
Рис. 1. Преображение качества фотографии
Автор:Бершадская О.А., Семенова А.П.
Источник: Материалы XIII Международной научно-технической конференции «Информатика, управляющие системы, математическое и компьютерное моделирование» (ИУСМКМ-2022). – Донецк: ДОННТУ, 2022. – С.437-441.
УДК 004.93'4
РАСПОЗНАВАНИЕ ТЕКСТОВЫХ ИЗОБРАЖЕНИЙ ПРИ ПОМОЩИ НЕЙРОННЫХ СЕТЕЙ
Бершадская О. А., Семенова А. П.
Донецкий национальный технический университет
кафедра
E-mail: olga.bershadskaya20@yandex.ru
Аннотация:
Бершадская О.А., Семенова А.П. Распознавание текстовых изображений при помощи нейронных сетей. Рассмотрено актуальное на сегодняшний день оптическое распознавание текстового изображения. Рассмотрены этапы обработки изображения для распознавания текста. Определены современные подходы к оптическому распознаванию символов. Рассмотрена рекуррентная нейронная сеть с обратной связью, которая позволяет выделять границы строк и распознавать символы.
Annotation:
Bershadskaya O.A., Semenova A.P. Recognition of text images using neural networks. The current optical recognition of a text image is considered. The stages of image processing for text recognition are considered. Modern approaches to optical character recognition are defined. A recurrent neural network with feedback is considered, which allows you to highlight the boundaries of strings and recognize characters.
Введение
В современном мире человек не может представить себя без цифровых технологий, особенно без фотографий. Фотографии, сделанные человеком, несут в себе огромный информационный поток. На них остаются названия улиц, магазинов, номера машин, чем непосредственно и занимается система распознавания текста. Проанализированные фотографии можно использовать для любых задач компьютерного зрения. Например, поиск по схожести, автоматическая навигация. Однако, самой популярной задачей на данный момент является моментальный перевод текста фотографии в редактор.
Такие варианты распознавания несут за собой некоторые недостатки в качестве изображения: фотография может быть с низким разращением, зашумлена и размыта. Также, необходимо автоматически определить язык текста на фотографии.
Актуальность задачи в автоматическом обнаружении и распознавании текста на фотографии. Нахождение контуров текста – один из самых важных этапов для дальнейшего распознавания текста.
Примеры использования распознавания текста
Данное направление необходимо при оцифровке изображений текста. Распознавание текста необходимо при сканировании документа, книги, статьи, журнала, чтобы продолжить работы с текстом в цифровом редакторе. Также это используется при обработке анкетных бланков, обработке системы тестирования знаний, распознавания номеров машин.
Этапы распознавания текста
Первый этап необходим для очистки исходного изображения от посторонних шумов, размытости фотографии. Очистка изображения помогает результативно выделить контуры символов и распознать их (рис. 1).
Рис. 1. Преображение качества фотографии
На рисунке 1 показан процесс обработки качества фотографии, следом за этом происходит анализ фотографии. Для этого процесса применяются специальные фильтры реставрации испорченных фотографий, например, с помощью гипоэллиптической диффузии [1], фильтры, устраняющие размазанность [2].
На втором этапе распознавания текст разбивается на блоки, базируясь на расположении его к горизонтальной и вертикальной прямой, далее добавляется текст в колонки (рис.2).

Рис. 2. Блок текста после второго этапа распознавания
Именно второй этап отвечает за обнаружение текста на фотографии. Есть несколько способов: выделение границ текста (скелетизация [3], определение краев и углов [4], методы на основе инвариантных моментов[5]), выделение цвета, анализ текстуры фотографии.
На третьем этапе происходит преображение текстовой фотографии на изображение строк (рис.3), чтобы далее обработать каждый символ отдельно. Далее различные системы распознают текст по различным алгоритмам.

