующий урожай, который необходимо разработать для лучшего создания, чтобы завершить создание урожая в пространстве дохода, чтобы определить общие потребности в компосте и узнать другую информацию о премии.
Туманные вычисления
Дарвиш и др. [63] представили план своевременного исследования огромной информации ITS в среде IoV. Дизайн сочетает в себе три измерения: интеллектуальную обработку (например, обработку облаков и тумана), непрерывное исследование огромных объемов информации и измерение IoV. Кроме того, это исследование дает исчерпывающее представление о природе IoV, огромных информационных качествах ITS, лямбда-инженерии для непрерывного изучения огромных объемов информации и нескольких умных достижениях в расчетах. Тем более важно, что это исследование исследует шансы и трудности, с которыми сталкивается выполнение обработки тумана и непрерывное исследование огромных объемов информации в IoV.
Пограничные вычисления
Гарг и др. [66] представили высокоуровневый метод соответствия транспортных средств, в котором RSU восстанавливаются на этапах регистрации границ. Затем, в этот момент, планируется безопасное переписывание V2V и V2E с использованием канала Quotient, вероятностной информационной структуры. Вкратце, интеллектуальная система безопасности для автомобильных одноранговых сетей (VANET), оснащенная периферийными узлами регистрации и инновациями 5G, была разработана для повышения возможностей переписки и вычислений в передовых средах умного города. Экспериментальные результаты показывают, что модель превосходит обычные модели транспортных средств, предоставляя энергоэффективную безопасную структуру с наименьшей задержкой.
Опрос по приложению больших данных, зависящему от приложения «умный город», приведен ниже. Шахат Осман [51] представил трехуровневую структуру, известную как Панель анализа данных Smart City (SCDAP) для приложения Smart City. Фреймворк состоит из трех уровней: вычисление данных, безопасность и платформа. При установлении многоуровневого рамочного подхода доступ к нормализованной информации, расширение возможностей как текущего, так и проверяемого исследования информации, поддержка как итеративной, так и последовательной подготовки информации, а также универсальность являются стандартами плана, которым обычно следуют. Кроме того, на уровне уровней адаптируемые этапы, облачные среды, интеллектуальный анализ информации, искусственный интеллект, наборы данных в памяти и восприятие информации являются инновациями, расширяющими возможности. С другой стороны, две дополнительные возможности структур исследования для блестящих городских сообществ, а именно: управление моделью и накопление модели, являются фундаментальным обязательством модели. SCDAP представляет новые функциональные возможности для больших информационных систем для приложений умного города. Основной компонент этой разработки ограничен пакетом Apache Hadoop в качестве хранилища фундаментальной информации и уровня руководителей. Разделение между функциями SCDAP и базовым накоплением информации и уровнем платы улучшает согласованность SCDAP и его способность управлять множеством различных этапов.
Рехман и др. [68] представили эффективную систему распределения Concentric Computing Model (CCM) для приложения BDA для работы над функциональной производительностью и выполнением приложений в средах, зависящих от IIoT. В этой модели представлены выставочные и корреспонденционные направления, которые можно выполнить, приняв участие в CCM в IIoT.
Интернет вещей
Аль-Али и др. [55] представили систему управления энергопотреблением (EMS) для домашних приложений «умный дом». В этой структуре каждый домашний гаджет взаимодействует с модулем защиты информации, который представляет собой объект IoT с интересным IP-адресом, что приводит к удаленной организации устройства с огромным сечением. Модуль получения информации System on Chip (SoC) собирает информацию об использовании энергии с каждого умного домашнего гаджета. Он передает информацию единому работнику для дополнительной обработки и проверки. Эти данные со всех локальных мест собираются дистрибьюторами утилиты как большие данные [55].
Ратор и др. [59] предложил основу для умного цифрового города, в котором используются устройства IoT для сбора информации о городе и исследования больших данных для получения информации. Усовершенствованная модель проектирования и реализации цифрового города используется для создания структуры, которая может обрабатывать огромное количество информации о городе и давать указания столичным специалистам, чтобы сделать их регионы более интеллектуальными и компьютеризированными. Выполнение фреймворка включает в себя различные усовершенствования, в том числе информационный возраст и сортировку, накопление, фильтрацию, размещение, предварительную обработку, обработку и динамику. Собранная информация со всех интеллектуальных платформ постоянно обрабатывается для создания интеллектуального города с использованием Hadoop, работающего под управлением Apache Spark. Существующие наборы данных, созданные умными домами, продуманной парковкой, климатическими системами, датчиками проверки загрязнения и сетью транспортных средств, используются для исследования и тестирования. Все наборы данных воспроизводятся вместе с реальным исполнением транспортной организации, чтобы получать постоянную информацию для тестирования системы. Этот метод пытался решить большую часть проблем, с которыми сталкивается обычный житель, а также давал возможность государственным органам постоянно принимать разумные решения. Кроме того, модель помогает сдерживать запросы и проблемы, создаваемые жителями. STB использовала диаграммный подход, реализованный с использованием огромных устройств обработки диаграмм. Результаты показывают, что структура более продуктивна, универсальна и подходит для работы в постоянном климате.
Аналитика больших данных
Амини и др. [57] представил полный и адаптируемый дизайн для текущих светофоров, зависящих от исследования больших данных. Рамки зависят от методического изучения потребностей региона. Структура была воплощена в модели сцены с использованием Кафки и использовалась в работе круга контроля критики, чтобы открыть или закрыть обочину дороги. Принципиальным ограничением следствия было отсутствие доступа к достоверным сведениям.
Ячирема и др. [64] представили структуру, основанную на трехуровневой архитектуре, для помощи в непрерывном наблюдении за синдромом обструктивного апноэ сна (СОАС) у пожилых людей, а также руководство по их лечению. Платформа выполняется с использованием разнородного и ненавязчивого устройства, соглашений IoT, сегментов стандартных этапов, маломощных инноваций, огромных информационных технологий, а также подходов к туманной и облачной регистрации. Проведено использование обработки информации кластера инструментов больших данных на облачном уровне. Он может разыграть графическое исследование, которое в значительной степени утончает поведение информации от интеллектуальной двери IoT и предвидит наиболее неструктурированную область, зависящую от информации о токсине, доступную в умных городских сообществах, для постановки диагноза OSA. Исследуемая информация передается сотруднику, который отображает данные в веб-интерфейсе индийского университета IU, поэтому специалисты медицинских служб, занимающиеся рассмотрением пожилых людей, могут без особого труда получить доступ из любого места, в любое время и с любого устройства.
Гохар и др. [65] продемонстрировали стратегию оценки больших данных для ИТС, которая умело анализирует и хранит информацию ИТС и помогает городским организациям сделать лучший выбор в зависимости от вида доступных представлений. Стратегия имеет базовую способность накопления и исследования для работы с информацией ITS и состоит из четырех модулей: (1) Группа сбора и предварительной обработки больших данных, (2) Группа обработки больших данных, (3) Группа анализа больших данных и ( 4) Блок визуализации данных. Этот метод оценивается с использованием Hadoop, после чего утверждается подтверждение идеи.
Ван и др. [71] представили модель рамочного уровня для оценки надежности в энергетическом Интернете по базовой энергоемкости для исследования области малой агравационной прочности (SDSR), где SDSR можно получить путем оценки функционального информационного края соответствующих возрастов (DG). Преимущество оценивается на основе использования энергии, а не узлов баланса, которые используют гипотезу работы энергии и уменьшают сложность вычислений. Кроме того, огромная информация, добавленная в модель, приближает оценочный расчет к подгонке гиперплоскости для продвижения и разрушения SDSR.
Миа и др. [58] представили стратегию удаления, ранжирования, распознавания и выделения важных данных о путешественниках из неструктурированных огромных информационных индексов для поддержки динамического принятия решений в варианте миграции базы данных (DMO). Изучая фотографии с геотегами и другие связанные тонкости, наша стратегия отвечает различным возражениям и дает ценные результаты, как показано на примере Мельбурна, Австралия. Этот метод следовал гипотезе установки и методологическим правилам запроса субъекта данных (DSR) для планирования, продвижения и распространения генерируемого шума.
Технологии Hadoop
Бабар и др. [69] представили зависимый от Hadoop дизайн для управления накоплением и подготовкой больших данных, а административный дизайн состоит из двух отдельных модулей. Демонстрация и мастерство укладки информации проверяются для разработки отлаженной методологии укладки больших данных на стадии передачи и подготовки. Стекирование информации выполняется и многократно сравнивается с различными вариантами анализа приема информации в Hadoop. Экспериментальные результаты записываются для различных характеристик наряду с ручным и обычным набором информации, чтобы показать профессионализм организации. С другой стороны, управление осуществляется с помощью системы YARN связки с явной настройкой динамического планирования. Кроме того, пригодность метода с точки зрения планирования и вычислений подчеркивается и подчеркивается с точки зрения пропускной способности.
Другие методы
Чанг [72] предложил модель платформы анализа социальных сетей (SNAP), которая демонстрирует, как извлекать информацию из Facebook в рамках установленного API социальной сети, который оценивает большие данные корреспондентской сети. Разработано описание организации, а также методы анализа и представления информации. Шесть элементов API социальных сетей можно использовать для анализа информации, объясняющей связь между различными организациями. Они могут показать, что SNAP можно использовать в качестве этапа управления взаимоотношениями с клиентами (CRM), планирования ресурсов предприятия (ERP) и вероятностной информационной системы управления (MIS) для разделения данных организаций и проведения тщательного исследования каждого мыслимого обстоятельства. Кроме того, шесть элементов API социальных сетей были широко опробованы с масштабными реконструкциями. Результаты подтверждают универсальность нашего предложения SNAP, цель которого заключается в том, чтобы администрация могла быть запущена и работать при наличии 50 000 одновременных клиентов или запросов, что может дополнительно проверить скорость и точность неофициального исследования больших данных сообществом.
Анализ и обсуждение
Этот раздел иллюстрирует оценку и обсуждение методов, показателей и инструментов, используемых в исследовательских работах. Результаты анализа указывают на важность количества стратегий реализации на основе больших данных.
Анализ на основе используемых методик
Таблица 1 иллюстрирует анализ исследовательских работ с точки зрения методов, используемых в приложениях для работы с большими данными. В обзорных документах обычно использовались базы данных, такие как машинное обучение, глубокое обучение, облачные вычисления и методы анализа больших данных.