Рис. 3. Текст после третьего этапа распознавания
Четвертый этап занимается обработкой целостного символа. Выбранный символ сравнивается с заданными в базе шаблонами, распознавание происходит при помощи нейронных сетей. Результат четвертого этапа – возможный вариант буквы. Далее система производит уточняющие действия, использую другие методы распознавания.
Современные подходы к оптическому распознаванию символов
Алгоритм оптического распознавания текста приведен на рис. 4. Прежде всего передний план объектов отделяется от фона. Затем определяется тип выделенных областей. Если определено, что данная область – текст, то можно начинать к его сегментации и распознаванию. В процессе своего развития подходы к OCR-системам корректировались, проходя через следующие этапы [6]:
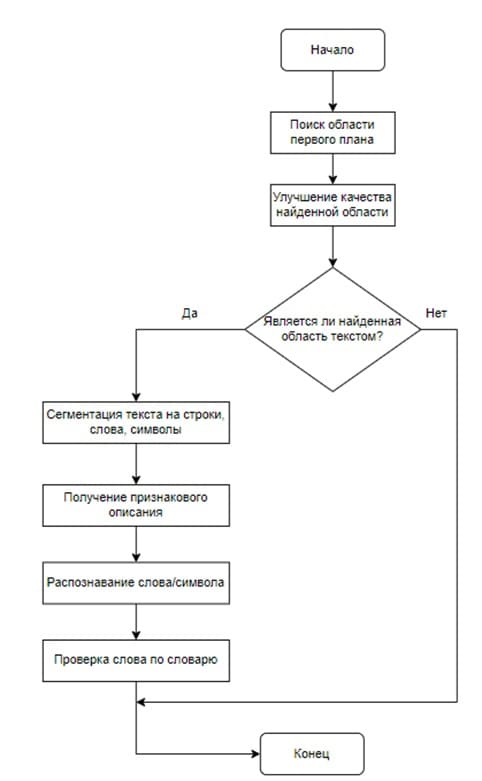
Рис. 4. Общий алгоритм работы OCR-системы
Рекуррентная нейронная сеть для распознавания текстовых изображений
Рекуррентные нейронные сети (РНС), подвидом которых является LSTM (long short-term memory), – тип нейронных сетей, задействующих обратную связь. В отличие от нейросетей прямого распространения, в которых информация передается последовательно от слоя к слою, в рекуррентных нейронных сетях каждый слой нейронов, помимо входных данных, получает некоторую информацию о предыдущем состоянии сети, что делает возможным анализ последовательностей данных (рис. 5).
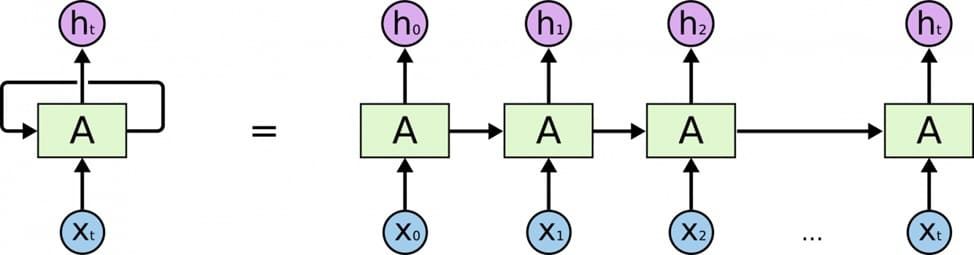
Рис. 5. Схема работы одного слоя нейронов рекуррентной сети
Главной же особенностью и преимуществом LSTM-сетей является умение работать с долгосрочными зависимостями: проще говоря, они, в отличие от обычных рекуррентных нейронных сетей, умеют работать с информацией, обработанной много циклов назад. Сейчас внедрение нейронных сетей, задействующих обратную связь, очень популярно доля распознавания любого вида текста на изображении.
Схема работы оптического распознавания текста и программная реализация
Программа определяет макет страницы и группирует очертания текста в объекты. Далее в объектах выделяются строки, а строки, в свою очередь, разбиваются на слова в зависимости от длины промежутков между ними. Для выделения макета страницы, а также выделения границ строк и отдельных слов используется рекуррентная нейронная сеть LSTM.
После этого анализируется, какой тип шрифта был использован для той или иной области текста: моноширинный или пропорциональный. В первом случае каждый символ имеет фиксированную ширину, а значит, есть возможность сразу разбить строку на символы. Во втором случае программа выделяет определенные и неопределенные промежутки между символами: решение по поводу неопределенных промежутков принимается в самом конце.
Распознавание проходит в два этапа. Сначала алгоритм старается распознать каждое слово по очереди и передает каждую успешную попытку классификатору в качестве обучающей выборки. Классификатор использует эти данные при дальнейшем продвижении по странице и на втором этапе распознавания, когда алгоритм повторно работает с теми словами, которые не получилось распознать в первый раз.
В самом конце принимается решение по поводу неопределенных промежутков и проверяет, не являются ли некоторые нераспознанные строчные буквы малыми заглавными.
Программная реализация распознавания текстовой картинки предоставлено на рис. 6.

Рис. 6. Программная реализация распознавания текста на изображениии
Выводы
Был рассмотрен основное и актуальное на сегодняшний день оптическое распознавание текстового изображения. Рассмотрены этапы распознавания речи, способы очистки фотографии от смазанности, нечетких букв, а также лишних фильтров.
Общий алгоритм системы оптического распознавания текста состоит в отделении переднего объекта от фона, определением является ли этот объект текстом, сегментация текста, распознавание слова и сверка его со словарем.
Для выделения границ строк и распознавания текста используется рекуррентная нейронная сеть с обратной связью. Она разработаны специально, чтобы избежать проблемы долговременной зависимости.
Литература