Таблица 1. Анализ на основе используемых методов
| Техники | Документы |
|---|---|
| Машинное обучение | [29, 52, 60, 67] |
| Глубокое обучение | [53, 67] |
| Облачные вычисления | [54, 61, 62, 73] |
| Туман вычисления | [61, 63] |
| Интернет вещей | [55, 59] |
| Аналитика больших данных | [29, 55,56,57,58,59,60, 65, 71] |
| Пограничные вычисления | [66] |
| Концентрические вычисления | [51, 68] |
| Hadoop | [69] |
| Другие методы | [51, 70, 72] |
Аналитика больших данных является широко используемым методом среди различных приложений. Из 25 статей в 9 используется BDA, в 4 — методы машинного обучения, в 4 — облачные вычисления, а в 1 — инфраструктура Hadoop. На рис. 2 представлена диаграмма, основанная на анализе методик.
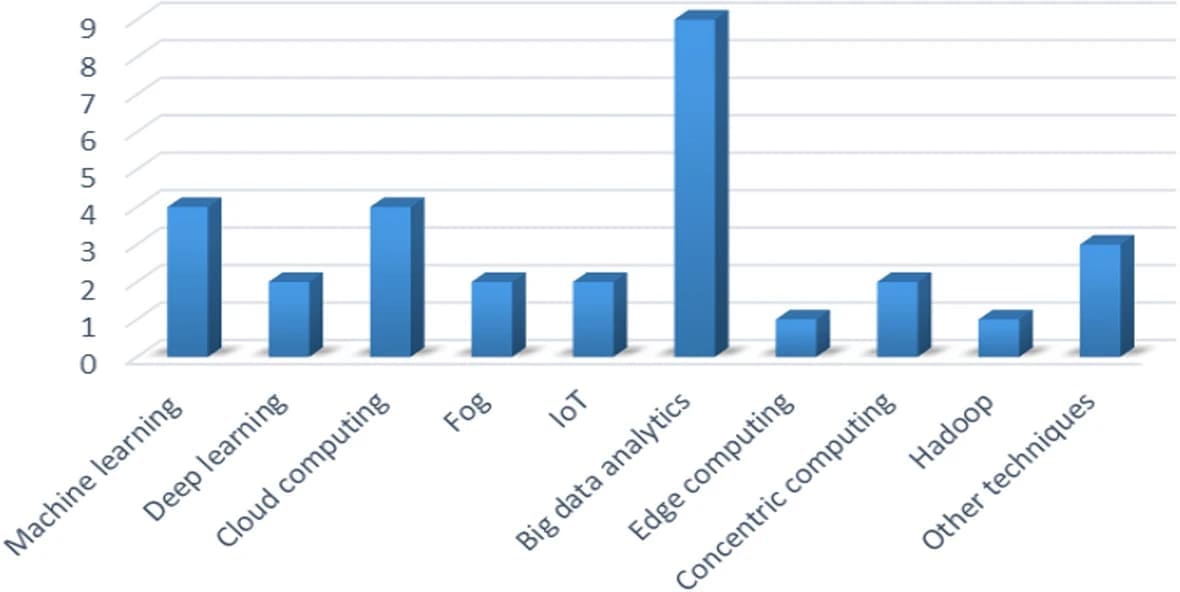
Рис.2. Диаграмма, основанная на методах, используемых в приложениях для работы с большими данными
Анализ по годам публикации и журналам
Большинство статей были опубликованы в 2018, 2019 и 2020 годах. Детали журнальных публикаций перечислены на рис. 4. Большинство статей публикуются в стандартных журналах и ниже текущих лет.
Рис.3. Диаграмма на основе журнальных публикаций
Проблемы, связанные с приложениями для работы с большими данными
- большинство систем анализа больших данных ограничено пакетом Apache Hadoop. Следовательно, разделение уровня хранения данных и уровня управления является проблемой. Разделение между упомянутыми слоями повысит функциональность приложения для работы с большими данными;
- баланс распределенной и централизованной функциональности является основной проблемой, возникающей в приложении для работы с большими данными, основанном на глубоком обучении [49].
Будущее направление
- требуется ансамблевый алгоритм для эффективной классификации хранилища и уровня управления;
- функция экспорта или импорта должна быть включена для увеличения функциональности системы;
- нам необходимо разработать метод динамических граничных вычислений, чтобы установить баланс между централизованной и распределенной функциональностью.
Аналитика больших данных: проблемы и вызовы
- Большие данные сталкиваются с различными трудностями в управлении организацией [12, 15, 16, 33]. Фреймворк, работающий с большими данными, должен учитывать потребность в инновациях и требования клиента. Справляться с трудностями, создаваемыми большими данными, проблематично, а объем информации, увеличивающейся с каждым днем, скорость ее возраста увеличивается быстрее, чем когда-либо в недавней памяти; Ассортимент информации также растет. Текущие инструменты, достижения, инженерия, руководители и подходы к исследованию не могут справиться со сложностью вводимой информации.
- Защита, безопасность и доверие: организация, использующая большие данные, полна решимости обеспечить защиту и безопасность своих клиентов и должна гарантировать, что ассоциация должна согласовать все демонстрации, связанные с защитой и безопасностью, чтобы улучшить установленные четкие точки остановки для использования индивидуальные данные [22]. Доверие к ассоциации должно возрастать с увеличением объема информации. Доверие клиентов к этим организациям и их способность безопасно хранить личные данные, несомненно, могут зависеть от утечки информации или данных в публичное пространство.
- Управление информацией и обмен ею: агентства понимают, что для того, чтобы информация имела какую-либо ценность, она должна быть доступной для обнаружения, открытой и пригодной для использования. Организации должны выполнять эти требования, но при этом строго соблюдать законы о безопасности. Последние достижения в области открытой информации сделали упор на то, чтобы сделать наборы данных доступными для общества в целом. Офисы должны сосредоточить внимание на том, чтобы сделать информацию доступной, открытой и стандартизированной внутри и между организациями, чтобы это позволяло офисам использовать и объединяться в той степени, в которой это возможно в соответствии с законами о защите.
- Инновации и аналитические способности: аналитика больших данных придает большое значение поставщикам информационных и коммуникационных технологий (ИКТ) для разработки новых устройств и инноваций для обработки сложной информации. Нынешние инструменты и инновации не могут хранить, измерять и разбивать огромные объемы разнородной информации. Продавцы и разработчики инфраструктур и механизмов больших данных, включая программирование с открытым исходным кодом, становятся все более компетентными в преодолении трудностей, связанных с анализом больших данных.
- Хранение и извлечение информации: в настоящее время доступные разработки могут работать с информационными секциями и накоплением информации. Однако аппараты, предназначенные для процесса обмена, могут искать небольшое количество данных, а не огромный массив информации. Наиболее эффективный метод обработки полу- или неструктурированной информации пока неясен [2].
- Информационный рост и расширение: ожидается, что по мере того, как ассоциации будут создавать свои администрации, их информация будет развиваться. Ассоциация считает информационное развитие за счет информации, наполненной щедростью, и информации, продвинутой с новыми стратегиями [2].
- Скорость и масштаб: трудно преобразовать знания в информацию в период, когда объем данных увеличивается. Приобретение знаний об информации имеет более высокий приоритет, чем обработка всей информации. Вычисления информации, близкой к непрерывной, постоянно требуют предварительной подготовки для получения приемлемых результатов [2].
- Организованная и неструктурированная информация: переход между организованной информацией, хранящейся в четких таблицах, и неструктурированной информацией (изображения, записи, текст), необходимой для изучения, будет влиять на подготовку информации от начала до конца. Информационное изображение и вычисления станут более адаптируемыми с развитием новых не относительных инноваций [2].
- Информационное владение: очень большое количество информации находится у сотрудников организаций, специализирующихся на сетевых СМИ. Они не владеют этой информацией; однако они хранят информацию о своих клиентах. Подлинный владелец страницы сделал страницу или запись. Право собственности на информацию становится все более серьезной проблемой в онлайн-медиапространстве [2, 18].
- Перекос данных: в наборе данных неравномерное распределение данных называется перекосом данных, что допустимо только в архитектуре параллельной обработки, где происходит распределенная обработка данных. Важность распределенной обработки данных заключается в том, что вместо выполнения задания одним процессором, если это задание разделить на несколько параллельных более мелких заданий, обрабатываемых разными процессорами, то задание в целом выполняется быстрее. Это сокращает время выполнения и повышает производительность [90].
- Разнообразие данных: одним из ключевых компонентов больших данных является разнообразие данных. Объединение данных из нескольких источников и их рассредоточение различными способами приводит к разнообразию данных. Использование ресурсов обработки, таких как использование ЦП, сильно различается из-за этого аспекта больших данных. DVFS — это метод, используемый для уменьшения проблем и потребления энергии ЦП [91].
- Ограниченные ресурсы: граничные вычисления — это парадигма распределенных вычислений, которая приближает вычисления и хранение данных к источникам данных. Ожидается, что это улучшит время отклика и сэкономит пропускную способность [92].
- Edge Data Processing: аппроксимационные подходы к большим данным могут быть полезны для приложений, которые проверяют входящие данные, журналы и запросы для получения агрегированных результатов или информационных панелей. Эти приложения используют больше всего энергии, денег и времени, потому что выход значительно меньше, чем вход [93].
- Потребление энергии: центры обработки данных различаются по эффективности, при этом значительная часть мощности, подаваемой в центр обработки данных, может использоваться для охлаждения и других вспомогательных функций, а не для ИТ-оборудования. Коэффициенты использования должны быть высокими в центрах обработки данных, где можно планировать работу. Поддержание высокого уровня использования в других областях более проблематично, если только спрос не является очень предсказуемым [94].
Сравнение с существующим методом обследования
Уссус и др. [86] проводят обзор последних технологий, используемых в аналитике больших данных, что помогает выбрать подходящие технологии для удовлетворения технических требований и применения. Опрос обеспечивает сравнение между различными уровнями хранения, такими как уровень управления, уровень запроса данных, уровень обработки данных, уровень управления и уровень доступа к данным. Он содержит краткое описание преимуществ, ограничений и технологических особенностей больших данных. В этой обзорной статье объясняется значение и таксономия больших данных. В статье также объясняются инструменты, используемые для обработки больших данных. Кроме того, документ включает анализ, основанный на используемых методах, годе публикации и показателях эффективности, что повышает ценность нашей обзорной статьи по сравнению с существующими исследованиями.
Чен и др. [87] дают краткий обзор проблем больших данных с современными технологиями, методами и возможностями. Обзорная статья содержит описание квантовых вычислений, облачных вычислений и биологических вычислений. Однако в этой статье не анализируются текущие инструменты, используемые в технологиях больших данных, такие как storm, spark и Hive. В нашей обзорной статье анализируются новейшие инструменты с их достоинствами и недостатками. Кроме того, в нашей статье дается краткое описание экосистемы Hadoop.
Вывод
В этой статье обсуждаются термины, приложения и технологии для работы с большими данными, а также перечисляются проблемы, связанные с приложениями для работы с большими данными. Этот обзор объясняет значение больших данных, их таксономию и детализирует основные термины, используемые в больших данных. Кроме того, в обзоре описываются технологии, используемые в приложениях для работы с большими данными, а также различные сложности и проблемы, связанные с большими данными. В статье основное внимание уделяется различным методам, представленным в литературе, для ограничения проблем, связанных с большими данными. Методы больших данных анализируются по нескольким факторам, включая год публикации, показатели производительности, достижения существующей модели и используемые методы.
Кроме того, в данной научной статье представлена оценка методов с точки зрения их преимуществ и недостатков. Затем в этом обзорном документе обсуждаются возможности и приложения для работы с большими данными, а также приводится подробный обзор сред обработки больших данных, таких как Hadoop, MapReduce и Spark. Наконец, в статье описывается будущее направление исследований. Таким образом, обзор обобщает предысторию больших данных, их терминологию, методы и приложения и фокусируется на правильном направлении дальнейших исследований. Однако наша исследовательская статья не дает глубокого понимания таких методов, как глубокое обучение, машинное обучение и визуализация данных, которые будут рассмотрены в будущих исследованиях.
Использованная литература
- Wei J, Chen M, Wang L, Ren P, Lei Y, Qu Y, Jiang Q, Dong X, Wu W, Wang Q, Zhang K. Status, challenges and trends of data-intensive supercomputing. CCF Transactions on High Performance Computing. 2022. 1–20.
- Zakir J, Seymour T, Berg K. Big data analytics. Issues Inf Syst. 2015;16:2.
- Margara A. A unifying model for distributed data-intensive systems. In Proceedings of the 16th ACM International Conference on Distributed and Event-Based Systems. 2022. p. 176–179.
- Hu H, Wen Y, Chua TS, Li X. Toward scalable systems for big data analytics: a technology tutorial. IEEE Access. 2014;2:652–87.
- Fisher D, DeLine R, Czerwinski M, Drucker S. Interactions with big data analytics. Interactions. 2012;19(3):50–9.
- Silva BN, Diyan M, Han K. Big data analytics. In: Khan M, Jan B, Farman H, editors. Deep learning: convergence to big data analytics. Singapore: Springer Singapore; 2019. p. 13–30.
- Vassakis K, Petrakis E, Kopanakis I. Big data analytics: applications, prospects and challenges. In: Skourletopoulos G, Mastorakis G, Mavromoustakis CX, Dobre C, Pallis E, editors. Mobile big data. Cham: Springer International Publishing; 2018. p. 3–20.
- Kwon O, Lee N, Shin B. Data quality management, data usage experience and acquisition intention of big data analytics. Int J Inf Manage. 2014;34(3):387–94.
- Elgendy N, Elragal A. Big data analytics in support of the decision making process. Procedia Comput Sci. 2016;100:1071–84.
- Gandomi A, Haider M. Beyond the hype: big data concepts, methods, and analytics. Int J Inf Manage. 2015;35(2):137–44.
- Vitale CH, Kennedy ML, Ruttenberg J. Advancing data science, data-intensive research, and its understanding through collaboration. In: Mani NS, Cawley MA, editors. Handbook of research on academic libraries as partners in data science ecosystems. Hershey: IGI Global; 2022. p. 25–44.
- Zhou ZH, Chawla NV, Jin Y, Williams GJ. Big data opportunities and challenges: discussions from data analytics perspectives [discussion forum]. IEEE Comput Intell Mag. 2014;9(4):62–74.
- Wamba SF, Gunasekaran A, Akter S, Ren SJF, Dubey R, Childe SJ. Big data analytics and firm performance: effects of dynamic capabilities. J Bus Res. 2017;70:356–65.
- Mohamed A, Najafabadi MK, Wah YB, Zaman EAK, Maskat R. The state of the art and taxonomy of big data analytics: view from new big data framework. Artif Intell Rev. 2020;53(2):989–1037.
- Lv Z, Song H, Basanta-Val P, Steed A, Jo M. Next-generation big data analytics: state of the art, challenges, and future research topics. IEEE Trans Industr Inf. 2017;13(4):1891–9.
- Ardagna CA, Ceravolo P, Damiani E. Big data analytics as-a-service: Issues and challenges. In proceedings of IEEE international conference on big data (big data). 2016. p. 3638–3644.
- Jun SW, Liu M, Lee S, Hicks J, Ankcorn J, King M, Xu S. Bluedbm an appliance for big data analytics. In: Marr D, editor. ACM/IEEE 42nd annual international symposium on computer architecture ISCA. Manhattan: IEEE; 2015. p. 1–13.
- Chandarana P, Vijayalakshmi M. Big data analytics frameworks, In proceedings of IEEE International Conference on Circuits, Systems, Communication and Information Technology Applications (CSCITA). 2014. p. 430–434.
- Gupta R, Gupta H, Mohania M. Cloud computing and big data analytics: what is new from databases perspective? Springer: In proceedings of international conference on big data analytics; 2012. p. 42–61.
- Salloum S, Dautov R, Chen X, Peng PX, Huang JZ. Big data analytics on apache spark. Int J Data Sci Anal. 2016;1(3):145–64.
- Erdei RM, Toka L. Optimal Resource Provisioning for Data-intensive Microservices. In NOMS 2022–2022 IEEE/IFIP Network Operations and Management Symposium. IEEE. 2022. (pp. 1–6).
- Jensen, M., "Challenges of privacy protection in big data analytics", In proceedings of IEEE international congress on big data. 2013. p. 235–238.
- Wang WY, Yin J, Chai Z, Chen X, Zhao W, Lu J, Sun F, Jia Q, Gao X, Tang B, Hui X. Big data-assisted digital twins for the smart design and manufacturing of advanced materials: from atoms to products. J Mater Inform. 2022;2(1):1.
- Iqbal R, Doctor F, More B, Mahmud S, Yousuf U. Big data analytics: computational intelligence techniques and application areas. Technol Forecast Soc Chang. 2020;153:119253.
- Ardagna CA, Bellandi V, Bezzi M, Ceravolo P, Damiani E, Hebert C. Model-based big data analytics-as-a-service: take big data to the next level. IEEE Trans Serv Comput. 2018;14(2):516–29.
- Shu H. Big data analytics: six techniques. Geo-spatial Inf Sci. 2016;19(2):119–28.
- Cevher V, Becker S, Schmidt M. Convex optimization for big data: scalable, randomized, and parallel algorithms for big data analytics. IEEE Signal Process Mag. 2014;31(5):32–43.
- Barba-González C, García-Nieto J, del Mar Roldán-García M, Navas-Delgado I, Nebro AJ, Aldana-Montes JF. BIGOWL: knowledge centered big data analytics. Expert Syst Appl. 2019;115:543–56.
- El-Hasnony IM, Barakat SI, Elhoseny M, Mostafa RR. Improved feature selection model for big data analytics. IEEE Access. 2020;8:66989–7004.
- Matteussi KJ, dos Anjos J, Leithardt VR, Geyer CF. Performance evaluation analysis of spark streaming backpressure for data-intensive pipelines. Sensors. 2022;22(13):4756.
- Ortega F, Cano EL. Sensor data analytics: challenges and methods for data-intensive applications. Entropy. 2022;24(7):850.
- Veiga J, Expósito RR, Pardo XC, Taboada GL, Tourifio J. Performance evaluation of big data frameworks for large-scale data analytics. In proceedings of IEEE International Conference on Big Data (Big Data). 2016. p. 424–431.
- Venkatesh K, Ali MJS, Nithiyanandam N, Rajesh M. Challenges and research disputes and tools in big data analytics. Int J Eng Adv Technol. 2019;6:1949–52.
- Divya KS, Bhargavi P, Jyothi S. Machine learning algorithms in big data analytics. Int J Comput Sci Eng. 2018;6(1):63–70.
- Chawda RK, Thakur G. Big data and advanced analytics tools. In proceedings of symposium on colossal data analysis and networking (CDAN). 2016. p. 1–8
- Wilcox T, Jin N, Flach P, Thumim J. A big data platform for smart meter data analytics. Comput Ind. 2019;105:250–9.
- Prasad AK, Bojnordi MN, Monarch: a durable polymorphic memory for data intensive applications. IEEE Transactions on Computers. 2022.
- Li H, Lu X. Challenges and trends of big data analytics. In proceedings of IEEE Ninth International Conference on P2P, Parallel, Grid, Cloud and Internet Computing. 2014. pp. 566–567.
- Ardagna CA, Bellandi V, Ceravolo P, Damiani E, Bezzi M, Hebert C. A model-driven methodology for big data analytics-as-a-service. In proceedings of IEEE International Congress on Big Data (BigData Congress). 2017. p. 105–112.Rialti R, Zollo L, Ferraris A, Alon I. Big data analytics capabilities and performance: evidence from a moderated multi-mediation model. Technol Forecast Soc Chang. 2019;149: 119781.
- Slavakis K, Giannakis GB, Mateos G. Modeling and optimization for big data analytics:(statistical) learning tools for our era of data deluge. IEEE Signal Process Mag. 2014;31(5):18–31.
- Poudel M, Sarode RP, Watanobe Y, Mozgovoy M, Bhalla S. A survey of big data archives in time-domain astronomy. Appl Sci. 2022;12(12):6202.
- Londhe A, Rao PP. Platforms for big data analytics: trend towards hybrid era. In proceedings of IEEE international conference on energy, communication, data analytics and soft computing (ICECDS). 2017. p. 3235–3238.
- Alsheikh MA, Niyato D, Lin S, Tan HP, Han Z. Mobile big data analytics using deep learning and apache spark. IEEE Network. 2016;30(3):22–9.
- Gudivada VN, Irfan MT, Fathi E, Rao DL. Cognitive analytics: going beyond big data analytics and machine learning. In Handbook Stat. 2016;35:169–205.
- Khalajzadeh H, Simmons AJ, Abdelrazek M, Grundy J, Hosking J, He Q. An end-to-end model-based approach to support big data analytics development. J Comput Languages. 2020;58: 100964.
- Spangenberg N, Roth M, Franczyk B. Evaluating new approaches of big data analytics frameworks. In proceedings of International conference on business information systems. 2015. p. 28–37.
- Lee I. Big data: dimensions, evolution, impacts, and challenges. Bus Horiz. 2017;60(3):293–303.
- Elaraby NM, Elmogy M, Barakat S. Deep Learning: Effective tool for big data analytics. International Journal of Computer Science Engineering (IJCSE). 2016;9.
- Kumar O, Goyal A. Visualization: a novel approach for big data analytics. In proceedings of second international conference on computational intelligence and communication technology (CICT). 2016. p. 121–124.
- Osman AMS. A novel big data analytics framework for smart cities. Futur Gener Comput Syst. 2019;91:620–33.
- Kibria MG, Nguyen K, Villardi GP, Zhao O, Ishizu K, Kojima F. Big data analytics, machine learning, and artificial intelligence in next-generation wireless networks. IEEE Access. 2018;6:32328–38.
- Raut RD, Mangla SK, Narwane VS, Gardas BB, Priyadarshinee P, Narkhede BE. Linking big data analytics and operational sustainability practices for sustainable business management. J Clean Prod. 2019;224:10–24.
- Lu Y, Xu X. Cloud-based manufacturing equipment and big data analytics to enable on-demand manufacturing services. Robotics Comput-Integr Manuf. 2019;57:92–102.
- Al-Ali AR, Zualkernan IA, Rashid M, Gupta R, AliKarar M. A smart home energy management system using IoT and big data analytics approach. IEEE Trans Consum Electron. 2017;63(4):426–34.
- Holmlund M, Van Vaerenbergh Y, Ciuchita R, Ravald A, Sarantopoulos P, Ordenes FV, Zaki M. Customer experience management in the age of big data analytics: a strategic framework. J Bus Res. 2020;116:356–65.
- Amini S, Gerostathopoulos I, Prehofer C. Big data analytics architecture for real-time traffic control. Models and technologies for intelligent transportation systems (MT-ITS). IEEE. 2017. p. 710–715.
- Ragini JR, Anand PR, Bhaskar V. Big data analytics for disaster response and recovery through sentiment analysis. Int J Inf Manage. 2018;42:13–24.
- Rathore MM, Paul A, Hong WH, Seo H, Awan I, Saeed S. Exploiting IoT and big data analytics: defining smart digital city using real-time urban data. Sustain Cities Soc. 2018;40:600–10.
- Keshk M, Moustafa N, Sitnikova E, Turnbull B. Privacy-preserving big data analytics for cyber-physical systems. Wireless Networks. 2018. p. 1–9
- Yassine A, Singh S, Hossain MS, Muhammad G. IoT big data analytics for smart homes with fog and cloud computing. Future Gener Comput Syst. 2019;91:563–73.
- Shorfuzzaman M, Hossain MS, Nazir A, Muhammad G, Alamri A. Harnessing the power of big data analytics in the cloud to support learning analytics in mobile learning environment. Comput Hum Behav. 2019;92:578–88.
- Darwish TS, Bakar KA. Fog based intelligent transportation big data analytics in the internet of vehicles environment: motivations, architecture, challenges, and critical issues. IEEE. 2018;6:15679–701.
- Yacchirema DC, Sarabia-Jácome D, Palau CE, Esteve M. A smart system for sleep monitoring by integrating IoT with big data analytics. IEEE. 2018;6:35988–6001.
- Gohar M, Muzammal M, Rahman AU. SMART TSS: defining transportation system behavior using big data analytics in smart cities. Sustain Cities Soc. 2018;41:114–9.
- Garg S, Singh A, Kaur K, Aujla GS, Batra S, Kumar N, Obaidat MS. Edge computing-based security framework for big data analytics in VANETs. IEEE Netw. 2019;33(2):72–81.
- Hadi MS, Lawey AQ, El-Gorashi TE, Elmirghani JM. Patient-centric cellular networks optimization using big data analytics. IEEE. 2019;7:49279–96.
- Ur Rehman MH, Ahmed E, Yaqoob I, Hashem IAT, Imran M, Ahmad S. Big data analytics in industrial IoT using a concentric computing model. IEEE Commun Mag. 2018;56(2):37–43.
- Babar M, Arif F, Jan MA, Tan Z, Khan F. Urban data management system: towards big data analytics for internet of things based smart urban environment using customized hadoop. Future Gener Comput Syst. 2019;96:398–409.
- He QP, Wang J. Statistical process monitoring as a big data analytics tool for smart manufacturing. J Process Control. 2018;67:35–43.
- Wang K, Li H, Feng Y, Tian G. Big data analytics for system stability evaluation strategy in the energy internet. IEEE Trans Ind Inform. 2017;13(4):1969–78.
- Chang V. A proposed social network analysis platform for big data analytics. Technol Forecast Soc Chang. 2018;130:57–68.
- Rajeswari S, Suthendran K, Rajakumar K. A smart agricultural model by integrating IoT, mobile and cloud-based big data analytics. Intelligent Computing and Control (I2C2). IEEE. 2017. p. 1–5
- Barbeito-Caamaño A, Chalmeta R. Using big data to evaluate corporate social responsibility and sustainable development practices. Corp Soc Responsib Environ Manag. 2020;27(6):2831–48.
- Bangui H, Ge M, Buhnova B, Hong Trang L. Towards faster big data analytics for anti-jamming applications in vehicular ad-hoc network. Trans Emerg Telecommun Technol. 2021;32(10):e4280.
- Dankwa‐Mullan I, Zhang X, Le PT, Riley WT. Applications of big data science and analytic techniques for health disparities research. The Science of Health Disparities Research. 2021. p. 221–242
- Nayak J, Kumar PS, Reddy DKK, Naik B, Pelusi D. Machine learning and big data in cyber‐physical system: methods, applications and challenges. Cognitive engineering for next generation computing: a practical analytical approach. 2021. p. 49–91
- Luthra H, Nihith TAS, Pravallika VSS, Shree RR, Chaurasia A, Bansal H. New paradigm in healthcare industry using big data analytics. In IOP conference series: materials science and engineering. 2021. Vol. 1099, No. 1, pp. 012054
- Zheng X. The application of big data technology in network marketing. J Phys Conf Ser. 2021;1744(4):042200.
- Ye X. The application of big data in the political and computer education of colleges and universities. J Phys Conf Ser. 2020;1648(3):032104.
- Moharm K, Eltahan M. The role of big data in improving e-learning transition. In IOP Conference Series: Materials Science and Engineering. 2020; Vol. 885. No. 1. p. 012003.
- Liang JH. Application of big data technology in product selection on cross-border e-commerce platforms. J Phys Conf Ser. 2020;1601(3):032012.
- Jin W, Jitao Y. Management innovations research of the logistics enterprises based on the big data environment. J Phys Conf Ser. 2020;1616(1):012010.
- Ramesh A, Rajkumar S, Livingston LJ. Disaster management in smart cities using IoT and big data. J Phys Conf Ser. 2020;1716(1):012060.
- Kend M, Nguyen LA. Big data analytics and other emerging technologies: the impact on the Australian audit and assurance profession. Aust Account Rev. 2020;30(4):269–82.
- Oussous A, Benjelloun FZ, Lahcen AA, Belfkih S. Big data technologies: a survey. J King Saud Univ-Comput Inform Sci. 2018;30(4):431–48.
- Chen CP, Zhang CY. Data-intensive applications, challenges, techniques and technologies: a survey on big data. Inf Sci. 2014;275:314–47.
- Agarwal S, Sonbhadra SK, Singh Punn N. Software Testing and Quality Assurance for Data Intensive Applications. In the International conference on evaluation and assessment in Software Engineering 2022. p. 461–462, 2022.
- Fekete JD. Visual analytics infrastructures: from data management to exploration. Computer. 2013;46(7):22–9.
- Ahmadvand H, Dargahi T, Foroutan F, Okorie P, Esposito F. Big data processing at the edge with data skew aware resource allocation. In 2021 IEEE conference on network function virtualization and software defined networks (NFV-SDN). 2021. 81–86.
- Ahmadvand H, Foroutan F, Fathy M. DV-DVFS: merging data variety and DVFS technique to manage the energy consumption of big data processing. J Big Data. 2021;8(1):1–16.
- Ahmadvand H, Goudarzi M. Significance-aware approach to improve qor of big data processing in case of budget constraint. J Supercomput. 2019;75(9):5760–81.
- Ahmadvand H, Goudarzi M, Foroutan F. Gapprox: using gallup approach for approximation in big data processing. J Big Data. 2019;6(1):1–24.
- Ahmadvand H, Goudarzi M. Using data variety for efficient progressive big data processing in warehouse-scale computers. IEEE Comput Architect Lett. 2016;16(2):166–9.
- Preuveneers D, Joosen W. Automated configuration of NoSQL performance and scalability tactics for data-intensive applications”. In Informatics. 2020. Vol. 7, No. 3, p. 29.
- Tuli S, Sandhu R, Buyya R. Shared data-aware dynamic resource provisioning and task scheduling for data intensive applications on hybrid clouds using aneka. Futur Gener Comput Syst. 2020;106:595–606.
- Nguyen M, Alesawi S, Li N, Che H, Jiang H. A black-box Fork-join latency prediction model for data-intensive applications. IEEE Trans Parallel Distrib Syst. 2020;31(9):1983–2000.
- Rao B, Liu Z, Zhang H, Lu S, Wang L. SODA: A semantics-aware optimization framework for data-intensive applications using hybrid program analysis. In 2021 IEEE 14th International Conference On Cloud Computing (CLOUD). 2021. p. 433–444.
- Rawas S, Zekri A. EEBA: energy-efficient and bandwidth-aware workload allocation method for data-intensive applications in cloud data centers. IAENG Int J Comput Sci. 2021;48:3.
- Sfiligoi I, Würthwein F, Davila D. Data intensive physics analysis in azure cloud. In: Pasumpon Pandian A, Fernando X, Haoxiang W, editors. Computer networks, big data and IoT. Singapore: Springer Nature Singapore; 2022.